How the JPEG format works
JPEG images are found everywhere in our digital life, but behind this cover of awareness are algorithms that eliminate details that are not perceived by the human eye. The result is the highest visual quality with the smallest file size - but how exactly does all this work? Let's see what exactly our eyes do not see!

It is easy to take, as a matter of course, the opportunity to send a photo to a friend, and not to worry about which device, browser or operating system he uses - but this was not always the case. By the early 1980s, computers were able to store and display digital images, but there were many competing ideas for the best way to do this. It was impossible to simply send the image from one computer to another and hope that everything will work.
To solve this problem, in 1986, a committee of experts from around the world was assembled under the name Joint Photographic Experts Group (JPEG), founded in collaboration with the International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC). ) - two international standards organizations, headquartered in Geneva (Switzerland).
A group of people called JPEG created the standard for compressing digital images JPEG in 1992. Anyone using the internet probably met with JPEG images. This is the most common way to encode, send and store images. From web pages to email and social networks, JPEG is used billions of times a day — almost every time we watch an image online or send it. Without JPEG, the web would be less bright, slower, and probably it would have fewer pictures of seals!
')
This article is about decoding a jpeg image. In other words, what is required to convert compressed data stored on a computer into an image that appears on the screen. It is worth knowing about this, not only because it is important for understanding the technology that we use daily, but also because by revealing compression levels, we know better the perception and vision, as well as the details to which our eyes are more receptive.
In addition, playing with images in this way is very interesting.
Looking inside jpeg
Everything is stored on a computer as a sequence of binary numbers. Typically, these bits, zeros and ones, are grouped into eight, making up bytes. When you open a JPEG image on a computer, something (browser, OS, something else) has to decode the bytes, restoring the original image as a list of colors that can be shown.
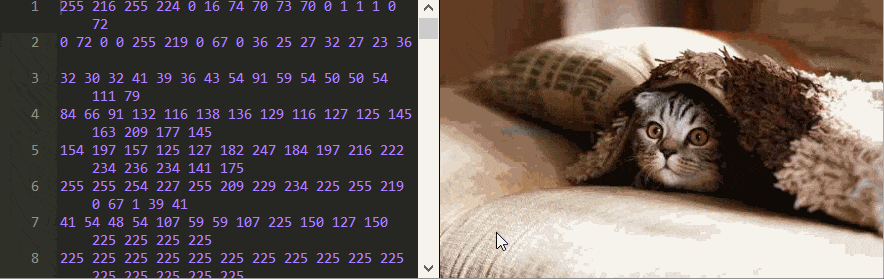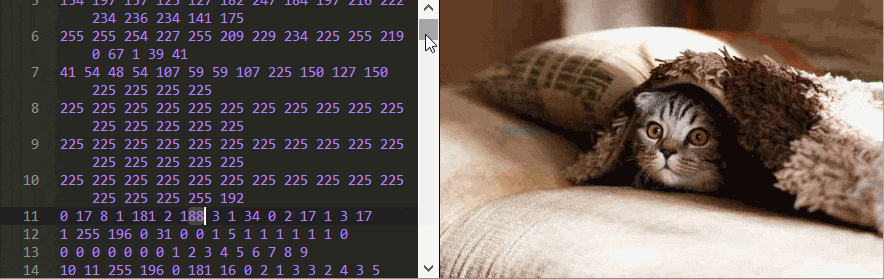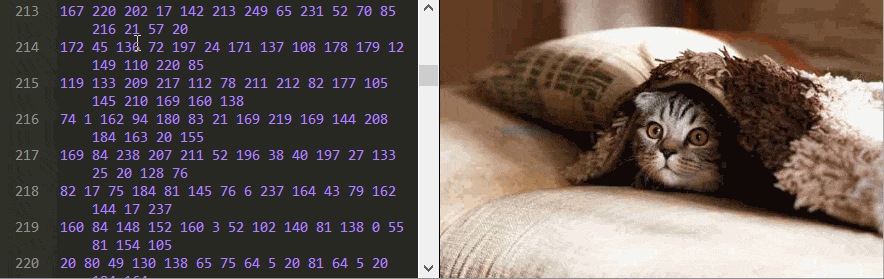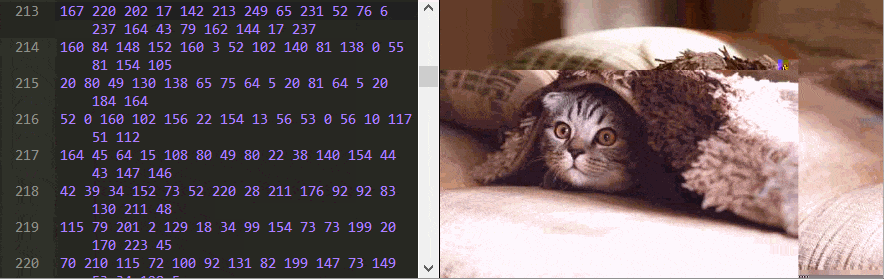
If you download this cute photo of a cat and open it in a text editor, you will see a bunch of incoherent characters.

