Backup, part 3: Review and testing duplicity, duplicati

This article describes backup tools that perform backups by creating archives on a backup server.
Of those that meet the requirements - duplicity (which has a nice interface in the form of deja dup) and duplicati.
Another very remarkable backup tool is dar, but since it has a very extensive list of options — the testing methodology covers almost 10% of what it is capable of — we do not test it during the current cycle.
Expected results
Since both candidates somehow create archives, you can use regular tar as a guide.
Additionally, we estimate how well storage is optimized on the storage server by creating backup copies containing only the difference between the full copy and the current state of the files, or between the past and the current archives (incremental, decremental, etc.).
Behavior when creating backups:
- A relatively small number of files on the backup storage server (comparable to the number of backups or the size of data in GB), but quite large in size (tens to hundreds of megabytes).
- The size of the repository will only include changes - duplicates will not be stored, thus the size of the repository will be smaller than when running software based on rsync.
- A large processor load is expected when using compression and / or encryption, and also, probably, a sufficiently large load on the network and disk subsystem, if the archiving and / or encryption process runs on the backup storage server.
As a reference value, run the following command:
cd /src/dir; tar -cf - * | ssh backup_server "cat > /backup/dir/archive.tar" The execution results were as follows:

Running time is 3m12s. It can be seen that the speed rested on the disk subsystem of the backup storage server, as in the rsync example. Only a little faster, because recording goes to one file.
Also, to evaluate the compression, we will run the same option, but enable compression on the server side of the backup:
cd /src/dir; tar -cf - * | ssh backup_server "gzip > /backup/dir/archive.tgz" The results are as follows:
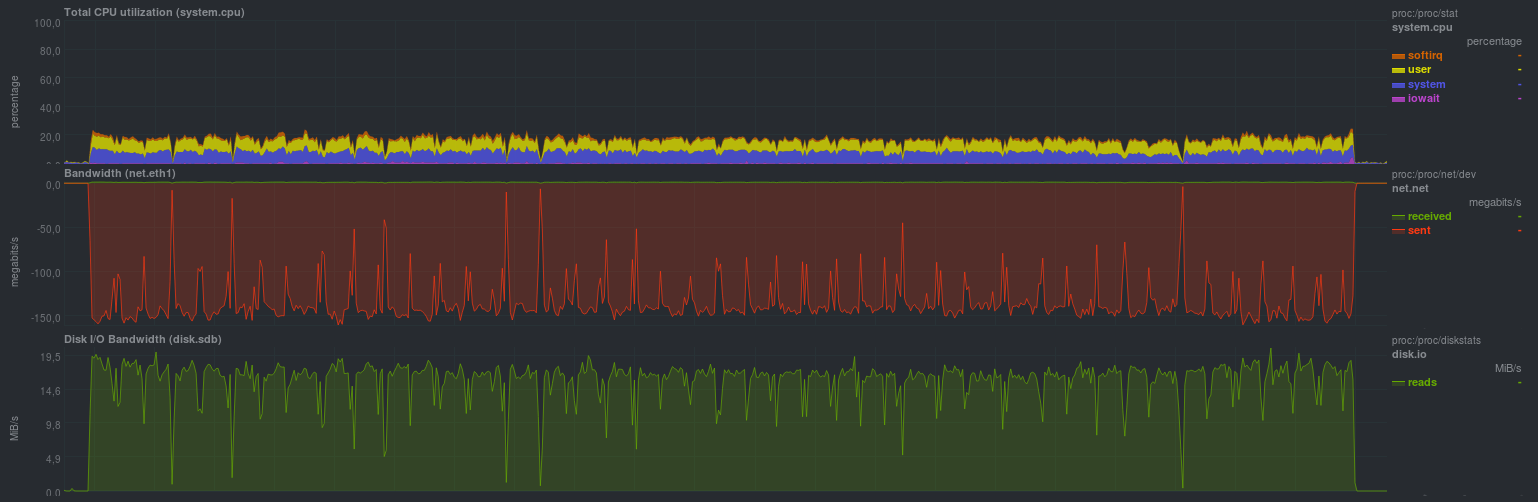
The lead time is 10m11s. Most likely, the bottleneck is a single-flow compressor on the receiving side.
