Node.js Best Practices - Project Structure Tips

Hi, Habr! I present to you the adapted translation of the first chapter of " Node.js Best Practices " by Yoni Goldberg. A selection of recommendations for Node.js is available on github, it has almost 30 tons of stars, but has not been mentioned on Habré until now. I assume that this information will be useful, at least, for beginners.
1. Project Structure Tips
1.1 Structure your project by component
The worst mistake of large applications is the monolith architecture in the form of a huge code base with a large number of dependencies (spaghetti code), such a structure slows down the development of especially the introduction of new functions. Council - separate your code into separate components, for each component, select your own folder for the modules of the component. It is important that each module remains small and simple. In the "Details" section you can see examples of the correct structure of projects.
Otherwise: it will be difficult for developers to develop a product - adding new functionality and making changes to the code will be made slowly and have a high chance of breaking other dependent components. It is believed that if business units are not divided, then problems with scaling the application may occur.
detailed information
Single paragraph explanation
')
For applications of medium size and above, monoliths are really bad - one big program with many dependencies is just hard to understand, and often leads to spaghetti code. Even experienced programmers who know how to properly “prepare modules” spend a lot of effort on architecture design and try to carefully evaluate the consequences of each change in the connections between objects. The best option is an architecture based on a set of small component programs: divide the program into separate components that do not share their files with anyone, each component should consist of a small number of modules (for example, modules: API, service, database access, testing etc.) so that the structure and composition of the components are obvious. Some may call this architecture “microservice”, but it is important to understand that microservices are not a specification that you should follow, but rather a set of some principles. At your request, you can adopt both individual of these principles and all the principles of microservice architecture. Both methods are good if you keep code complexity low.
The least you have to do is define the boundaries between the components: assign a folder in the root of your project to each of them and make them autonomous. Access to the functional components should be implemented only through a public interface or API. This is the foundation for keeping your components simple, avoiding dependency hell and letting your application grow to full-fledged microservices.
Quote of the blog: "Scaling requires scaling the entire application"
From the blog MartinFowler.com
Quote of the blog: "What does the architecture of your application say?"
From blog uncle-bob
So what is the architecture of your application talking about? When you look at the structure of top-level directories and the file modules in them, they say: I am an online store, I am bookkeeping, I am a production management system? Or do they shout: I'm Rails, I'm Spring / Hibernate, I'm ASP.
(Translator's Note, Rails, Spring / Hibernate, ASP are frameworks and web technologies).
Proper project structure with stand-alone components
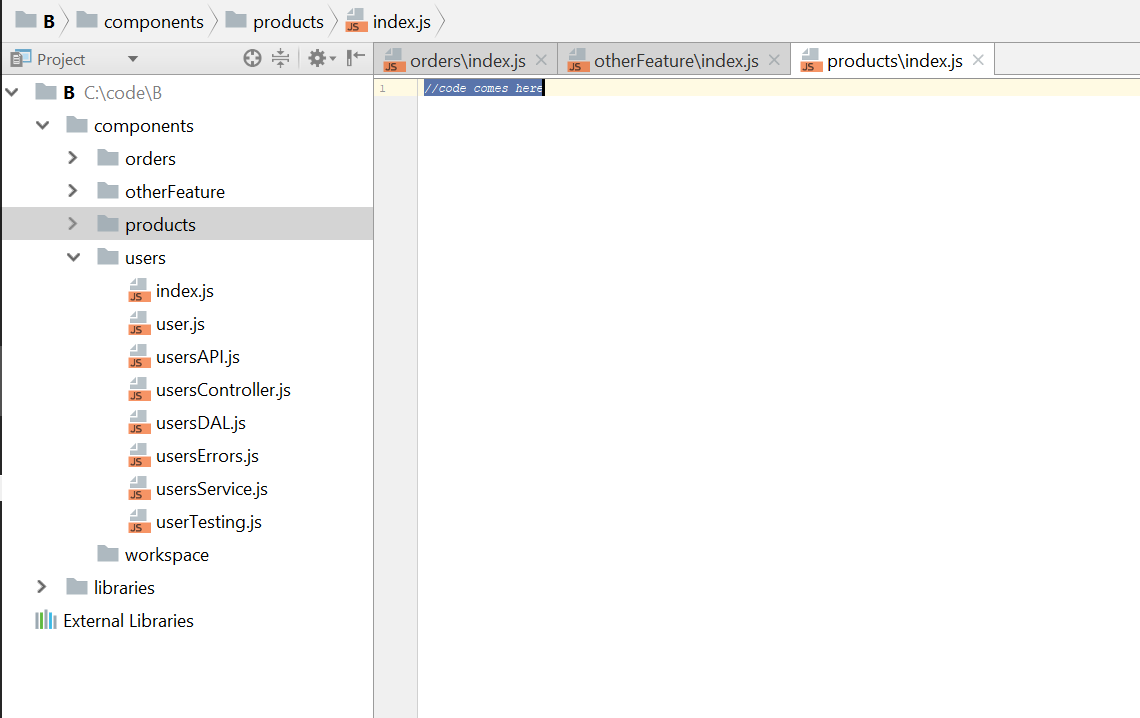
Incorrect project structure with grouping files according to their purpose.

')
