“Thick and thin” or how I mastered neural networks
Part 2
Part 1 is here .
Many thanks to the readers for the positive feedback.
Well, everything is ready! Now you can start. Begin to train the neural network, and then reap the benefits of this training. So I think at first, because of inexperience ... But back to the theory. To the neuron device. There are dendrites, there is a body of a neuron, there is an axon. According to the dendrites, we transmit the input signals (height and weight), which have their weights W1 and W2, there is a neuron body (activation function) and there is an axon (output).
')
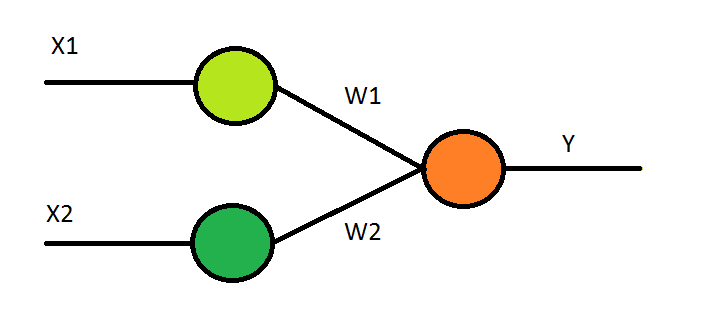
What function to take as an activation? - My choice fell on sigmoid (although, of course, other choices of activation function are possible).

The first problem I encountered was that a sigmoid gives too “small” response, a signal level that does not exceed one, and the BMI values are not that few, tens! But this problem is solved quite easily by entering a scaling factor. I took the ratio of 1/100.

The next problem - a sigmoid gives values from -0.5 to 0.5, and I have no negative values in the BMI. It is also solved quite simply - let's move the graph along the abscissa to the left by inputting a constant into the function (that is, so that X, equal to zero, gives Y, equal to "0", and not "0.5").

As a result, for the operation of our artificial neuron we have the following mathematical apparatus:
X = X1 * W1 + X2 * W2
Y = sigm (X) - 0.5
Where,
sigm is a sigmodal function:

Now go to the training. - We take the function of back propagation of an error and ... - And where can I get it? In addition to obscure "feint ears" in numerous articles under the heading: "Oh, yes, neural networks - it's easy! Like two fingers on the asphalt! ”There was no useful information there. It became clear that the book is needed. Normal is such a “human” book, where the author, without any extra “bends of fingers”, goes from “simple to complex” in building a neural network and explains everything in detail. And such a book was found. This is Tariq Rashid’s book Create a Neural Network.

For two or three days I carefully studied it in search of an answer to the question: “What is the formula for adjusting the weights during the reverse propagation of an error ?!”, while checking the correctness of my constructions, comparing with the constructions of Tariq. Tarik took the classic use of neural networks - “character recognition” and built his network to solve this problem (he has a two-layer network). The program code in this book is written in Python, so I had to fluently study this language in order to understand the implementation (I decided to leave the good Python mastery “for later”, as it is not only the language, but also the development environment and the toolkit).
Step by step, gradually I reached the chapter in which the error was evaluated and corrected. The method of calculating the correction values of the weights uses so-called. the gradient descent method using the differential calculus machine (yes, the neural network is for you "didn't sneeze a sheep", these are clever people have invented).
Important note: W1, W2 ... Wn weights are adjusted to the extent that they contribute to the error. I.e:
W new = Old - (dW * W old)
dW is the calculated “general” weighting correction, which is then distributed over each weight.
The book provided a formula for adjusting the weights for a two-layer network, I adapted it for a single-layer one. I will not give this formula here, in the article, in essence, this is the very “golden coin” and the heart of the whole method, without which all talk of neural networks turns into idle talk and cheap populism of Internet articles telling to quickly “master” neural networks and in half an hour to become an “expert” in them. Agree, it is better, after all, "to be" than to "seem." Therefore, if you are really interested in neural networks, I recommend that you study this book.

Wow! - Now you can erase the sweat from your forehead and proceed to the actual training and testing of the network ... True, we still need a small toolkit to assess the quality of its work, but I will tell about this in 3 parts of the article.
The end of the second part.
Part 1 is here .
Many thanks to the readers for the positive feedback.
Training
Well, everything is ready! Now you can start. Begin to train the neural network, and then reap the benefits of this training. So I think at first, because of inexperience ... But back to the theory. To the neuron device. There are dendrites, there is a body of a neuron, there is an axon. According to the dendrites, we transmit the input signals (height and weight), which have their weights W1 and W2, there is a neuron body (activation function) and there is an axon (output).
')
What function to take as an activation? - My choice fell on sigmoid (although, of course, other choices of activation function are possible).
The first problem I encountered was that a sigmoid gives too “small” response, a signal level that does not exceed one, and the BMI values are not that few, tens! But this problem is solved quite easily by entering a scaling factor. I took the ratio of 1/100.
The next problem - a sigmoid gives values from -0.5 to 0.5, and I have no negative values in the BMI. It is also solved quite simply - let's move the graph along the abscissa to the left by inputting a constant into the function (that is, so that X, equal to zero, gives Y, equal to "0", and not "0.5").
As a result, for the operation of our artificial neuron we have the following mathematical apparatus:
X = X1 * W1 + X2 * W2
Y = sigm (X) - 0.5
Where,
sigm is a sigmodal function:
Now go to the training. - We take the function of back propagation of an error and ... - And where can I get it? In addition to obscure "feint ears" in numerous articles under the heading: "Oh, yes, neural networks - it's easy! Like two fingers on the asphalt! ”There was no useful information there. It became clear that the book is needed. Normal is such a “human” book, where the author, without any extra “bends of fingers”, goes from “simple to complex” in building a neural network and explains everything in detail. And such a book was found. This is Tariq Rashid’s book Create a Neural Network.
For two or three days I carefully studied it in search of an answer to the question: “What is the formula for adjusting the weights during the reverse propagation of an error ?!”, while checking the correctness of my constructions, comparing with the constructions of Tariq. Tarik took the classic use of neural networks - “character recognition” and built his network to solve this problem (he has a two-layer network). The program code in this book is written in Python, so I had to fluently study this language in order to understand the implementation (I decided to leave the good Python mastery “for later”, as it is not only the language, but also the development environment and the toolkit).
Step by step, gradually I reached the chapter in which the error was evaluated and corrected. The method of calculating the correction values of the weights uses so-called. the gradient descent method using the differential calculus machine (yes, the neural network is for you "didn't sneeze a sheep", these are clever people have invented).
Important note: W1, W2 ... Wn weights are adjusted to the extent that they contribute to the error. I.e:
W new = Old - (dW * W old)
dW is the calculated “general” weighting correction, which is then distributed over each weight.
The book provided a formula for adjusting the weights for a two-layer network, I adapted it for a single-layer one. I will not give this formula here, in the article, in essence, this is the very “golden coin” and the heart of the whole method, without which all talk of neural networks turns into idle talk and cheap populism of Internet articles telling to quickly “master” neural networks and in half an hour to become an “expert” in them. Agree, it is better, after all, "to be" than to "seem." Therefore, if you are really interested in neural networks, I recommend that you study this book.
Wow! - Now you can erase the sweat from your forehead and proceed to the actual training and testing of the network ... True, we still need a small toolkit to assess the quality of its work, but I will tell about this in 3 parts of the article.
The end of the second part.
Source: https://habr.com/ru/post/454694/
All Articles