The same command, but with the transfer of compression to the server with the original data to test the hypothesis that the bottleneck is a single-flow compressor.
cd /src/dir; tar -czf - * | ssh backup_server "cat > /backup/dir/archive.tgz" It turned out like this:
Runtime was 9m37s. The loading of a single core by a compressor is clearly visible, since The network transfer speed and the load on the disk subsystem of the source are the same.
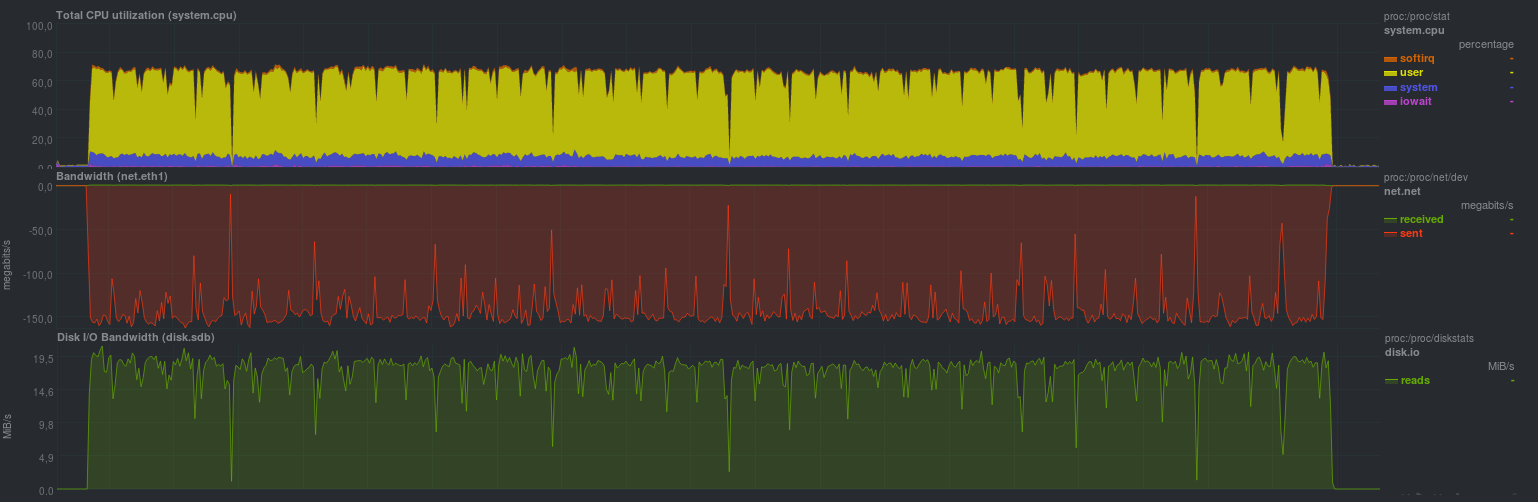
You can use openssl or gpg to evaluate encryption by connecting an additional openssl or gpg command to a pipe. For reference, there will be the following command:
cd /src/dir; tar -cf - * | ssh backup_server "gzip | openssl enc -e -aes256 -pass pass:somepassword -out /backup/dir/archive.tgz.enc" The results came out as follows:

The execution time turned out to be 10m30s, since 2 processes were launched on the receiving side - the bottleneck is again a single-threaded compressor, plus a small overhead of encryption.
