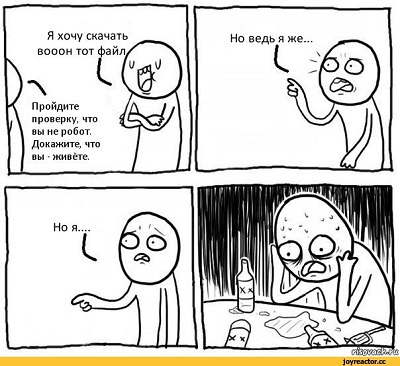
Competition of ML-systems on linguistic material. How we learned to fill in the gaps
Every year in Moscow, the conference " Dialogue ", in which linguists and data analysis specialists participate. They discuss what a natural language is, how to teach a machine to understand and process it. The conference traditionally held competitions (tracks) Dialogue Evaluation . They can participate as representatives of large companies that create solutions in the field of natural language processing (Natural Language Processing, NLP), and individual researchers. It may seem that if you are a simple student, do you have to deal with the systems that large specialists of large companies have been creating for years. Dialogue Evaluation - this is exactly the case when in the final standings a simple student may be above the eminent company.
This year will be the 9th in a row when Dialogue Evaluation is held at the Dialogue. Every year the number of competitions is different. NLP tasks such as key analysis (Sentiment Analysis), resolution of lexical polysemy (Word Sense Induction), finding typing errors (Automatic Spelling Correction), highlighting entities (Named Entity Recognition), and others have become themes for the tracks.
 This year, four groups of organizers prepared the following tracks:
This year, four groups of organizers prepared the following tracks:
Today we will tell about the last of them: what ellipse is and why teach the car to restore it in the text, how we created the new building, where you can solve this problem, how the competitions themselves went and what results the participants were able to achieve.
In the fall of 2018, we were faced with a research task related to ellipsis — the intentional omission of a chain of words in a text that can be restored from the context. How to automatically find such a pass in the text and fill it in correctly? It's easy for a native speaker, but teaching this machine is not easy. It quickly became clear that this was good competition material, and we got down to business.
')
The organization of competitions on a new theme has its own characteristics, and in many ways they seem to us to be pluses. One of the main things is the creation of a corpus (a set of markup texts for learning). What should it look like and what volume should it be? For many tasks, there are standards for the presentation of data from which you can build on. So, for example, IO / BIO / IOBES markup schemes were developed for the task of determining named entities , the CONLL format is traditionally used for the tasks of syntactic and morphological parsing, there is no need to invent anything, but you must strictly follow the guidelines.
In our case, we had to assemble the body and formulate the task ourselves.
Here we will inevitably have to make a popular linguistic introduction about what ellipsis is in general and gapping as one of its types.
Whatever ideas you may hold of a language, it’s hard to argue that the superficial level of expression (text or speech) is not the only one. Said phrase is the tip of the iceberg. Iceberg itself includes a pragmatic assessment, building a syntactic structure, selection of lexical material, and so on. Ellipsis is a phenomenon that beautifully connects the surface level with the deep level. This is the omission of duplicate syntactic structure elements. If we represent the syntactic structure of a sentence in the form of a tree and in this tree it will be possible to select identical subtrees, then often (but not always), in order for the sentence to be natural, duplicate elements are deleted. Such a deletion is called an ellipsis (Example 1).
(1) I was never called back, and I don’t understand whythey didn’t call me back .
Gaps obtained by ellipsis can be uniquely restored from the linguistic context. Compare the first example with the second (2), where there is a pass, but what exactly is missing there is not clear. This case is not an ellipse.
(2)
Gapping is one of the frequency types of ellipsis. Consider the example (3) and understand how it works.
(3) I took her for Italian, and his - for the Swede.
In all examples there are more than two sentences (clauses), they are composed among themselves. In the first clause, a verb is present (linguists, rather, they say “predicate”) and its participants accepted : I , her and for Italian . In the second clause there is no pronounced verb, there are only “remnants” (or remnants) that are not syntactically interconnected between him and the Swede , but we understand how the pass is restored.
