Behavioral crawling - not a panacea?
In the previous article, we considered the approach we applied to the issue of computational (aggregating) data processing for visualization on interactive deshbords. The article touched upon the stage of information delivery from primary sources to users in the context of analytical cases, which allow to rotate the information cube. The presented data transformation model on the fly creates an abstraction, providing a single query format and a designer for describing calculations, aggregation and integration of all connected types of sources - database tables, services and files .
The listed sources are more likely to be structured, implying the predictability of the data format and the uniqueness of the procedures for their processing and visualization. But for an analyst, unstructured data is of no less interest, which, when the first results appear, sometimes overestimates the expectations of such systems. Appetite comes with eating, and the loss of caution can exactly repeat the tale ...
- Still! More gold!
But his wheeze was already barely audible and horror appeared in his eyes.
(tale "Golden Antelope")

Under the cat, in the article, the key features and structure of a multi-role cluster and behavioral crawler by virtual users are outlined , which automate the routine for collecting information from complex Internet resources. And only touches the question of the limit of such systems.
Any hypothetical Internet resource, from which we need to extract information, when considering methods of crawling, can be placed on a scale with two extremes - from simple static resources and API to dynamic interactive sites that require high involvement from the user. The first can be attributed to the old generation of search robots ( modern, at least, learned how to handle JavaScript ), to the second - systems with browser farms and algorithms that simulate the user's work or attract him when collecting information.
In other words, the technology of crawling can be placed on the scale of difficulty:

On the one hand, the complexity of the source can be understood as a chain of actions necessary to obtain primary information, on the other hand, the technologies that need to be applied to obtain machine-readable data suitable for analysis.
Even the seemingly simple extraction of texts from static pages is not always trivial in practice - it is required either to develop and maintain HTML planarization rules for all types of pages, or to automate and invent heuristics and complex solutions. To some extent, structuring is simplified by the development of micromarking ( in particular, Schema.org , RDFa , Linked Data ), but only in narrow special cases, for downloading company cards, products, business cards and other search engine optimization and open data.
Below, we deliberately narrow the area of consideration and dwell on the technological component of a subset of browser-based crawlers designed to download information from complex sites, in particular social networks - this is exactly the right case when other simple ways of cracking do not work.
Information tape
Consider an approach that reduces the task of collecting information from social networks to the formation of an information timeline tape - an updated collection or stream of objects with attributes and timestamps. The list of object types and their attributes is different, changeable and extensible, for example: posts, likes, comments, reposts and other entities that are added to the system by developers and analyst operators, and are loaded with crawlers.
Since the tape is a stream of structured objects, the question of its filling arises. We supported two types of tapes:
- a simple tape that fills with content from fixed sources;
- thematic feed filled with content according to keywords, phrases and search expressions.
An example of a simple feed with fixed sources ( lists of profiles and pages are specified ):

A simple type of tape implies a periodic traversal of the specified profiles and pages in various social networks with a predetermined depth of traversal and loading of objects selected by the user. As it is filled, the tape becomes available for viewing, analyzing and uploading data:

Thematic ribbon is a simple extension, provides full-text search and filtering of objects loaded into the tape. The system automatically manages the collection of tape sources and the depth of their crawling, analyzing the relevance and connections of sources. This feature of the implementation is due to the absence or "strange" work of the built-in keyword search in social networks. Even when such a function is available, more often than not, the results are not given out completely and according to some internal algorithm, which is completely incompatible with the requirements for a crawler.
A special mechanism with a specific heuristic is responsible for managing the tape in the system - it analyzes data and history, adds relevant sources (profiles and communities tapes), in which either specified expressions are mentioned, or they are somehow related to those, and removes irrelevant ones.
An example of a thematic tape:

In the future, tapes are used as a source in analytical transformations with subsequent visualization of the results, for example, in the form of a graph:

In some cases, streaming processing of incoming objects is performed with saving to specialized target collections or unloaded via the REST API in order to use the collected content in third-party systems (for example ). In others, block processing is performed by timer. The operator describes the script processing script or constructs a process with control signals and functional blocks, for example:

Task pool
Active tapes define a primary task pool, each of which forms related tasks. For example, one profile traversal task may generate a multitude of related subtasks — bypassing friends, subscribers, or downloading new posts and detailed information, etc. There is also a stage of preprocessing new objects of the thematic tape, which also forms the tasks related to new relevant sources.
As a result, we get a huge number of different types of tasks related to each other, with priorities, time and conditions of implementation - all this zoo needs to be properly managed to avoid situations in which some tasks overload all the cluster resources to the detriment of tasks from other tapes .
To resolve the inconsistencies in the system, shared virtual resources and a dynamic prioritization mechanism are implemented, which take into account the types of tasks, the current time and are likely to run in the form of a dome. In general terms, the priority at a certain moment becomes maximum, but soon fades away, the task gets sour, but under certain circumstances it can grow again.
The formula for such a dome takes into account several factors, in particular: the priority of parental tasks, the relevance of the associated source, and the time of the last attempt (when re-traversing to track changes or when an error occurs).
Virtual users
By a virtual user, in a broad sense, we can understand the maximum imitation of human actions, in practical terms, the set of properties that a crawler should have:
- execute the page code using the same tools as the user - OS, browser, UserAgent, plug-ins, font sets, etc.
- interact with the page, imitating the work of a person with a keyboard and mouse - move the cursor around the page, make random movements, pauses, press keys when typing text, etc. ( don’t forget about mobile devices );
- interact with the decision center, taking into account the context and content of the page:
- take into account duplicates, the relevance of the objects on the page, the depth of the traversal, the time frame, etc.
- respond to non-standard situations - in the event of a captcha or error, form a request and wait for a decision either using a third-party service or with the involvement of the system operator;
- to have a plausible legend - to save the history of visits and cookies (browser profile), use certain IP addresses, take into account the periods of greatest activity (for example, morning-evening or lunch-night).
In an idealized view, a single virtual user can have multiple accounts, use multiple browsers at different times, and be connected to other virtual users, as well as enjoy the behavior and internet surfing habits of a person.
For example, imagine such a situation - one user uses the same browser and IP as if at work (the same IP can be used by "colleagues"), another browser and IP as at home (theirs are used by "neighbors"), and from time to time mobile phone. With such a view on the problem, countering the automated gathering by the Internet services seems to be a non-trivial task and, possibly, inexpedient.
In practice, everything is much simpler - the fight against crawlers is of a wave nature and includes a small set of techniques: manual moderation, analysis of user behavior (frequency and uniformity of actions) and displaying captcha. Clarler, possessing at least to some extent the properties from the list above, fully implements the concept of virtual users and, with due attention of the operator, can perform its function for a long time, remaining “ elusive Joe ”.
But what about the ethical and legal side of using virtual users?
In order not to play with the concepts of public and personal data, - each of the parties has its weighty arguments, - we will touch only the fundamental points.
Automated content publishing, spam mailing, account registration and other "active" activities of virtual users can easily be considered illegal or affecting the interests of third parties. In this regard, the system implements an approach in which virtual users are only curious observers representing the user (their operator) and performing the routine of collecting information instead.
Managing Shared Virtual Resources
As described above, a virtual user is a collective entity that uses several system and virtual resources in the process. Some resources are used solely, while others are shared and used by several virtual users, for example:
- output node address (external IP) - associated with one or more virtual users;
- browser profile - associated with a single virtual user;
- computational resource - associated with the server, sets the limitations of the server as a whole and for each type of task;
- virtual screen - sets server limits, but is used by a virtual user.
Each virtual resource has a type and group of instances called slots. On each cluster node, the configuration of virtual resources and slots is defined, which add virtual resources to the pool and are available to all cluster nodes. At the same time for a single type of virtual resource can be added as a fixed or a variable number of slots.
Each slot can have attributes that will be used as conditions when linking and allocating resources. For example, we can link each virtual user to specific types of tasks, servers, IP addresses, accounts, periods of the most active crawling, and other arbitrary attributes.
In general, the life cycle of a resource consists of certain steps:
- When you start a cluster node in the shared pool of virtual resources, additional open slots are registered, as well as links between resources;
- When a task is started by the dispatcher from the pool of virtual resources, a suitable free slot is selected and blocked. In turn, locking the parent resource results in blocking related resources, and in the absence of free slots, a failure is formed;
- Upon completion of the task, the slot of the main resource and the slots associated with it are released.
In addition to the settings specified in the node configuration, there are also user virtual resources — entities that the system operator works with. In particular, the operator uses the virtual users registry interface, which supports several useful functions at once:
- management of details and additional attributes indicating the specifics of use, in particular, virtual users can be divided into groups and used for different purposes;
- tracking the status and statistics of virtual users;
- connecting to a virtual screen - tracking work in real time, performing actions in the browser instead of a virtual user (remote desktop widget).
Sample registry of user virtual resources:

Cool case that did not catch on
In addition to informational tapes as killer-fitch, we developed a prototype search graph for performing complex searches and conducting online investigations. The main idea is to build a visual graph, in which the nodes are the templates of objects (persons, organizations, groups, publications, likes, etc.), and the links are templates of connections between the objects found.
An example of a simple search graph from people and links between them:

This approach assumes that the search begins with a minimum of known information. After the initial search, the user examines the results and gradually adds additional conditions to the search graph, narrowing the sample and increasing the depth of traversal and accuracy of the result. Ultimately, the graph takes the form in which each of the nodes is a separate information tape with the results. This tape can also be used as a source for further analysis and visualization on dashboards and widgets.

As an example, consider a few simple cases:
- find all the friends of the person with the given name;
- find all posts of a person’s friends with a given name and other attributes;
- to find all the subscribers of the pages on which the given key phrases are mentioned, or to put together an environment around certain posts or authors;
- or find intersections - authors of comments to all posts that are written by authors who once published posts on specific topics.
When we announced the development of such a fitch, our customers and partners ardently supported such an idea, it seemed to be exactly what is lacking in existing similar solutions. But after the completion of the working prototype, in practice it turned out that clients were not ready to change their internal processes, and Internet investigations were more likely considered as something that might come in handy if needed. At the same time, from the technological point of view, the functionality is serious and required further development and support. As a result, due to the lack of demand and the practical interest of our partners, this feature had to be temporarily frozen until better times.
Reincarnation
Given the current vector of development of our solutions, this fitcha still seems relevant, but from the technical side it is already seen differently. Rather, as an extension of the functionality of Cubisio, namely the editor of the domain model and the editor of data processing, which are still implemented in the form of a prototype, but provide a similar approach in a generalized form.
An example of the ontological model of the Social Networks subject area (an image of the editor will open on click):

An example of a search and analysis graph based on the above ontology (the image of the editor will open on click):