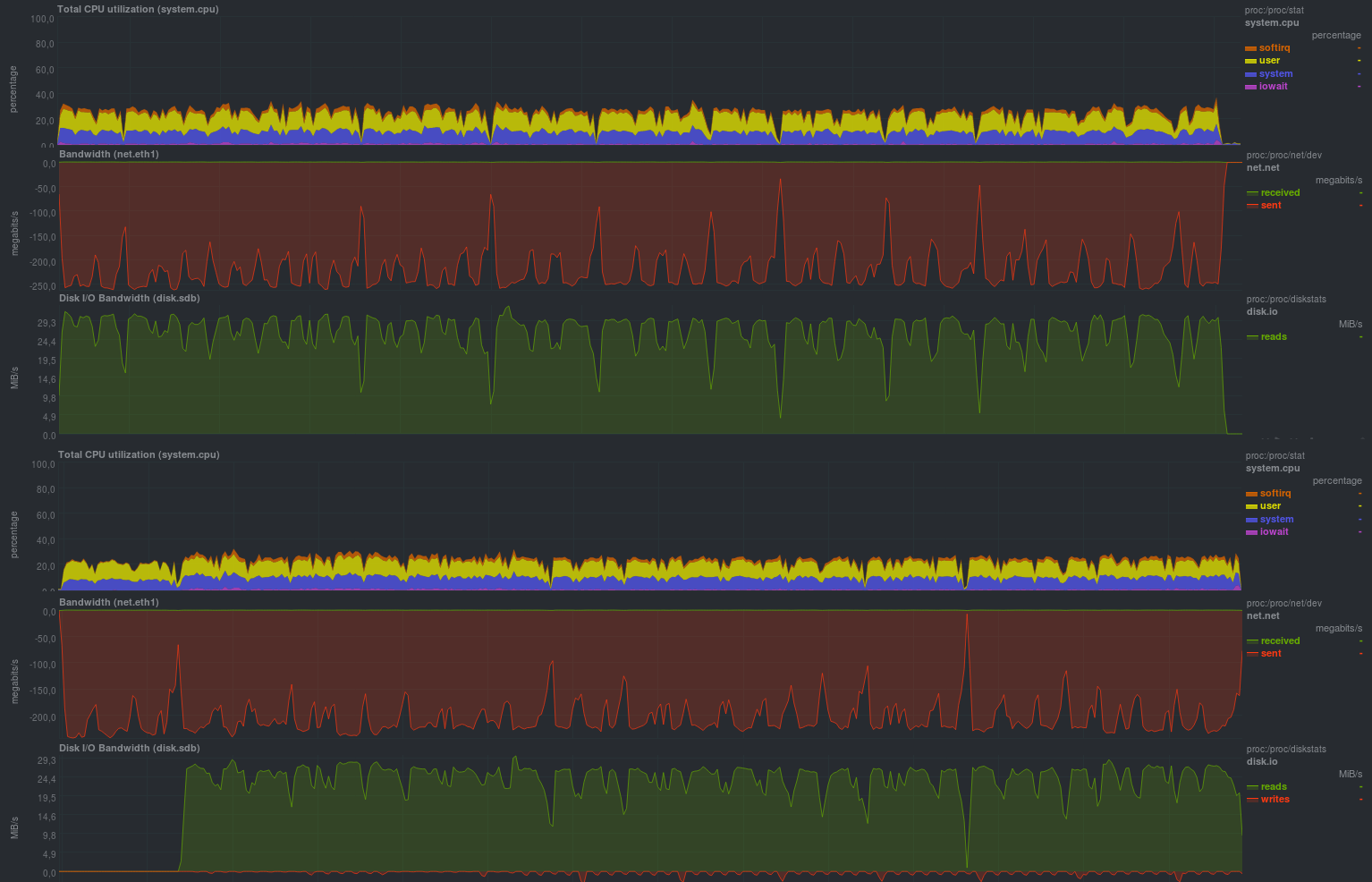
UPD: At the request of bliznezz add tests with pigz. If you use only the compressor - it turned out for 6m30s, if you also add encryption - about 7m. Failure on the lower graph - disk cache not flushed:
Testing duplicity
Duplicity is python backup software by creating encrypted tar archives.
For incremental archives, librsync is used, therefore, we can expect the behavior described in the previous article cycle .
Backups can be encrypted and signed with gnupg, which is important when using different providers for storing backups (s3, backblaze, gdrive, etc.)
