Life to runtime. Yandex report
In a large project, the task of identifying changes for the end user by the differences in the frontend code of the application may arise. Nikita Sidorov, a developer from Yandex.Market, described how we solved this problem using the Diffector library, about building and analyzing the module graph in Node.js applications, and about finding defects in the code before it starts.

- Today I will try to be as frank as possible. I have been working at Yandex.Market for a little more than a year and a half. I do the web as much, and I began to notice changes in myself, you can also notice them. My average hair length increased and my beard began to appear. And you know, today I looked at my colleagues: veged at Sergey Berezhnoy, at Grinenko tadatuta at Vova, and I realized that this is a good criterion for me to have almost matured as a real front-end developer.
')
And coming to this motherhood, I decided to talk with you about life, about the one in which we all participate. Basically - about life to runtime. Now I will explain what all this will be about.

What about life? About the life of the code, of course. The code is what we do with you. Let me remind you, I decided to be sincere with you here, so the first slide was as simple as possible. I took the truism, the first stage is adoption, agree that no one will argue with this axiom.

And then I realized that I would have to refine, but so that it was clear. Let it be some kind of acceptance of the requirements. Any code begins with the fact that you look at the task and try to accept the requirements that you put.

After this, we, of course, begin the stage of writing - we write our code. Then we cover it with tests, we check its effectiveness ourselves. After that, we already check whether our application works with our code entirely. After that, we give the tester - let him check. What do you think after that? I remind you, life is up to runtime. Should this runtime be what you think? Actually goes like this. And this is not a mistake in the presentation. Very often at any stage of inspections - and there may be a lot more of them than I indicated - you may have some goto call again to writing. Agree, this can be a pretty big problem. This can slow down the delivery of some feature in production and, in principle, slow you down as a developer, because the ticket will be on you. And here it all passes, passes. There are still some M times N checks, and only then the code gets to the user in the browser. But this is our goal. Our goal is to write code that will actually be available to the user and will really work for his benefit.
Today we will talk about the first part. About what happens before, but not quite about the tests.

It looks, by the way, something like this. I took our turn in the tracker, collected my own, counted the median. It turns out that my tickets are much less in development than in verification. And as you understand, the longer it takes to check, the higher the chance that either a goto to the beginning or a goto will appear at the end - and you don’t want this at all.
And also, if you pay attention, there are two words on the slide here - development (we, the developers) and verification (including us, but also the testers). Therefore, the problem is relevant, in fact, for testers.

The goal is quite prosaic. In general, I like to say that life should be simplified: we work a lot with you already. The goal looks something like this, but agree that it is rather ephemeral, so let's highlight some basic criteria on what the goal may depend.
Of course, the smaller the code, the easier it is for us. The faster we have CI checks, the sooner we will understand whether we are right or not. That is, locally, it can generally run forever. Test speed - this refers directly to the tester. If we have a large application and need to be checked in its entirety, this is a huge amount of time. The release speed depends on all of this. Including it is impossible to release until we have passed all the checks, and until we understand that the code is exactly the one we want.
To solve a part of the problems we are talking about, let's analyze the dependency graph of modules in our programming language. And, actually, let's describe it.

Graph oriented: it has edges with directions. In the nodes of the graph, we will have the modules of the language we are talking about. Edges are a certain type of connection. There are several types of communication.
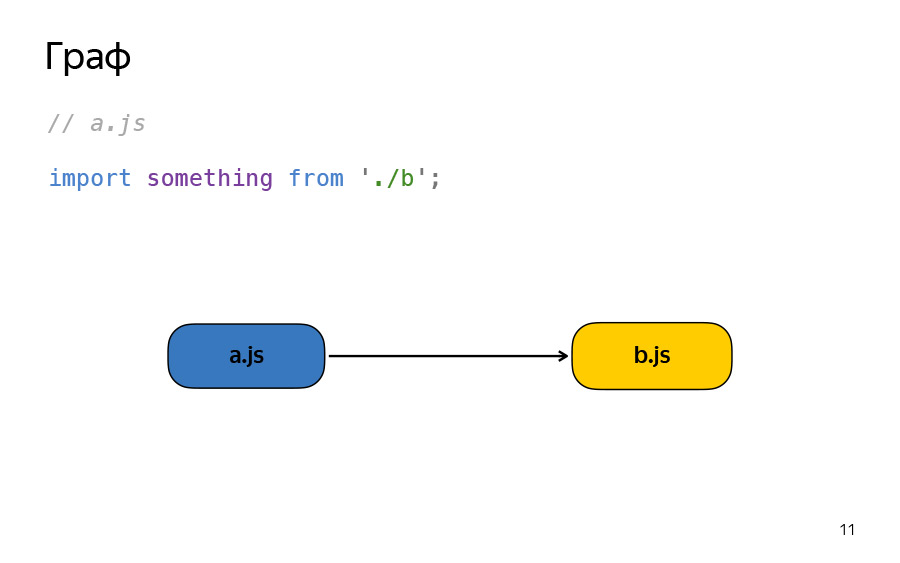
Let's look at a commonplace example. There is a file A. Here it is importing something from file B into it, and this is such a dependency between nodes.

