Rekko Challenge - how to take 2nd place in the competition for the creation of recommendation systems
Hello. My team in Tinkoff builds recommender systems. If you are satisfied with your monthly cashback, then this is our doing. We also built a recommendation system of special offers from partners and deal with individual collections of Stories in the Tinkoff application. We also love to participate in machine learning competitions to keep ourselves in good shape.
For two months from February 18 to April 18, a competition to build a recommender system based on real data of one of the largest Russian online cinemas Okko took place on Boosters.pro . The organizers aimed to improve the existing recommendation system. At the moment, the competition is available in sandbox mode , in which you can test your approaches and hone your skills in building recommender systems.
Data description
Access to the content in Okko is carried out through the application on a TV or smartphone, or through a web interface. Content can be leased®, purchased (P) or viewed by subscription (S). The organizer of the competition provided data on views for N days (N> 60), information about the ratings and bookmarks was additionally available. It is necessary to keep in mind one important detail; if a user watched one movie several times or several episodes of a series, then only the date of the last transaction and the total time spent per content unit will be recorded in the tablet.
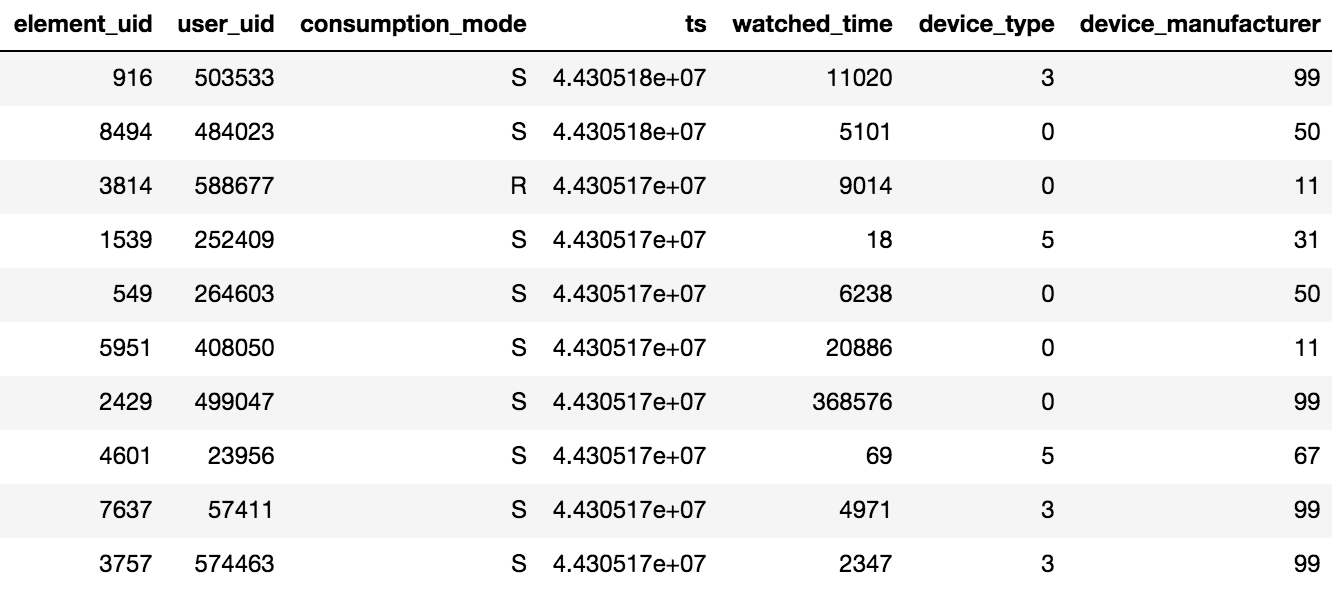
It was given about 10 million transactions, 450 thousand estimates and 950 thousand facts bookmarked by 500 thousand users.
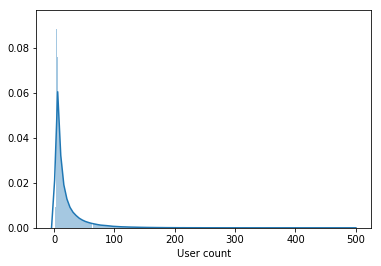
The sample contains not only active users, but also users who have watched a couple of films for the entire period.