Let's see what the results will be:
spoiler
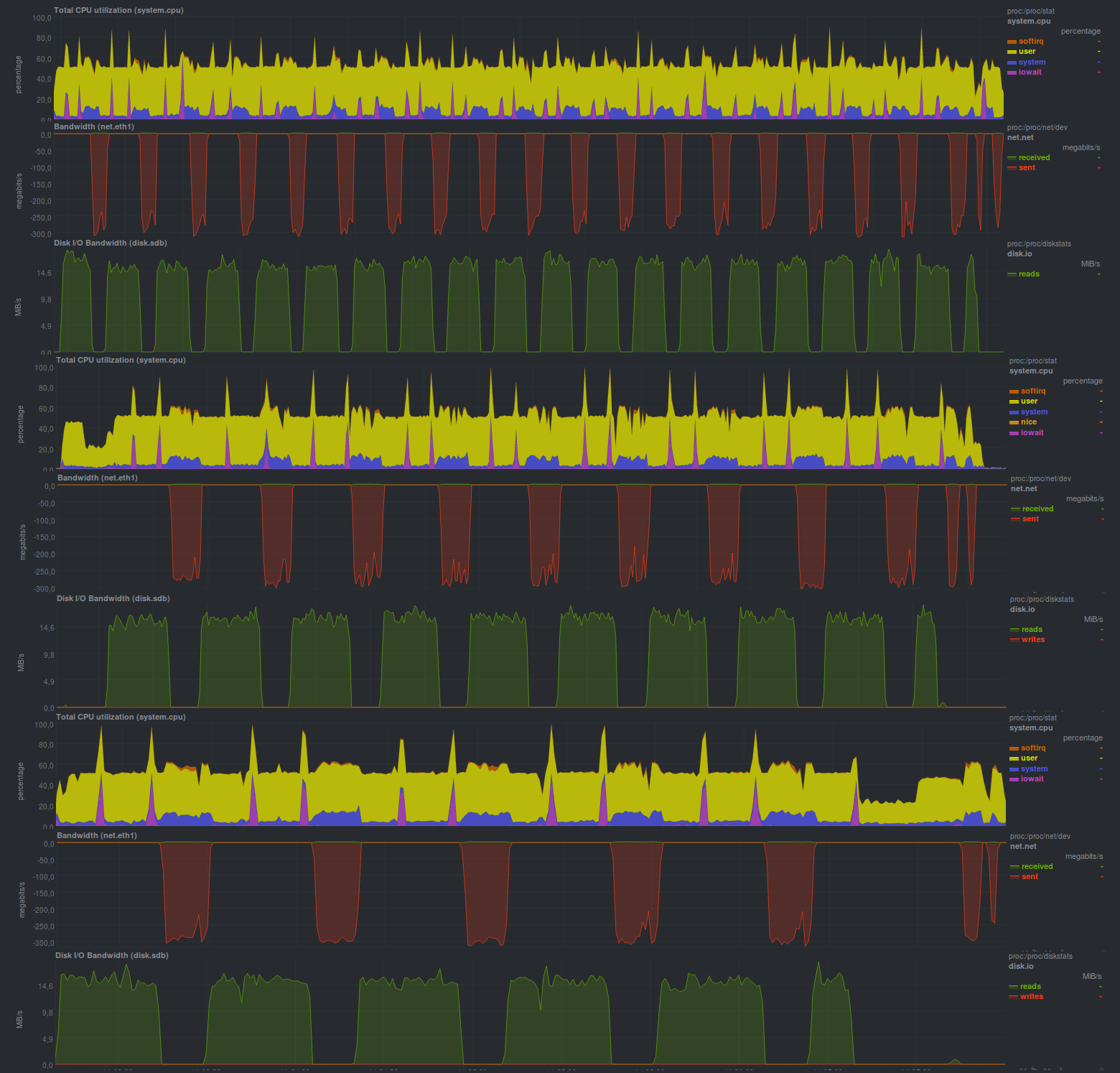
The time of each test run:
| Run 1 | Run 2 | Run 3 |
|---|---|---|
| 16m33s | 17m20s | 16m30s |
| 8m29s | 9m3s | 8m45s |
| 5m21s | 6m04s | 5m53s |
And here are the results when gnupg encryption is enabled, with a key size of 2048 bits:
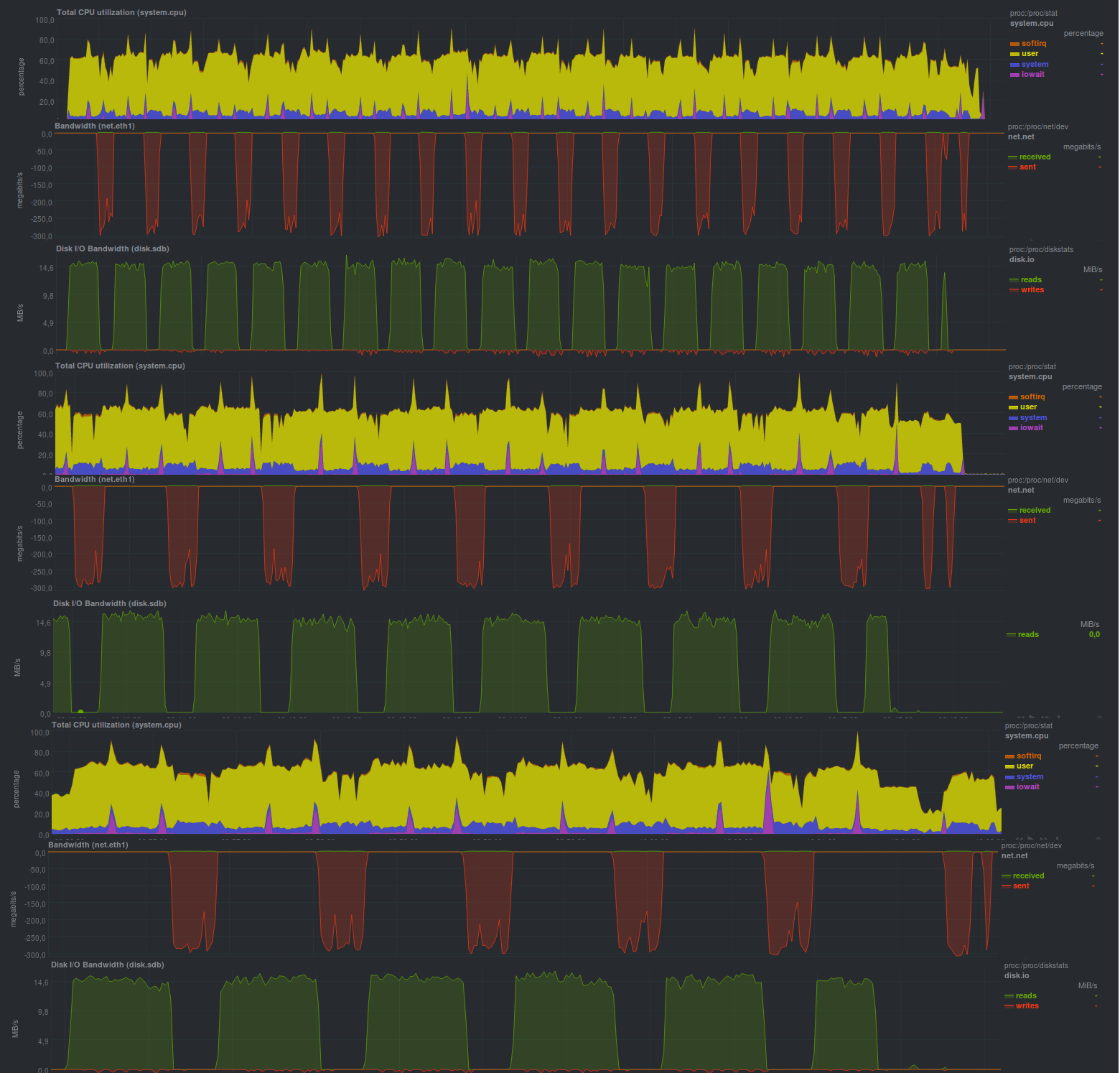
Operating time on the same data, with encryption:
| Run 1 | Run 2 | Run 3 |
|---|---|---|
| 17m22s | 17m32s | 17m28s |
| 8m52s | 9m13s | 9m3s |
| 5m48s | 5m40s | 5m30s |
The block size was indicated - 512 megabytes, which is clearly visible on the graphs; CPU usage was actually kept at 50%, which means that the program recycles no more than one processor core.
