Interesting archeology: R style guide under a magnifying glass
As you know, the code is read much more often than they write. To be able to read at least someone other than the author, and there are style guides. For R, this could be, for example, the Hadley manual.
The style guide is not just an unwritten contract of developers - behind many of the rules is a curious prehistory. Why the arrow
1. The assignment operator:
All available guides recommend using a non-standard operator
')
History reveals maps to us: in R, the arrow came from S, which in turn inherited it from APL. In the APL language, it made it possible to distinguish assignment from equality. In R, the equality operator is standard, so the difference is different. If the arrow was an assignment operator initially, then the equal sign assigned values only to named parameters. In 2001, the equal sign became the assignment operator, but it never became synonymous with the arrow.
What, then, can be considered
Here(no, it's still not Lisp) :
... or in braces:
In addition, the arrow takes precedence over the equal sign:
The last expression failed because it is equivalent to
In other words, we are trying to perform an incorrect operation: first we assign x the value of y, and then we try to assign x and y the value 4. The expression will be processed without errors only if we change the priority of the operations with brackets:
The guide recommends putting spaces between operators (except, of course, square brackets,:, :: and :: :: :), as well as before the opening bracket. Obviously, this is part of the GNU coding standards. However, this item is closely related to the use of
What is it? X is less than -1? Or assign x a value of 1?
However, the extra space is no better than the missing one, for example:
In the first case, there is no space between
In the question of names, style guides diverge: the Hadley guide recommends an underscore for all names; Google Guide - dots for variables and camel style with first line for functions; Bioconductor recommends lowerCamel for both functions and variables. In this question there is no unity in the R community, and all possible styles can be found:
There is no uniform style even for base R names (for example, rownames and row.names are different functions!). If you do not take into account the unreadable allowercase (only Matlab users can love it), we can distinguish three most popular styles: lowerCamel, lower case with _, and lower case with dotted divisions.
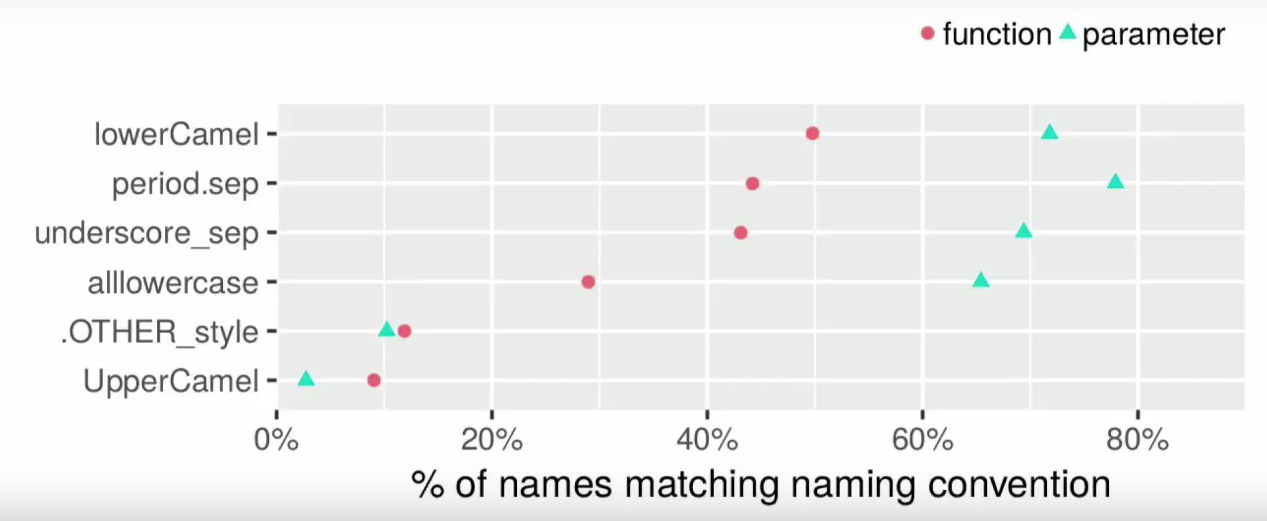
The popularity of different styles for the names of functions and parameters (one name can correspond to different styles). Source: Rasmus Bååth's performance on useR! 2017.
Split-dots ominously resemble the use of methods in object-oriented programming, but historically prevalent. It is so common that it is this style that can be considered truly R'vsky. For example, most of the basic functions use it (it’s exactly with each data.table and as.factor).
But the separation of _ is one of the least popular styles (and here Hadley goes against the majority). For many users of R, the underscore will be an irritant: in the popular Emacs Speaks Statistics extension, it is replaced by the assignment operatoralmost no one changes.