For applications of medium size and above, monoliths are really bad - one big program with many dependencies is just hard to understand, and often leads to spaghetti code. Even experienced programmers who know how to properly “prepare modules” spend a lot of effort on architecture design and try to carefully evaluate the consequences of each change in the connections between objects. The best option is an architecture based on a set of small component programs: divide the program into separate components that do not share their files with anyone, each component should consist of a small number of modules (for example, modules: API, service, database access, testing etc.) so that the structure and composition of the components are obvious. Some may call this architecture “microservice”, but it is important to understand that microservices are not a specification that you should follow, but rather a set of some principles. At your request, you can adopt both individual of these principles and all the principles of microservice architecture. Both methods are good if you keep code complexity low.
The least you have to do is define the boundaries between the components: assign a folder in the root of your project to each of them and make them autonomous. Access to the functional components should be implemented only through a public interface or API. This is the foundation for keeping your components simple, avoiding dependency hell and letting your application grow to full-fledged microservices.
Quote of the blog: "Scaling requires scaling the entire application"
From the blog MartinFowler.com
Monolithic applications can be successful, but people are increasingly frustrated with them, especially when they are thinking about deploying to the cloud. Any, even small, changes in the application require the assembly and re-laying of the entire monolith. It is often difficult to constantly maintain a good modular structure, in which changes in one module do not affect others. Scaling requires scaling the entire application, and not just its individual parts, of course, this approach requires more effort.
Quote of the blog: "What does the architecture of your application say?"
From blog uncle-bob
... if you have been to the library, then you can imagine its architecture: the main entrance, reception desks, reading rooms, conference rooms and many rooms with bookshelves. The architecture itself will say: this building is a library.
So what is the architecture of your application talking about? When you look at the structure of top-level directories and the file modules in them, they say: I am an online store, I am bookkeeping, I am a production management system? Or do they shout: I'm Rails, I'm Spring / Hibernate, I'm ASP.
(Translator's Note, Rails, Spring / Hibernate, ASP are frameworks and web technologies).
Proper project structure with stand-alone components
Incorrect project structure with grouping files according to their purpose.
1.2 Separate the layers of your components and do not mix them with the Express data structure.
Each of your components must have “layers”, for example, to work with the web, business logic, access to the database, these layers must have their own data format not mixed with the data format of third-party libraries. This not only clearly separates the problems, but also greatly facilitates the verification and testing of the system. Often, API developers mix layers by passing Express web layer objects (for example, req, res) into business logic and data layer — this makes your application dependent and strongly related to Express.