You can also clearly see how the program works: you took a piece of data, shook it, sent it to a backup storage server, which can be quite slow.
Another feature is the predictable time of the program, which depends only on the size of the modified data.
The inclusion of encryption did not particularly increase the running time of the program, but increased the processor load by about 10%, which can be a very good nice bonus.
Unfortunately, this program could not correctly detect the situation with the directory renaming, and the resulting repository size turned out to be equal to the size of the changes (ie, all 18GB), but the ability to use an untrusted server for backups uniquely blocks this behavior.
Testing duplicati
This software is written in C #, runs using a set of libraries from Mono. There is a GUI, as well as a cli version.
A sample list of core features is close to duplicity, including various backup storage providers, however, unlike duplicity, most features are available without third-party tools. Plus it or a minus - it depends on the specific case, however, for beginners, most likely, it is easier to have a list of all the possibilities at once, rather than installing packages for python, as is the case with duplicity.
Another small nuance - the program actively writes the local sqlite database on behalf of the user who starts the backup, so you need to additionally follow the correct indication of the desired database every time you start the process using cli. When working via GUI or WEBGUI, the details will be hidden from the user.
If you turn off encryption (and WEBGUI does not recommend this), the results are as follows:
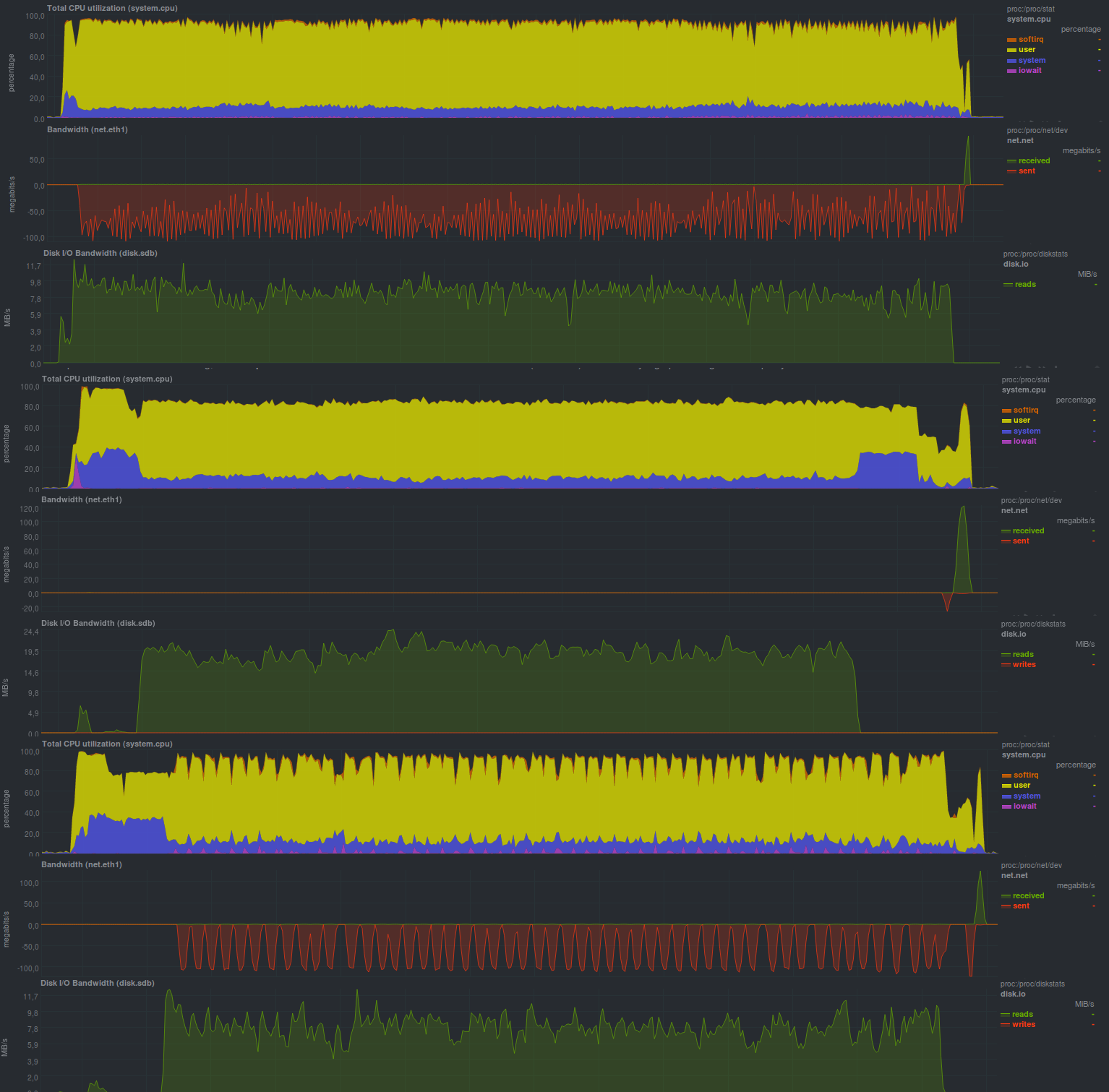
Working hours:
| Run 1 | Run 2 | Run 3 |
|---|---|---|
| 20m43s | 20m13s | 20m28s |
| 5m21s | 5m40s | 5m35s |
| 7m36s | 7m54s | 7m49s |
With encryption enabled, using aes, it turns out like this:
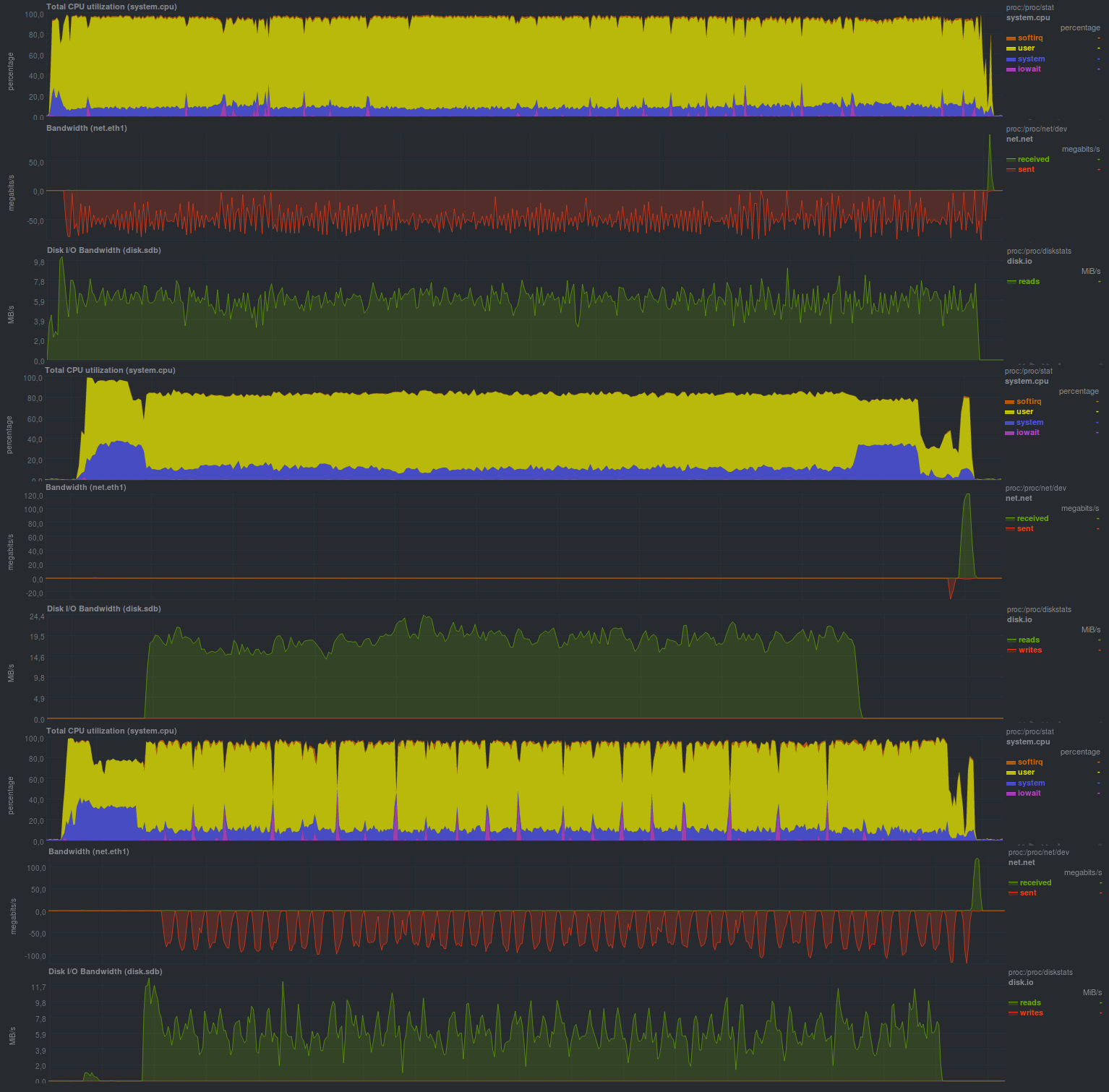
Working hours:
| Run 1 | Run 2 | Run 3 |
|---|---|---|
| 29m9s | 30m1s | 29m54s |
| 5m29s | 6m2s | 5m54s |
| 8m44s | 9m12s | 9m1s |
And if you use the external gnupg program, the following results will appear:

| Run 1 | Run 2 | Run 3 |
|---|---|---|
| 26m6s | 26m35s | 26m17s |
| 5m20s | 5m48s | 5m40s |
| 8m12s | 8m42s | 8m15s |
As you can see, the program can work in several streams, but this is not a more productive solution, and if you compare the work of encryption, start an external program
turned out to be faster than using the library from the Mono kit. Perhaps this is due to the fact that the external program is more optimized.
A pleasant moment was also the fact that the size of the repository takes exactly as much as the actual data was changed, i.e. duplicati found the directory was renamed and correctly handled the situation. This can be seen when running the second test.
In general, quite a positive impression from the program, including a sufficient friendliness to beginners.
results
Both candidates worked rather slowly, but in general, compared with the usual tar, there is progress, at least in duplicati. The price of such progress is also understandable - a noticeable load
processor. In general, there are no significant deviations in predicting the results.
findings
If there is no need to hurry anywhere, and there is also a reserve for the processor - any of the considered solutions will do, in any case, quite a lot of work has been done that should not be repeated by writing scripts-wrappers over tar. The presence of encryption is a very necessary property if the server for storing backups cannot be fully trusted.
Compared to rsync -based solutions, the performance can be several times worse, even though in its pure form, tar has worked rsync faster by 20–30%.
There is a saving on the size of the repository, but only with duplicati.
Announcement
Backup, Part 1: Why do I need backup, review of methods, technologies
Backup, part 2: Review and test rsync-based backup tools
Backup, part 3: Review and test duplicity, duplicati, deja dup
Backup, part 4: zbackup, restic, borgbackup review and testing
Backup, Part 5: Bacula and veeam backup for linux testing
Backup Part 6: Comparing Backup Tools
Backup, Part 7: Conclusions
Publisher: Pavel Demkovich
')
Source: https://habr.com/ru/post/454420/
All Articles