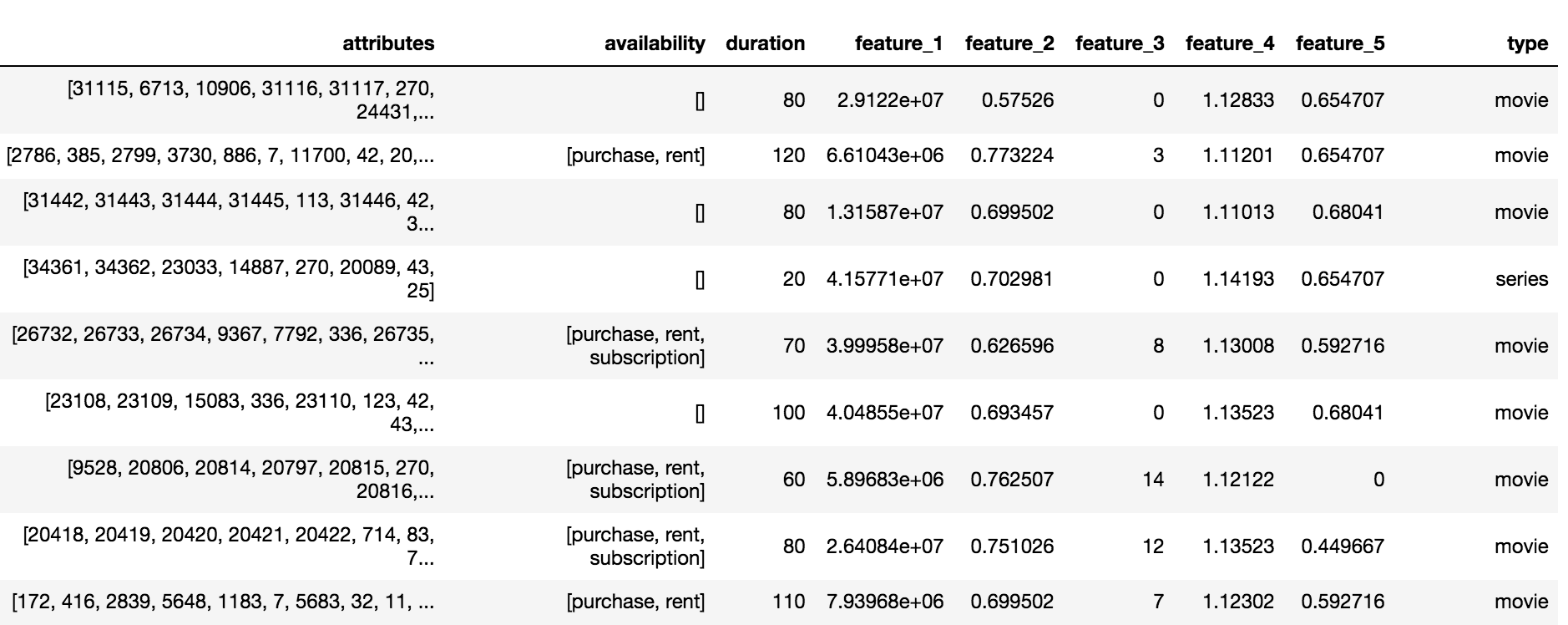
The Okko directory contains three types of content: movies (movie), series (serials) and multi-part films (multipart_movie), a total of 10,200 objects. For each object, a set of anonymized attributes (attributes) and attributes (feature_1, ..., feature_5), availability by subscription, rental or purchase, and duration were available.