The same will happen if you replace import with require. In fact, everything is not so simple.
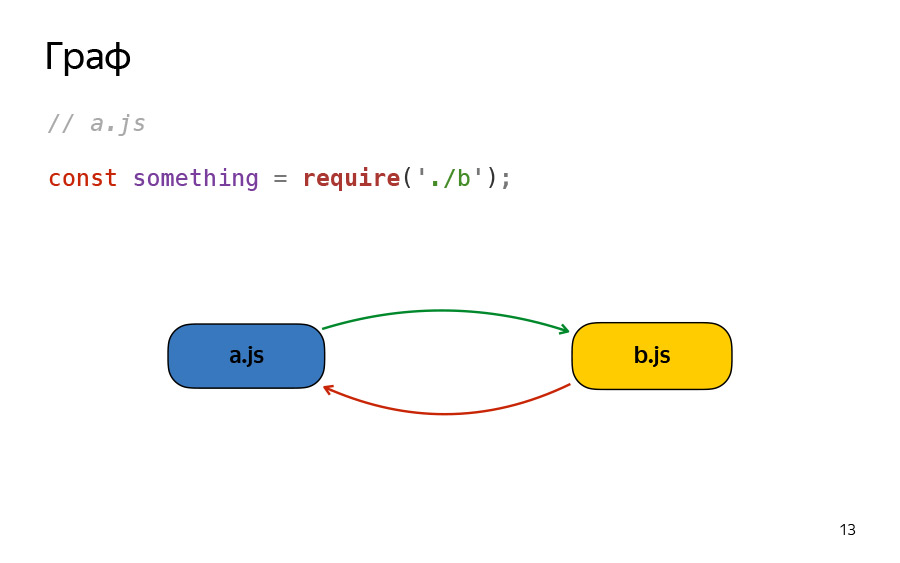
I suggest, since we are talking about the type of dependence, consider two types at least - to speed up your pipeline, to speed up the bypass of the graph. It is necessary to look not only dependent module, but also dependent. I propose to call the module A - the parent, B - the child, and I advise you to keep the links always as a double linked list. This will simplify your life, I inform you in advance.
Once we have described the graph, let's agree how we will build it.

There are two ways. Or your favorite tool in your favorite programming language using the same AST (abstract syntax trees) or regulars. What is the profit here? The fact that here you are not tied to anyone, but at the same time you have to implement everything yourself. You will have to describe all types of links of all those things and technologies that you use, whether it is a separate CSS builder, something else like that. But you have full freedom of flight, so to speak.
In addition, the second option, I will also promote it a little bit, this is an option for most people who already have an assembly system set up. The fact is that the build system collects the graph depending on the design, by default.

Let's take a look at one of Yandex’s most favorite build systems, this is a webpack. Here I gave an example of how to collect the entire result of the webpack in a separate file, which you can then feed to ours or some other analyzers. He collects it with the help of AST, the acorn library is used. You could notice her when something fell over you. I have noticed.
And what are the advantages. The fact is that when you describe your build system, you absolutely honestly set the entry. These are the files from which your dependencies spin up, the starting points of the detour. This is good, because you do not have to write them again. In addition, webpack and babel, and all this, and acorn, including, it is still not your maintener. And therefore, all sorts of new features of the language, all sorts of bugs and everything else, are corrected faster than if you did it, especially if you have a not very big team. Yes, even if large, it is also not as large as open source.
This is a plus and a minus, in fact. It is like such a double edge (double-edged sword) is obtained. The fact is that this graph is built during assembly. It’s as if it’s good, that is, we can build the project and immediately reuse the result of the assembly. But what if we don’t want to build a project, but just want to get this graph?
And such a major drawback, in fact. If you have any custom things connected, we will talk now much later about the connections, then the assembly system will not allow you to do this. Or, you will have to integrate it, such as your webpack plugin.

Consider a specific example. I executed the command on my project, where there are only three files, and received such output. And this I only show one key, which is called modules. We are just talking about the dependency graph of modules, so we are looking at the modules, everything is logical.

Quite a lot of information, but we don’t need everything. Let's leave some points and let's talk them over. Suppose we consider the first module. He has a name, there are reasons. The reasons are precisely the connection, in fact, “dependent” modules, it turns out those who import this module to themselves. This is the basic data to build a graph on them.

In addition, please pay attention to usedExports and providedExports. We will talk about them later. But these are also very important things.

And if you describe your solution, you need to talk about the types of connections that exist between modules. That is, we have, of course, our system of modules within our language: whether it be cjs modules, or esm modules. In addition, agree that we may have a connection between files in the file system at the level of the file system itself. These are some kind of frameworks: some kind of framework is going to, depending on how the daddy lie.
And such a banal example - if you wrote the server part of Node, then quite often you could see such a popular npm-package as Config. It allows you to quite conveniently determine your configurations.

To use it, you need to have a daddy config, where you have NODE_PATH, and specify several JavaScript files - just to show the config there for different environments. As an example - I created a daddy, specified default, development and production.

And, in fact, the whole config works like this. That is, when you write require ('config'), it simply reads the module you need inside yourself and takes the module name from a variable environment. As you understand, it was not clear there that these files are used somehow, because there is no direct import / require, the webpack would not even recognize it.

Today they also talked about Dependency Injection. I am not what was inspired, but in support I reviewed one of the libraries here. It is called inversify js. As you can see, it provides a pretty custom syntax: lazyInject, nameProvider, and this is all. And, you see, here it is not clear what kind of provider, what kind of module is injected here. And we need it, and we have to understand it. That is, again, the assembly system will not be solved, and we will have to do it ourselves.
Suppose that we have built a graph, and I suggest that you start by storing it somewhere. What will it allow us to do? This will allow us to do some kind of heuristic analysis, play Data Science a little bit, and make it, focusing on a time slice.