Here I use Notepad ++ to examine the contents of the file, because ordinary text editors, such as Notepad from Windows, will corrupt the binary file after saving, and it will no longer satisfy the JPEG format.
Opening the image in a text editor, you confuse the computer, just as you confuse your brain when you rub your eyes and start to see colored spots!
These spots that you see are known as phosphenes and are not the result of a light stimulus or hallucinations generated by the mind. They occur because your brain believes that any electrical signals in the optic nerves convey information about light. The brain needs to make such assumptions, since it is not possible to know whether the signal is sound, vision, or something else. All the nerves in the body transmit exactly the same electrical impulses. Pressing on the eyes, you send signals that are not visual, but activate the receptors of the eye that your brain interprets - in this case, it is not true - as something visual. You can literally see the pressure!
It's funny to think about how computers are similar to the brain, but this is also a useful analogy that illustrates how strongly the meaning of data — transmitted over the body by nerves or stored on a computer — depends on their interpretation. All binary data consists of zeros and ones, the basic components capable of transmitting information of any kind. Your computer often guesses how to interpret them using prompts such as file extensions. And now we force him to interpret them as text, since this is what the text editor expects.
To understand how to decode JPEG, we need to see the original signals themselves - binary data. This can be done with a hex editor, or directly on the web page of the original article ! There is an image, next to which all its bytes (except for the header) are shown in the text field, presented in decimal form. You can change them, and the script recodes and outputs a new image on the fly.

You can learn a lot just by playing with this editor. For example, can you tell in which order the pixels are stored?
In this example, it is strange that changing some numbers does not affect the image at all, but, for example, if you replace the number 17 with 0 in the first line, the photo will completely deteriorate!

Other changes, for example, replacing 7 on line 1988 with the number 254 changes the color, but only subsequent pixels.

Perhaps the strangest thing is that some numbers change not only the color, but also the shape of the image. Change 70 in line 12 to 2 and look not at the top row of the image to see what I mean.

And no matter what JPEG image you use, you will always find these mysterious chess sequences when editing bytes.
Playing with the editor, it is hard to understand how a photo of these bytes is recreated, since JPEG compression consists of three different technologies that are applied sequentially in levels. We will study each of them separately to uncover the mysterious behavior we observe.
Three levels of JPEG compression:
- Color sub-sampling .
- Discrete cosine transform and discretization .
- Length , Delta, and Huffman Coding
So that you can imagine the scale of compression, note that the image above represents 79,819 numbers, that is, about 79 Kb. If we stored it without compression, for each pixel we would need three numbers - for the red, green and blue components. This would be 917,700 numbers, or approx. 917 Kb. As a result of JPEG compression, the resulting file has decreased by more than 10 times!
In fact, this image can be squeezed much stronger. Below are two images next to each other - the photo on the right was stung to 16 Kb, that is, 57 times smaller than the uncompressed version!

If you look closely, you will see that these images are not identical. Both of them are pictures with JPEG compression, but the right one is much smaller in volume. It also looks a little worse (look at the squares of the background colors). Therefore, JPEG is also called lossy compression; during compression, the image changes and loses some details.
1. Color subsampling
Here is an image using only the first compression level.

