Why Every Data Scientist Should Know Dask
Hello colleagues!
Perhaps the name of today's publication would look better with a question mark - it is difficult to say. In any case, today we want to offer you a brief excursion that will introduce you to the Dask library, designed for parallelizing tasks in Python. We hope in the future to return to this topic more thoroughly.

Photo taken at
Dask - without exaggeration, the most revolutionary data processing tool that I came across. If you like Pandas and Numpy , but sometimes you don’t manage to handle data that doesn’t fit in RAM, then Dask is exactly what you need. Dask supports the Pandas data frame and Numpy data structures (arrays). Dask can be run either on the local computer, or scaled, and then run in a cluster. In essence, you write code only once, and then choose whether to use it on a local machine, or deploy in a cluster from a multitude of nodes, using the most common Python syntax for all of this. By itself, this feature is great, but I decided to write this article just to emphasize: every Data Scientist (at least using Python) should use Dask. From my point of view, Dask's magic is that by changing the code minimally, you can parallelize it using the computing power that you already have, for example, on my laptop. When parallel data processing program runs faster, you have to wait less, respectively, more time left on the analytics. In particular, in this article we will talk about the
')
As an acquaintance with Dask, I will give a couple of examples, just to give you an idea of its completely unobtrusive and natural syntax. The most important conclusion that I want to suggest in this case is that the knowledge you already have will be enough for work; You do not have to learn a new tool for handling big data, such as Hadoop or Spark.
Dask offers 3 parallel collections in which data can be stored that is larger than RAM, namely Dataframes, Bags and Arrays. In each of these types of collections, you can store data by segmenting it between RAM and a hard disk, and also distribute data across multiple nodes in a cluster.
Dask DataFrame consists of shredded dataframes, such as in Pandas, so it allows you to use a subset of capabilities from the syntax of Pandas queries. Below is a sample code that loads all the csv files for 2018, parses the timestamp field and triggers the Pandas query:
Dask Dataframe Example
In Dask Bag, you can store and handle collections of pythonic objects that do not fit in memory. Dask Bag is great for processing logs and collections of documents in json format. In this code example, all files in json format for 2018 are loaded into the Dask Bag data structure, each json record is parsed, and user data is filtered using the lambda function:
Dask Bag Example
The Dask Arrays data structure supports Numpy style slices. In the following example, the HDF5 data set is divided into blocks of dimension (5000, 5000):
Dask Array Example
Another equally accurate name for this section would be “Death of a Sequential Cycle”. I now and then encounter a common pattern: sorting through the list of elements, after which we execute the Python method with each element, but with different input arguments. Common data processing scenarios include the calculation of feature aggregates for each client or the aggregation of events from the log for each student. Instead of applying a function to each argument in a sequential loop, the Dask Delayed object allows you to process multiple items in parallel. When working with Dask Delayed, all function calls are queued, put in the execution graph, after which they are scheduled for processing.
I have always been a little lazy to write my own thread-handling mechanism or use asyncio, so I will not even show you similar examples for comparison. With Dask, you can change neither syntax nor programming style! You just need to annotate or wrap the method that will be executed in parallel with
In the example below, two methods are annotated with
The number of threads can be set (for example,
So, I demonstrated how trivial it would be to add parallel processing of tasks to a project from the field of Data Science using Dask. Shortly before writing this article, I used Dask to split the data on user click flows (visitor histories) into 40-minute sessions, and then aggregate features for each user for subsequent clustering. Tell us how you have used Dask!
Perhaps the name of today's publication would look better with a question mark - it is difficult to say. In any case, today we want to offer you a brief excursion that will introduce you to the Dask library, designed for parallelizing tasks in Python. We hope in the future to return to this topic more thoroughly.
Photo taken at
Dask - without exaggeration, the most revolutionary data processing tool that I came across. If you like Pandas and Numpy , but sometimes you don’t manage to handle data that doesn’t fit in RAM, then Dask is exactly what you need. Dask supports the Pandas data frame and Numpy data structures (arrays). Dask can be run either on the local computer, or scaled, and then run in a cluster. In essence, you write code only once, and then choose whether to use it on a local machine, or deploy in a cluster from a multitude of nodes, using the most common Python syntax for all of this. By itself, this feature is great, but I decided to write this article just to emphasize: every Data Scientist (at least using Python) should use Dask. From my point of view, Dask's magic is that by changing the code minimally, you can parallelize it using the computing power that you already have, for example, on my laptop. When parallel data processing program runs faster, you have to wait less, respectively, more time left on the analytics. In particular, in this article we will talk about the
dask.delayed object and how it fits into the data science task flow.')
Meet Dask
As an acquaintance with Dask, I will give a couple of examples, just to give you an idea of its completely unobtrusive and natural syntax. The most important conclusion that I want to suggest in this case is that the knowledge you already have will be enough for work; You do not have to learn a new tool for handling big data, such as Hadoop or Spark.
Dask offers 3 parallel collections in which data can be stored that is larger than RAM, namely Dataframes, Bags and Arrays. In each of these types of collections, you can store data by segmenting it between RAM and a hard disk, and also distribute data across multiple nodes in a cluster.