What is the idea? Here, indeed, right our data. We recently just implemented our design system in Yandex.Market, including, among other things, linking the library components as part of this design system. And here you can see: we count the number of imports, the reactor component from our library, the total component. And you can distribute the directories. In this case, we have such a non-repository, and therefore we have platform.desktop, platform.touch and src.
What can we think when we see these numbers? We can hypothesize that the touch command, it does not seem to increase the use of common components. This means that either the components are bad for mobile are badly done, or the touch command is lazy. But is it really?
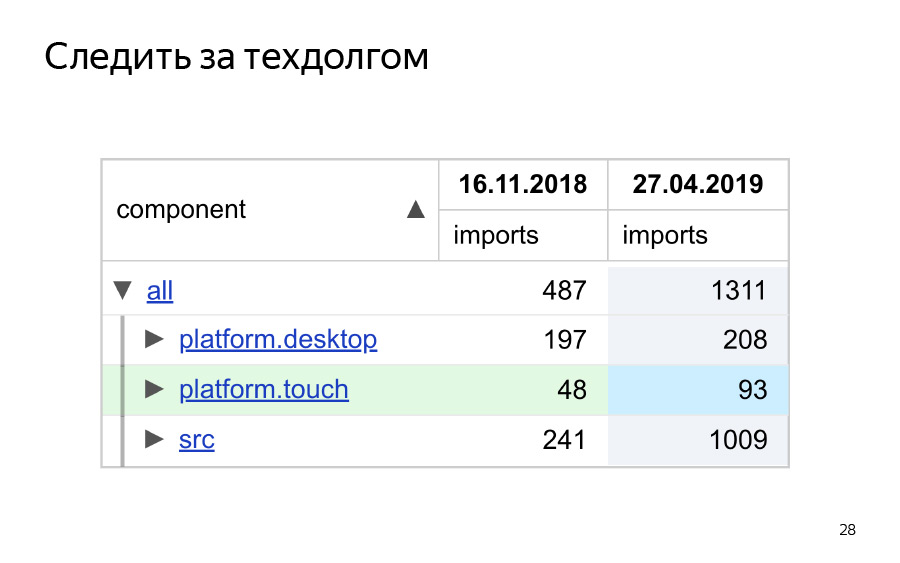
If we look at a longer period, a longer time slice, it allows us to do just the storage of graphs after each release, then we understand that, in fact, for touch everything is OK, the indicator grows in it. For src is even better, for desktop, it turns out, no.

There was also a question from the audience about how to explain the importance of managers. Here, the total number of imports of the library, also in terms of time. What kind of managers don't like graphics? You can build such a graph and see that the use of the library is growing, which means that it is at least a useful thing.
One of my favorite parts. I will cover it rather briefly. This is a search for defects in the graph. Today I wanted to talk to you about two types of defects: this is a cyclic dependence of the modules and an unused module of some kind, that is, a dead code elimination problem.

Let's start with cyclical dependency.

Here, it seems, everything is quite simple. You already have a directed graph, you just need to find a cycle there. Let me explain why I'm talking about this. The fact is that before I wrote, basically, the server part on Node.js, and we did not use, in principle, no webpack / babel, nothing. That is, run as is. And there was require. Who remembers the difference between import and require? All right If you have written the code badly, and I really did it, you can find out on your server that your module is in some kind of circular dependency only when some request comes from users, or some event still works. That is, it turns out quite a global problem. To runtime do not understand. That is, import is much better, there will be no such problem.

Here you just take any algorithm you like. Here I took a fairly simple algorithm. We must find a vertex that has only one type of edge, either incoming or outgoing. If there is such a vertex, we delete it, delete the edges, and, in fact, continue this process, we will find and prove that in this graph there was a five-cycle cycle.
Agree, if you looked at it by the code, that is, there a cycle of two or three can still be found, but more is unrealistic, and we actually had a cycle of seven in the project, but not in production.
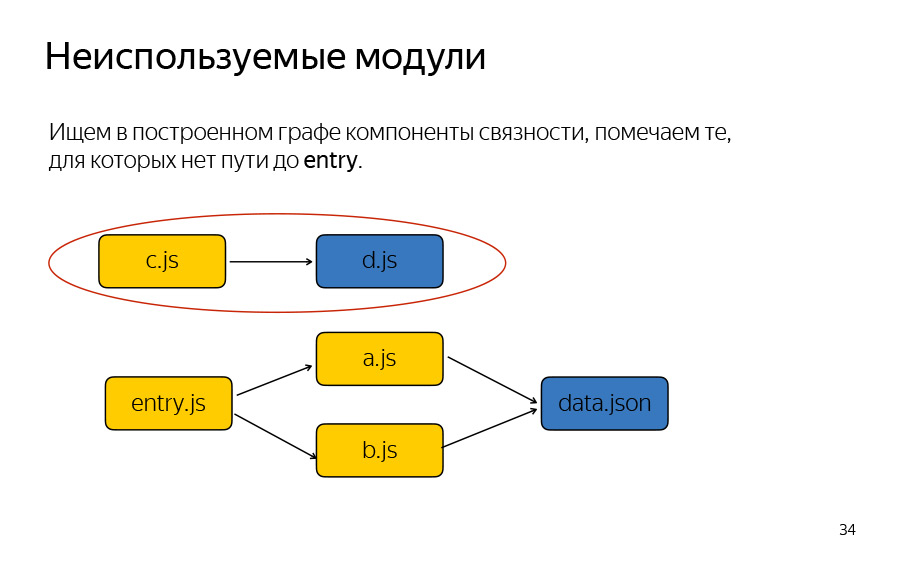
About unused modules. This is also a rather trivial algorithm. We need to highlight the connected components in our graph, and just look, find those components that do not include any of the entry nodes. In this case, this is this component of connectedness, both vertices, it turns out, both nodes. I called entry.js here. Actually, no matter what it is called, this is what you have described in the config of the entry assembly is meant.