Cluster technology stack

The described system was developed in conjunction with the platform (we call it dWires) several years ago, it is still in operation and in use. The main successful solutions naturally migrated to our new developments. In particular, the described platform is the first generation of the designer of information analytical systems, from which the jsBeans platform and our other developments have sprung.
In short, the system is based on the Akka cluster, the Rhino interpreter and the Jetty embedded web server. Some useful features of the architecture can be seen in the diagram above. But It is worth noting that, in our opinion, only the concept of JavaScript bins and the communication engine that implements it, which formed the basis of jsBeans , deserve special attention.
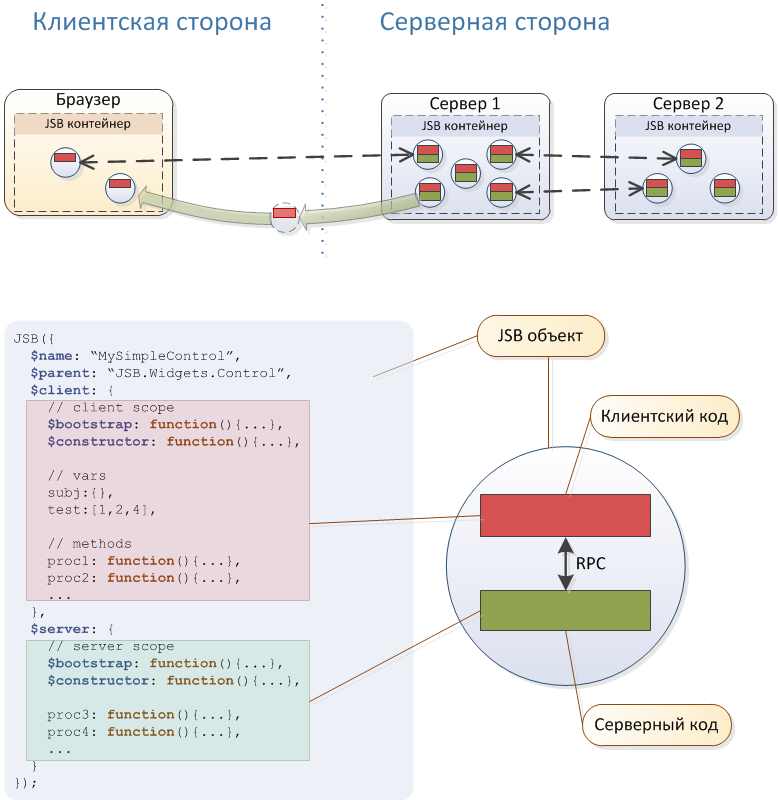
As for the rest, from the architectural point of view, nothing unique was introduced and was not planned in this system - all decisions were based on the integration of third-party components familiar to developers and predictable in operation.
Core
The main part of the kernel is written in Java. The actors implemented a plug-in and service bus, as well as key services, the main of which are the web server and the JavaScript engine. JavaScript implements the entire system interface (client and server code), as well as key project scripts describing business logic, user and crawler scripts. All necessary environments are implemented around the kernel - a message bus, a debugger, an administration console, a data access bus, text processing, a web component library, and much more.
Cluster
Akka cluster management and control of input / output nodes are programmed in a special service. Due to some features of cluster operation modes, standard Akka Cluster scripts did not meet expectations, and our virtual users hung up at the most inappropriate moment. As a result of the refinement, the connection between cluster nodes and virtual resources has become inseparable, the opportunity has appeared “to hot” (with working crawlers and users) to introduce new nodes into work and perform maintenance.
Crawlers
The virtual user farm is implemented on the basis of Selenium WebDriver with some important improvements, for example: management of saved browser profiles and network access, as well as an additional abstraction that implements the virtual user API and important features. The launch of WebDriver and the browser has also been rewritten to some extent in order to ensure seamless operation with virtual resources (browser profile, external IP and virtual screen).
Each virtual screen represents several modules ( at different times different third-party components were used ):
- the screen itself, for example, Xvfb;
- local VNC server, for example, x11vnc;
- VNC Web Viewer for remote operator control, for example, a bunch of noVNC server and its web component.
Storage
MongoDB was chosen as the main DBMS for system persistent indexes and data, which on each node is present in two roles - local and global storage. Elasticsearch, working in conjunction with MongoDB, is used as a full-text index. Also, some services use other databases and storages (H2, EhCache, Db4o).
Administration
Automatic deployment of nodes to bare OS, zoo management components, updates and administration is performed by a set of bash scripts that work through a single interface (administrator commands). This approach was the easiest and most understandable. For each deployment configuration, a universal distribution kit and a unique set of configuration files are used, the administrator’s participation is minimal.
Finally
At a quick glance, the above-described approach of using virtual users to automate the downloading of information from complex Internet resources seems to be universal and provides almost unlimited possibilities for mass downloading of any information available to the average user.
But in practice, not everything is so rosy. The above diagram of the complexity of the crawler works in relation to another manifestation - there is a lower bound and a technological ceiling on the speed and volume of the loaded information. This approach does not provide for downloading millions of objects per day without deploying an expensive cluster of dozens of servers, and in the case of simple tasks it turns out to be “shooting from a cannon at sparrows”.
All this imposes some restrictions and allows for a comprehensive solution to the problem of collecting information from Internet sources only in combination with other approaches, generally providing a middle ground.
The boy thanked the Golden Antelope for his salvation and together they went to the jungle, where no one asked for gold and everyone believed in kindness
')
(tale "Golden Antelope")
Source: https://habr.com/ru/post/454204/
All Articles