However, the influence of Emacs ESS is still an explanation from the category of "tail wags the dog." There is a more ancient reason: in earlier versions of R, the underscore was synonymous with the arrow
Here, instead of creating the variable
Due to the unpopularity of _ the functions of this style are almost not found among the basic ones:
Finally, the lowerCamel style is notable for its low readability when using long names:
Thus, in terms of the names of recommendations guide can not be considered unambiguous; after all, this is a matter of taste (as long as there is consistency in this).
According to the guide, a new line should follow the opening brace, and the closing line should be on a separate line (unless it is followed by an else). Those. like that:
Everything is not very interesting here: this is the standard K & R indenting style, which goes back to the C language and the famous book by Kernighan and Ritchie “The C Programming Language” (or K & R by the names of the authors).
The origins of this style are also quite obvious: it allows you to save lines, while maintaining readability. For early computers, vertical space was too much luxury. For example, C was developed on the PDP-11, in the terminal of which there were only 24 lines. Yes, and when printing a K & R book, this style saved paper!
The recommended length of the string according to the guide is 80 characters. The magic number 80 is found not only in R, but also in a huge number of other languages (Java, Perl, PHP, etc., etc.). And not only languages: even the Windows command line consists of 80 characters.
For the first time in programming, this number appeared in 1928 instead of with the standard IBM punch card, where there were exactly 80 columns for data. Much more interesting question - why was chosen such a standard? After all, previously used and punched cards of different lengths (24 or 45 columns).

The most popular answer relates the length of the punch card to the length of the line for typewriters. The first machines were designed for the American standard paper 8½ x 11 inches, and allowed to print from 72 to 90 characters, depending on the size of the fields. Therefore, the version of the 80 characters in the string looks quite plausible, although not the ultimate truth. It is possible that 80 characters - it's just a happy medium in terms of ergonomics.
The style recommended by the guide is two spaces, not tabulation. Failure to tab is quite understandable: the length of a TAB varies in different text editors (this can be anything from 2 to 8 spaces). Refusing them, we get two advantages at once: first, the code will look exactly the same as we typed it; secondly, there will be no accidental violation of the recommended string length. At the same time, we, of course, increase the file size (who wants to deal with such micro-optimizations in 2k19 year?)
Dispute spaces vs tabulation has a long history, and can be equated to religious (for example, Win vs Linux, Android vs iOS, and the like). However, we already know who won in it: according to the Stack Overflow study , developers using spaces earn more than those who use tabulation. A more weighty argument than the rules of the style guide, is it?
Instead of a conclusion: the rules of style guides may seem strange and illogical. Indeed, why the arrow
The style guide is not just an unwritten contract of developers - behind many of the rules is a curious prehistory. Why the arrow
<- better than the equal sign = , why the old-timers R do not like the underscore, how the recommended length of the line is related to the punched card, and about many other things - further.Disclaimer: Style Guides R
Unlike Python, there is no single standard in R. Accordingly, there is no single leadership. In addition to the guide Hadley (or its extended version of the tidyverse ), there are others, for example Google or Bioconductor .
Nevertheless, the Hadley guide can be considered the most common (as built-in RStudio check , for example), which is greatly contributed by the popularity of libraries created by Hadley himself (dplyr, ggplot, tidyr, and others from the tidyverse collection).
Nevertheless, the Hadley guide can be considered the most common (as built-in RStudio check , for example), which is greatly contributed by the popularity of libraries created by Hadley himself (dplyr, ggplot, tidyr, and others from the tidyverse collection).
1. The assignment operator: <- vs =
All available guides recommend using a non-standard operator
<- , and not an equal sign = , familiar to other modern languages. Three other operators ( <<- , -> , ->> ) are not even mentioned (as well as existed in earlier versions := ). It would seem, why do we need this non-standard arrow?')
History reveals maps to us: in R, the arrow came from S, which in turn inherited it from APL. In the APL language, it made it possible to distinguish assignment from equality. In R, the equality operator is standard, so the difference is different. If the arrow was an assignment operator initially, then the equal sign assigned values only to named parameters. In 2001, the equal sign became the assignment operator, but it never became synonymous with the arrow.