But there is another approach. If you did not collect the graph, and you just have an assembly system, then how is it the cheapest thing to do? Let's just mark all the files that are in the assembly during the build. Tag them and create lots. After that we have to get a lot of all the files that you have in the project, and just subtract them. That is very simple operations.

And here I am not just telling you something theoretical, I was inspired, came to my project, and did this. And attention! I didn't even delete node_modules. This I left as a growth point for the next review. And, in short, I was so inspired by myself that I decided to somehow do this slide, re-arrange it. Let it look like this, because it's really cool!
Good numbers, can you imagine how everything became good? And then I was driven into such a steppe that I felt like a designer, and I thought that this is an achievement that I would like to add to the frame. And, as you understand, I got up, looked and realized that I’m rather not a designer, but, really, a web developer. But I'm not a fool. I took this frame, added to my site to SEO-amulets.
You can use, even the link is there. And lest you think that I am deceiving you - we are frank today - I really looked at the reviews. I think you can believe them.
Well, to be honest, it looked something like this. I saw a new hyos library thanos-js, picked up, created a pull request. In secret, I have administrator rights in our repository. And I took and demoted the master. How do you like that? Well, we are frank with you, and, in fact, it all looked like this. If anyone does not know, thanos-js is a library that simply deletes 50% of your code randomly.
In fact, I still used the library there, but the library is called differently. She is called diffector, and now we'll talk about it with you. And here I would like to note that the pull request is quite significant, minus 44 thousand lines of code, and you can imagine that it was tested the first time. That is what I am talking about, really can work.

Diffector. In fact, he is engaged not only in the task of removing unused modules, finding defects in a graph, but also in a more important task. What I initially declared was to help the developer and tester, now this will be discussed. And it works like this.
We get a list of changed files using a version control system. We have already built a graph - diffector builds it. And for each such modified file, we look for the path to entry and mark the modified entry. And the entry we will have to correspond with the pages of applications that the user sees. But it is quite logical.
And what does this give us? For testing, we know which pages in the application have changed. We can tell the tester that we only need to test them. We can also tell our ci-job, which runs auto-tests, that only these pages should be tested. And for developers, everything is much simpler, because now testers do not write to you and do not ask: “Why should we test?”
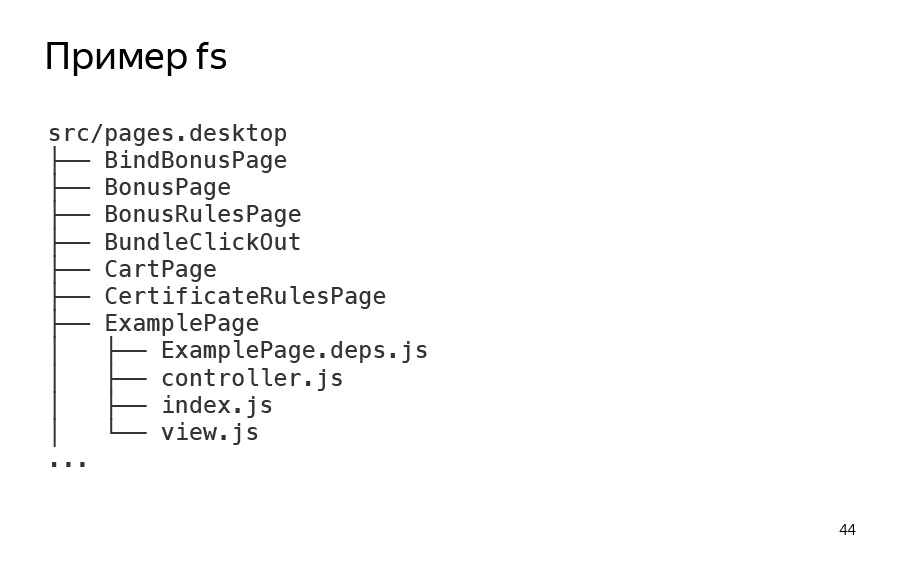
Let's look at an example of how diffector works. Here we have a certain directory, pages.desktop / *. It contains just a list of the pages themselves. And the pages are also described in several files. The controller is the server part of the page. View - some react-part. And deps, this is from another build system. We have not only webpack, but also ENB.

And I made some changes to the project, to an empty file whose structure you saw. This is what the diffector gives me. I just ran it, diffector is a command line application. I launched it, it tells me that I have changed one page called BindBonusPage.

I can also run it in verbose mode, see a more detailed report, and, indeed, see that it at least works in such a simple case. As we can see, in our BindBonusPage the index file and the controller have changed.
But let's see what happens if we change something else.