Otherwise: for an application in which the objects of the layers are mixed, it is more difficult to ensure the testing of the code, the organization of CRON tasks and other non-Express calls.
detailed information
Split component code into layers: web, services, and DAL
The reverse side of the mixture of layers in one gif-animation

The reverse side of the mixture of layers in one gif-animation
1.3 Wrap your basic utilities in npm packages
In a large application consisting of various services with their own repositories, such universal utilities as logger, encryption, etc., should be wrapped with your own code and presented as private npm packages. This allows you to share them between multiple code bases and projects.
Otherwise: you will have to invent your own bike to share this code between separate code bases.
detailed information
Single paragraph explanation
As soon as the project starts to grow and you have different components on different servers using the same utilities, you should start managing dependencies. How can you allow multiple components to use it without duplicating your utility code between repositories? For this there is a special tool, and it is called - npm .... Start by wrapping third-party utility packages with your own code so that it can be easily replaced in the future, and publish this code as a private npm package. Now your entire codebase can import utility code and use all the npm dependency management features. Remember that there are the following ways to publish npm packages for personal use without opening them for public access: private modules , private registry or local npm packages .
Sharing your own common utilities in different environments
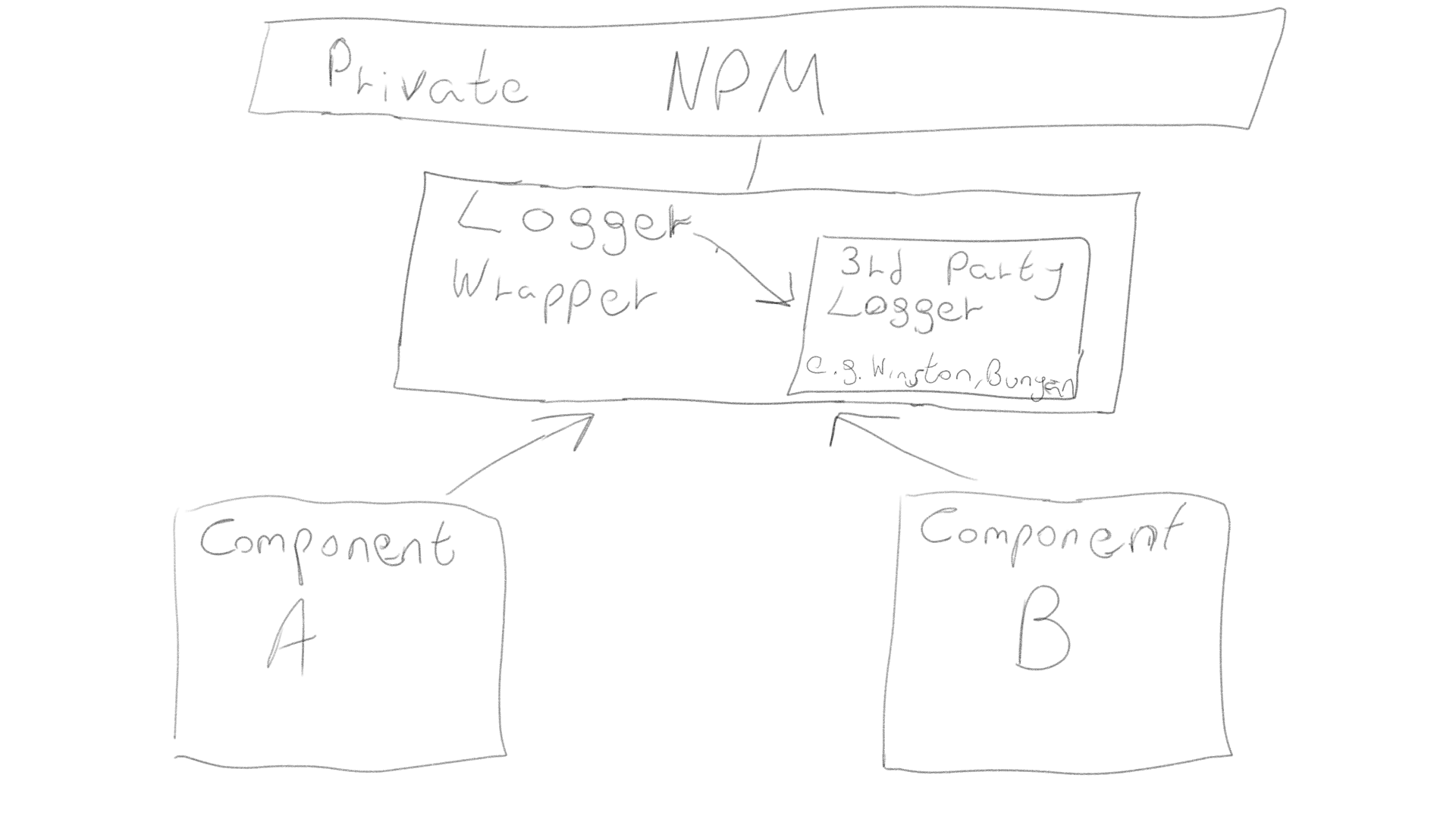
As soon as the project starts to grow and you have different components on different servers using the same utilities, you should start managing dependencies. How can you allow multiple components to use it without duplicating your utility code between repositories? For this there is a special tool, and it is called - npm .... Start by wrapping third-party utility packages with your own code so that it can be easily replaced in the future, and publish this code as a private npm package. Now your entire codebase can import utility code and use all the npm dependency management features. Remember that there are the following ways to publish npm packages for personal use without opening them for public access: private modules , private registry or local npm packages .
Sharing your own common utilities in different environments
1.4 Split Express into “application” and “server”