To restore the pass, we refer to the first clause and copy the entire structure from it (example 4). We replace only those parts for which there are “parallel” remnants in the incomplete clause. We copy the predicate, we replace it with it , for Italian we replace it with a remnant for a Swede . For me, there was no parallel remnant, which means we copy it without replacement.
(4) I took her for Italian, and I took him for the Swede.
It seems that to restore the pass, it is enough to determine whether there is a gapping in this offer, find an incomplete clause and the complete clause associated with it (from which the recovery material is taken), and then understand what “remnants” (remnants) and what they correspond to in full. It seems these conditions are enough to effectively fill the gap. In this way, we are trying to imitate a process in the head of a person reading or hearing a text that may have omissions.
It is clear that a person who hears for the first time about the ellipsis and the processing difficulties associated with it may have a logical question "Why?" Skeptics would like tosuggest reading the fathers of linguistic science to explain that if the solution of an applied problem provides material that may be useful in theoretical studies, then this is a sufficient answer to the question of the purpose of such activity.
Theorists have been studying ellipsis in different languages for about 50 years, describe limitations, highlight common patterns in different languages. At the same time, we are unaware of the existence of the corpus illustrating any type of ellipsis in more than a few hundred examples. This is partly due to the rarity of the phenomenon (for example, on our data, gapping is found in no more than 5 sentences out of 10 thousand). So the creation of such a body is already an important result.
In applied systems working with textual data, the rarity of a phenomenon makes it possible to simply ignore it. The inability of the syntactic parser to recover gaps when mapping exactly will not bring many errors. But from the rare phenomena there is an extensive and variegated linguistic periphery. It seems that the experience of solving such a problem in itself should be interesting to those who want to create systems that work not only on simple, short, clean texts with common vocabulary, that is, on spherical texts in a vacuum that are practically not found in nature.
Few parsers can boast an effective system for defining and resolving ellipsis. But the ABBYY internal parser has a module responsible for restoring gaps, and it is based on hand-written rules. Thanks to this parser ability, we were able to create a large case for the competition. A potential benefit to the original parser is to replace a slow-running module. Also, while working on the case, we conducted a detailed analysis of the errors of the current system.
Our body is primarily intended for training automatic systems, which means that it is extremely important that it is voluminous and diverse. Guided by this, we built the data collection work as follows. For the corpus, we selected texts of various genres: from technical documentation and patents to news and posts from social media. All of them were marked up by the ABBYY parser. Within a month, we distributed data among linguists-razmetovchik. The markers were asked, without changing the markup, to evaluate it on a scale:
0 - there is no mapping in the offer, the markup is irrelevant.
1 - there is a mapping, and its layout is correct.
2 - there is a mapping, but there is something wrong with the markup.
3 - difficult case, is it a mapping at all?
As a result, each of the groups was useful to us. Examples from category 1 fell into the positive class of our dataset. We basically did not want to redeclare the examples from categories 2 and 3 manually in order to save time, but these examples were useful to us later to evaluate our received corps. According to them you can judge what cases the system marks stably wrong, which means that they do not fall into our body. And finally, by including in the corpus the examples assigned by razmetovchiki to category 0, we gave the systems the opportunity to “learn from the mistakes of others”, that is, not only to imitate the behavior of the original system, but to work better than it.
Each example was evaluated by two markers. After that, slightly more than half of the sentences came from the original data into the corpus. Of them consists of the whole positive class of examples and part of the negative. We decided to make the negative class twice as positive, so that, on the one hand, the classes were comparable in size, and on the other, the negative class prevailing in the language.
To keep this proportion, we had to add more negative examples to the corpus, in addition to the described examples of category 0. Let us give an example (5) of category 0, which can confuse not only the car, but also the person.
(5) But by then, Jack was in love with Cindy Page, now Mrs. Jack Switek.
In the second clause, he is not recovering in love , because it means that now Cindy Page has become Mrs. Jack Switek because she married him.