What, then, can be considered
= full replacement of the arrow? First of all, = how the assignment operator works only at the top level. For example, inside the function everything will work as before: mean(x = 1:5) # [1] 3 x # Error: object 'x' not found mean (x <- 1:5) # [1] 3 x # [1] 1 2 3 4 5 Here
= only specifies the parameter of the function, while <- also assigns the value to the variable x. We can achieve the same effect by putting the assignment operation in parentheses mean ((x = 1:5)) # [1] 3 x # [1] 1 2 3 4 5 ... or in braces:
mean ({x = 1:5}) # [1] 3 x # [1] 1 2 3 4 5 In addition, the arrow takes precedence over the equal sign:
x <- y <- 1 # OK x = y = 2 # OK x = y <- 3 # OK x <- y = 4 # Error in x <- y = 4 : could not find function "<-<-" The last expression failed because it is equivalent to
(x <- y) = 4 , and the parser interprets it as `<-<-`(x, y = 4, value = 4) In other words, we are trying to perform an incorrect operation: first we assign x the value of y, and then we try to assign x and y the value 4. The expression will be processed without errors only if we change the priority of the operations with brackets:
x <- (y = 4) .2. Spacing
The guide recommends putting spaces between operators (except, of course, square brackets,:, :: and :: :: :), as well as before the opening bracket. Obviously, this is part of the GNU coding standards. However, this item is closely related to the use of
<- as an assignment operator. For example, x <-1 What is it? X is less than -1? Or assign x a value of 1?
However, the extra space is no better than the missing one, for example:
x <- 0 ifelse(x <-1, T, F) # [1] TRUE x <- 0 ifelse(x < -1, T, F) # [1] FALSE In the first case, there is no space between
< and - , which creates an assignment operator.3. Names of functions and variables
In the question of names, style guides diverge: the Hadley guide recommends an underscore for all names; Google Guide - dots for variables and camel style with first line for functions; Bioconductor recommends lowerCamel for both functions and variables. In this question there is no unity in the R community, and all possible styles can be found:
lowerCamel period.separation lower_case_with_underscores allowercase UpperCamel There is no uniform style even for base R names (for example, rownames and row.names are different functions!). If you do not take into account the unreadable allowercase (only Matlab users can love it), we can distinguish three most popular styles: lowerCamel, lower case with _, and lower case with dotted divisions.
The popularity of different styles for the names of functions and parameters (one name can correspond to different styles). Source: Rasmus Bååth's performance on useR! 2017.
The same in 2012
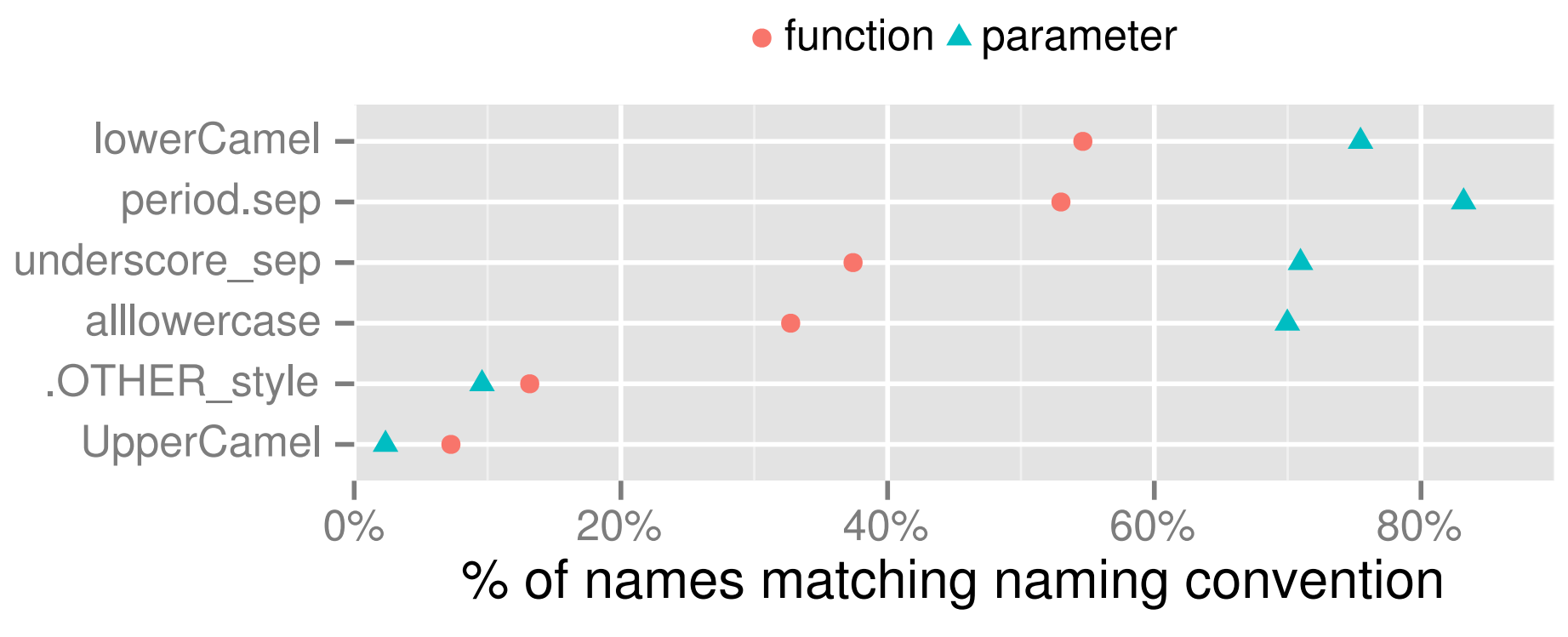
Split-dots ominously resemble the use of methods in object-oriented programming, but historically prevalent. It is so common that it is this style that can be considered truly R'vsky. For example, most of the basic functions use it (it’s exactly with each data.table and as.factor).