I changed something else. And the diffector told me that I have changed nine pages. And now this does not please me, no matter how much he helped me.
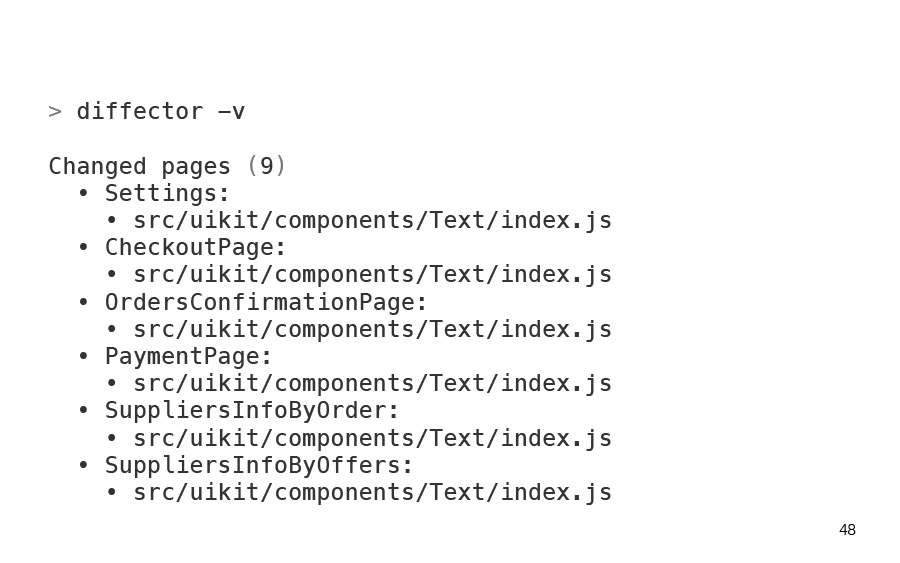
, ? , . , . - uikit.
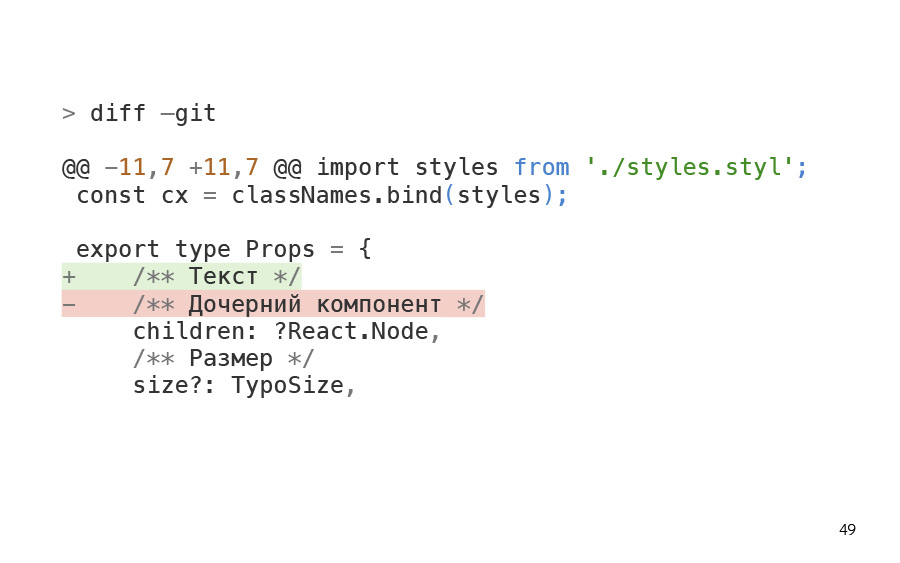
diff. . , diffector . , - , .

, , . , , entry, , , test-scope, . .
. , , , , .

. - , . — i18n, , . , , , . , , - .
? , , , , , .

- . , B , , -2 . . , esm.

.

.

, value, . , , . , .
, AST, , 250 , , . , , - , , .

, - GlobalContext - , . , modify, , ? , - GlobalContext. . . , side effects. , , webpack, , . , webpack sideEffects: true, . .

, - - . , . diffector, . , , . — , . , .
, , diff, expand, log, , , , .
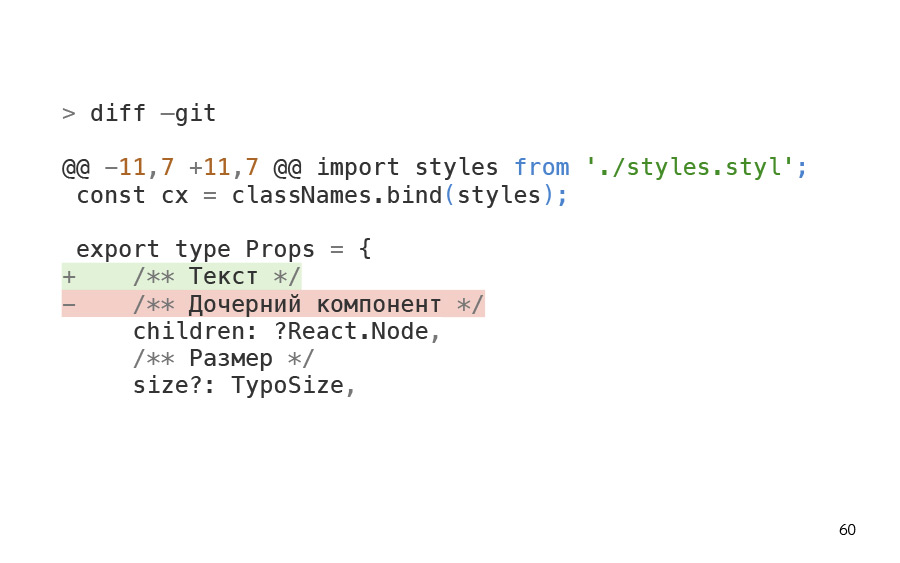
, . D, diff. , , , . , , . , , . .
, , . . . , — , . . . , , , , , . . , .
— diffector ? , , , .