(The interactive version is in the original article). Removing one number destroys all colors. However, if you remove exactly six numbers, it almost does not affect the image.
Now the numbers are a little easier to decipher. This is almost a simple list of colors, in which each byte changes exactly one pixel, but at the same time it is already half the size of an uncompressed image (which would take about 300 KB in such a reduced size). Guess why?
You can see that these numbers do not denote the standard red, green, and blue components, because if we replace all the numbers with zeros, we get a green image (not white).

This is because these bytes denote Y (brightness),

Cb (relative blue),

and Cr (relative redness) pictures.

Why not use RGB? After all, this is how most modern screens work. Your monitor can show any color, including red, green and blue colors with different intensities for each pixel. White is obtained by turning on all three at full brightness, and black by turning them off.
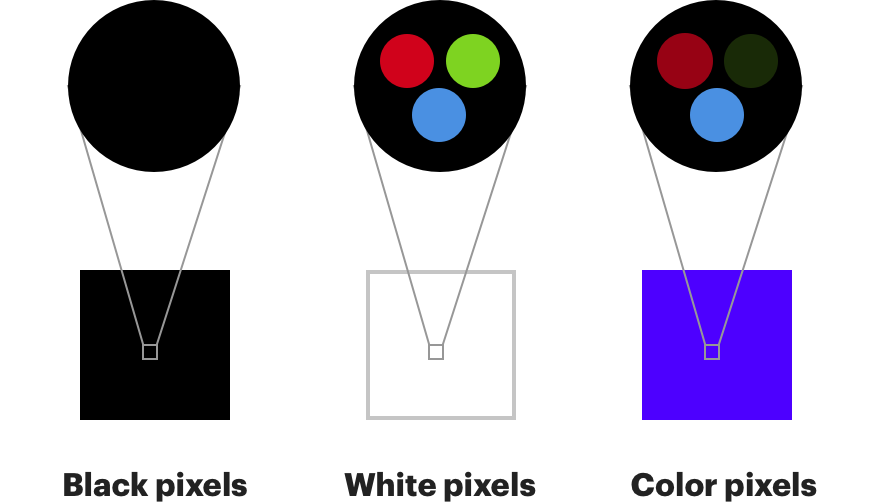
It is also very similar to the work of the human eye. The color receptors of our eyes are called " cones ", and are divided into three types, each of which is more sensitive to either red, or green, or blue [S-type cones are sensitive in violet-blue (S from the English. Short - short-wave spectrum), M-type - in green-yellow (M from English. Medium - medium wave), and L-type - in yellow-red (L from English. Long - long wave) parts of the spectrum. The presence of these three types of cones (and rods, sensitive in the emerald-green part of the spectrum) gives a person color vision. / approx. trans.]. Sticks , a different type of photoreceptor in our eyes, can detect changes in brightness, but are much more sensitive to color. In our eyes there are about 120 million rods and only 6 million cones.
Therefore, our eyes notice much better changes in brightness than changes in color. If you separate the color from the brightness, you can remove a little color, and no one will notice. Color subsampling is the process of representing the color components of an image at a lower resolution than the brightness components. In the example above, each pixel has exactly one component Y, and each separate group of four pixels has exactly one Cb component and one Cr. Therefore, the image contains four times less color information than the original.
The YCbCr color space is not only used in JPEG. He was originally invented in 1938 for television programs. Not everyone has a color TV, so the separation of color and brightness allowed everyone to receive the same signal, and TVs without color simply used only the brightness component.
Therefore, removing one number from the editor completely destroys all the colors. Components are stored as YYYY Cb Cr (in fact, not necessarily in this order - the storage order is specified in the file header). Removing the first number will lead to the fact that the first Cb value will be perceived as Y, Cr as Cb, and in general there will be a domino effect that switches all colors of the picture.
The JPEG specification does not obligate you to use YCbCr. But in most files it is used because it gives better quality images after subsampling compared to RGB. But you don't have to take my word for it. See for yourself in the table below what the downsampling of each individual component will look like in both RGB and YCbCr.