Target variable and metric
The task required to predict a lot of content that the user will consume over the next 60 days. A user is considered to consume content if he:
- Buy it or rent it
- Watch more than half of the movie by subscription
- Watch more than a third of the series by subscription
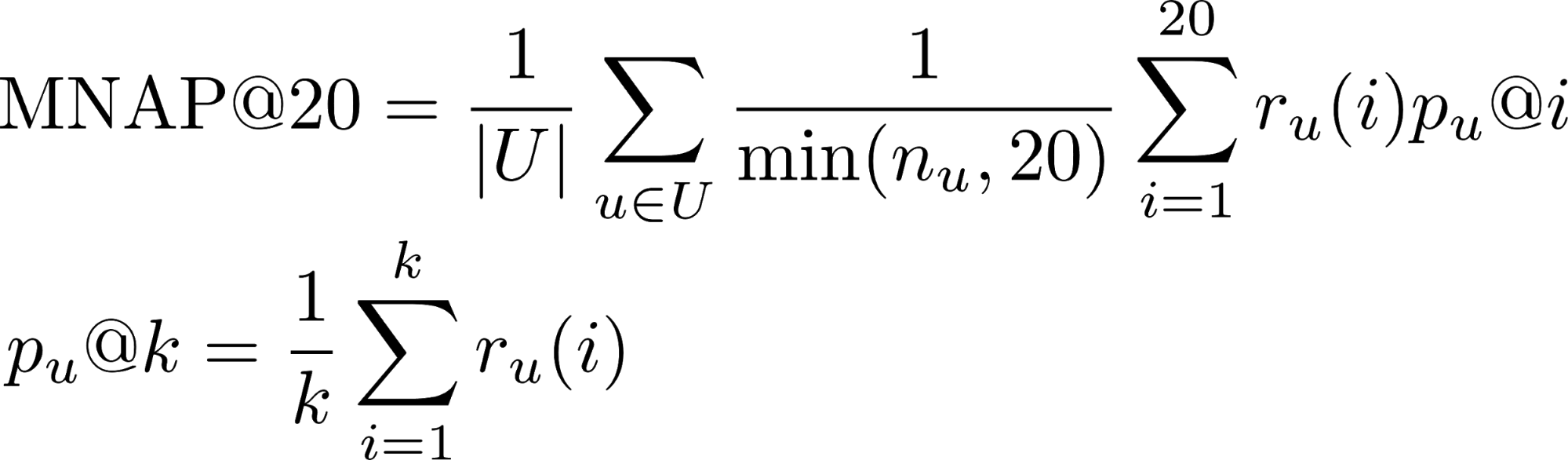
- r_u (i) - whether the user u consumed the content predicted to him in place i (1 or 0)
- n_u - the number of items that the user consumed during the test period
- U - a lot of test users
Learn more about the metrics for the ranking task in this post .
Most users watch movies to the end, so the transaction share of the positive class is 65%. The quality of the algorithm was evaluated by a subset of 50 thousand users from the presented sample.
Aggregated rating
The decision of the competition began with the aggregation of all interactions of users with content into a single rating scale. It was assumed that if the user bought the content, it means the maximum interest. The film is shorter than the series, therefore for watching the entire series you need to give more points. As a result, the aggregated rating was formed according to the following rules:
- Share movie viewing * 5
- Watch TV show share * 10
- [Bookmark movie] * 0.5
- [Bookmark TV Show] * 1.5
- [Buying / renting content] * 15
- Rating + 2
First level model
The organizers provided a basic solution based on collaborative filtering with Tf-IDF weights. Adding all types of interactions to the aggregated rating, increasing the number of nearest neighbors from 20 to 150 and replacing Tf-IDF with BM25 weights knocked out about 0.03 per LB (Leader Board).
Inspired by the post of the team that took 3rd place at the RecSys Challenge 2018 , I chose the LightFM model with the WARP Loss as the second base model. LightFM with selected hyper-parameters: learning_rate, no_components, item_alpha, user_alpha, max_sampled gave 0.033 on LB.

Validation of the model was carried out in time: the first 80% of the interactions fell into the train, the remaining 20% were validated. For a submission on LB, the model on all datasets with parameters selected for validation was separately studied.
Blending models
In the previous stage, it turned out to build two strong baselines, moreover, their recommendations intersected on average 60 percent of the recommended content. If there are two strong and at the same time weakly correlated models, then a reasonable step is their blending.
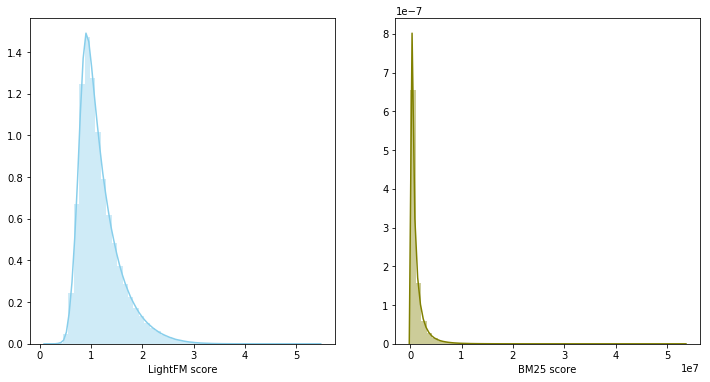
In this case, model skors belong to different distributions and have a different scale, so it was decided to use the sum of ranks to combine the two models. The model blending gave 0.0347 on LB.