- , , .

, , entry. entry. diffector.

. -. , .

, entry -, .

. diffector. . , , - , -. , . : , BindBonusPage, -, . . , , - . .


— CI. . : , , .
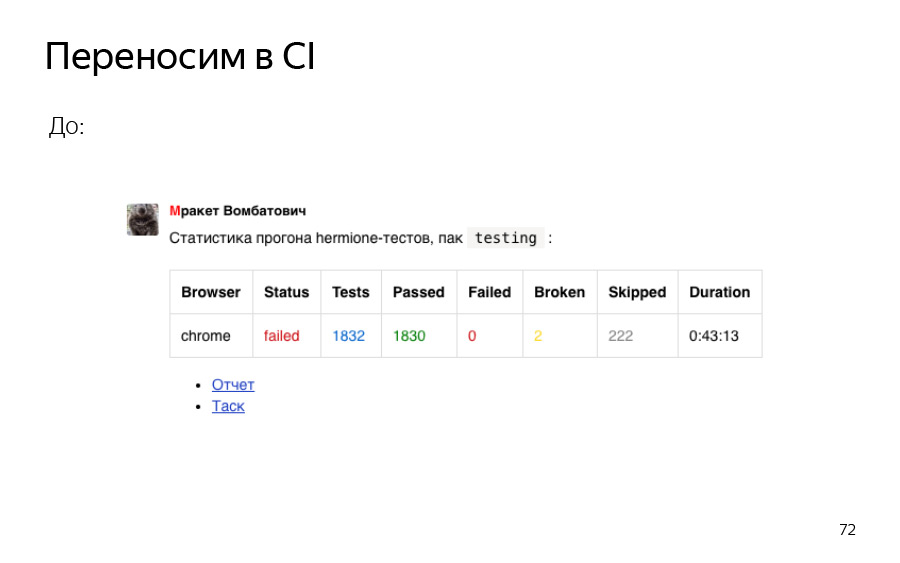
, . 43 — testing, , .

. , , .

, . : , , . , , , , , . , , - .