But the separation of _ is one of the least popular styles (and here Hadley goes against the majority). For many users of R, the underscore will be an irritant: in the popular Emacs Speaks Statistics extension, it is replaced by the assignment operator
<- by default. And the default settings, of course, However, the influence of Emacs ESS is still an explanation from the category of "tail wags the dog." There is a more ancient reason: in earlier versions of R, the underscore was synonymous with the arrow
<- . For example, in 2000 it was possible to meet such: # R c <- c(1,2,3,4,5) mean(c) [1] 3 c_mean <- mean(c) c [1] 3 Here, instead of creating the variable
c_mean R assigned the value 3 first to the variable mean and then to the variable c. In modern R, such metamorphosis, of course, will not occur.Due to the unpopularity of _ the functions of this style are almost not found among the basic ones:
# 3.5.1 25 grep("^[^\\.]*$", apropos("_"), value = T) Finally, the lowerCamel style is notable for its low readability when using long names:
# ! GrossNationalIncomePerCapitaAtlasMethodCurrentUnitedStatesDollars Thus, in terms of the names of recommendations guide can not be considered unambiguous; after all, this is a matter of taste (as long as there is consistency in this).
4. Braces
According to the guide, a new line should follow the opening brace, and the closing line should be on a separate line (unless it is followed by an else). Those. like that:
if (x >= 0) { log(x) } else { message("Not applicable!") } Everything is not very interesting here: this is the standard K & R indenting style, which goes back to the C language and the famous book by Kernighan and Ritchie “The C Programming Language” (or K & R by the names of the authors).
The origins of this style are also quite obvious: it allows you to save lines, while maintaining readability. For early computers, vertical space was too much luxury. For example, C was developed on the PDP-11, in the terminal of which there were only 24 lines. Yes, and when printing a K & R book, this style saved paper!
5. 80 character string
The recommended length of the string according to the guide is 80 characters. The magic number 80 is found not only in R, but also in a huge number of other languages (Java, Perl, PHP, etc., etc.). And not only languages: even the Windows command line consists of 80 characters.
For the first time in programming, this number appeared in 1928 instead of with the standard IBM punch card, where there were exactly 80 columns for data. Much more interesting question - why was chosen such a standard? After all, previously used and punched cards of different lengths (24 or 45 columns).
The most popular answer relates the length of the punch card to the length of the line for typewriters. The first machines were designed for the American standard paper 8½ x 11 inches, and allowed to print from 72 to 90 characters, depending on the size of the fields. Therefore, the version of the 80 characters in the string looks quite plausible, although not the ultimate truth. It is possible that 80 characters - it's just a happy medium in terms of ergonomics.
6. Indent lines: spaces vs tabulation
The style recommended by the guide is two spaces, not tabulation. Failure to tab is quite understandable: the length of a TAB varies in different text editors (this can be anything from 2 to 8 spaces). Refusing them, we get two advantages at once: first, the code will look exactly the same as we typed it; secondly, there will be no accidental violation of the recommended string length. At the same time, we, of course, increase the file size (who wants to deal with such micro-optimizations in 2k19 year?)
Dispute spaces vs tabulation has a long history, and can be equated to religious (for example, Win vs Linux, Android vs iOS, and the like). However, we already know who won in it: according to the Stack Overflow study , developers using spaces earn more than those who use tabulation. A more weighty argument than the rules of the style guide, is it?
Instead of a conclusion: the rules of style guides may seem strange and illogical. Indeed, why the arrow
<- if there is a standard operator = ? But if you dig deeper, then behind each rule is some logic, often already forgotten.Source: https://habr.com/ru/post/454432/
All Articles