In general, for such a relatively rare syntactic phenomenon as gapping, almost any random sentence of a language is a negative example, because the probability that there will be a gapping in a random sentence is tiny. However, the use of such negative examples can lead to retraining on punctuation marks. In our case, examples for the negative class were obtained by simple criteria: the presence of a verb, the presence of a comma or a dash, the minimum sentence length is not less than 6 tokens.
For the competition, we selected a part (in a ratio of 1: 5) from the training corps, which participants were offered to use to configure their systems. The final versions of the systems were trained in the combined train and dev parts. We labeled the test case manually with our own resources; it is the 10th part of train + dev by volume. Here is the exact number of examples by class:

In addition, we added a raw markup file from the source system to the manually verified training data. It contains more than 100 thousand examples, and the participants could use this data to supplement the training sample. Looking ahead, let's say that only one participant came up with how to significantly increase the training building with the help of dirty data without losing quality.
We deliberately abandoned the use of third-party parsers and developed markup in which all the elements of interest to us are linearly marked in the text line. We used two types of markup. The first, human-readable, is designed to work with markup, and it is convenient to analyze the errors of the resulting systems. With this method, all elements of the mapping are indicated by square brackets inside the sentence. Each pair of brackets is labeled with the name of the corresponding element. We used the following notation:
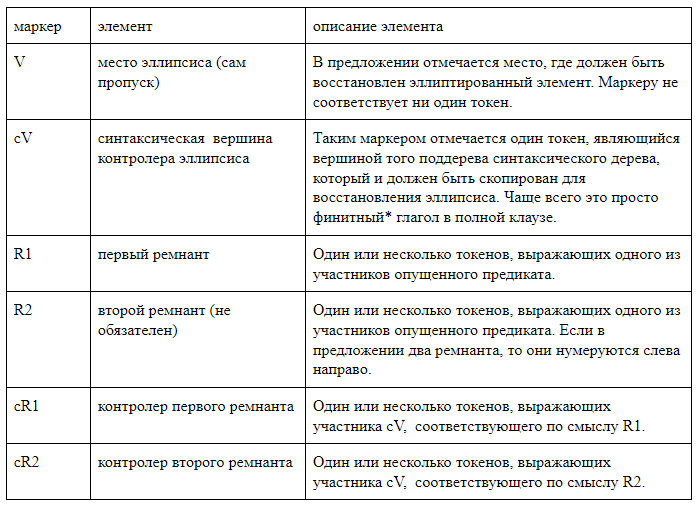

We give examples of sentences with mapping with bracket marking.
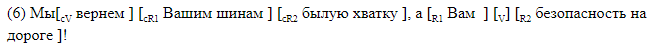
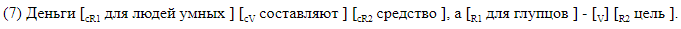

Staple markings suitable for material analysis. In the case, the data is stored in a different format, which, if desired, can be easily converted into a bracket. One line corresponds to one sentence. The columns indicate the presence of a gapping in the sentence, and for each possible label in its column the symbol offsets of the beginning and end of the segment corresponding to the element are given. This is the markup by offset, corresponding to the bracket markup in ().

Participants of AGRR-2019 could solve any of the three tasks:
Each next task should solve the previous one. It is clear that any markup is possible only in sentences, in which the binary classification shows a positive class (there is a mapping), and the complete markup includes finding the boundaries of the missed and controlling predicates.
For the problem of binary classification, we used standard metrics: accuracy and completeness - and the results of the participants were ranked by f-measure.
For the tasks of resolving the mapping and full markup, we decided to use the character-based f-measure, since the source texts were not tokenized and we didn’t want the difference in the tokenizers used by the participants to affect the results. True-negative examples did not contribute to the character-based f-measure, for each markup element its own f-measure was considered, the final result was obtained by macro-averaging over the whole body. Due to this calculation of the metric, false-positive cases were significantly penalized, which is important in the case when there are many times less positive examples in real data.