Second level model
In recommender systems, a two-tier approach is often used to build models: first, top candidates are selected by a simple first-level model, then the selected top is re-ranked by a more complex model with the addition of a large number of features.

Dataset was broken down into training and validation parts. For the validation part, a selection of recommendations was collected for each user, consisting of combining top200 predictions of first-level models with the exception of already watched films. Further, it was required to teach the model to rearrange the resulting top for each user. The problem was formulated in terms of a binary classification. The pair (user, content) belonged to the positive class only if the user consumed the content during the validation period. As a model of the second level, gradient boosting was used, namely the LightGBM package.
Signs of
Models of the first level for couples (user, content) evaluate relevance in the form of skor, sorting out which in descending order you can get rank. The model, trained on the signs of rank and speed, in combination with the signs, knocked out 0.0359 from the content catalog from LB.
From the form of distribution of the first of the anonymized features, it was concluded that it is the date the film appeared in the catalog, therefore the model was strongly retrained for this feature with the selected validation scheme. Removing a trait from the sample increased on LB to 0.0367
In addition to predicting content relevance for a user, the LightFM model returns two vectors: item bias and user bias, correlating with the degree of popularity of the content and the number of films viewed by the user, respectively. Adding signs raised fast on LB to 0.0388 .
You can assign a rank for a couple (user, content) either before or after deleting already watched movies. A change in the method to the latter provided an increase in LB to 0.0395 .
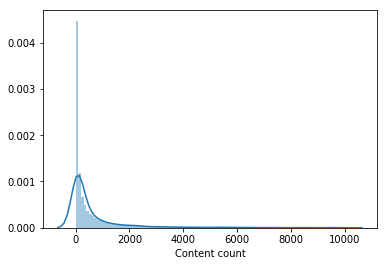
Almost no one watched a significant part of the movie catalog. Content that was viewed by less than 100 users was removed from the sample for learning the second-level model, which reduced the catalog by half. Removing unpopular content made the selection from first-level models more relevant and only after that the vectors of users from LightFM improved the validation rate and gave an increase on LB to 0.0429 .
Further, a sign was added - the user added the movie to the bookmarks, but did not watch it during the training period, which raised the speed on LB to 0.0447 . Signs about the date of the first and last transactions were also added, they raised speed to 0.0457 on LB.

We will consider this model final. The most significant were signs from the first-level models and anonymized signs from the content catalog.
The following features did not give rise to the final model:
- number of bookmarks + share of browsed content from bookmarks - 0.0453 LB
- number of purchased films 0.0451 LB
But when blending with the final model, 0.0465 was knocked out on the LB. Inspired by the result of blending, the following models were separately trained:
- with different training sample fractions for the first level model. A split of 90% / 10% gave an increase, in contrast to partitions of 95% / 5% and 70% / 30%.
- with a modified rating aggregation method.
- with the addition of unpopular films in the training sample for the model of the second level. For each unit of content was compiled from 1000 users.
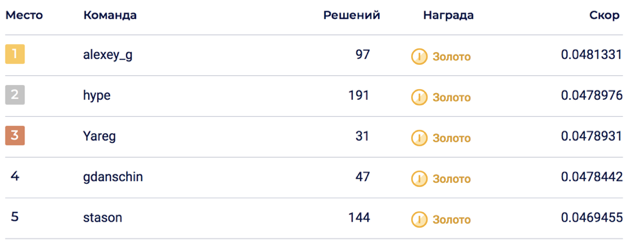
The final blending of 6 models allowed achieving 0.0469678 on LB, which corresponded to the 5th place.

On the private side, a shake-up happened, throwing the decision to 2nd place. I think that the solution turned out to be stable due to the blending of a large number of models.