Dask DataFrame consists of shredded dataframes, such as in Pandas, so it allows you to use a subset of capabilities from the syntax of Pandas queries. Below is a sample code that loads all the csv files for 2018, parses the timestamp field and triggers the Pandas query:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute() Dask Dataframe Example
In Dask Bag, you can store and handle collections of pythonic objects that do not fit in memory. Dask Bag is great for processing logs and collections of documents in json format. In this code example, all files in json format for 2018 are loaded into the Dask Bag data structure, each json record is parsed, and user data is filtered using the lambda function:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies() Dask Bag Example
The Dask Arrays data structure supports Numpy style slices. In the following example, the HDF5 data set is divided into blocks of dimension (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000)) Dask Array Example
Parallel processing in Dask
Another equally accurate name for this section would be “Death of a Sequential Cycle”. I now and then encounter a common pattern: sorting through the list of elements, after which we execute the Python method with each element, but with different input arguments. Common data processing scenarios include the calculation of feature aggregates for each client or the aggregation of events from the log for each student. Instead of applying a function to each argument in a sequential loop, the Dask Delayed object allows you to process multiple items in parallel. When working with Dask Delayed, all function calls are queued, put in the execution graph, after which they are scheduled for processing.
I have always been a little lazy to write my own thread-handling mechanism or use asyncio, so I will not even show you similar examples for comparison. With Dask, you can change neither syntax nor programming style! You just need to annotate or wrap the method that will be executed in parallel with
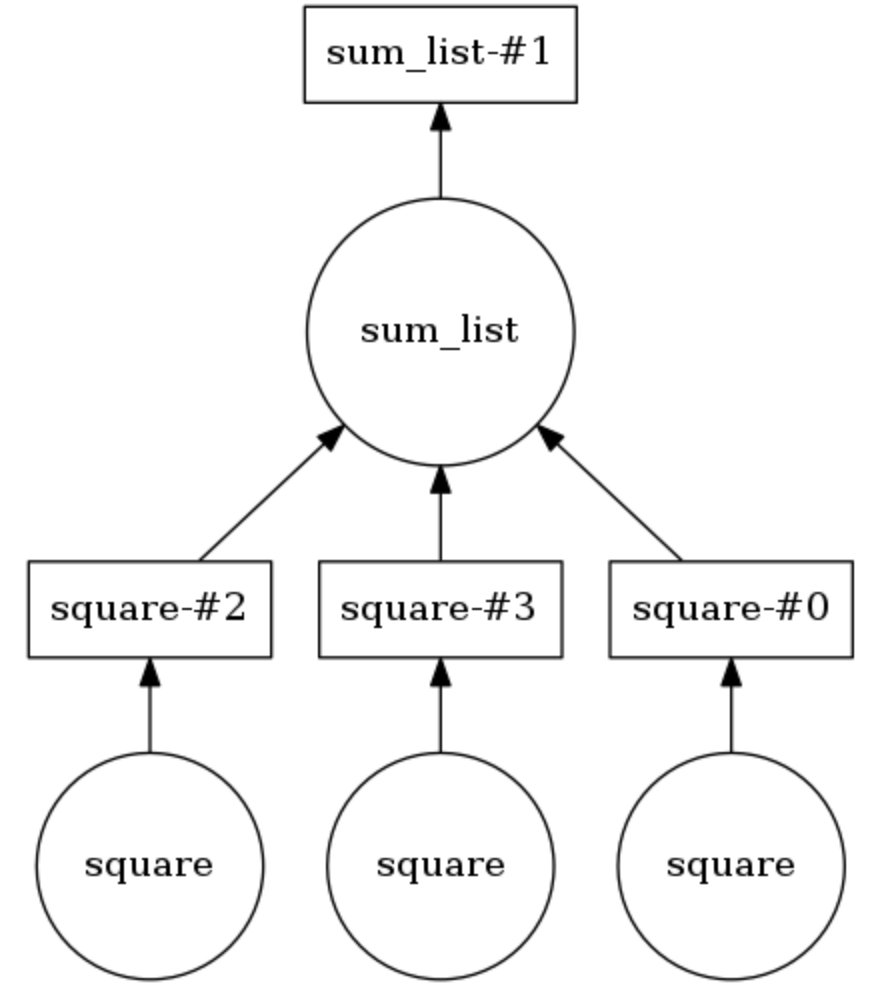
@dask.delayed and call the computational method after executing the loop code.Sample Dask Computing Graph
In the example below, two methods are annotated with
@dask.delayed . Three numbers are stored in the list, they need to be squared, and then all together sum up. Dask builds a computational graph that provides parallel execution of the method for squaring, after which the result of this operation is passed to the sum_list method. A computational graph can be displayed by calling calling .visualize() . Calling .compute() performs a computation graph. As is clear from the conclusion , the elements of the list are not processed in order, but in parallel.The number of threads can be set (for example,
dask.set_options( pool=ThreadPool(10) ), and also they can be easily downloaded to use processes on your laptop or PC (eg, dask.config.set( scheduler='processes' )) .So, I demonstrated how trivial it would be to add parallel processing of tasks to a project from the field of Data Science using Dask. Shortly before writing this article, I used Dask to split the data on user click flows (visitor histories) into 40-minute sessions, and then aggregate features for each user for subsequent clustering. Tell us how you have used Dask!
Source: https://habr.com/ru/post/454262/
All Articles