Avoid the unpleasant habit of defining the entire Express application in one huge file, divide your 'Express' code into at least two files: the API declaration (app.js) and the www server code. For even better structure, place the API declaration in component modules.
Otherwise: your API will be available for testing only via HTTP calls (which is slower and much more difficult to create coverage reports). Still, I suppose it's not too much fun to work with hundreds of lines of code in one file.
detailed information
Single paragraph explanation
We recommend using the Express application generator and its approach to building an application database: the API declaration is separated from the server configuration (port data, protocol, etc.). This allows you to test the API without making network calls, which speeds up testing and makes it easier to get code coverage metrics. It also allows you to flexibly deploy the same API for different server network settings. Bonus you also get a better division of responsibility and a cleaner code.
Example code: API declaration, must be in app.js
Example code: server network settings, must be in / bin / www
Example: test your API using supertest (popular testing package)
We recommend using the Express application generator and its approach to building an application database: the API declaration is separated from the server configuration (port data, protocol, etc.). This allows you to test the API without making network calls, which speeds up testing and makes it easier to get code coverage metrics. It also allows you to flexibly deploy the same API for different server network settings. Bonus you also get a better division of responsibility and a cleaner code.
Example code: API declaration, must be in app.js
var app = express(); app.use(bodyParser.json()); app.use("/api/events", events.API); app.use("/api/forms", forms); Example code: server network settings, must be in / bin / www
var app = require('../app'); var http = require('http'); /** * Express. */ var port = normalizePort(process.env.PORT || '3000'); app.set('port', port); /** * HTTP-. */ var server = http.createServer(app); Example: test your API using supertest (popular testing package)
const app = express(); app.get('/user', function(req, res) { res.status(200).json({ name: 'tobi' }); }); request(app) .get('/user') .expect('Content-Type', /json/) .expect('Content-Length', '15') .expect(200) .end(function(err, res) { if (err) throw err; }); 1.5 Use secure hierarchical configuration with environment variables
The ideal configuration setting should provide:
(1) reading keys from both the configuration file and environment variables,
(2) storing secrets outside the repository code,
(3) a hierarchical (rather than a flat) data structure of the configuration file to facilitate the work with the settings.