(The interactive version is in the original article).
Removing blue is not as noticeable as red or green. That's because of the six million cones in your eyes, about 64% are sensitive to red, 32% to green and 2% to blue.
Subsampling of the Y component (lower left) is best seen. Even a slight change is noticeable.
Converting an image from RGB to YCbCr does not reduce the file size, but makes it easier to find less noticeable details that can be deleted. Lossy compression occurs in the second stage. It is based on the idea of presenting data in a more compressible form.
2. Discrete cosine transform and discretization
This level of compression for the most part determines the essence of JPEG. After converting colors to YCbCr, the components are compressed separately, so we can then concentrate only on component Y. And this is how the bytes of component Y look after applying this level.
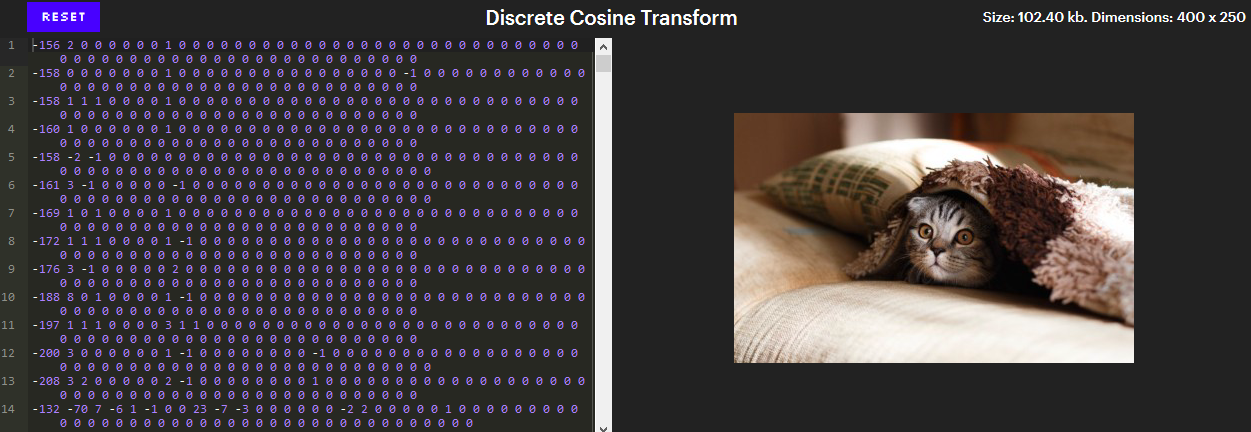
(The interactive version is in the original article). In the interactive version, clicking on a pixel scrolls the editor to the line that represents it. Try removing numbers from the end or add a few zeros to a specific number.
At first glance, it looks like a very bad compression. There are 100,000 pixels in the image, and 102,400 numbers are required to indicate their brightness (Y-components) - this is worse than not compressing anything at all!
However, note that most of these numbers are zero. Moreover, all these zeros at the end of lines can be deleted without changing the image. It remains about 26,000 numbers, and this is almost 4 times less!
At this level is the secret of chess patterns. Unlike other effects that we have seen, the appearance of these patterns is not a glitch. They are the building blocks of the entire image. Each line of the editor contains exactly 64 numbers, the coefficients of the discrete cosine transform (DCT), corresponding to the intensities of 64 unique patterns.
These patterns are formed based on the cosine graph. Here are some of them:

8 of 64 factors
Below is an image showing all 64 patterns.
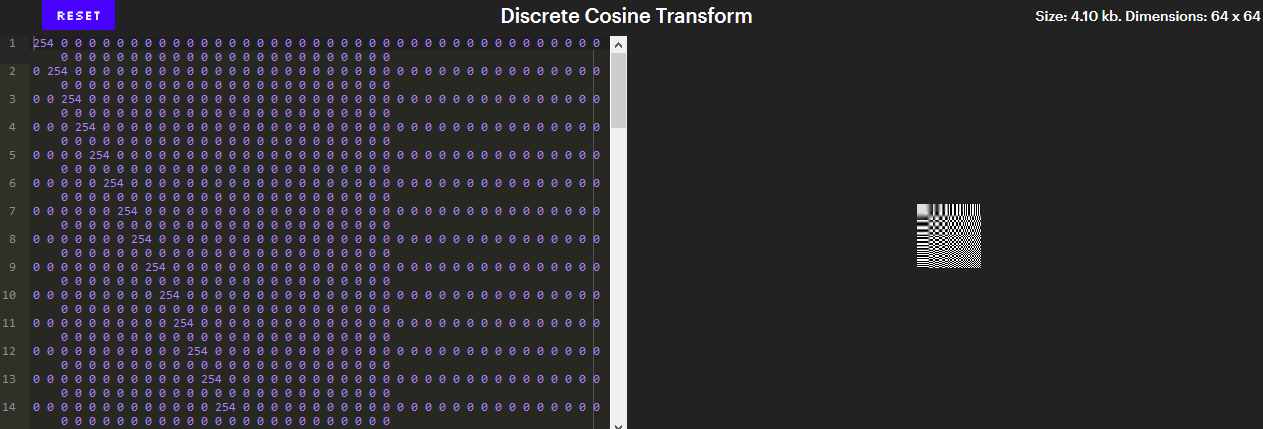
(The interactive version is in the original article).
These patterns have a special meaning because they form the basis of 8x8 images. If you are unfamiliar with algebra, this means that any 8x8 image can be obtained from these 64 patterns. DCT is the process of dividing images into 8x8 blocks and transforming each block into a combination of these 64 coefficients.
The fact that any image can be made up of 64 certain patterns, it seems like magic. However, this is the same as saying that any place on Earth can be described by two numbers - latitude and longitude [indicating hemispheres / approx. trans.]. We often consider the surface of the Earth to be two-dimensional, therefore we need only two numbers. The 8x8 image has 64 dimensions, so we need 64 numbers.
It is not yet clear how this helps us in terms of compression. If we need 64 numbers to represent an 8x8 image, why would this method be better than just storing 64 brightness components? We do this for the same reason that we turned three RGB numbers into three YCbCr numbers: this allows us to remove unnoticeable details.
It is difficult to see exactly which parts are removed at this stage, since JPEG applies DCT to 8x8 blocks. However, no one forbids us to apply it to the whole picture. Here is what DCT looks like for component Y as applied to the whole picture:
From the end you can remove more than 60,000 numbers with almost no noticeable changes in the pictures.

However, note that if we reset the first five numbers, the difference will be obvious.

The numbers at the beginning denote low frequency variations in the image, and our eyes catch them best. Numbers near the end indicate high frequency variations that are more difficult to notice. To "see what is not visible to the eye," we can isolate these high-frequency details by resetting the first 5,000 numbers.

We see all areas of the image in which the largest change from pixel to pixel occurs. The cat's eyes stand out, his mustache, a terry blanket and the shadows in the lower left corner. You can go further by resetting the first 10,000 numbers:

20,000:

40,000:

60,000:

These high-frequency details are JPEG and removes during the compression phase. Color conversion to DCT coefficients is not a loss. Losses are generated at the discretization step, where the high frequency values or close to zero are removed. When you lower the quality of JPEG saving, the program increases the threshold for the number of values to be deleted, which reduces the file size, but makes the picture more pixelated. Therefore, the image in the first section, which was 57 times smaller, looked like that. Each 8x8 block was represented by a much smaller number of DCT coefficients compared to a higher-quality version.
You can make such a cool effect as a gradual streaming of images. You can display a blurry image that becomes more and more detailed as you download more and more coefficients.
Here, just for the sake of interest, what happens when you use only 24,000 numbers:

Or just 5000:

Very blurry, but as if recognizable!
3. Length, Delta, and Huffman Coding
So far, all the stages of compression have been going down. The last stage, on the contrary, goes without loss. It does not delete the information, but significantly reduces the file size.
How can you compress something without discarding information? Imagine how we would describe a simple black rectangle 700 x 437.
JPEG uses 5,000 numbers for this, but much better results can be achieved. Can you imagine a coding scheme that describes such an image in as few bytes as possible?
The minimal scheme I could think of uses four: three to indicate color, and the fourth how many pixels have that color. The idea of representing repetitive values in such a compressed way is called run length coding. It has no losses, since we can recover the coded data in its original form.
The size of a JPEG file with a black rectangle is much more than 4 bytes - remember that at the DCT level, compression is applied to blocks of 8x8 pixels. Therefore, at a minimum, we need one DCT coefficient for every 64 pixels. We need one because instead of storing one DCT coefficient followed by 63 zeros, the coding of run lengths allows us to store one number and designate that “all the others are zeros”.
Delta encoding is a technique in which each byte contains a difference from some value, not an absolute value. Therefore, editing certain bytes changes the color of all other pixels. For example, instead of storing
12 13 14 14 14 13 13 14
We could start with 12, and then simply designate how much to add or subtract to get the next number. And this sequence in delta coding takes the form:
12 1 1 0 0 -1 0 1
The converted data is not less than the original, but compressing it is already easier. The use of delta coding before coding lengths of series can greatly help, while remaining lossless compression.
Delta encoding is one of the few techniques used outside 8x8 blocks. Of the 64 DCT coefficients, one is simply a constant wave function (solid color). It represents the average brightness of each block for the brightness component, or the average blue for the Cb components, and so on. The first value of each DCT block is called a DC value, and each DC value passes a delta encoding with respect to the previous ones. Therefore, changing the brightness of the first block will affect all the blocks.
The last mystery remains: how does the change in the singular completely spoil the whole picture? So far, there were no such properties for compression levels. The answer lies in the JPEG header. The first 500 bytes contain metadata about the image — width, height, and so on, and so far we have not worked with them.
Without a header, it is almost impossible (well, or very difficult) to decode JPEG. It will look like I'm trying to describe a picture for you, and start to invent words in order to convey my impression. The description will probably be very succinct, because I can invent words with the very meaning I want to convey, but for everyone else they will not make sense.
It sounds silly, but this is exactly what happens. Each JPEG image is compressed with codes specific to it. The code dictionary is stored in the header. This technique is called the “Huffman code”, and the dictionary is the Huffman table. In the header, the table is marked with two bytes - 255 and then 196. Each color component can have its own table.
Changes to tables will radically affect any image. A good example is to change on line 15 to 12.

This is because the tables indicate how to read individual bits. So far we have only worked with binary numbers in decimal form. But this hides from us the fact that if you want to store the number 1 in a byte, then it will look like 00000001, since each byte must have exactly eight bits, even if you only need one of them.
This is potentially a big waste of space if you have a lot of small numbers.The Huffman code is a technique that allows us to weaken this requirement, according to which each number should occupy eight bits. This means that if you see two bytes:
234 115
That, depending on the Huffman table, it can be three numbers. To extract them, you first need to break them into separate bits:
11101010 01110011
Then we turn to the table to figure out how to group them. For example, it can be the first six bits, (111010), or 58 in the decimal system, followed by five bits (10011), or 19, and finally the last four bits (0011), or 3.
Therefore, it is very difficult to understand bytes at this stage of compression. Bytes do not represent what it seems. I will not go into the details of working with the table in this article, but materialson this issue on the network enough .
One of the interesting tricks that can be done, knowing this is to separate the header from the JPEG and store it separately. In fact, it turns out that only you can read the file. Facebook is doing this to shrink files even more.
What else can be done - quite a bit to change the Huffman table. For others, it will look like a spoiled picture. And only you will know the magic version of its correction.
To summarize: so what is needed for JPEG decoding? It is necessary:
- Extract the Huffman table (s) from the header and decode the bits.
- Extract the discrete cosine transform coefficients for each color and brightness component for each 8x8 block by performing the inverse transforms of the run and delta length coding.
- , 88.
- , ( ).
- YCbCr RGB.
- !
Serious work for easy viewing photos with a cat! However, what I like about it is that the JPEG technology is human-centric. It is based on the features of our perception, allowing us to achieve much better compression than conventional technologies. And now, understanding how JPEG works, you can imagine how these technologies can be transferred to other areas. For example, delta encoding in video can give a serious decrease in file size, since there are often whole areas that do not change from frame to frame (for example, the background).
The code used in the article is open, and contains instructions for replacing images with your own.
Source: https://habr.com/ru/post/454944/
All Articles