Did not go
In the process of resolving the competition, many signs were generated that seemed to come in exactly, but alas. Signs and approaches that were believed the most:
- Anonymized content attributes. It was not known for certain what they contain, but all participants of the competition thought that they contained information about actors, directors, composers ... In my solution I tried to add them in several formats: top popular as binary signs, to decompose the content matrix attributes using LightFM and BigARTM, and then dragging out vectors and adding to the second-level model.
- Content vectors from the LigthFM model in the second level model.
- Attributes of the devices from which the user viewed the content.
- Lowering the weights of popular content for the second level model.
- Share movies / series in relation to the total number of viewed content.
- Ranking Metrics from CatBoost.
Interesting facts about the competition
- Top1 solution was worse than the product model okko 0.048 vs 0.062. It should be borne in mind that the product model has already been launched at the time of sampling.
- About a week after the start of the competition, datasets were changed, those who participated from the outset added 30 submissions, which suddenly burned down after the merge of the teams.
- Validation did not always correlate with LB, which indicated a possible shake up.
Decision code
The solution is available on github in the form of two jupyter laptops: rating aggregation, training of models of the first and second levels.
A 3rd place solution is also available on github .
The decision of the organizers
Instead of a thousand words, I attach the top features of the organizers.
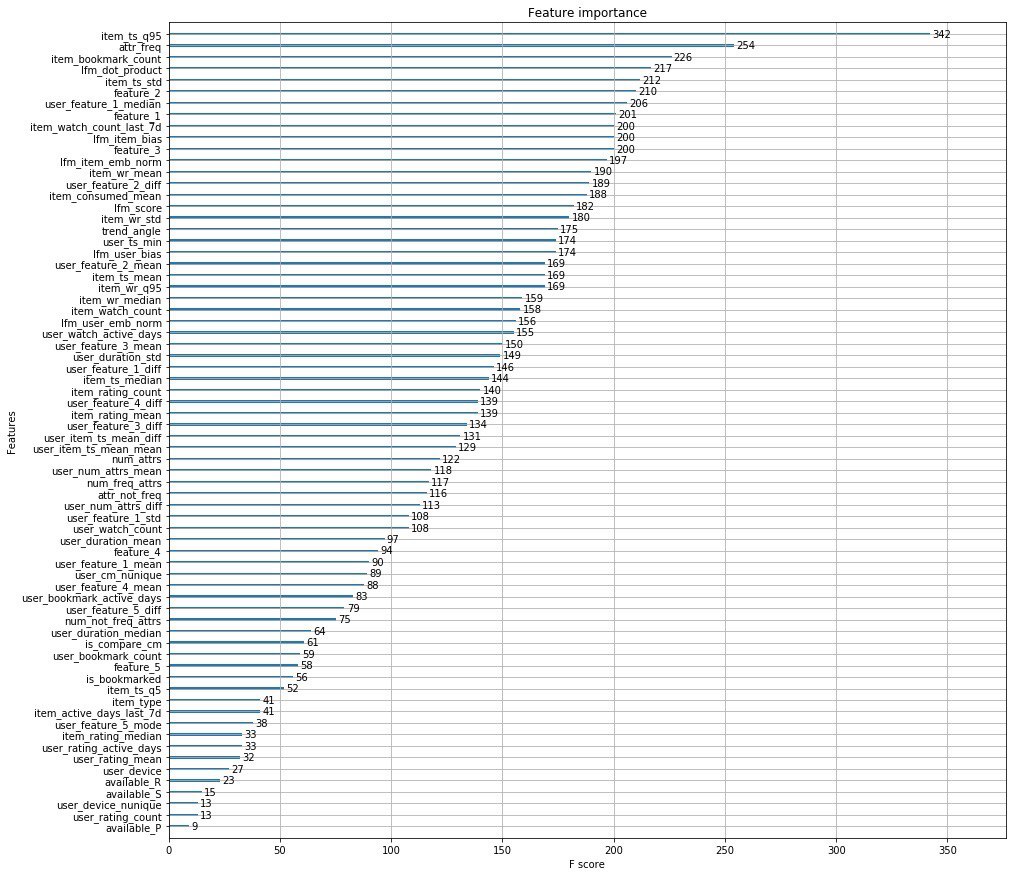
In addition, the guys from Okko released an article in which they talk about the stages of development of their recommendation engine.
PS here you can see the presentation on Data Fest 6 about this solution to the problem.
')
Source: https://habr.com/ru/post/454818/
All Articles