. , , , . - , - , , , . .
, , , output . , . — . — . Thank!
- Today I will try to be as frank as possible. I have been working at Yandex.Market for a little more than a year and a half. I do the web as much, and I began to notice changes in myself, you can also notice them. My average hair length increased and my beard began to appear. And you know, today I looked at my colleagues: veged at Sergey Berezhnoy, at Grinenko tadatuta at Vova, and I realized that this is a good criterion for me to have almost matured as a real front-end developer.
')
And coming to this motherhood, I decided to talk with you about life, about the one in which we all participate. Basically - about life to runtime. Now I will explain what all this will be about.
What about life? About the life of the code, of course. The code is what we do with you. Let me remind you, I decided to be sincere with you here, so the first slide was as simple as possible. I took the truism, the first stage is adoption, agree that no one will argue with this axiom.
And then I realized that I would have to refine, but so that it was clear. Let it be some kind of acceptance of the requirements. Any code begins with the fact that you look at the task and try to accept the requirements that you put.
After this, we, of course, begin the stage of writing - we write our code. Then we cover it with tests, we check its effectiveness ourselves. After that, we already check whether our application works with our code entirely. After that, we give the tester - let him check. What do you think after that? I remind you, life is up to runtime. Should this runtime be what you think? Actually goes like this. And this is not a mistake in the presentation. Very often at any stage of inspections - and there may be a lot more of them than I indicated - you may have some goto call again to writing. Agree, this can be a pretty big problem. This can slow down the delivery of some feature in production and, in principle, slow you down as a developer, because the ticket will be on you. And here it all passes, passes. There are still some M times N checks, and only then the code gets to the user in the browser. But this is our goal. Our goal is to write code that will actually be available to the user and will really work for his benefit.
Today we will talk about the first part. About what happens before, but not quite about the tests.
It looks, by the way, something like this. I took our turn in the tracker, collected my own, counted the median. It turns out that my tickets are much less in development than in verification. And as you understand, the longer it takes to check, the higher the chance that either a goto to the beginning or a goto will appear at the end - and you don’t want this at all.
And also, if you pay attention, there are two words on the slide here - development (we, the developers) and verification (including us, but also the testers). Therefore, the problem is relevant, in fact, for testers.
The goal is quite prosaic. In general, I like to say that life should be simplified: we work a lot with you already. The goal looks something like this, but agree that it is rather ephemeral, so let's highlight some basic criteria on what the goal may depend.
Of course, the smaller the code, the easier it is for us. The faster we have CI checks, the sooner we will understand whether we are right or not. That is, locally, it can generally run forever. Test speed - this refers directly to the tester. If we have a large application and need to be checked in its entirety, this is a huge amount of time. The release speed depends on all of this. Including it is impossible to release until we have passed all the checks, and until we understand that the code is exactly the one we want.
To solve a part of the problems we are talking about, let's analyze the dependency graph of modules in our programming language. And, actually, let's describe it.
Graph oriented: it has edges with directions. In the nodes of the graph, we will have the modules of the language we are talking about. Edges are a certain type of connection. There are several types of communication.
Let's look at a commonplace example. There is a file A. Here it is importing something from file B into it, and this is such a dependency between nodes.
The same will happen if you replace import with require. In fact, everything is not so simple.
I suggest, since we are talking about the type of dependence, consider two types at least - to speed up your pipeline, to speed up the bypass of the graph. It is necessary to look not only dependent module, but also dependent. I propose to call the module A - the parent, B - the child, and I advise you to keep the links always as a double linked list. This will simplify your life, I inform you in advance.
Once we have described the graph, let's agree how we will build it.
There are two ways. Or your favorite tool in your favorite programming language using the same AST (abstract syntax trees) or regulars. What is the profit here? The fact that here you are not tied to anyone, but at the same time you have to implement everything yourself. You will have to describe all types of links of all those things and technologies that you use, whether it is a separate CSS builder, something else like that. But you have full freedom of flight, so to speak.
In addition, the second option, I will also promote it a little bit, this is an option for most people who already have an assembly system set up. The fact is that the build system collects the graph depending on the design, by default.
Let's take a look at one of Yandex’s most favorite build systems, this is a webpack. Here I gave an example of how to collect the entire result of the webpack in a separate file, which you can then feed to ours or some other analyzers. He collects it with the help of AST, the acorn library is used. You could notice her when something fell over you. I have noticed.
And what are the advantages. The fact is that when you describe your build system, you absolutely honestly set the entry. These are the files from which your dependencies spin up, the starting points of the detour. This is good, because you do not have to write them again. In addition, webpack and babel, and all this, and acorn, including, it is still not your maintener. And therefore, all sorts of new features of the language, all sorts of bugs and everything else, are corrected faster than if you did it, especially if you have a not very big team. Yes, even if large, it is also not as large as open source.
This is a plus and a minus, in fact. It is like such a double edge (double-edged sword) is obtained. The fact is that this graph is built during assembly. It’s as if it’s good, that is, we can build the project and immediately reuse the result of the assembly. But what if we don’t want to build a project, but just want to get this graph?
And such a major drawback, in fact. If you have any custom things connected, we will talk now much later about the connections, then the assembly system will not allow you to do this. Or, you will have to integrate it, such as your webpack plugin.
Consider a specific example. I executed the command on my project, where there are only three files, and received such output. And this I only show one key, which is called modules. We are just talking about the dependency graph of modules, so we are looking at the modules, everything is logical.
Quite a lot of information, but we don’t need everything. Let's leave some points and let's talk them over. Suppose we consider the first module. He has a name, there are reasons. The reasons are precisely the connection, in fact, “dependent” modules, it turns out those who import this module to themselves. This is the basic data to build a graph on them.
In addition, please pay attention to usedExports and providedExports. We will talk about them later. But these are also very important things.
And if you describe your solution, you need to talk about the types of connections that exist between modules. That is, we have, of course, our system of modules within our language: whether it be cjs modules, or esm modules. In addition, agree that we may have a connection between files in the file system at the level of the file system itself. These are some kind of frameworks: some kind of framework is going to, depending on how the daddy lie.
And such a banal example - if you wrote the server part of Node, then quite often you could see such a popular npm-package as Config. It allows you to quite conveniently determine your configurations.
To use it, you need to have a daddy config, where you have NODE_PATH, and specify several JavaScript files - just to show the config there for different environments. As an example - I created a daddy, specified default, development and production.
And, in fact, the whole config works like this. That is, when you write require ('config'), it simply reads the module you need inside yourself and takes the module name from a variable environment. As you understand, it was not clear there that these files are used somehow, because there is no direct import / require, the webpack would not even recognize it.