There are several packages that can help with the implementation of these items, such as: rc, nconf and config.
Otherwise: failure to comply with these configuration requirements will lead to a breakdown in the work of both the individual developer and the entire team.
detailed information
Single paragraph explanation
When you deal with configuration settings, many things can annoy and slow down your work:
1. Setting all parameters using environment variables becomes very tedious if you need to enter 100+ keys (instead of simply storing them in the configuration file), however, if the configuration is specified only in the configuration files, this can be inconvenient for DevOps. A reliable configuration solution should combine both ways: both configuration files and parameter overrides from environment variables.
2. If the configuration file is “flat” JSON (i.e., all keys are written as a single list), then increasing the number of settings will make it difficult to work with it. This problem can be solved by forming nested structures containing groups of keys according to settings sections, i.e. organize a hierarchical JSON data structure (see example below). There are libraries that allow you to store such a configuration in several files and merge data from them at runtime.
3. It is not recommended to store confidential information (such as the database password) in configuration files, but there is no definitive, convenient solution where and how to store such information. Some configuration libraries allow you to encrypt configuration files, others encrypt these records during git commits, and you can not save secret parameters in files at all and set their values during deployment through environment variables.
4. Some advanced configuration scenarios require entering keys via the command line (vargs) or synchronizing configuration data through a centralized cache, such as Redis, so that multiple servers use the same data.
There are npm libraries that will help you with the implementation of most of these recommendations, we advise you to look at the following libraries: rc , nconf and config .
Example code: a hierarchical structure helps to find records and work with large configuration files
(Translator's note, comments cannot be used in a classic JSON file. The above example is taken from the documentation of the config library, which added the functionality of pre-clearing JSON files from comments. Therefore, the example is quite working, but linters, such as ESLint, with default settings can "Swear" on a similar format).
When you deal with configuration settings, many things can annoy and slow down your work:
1. Setting all parameters using environment variables becomes very tedious if you need to enter 100+ keys (instead of simply storing them in the configuration file), however, if the configuration is specified only in the configuration files, this can be inconvenient for DevOps. A reliable configuration solution should combine both ways: both configuration files and parameter overrides from environment variables.
2. If the configuration file is “flat” JSON (i.e., all keys are written as a single list), then increasing the number of settings will make it difficult to work with it. This problem can be solved by forming nested structures containing groups of keys according to settings sections, i.e. organize a hierarchical JSON data structure (see example below). There are libraries that allow you to store such a configuration in several files and merge data from them at runtime.
3. It is not recommended to store confidential information (such as the database password) in configuration files, but there is no definitive, convenient solution where and how to store such information. Some configuration libraries allow you to encrypt configuration files, others encrypt these records during git commits, and you can not save secret parameters in files at all and set their values during deployment through environment variables.
4. Some advanced configuration scenarios require entering keys via the command line (vargs) or synchronizing configuration data through a centralized cache, such as Redis, so that multiple servers use the same data.
There are npm libraries that will help you with the implementation of most of these recommendations, we advise you to look at the following libraries: rc , nconf and config .
Example code: a hierarchical structure helps to find records and work with large configuration files
{ // Customer module configs "Customer": { "dbConfig": { "host": "localhost", "port": 5984, "dbName": "customers" }, "credit": { "initialLimit": 100, // Set low for development "initialDays": 1 } } } (Translator's note, comments cannot be used in a classic JSON file. The above example is taken from the documentation of the config library, which added the functionality of pre-clearing JSON files from comments. Therefore, the example is quite working, but linters, such as ESLint, with default settings can "Swear" on a similar format).
Afterword from the translator:
- In the project description it is written that the Russian translation has already been launched, but I did not find this translation there, so I took up the article.
- If the translation seems very brief to you, then try to expand the detailed information in each section.
- Sorry that the illustrations are left without translation.
Source: https://habr.com/ru/post/454476/
All Articles