Link from the slide
Today they also talked about Dependency Injection. I am not what was inspired, but in support I reviewed one of the libraries here. It is called inversify js. As you can see, it provides a pretty custom syntax: lazyInject, nameProvider, and this is all. And, you see, here it is not clear what kind of provider, what kind of module is injected here. And we need it, and we have to understand it. That is, again, the assembly system will not be solved, and we will have to do it ourselves.
Suppose that we have built a graph, and I suggest that you start by storing it somewhere. What will it allow us to do? This will allow us to do some kind of heuristic analysis, play Data Science a little bit, and make it, focusing on a time slice.
What is the idea? Here, indeed, right our data. We recently just implemented our design system in Yandex.Market, including, among other things, linking the library components as part of this design system. And here you can see: we count the number of imports, the reactor component from our library, the total component. And you can distribute the directories. In this case, we have such a non-repository, and therefore we have platform.desktop, platform.touch and src.
What can we think when we see these numbers? We can hypothesize that the touch command, it does not seem to increase the use of common components. This means that either the components are bad for mobile are badly done, or the touch command is lazy. But is it really?
If we look at a longer period, a longer time slice, it allows us to do just the storage of graphs after each release, then we understand that, in fact, for touch everything is OK, the indicator grows in it. For src is even better, for desktop, it turns out, no.
There was also a question from the audience about how to explain the importance of managers. Here, the total number of imports of the library, also in terms of time. What kind of managers don't like graphics? You can build such a graph and see that the use of the library is growing, which means that it is at least a useful thing.
One of my favorite parts. I will cover it rather briefly. This is a search for defects in the graph. Today I wanted to talk to you about two types of defects: this is a cyclic dependence of the modules and an unused module of some kind, that is, a dead code elimination problem.
Let's start with cyclical dependency.
Here, it seems, everything is quite simple. You already have a directed graph, you just need to find a cycle there. Let me explain why I'm talking about this. The fact is that before I wrote, basically, the server part on Node.js, and we did not use, in principle, no webpack / babel, nothing. That is, run as is. And there was require. Who remembers the difference between import and require? All right If you have written the code badly, and I really did it, you can find out on your server that your module is in some kind of circular dependency only when some request comes from users, or some event still works. That is, it turns out quite a global problem. To runtime do not understand. That is, import is much better, there will be no such problem.
Here you just take any algorithm you like. Here I took a fairly simple algorithm. We must find a vertex that has only one type of edge, either incoming or outgoing. If there is such a vertex, we delete it, delete the edges, and, in fact, continue this process, we will find and prove that in this graph there was a five-cycle cycle.
Agree, if you looked at it by the code, that is, there a cycle of two or three can still be found, but more is unrealistic, and we actually had a cycle of seven in the project, but not in production.
About unused modules. This is also a rather trivial algorithm. We need to highlight the connected components in our graph, and just look, find those components that do not include any of the entry nodes. In this case, this is this component of connectedness, both vertices, it turns out, both nodes. I called entry.js here. Actually, no matter what it is called, this is what you have described in the config of the entry assembly is meant.
But there is another approach. If you did not collect the graph, and you just have an assembly system, then how is it the cheapest thing to do? Let's just mark all the files that are in the assembly during the build. Tag them and create lots. After that we have to get a lot of all the files that you have in the project, and just subtract them. That is very simple operations.
And here I am not just telling you something theoretical, I was inspired, came to my project, and did this. And attention! I didn't even delete node_modules. This I left as a growth point for the next review. And, in short, I was so inspired by myself that I decided to somehow do this slide, re-arrange it. Let it look like this, because it's really cool!
Good numbers, can you imagine how everything became good? And then I was driven into such a steppe that I felt like a designer, and I thought that this is an achievement that I would like to add to the frame. And, as you understand, I got up, looked and realized that I’m rather not a designer, but, really, a web developer. But I'm not a fool. I took this frame, added to my site to SEO-amulets.
You can use, even the link is there. And lest you think that I am deceiving you - we are frank today - I really looked at the reviews. I think you can believe them.
Well, to be honest, it looked something like this. I saw a new hyos library thanos-js, picked up, created a pull request. In secret, I have administrator rights in our repository. And I took and demoted the master. How do you like that? Well, we are frank with you, and, in fact, it all looked like this. If anyone does not know, thanos-js is a library that simply deletes 50% of your code randomly.
In fact, I still used the library there, but the library is called differently. She is called diffector, and now we'll talk about it with you. And here I would like to note that the pull request is quite significant, minus 44 thousand lines of code, and you can imagine that it was tested the first time. That is what I am talking about, really can work.
Diffector. In fact, he is engaged not only in the task of removing unused modules, finding defects in a graph, but also in a more important task. What I initially declared was to help the developer and tester, now this will be discussed. And it works like this.
We get a list of changed files using a version control system. We have already built a graph - diffector builds it. And for each such modified file, we look for the path to entry and mark the modified entry. And the entry we will have to correspond with the pages of applications that the user sees. But it is quite logical.
And what does this give us? For testing, we know which pages in the application have changed. We can tell the tester that we only need to test them. We can also tell our ci-job, which runs auto-tests, that only these pages should be tested. And for developers, everything is much simpler, because now testers do not write to you and do not ask: “Why should we test?”
Let's look at an example of how diffector works. Here we have a certain directory, pages.desktop / *. It contains just a list of the pages themselves. And the pages are also described in several files. The controller is the server part of the page. View - some react-part. And deps, this is from another build system. We have not only webpack, but also ENB.
And I made some changes to the project, to an empty file whose structure you saw. This is what the diffector gives me. I just ran it, diffector is a command line application. I launched it, it tells me that I have changed one page called BindBonusPage.
I can also run it in verbose mode, see a more detailed report, and, indeed, see that it at least works in such a simple case. As we can see, in our BindBonusPage the index file and the controller have changed.
But let's see what happens if we change something else.
I changed something else. And the diffector told me that I have changed nine pages. And now this does not please me, no matter how much he helped me.
, ? , . , . - uikit.
diff. . , diffector . , - , .
, , . , , entry, , , test-scope, . .
. , , , , .
. - , . — i18n, , . , , , . , , - .
? , , , , , .
- . , B , , -2 . . , esm.
.
.
, value, . , , . , .
, AST, , 250 , , . , , - , , .
, - GlobalContext - , . , modify, , ? , - GlobalContext. . . , side effects. , , webpack, , . , webpack sideEffects: true, . .
, - - . , . diffector, . , , . — , . , .
, , diff, expand, log, , , , .
, . D, diff. , , , . , , . , , . .
, , . . . , — , . . . , , , , , . . , .
— diffector ? , , , .
- , , .
, , entry. entry. diffector.
. -. , .
, entry -, .
. diffector. . , , - , -. , . : , BindBonusPage, -, . . , , - . .
— CI. . : , , .
, . 43 — testing, , .
. , , .
, . : , , . , , , , , . , , - .
. , , , . - , - , , , . .
, , , output . , . — . — . Thank!
Source: https://habr.com/ru/post/454470/
All Articles