In parallel with the collection of the corps, we accepted applications for participation in the competition. As a result, we have registered more than 40 participants. Then we laid out the training building and launched the competition. Participants had 4 weeks to build their models.
The results evaluation stage was as follows: the participants received 20 thousand sentences without markup, within which the test building was mixed. The teams had to mark these data with their own systems, after which we evaluated the results of the markup on the test package. Mixing the dough in a large amount of data guaranteed us that the case with all the desire could not be able to manually mark out for the few days that were given for the run (automatic marking).
9 teams reached the final, including representatives of two IT companies, researchers from Moscow State University, Moscow Institute of Physics and Technology, National Research University Higher School of Economics and IITP RAS.
All teams, except one, participated in all three competitions. Under the terms of AGRR-2019, all teams published the code of their decisions. The summary table with the results is given in our repository , in the same place you can find links to the posted solutions of the teams with brief descriptions.
Almost all showed high results. Here are estimates of the decisions of the teams that won the prizes:
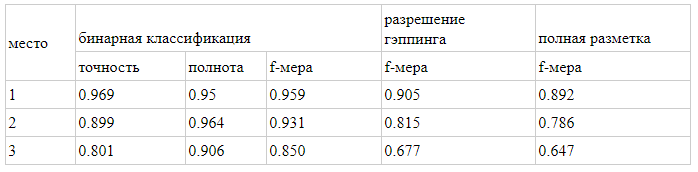
A detailed description of the top solutions will soon be available in the articles of the participants in the Dialogue book.
So, in this article we told how, taking a rare language phenomenon as a basis, to formulate a task, prepare a corpus and hold competitions. The NLP-community also benefits from such work, because competitions help to compare different architectures and approaches among themselves on specific material, and linguists receive a corpus of a rare phenomenon with the possibility of its replenishment (using the decisions of the winners). The assembled case is several times larger than the volumes of currently existing buildings (and for gapping, the volume of the body is an order of magnitude greater than the volume of the buildings, not only for Russian, but generally for all languages). All data and links to the decisions of the participants can be found in our githaba.
May 30 at the special session of the " Dialogue " dedicated to the competitions on automatic analysis of gapping, the results of AGRR-2019 will be summed up. We will tell about the organization of the competition and dwell in detail on the content of the created corps, and the participants will present selected architectures with which they solved the problem.
NLP Advanced Research Group
This year will be the 9th in a row when Dialogue Evaluation is held at the Dialogue. Every year the number of competitions is different. NLP tasks such as key analysis (Sentiment Analysis), resolution of lexical polysemy (Word Sense Induction), finding typing errors (Automatic Spelling Correction), highlighting entities (Named Entity Recognition), and others have become themes for the tracks.
This year, four groups of organizers prepared the following tracks:- Generate headlines for news articles.
- Anaphora and Coreference Resolution.
- Morphological analysis on the material of resource languages.
- Automatic analysis of one of the types of ellipsis (gapping).
Today we will tell about the last of them: what ellipse is and why teach the car to restore it in the text, how we created the new building, where you can solve this problem, how the competitions themselves went and what results the participants were able to achieve.
AGRR-2019 (Automatic Gapping Resolution for Russian)
In the fall of 2018, we were faced with a research task related to ellipsis — the intentional omission of a chain of words in a text that can be restored from the context. How to automatically find such a pass in the text and fill it in correctly? It's easy for a native speaker, but teaching this machine is not easy. It quickly became clear that this was good competition material, and we got down to business.
')
The organization of competitions on a new theme has its own characteristics, and in many ways they seem to us to be pluses. One of the main things is the creation of a corpus (a set of markup texts for learning). What should it look like and what volume should it be? For many tasks, there are standards for the presentation of data from which you can build on. So, for example, IO / BIO / IOBES markup schemes were developed for the task of determining named entities , the CONLL format is traditionally used for the tasks of syntactic and morphological parsing, there is no need to invent anything, but you must strictly follow the guidelines.
In our case, we had to assemble the body and formulate the task ourselves.
This is the task ...
Here we will inevitably have to make a popular linguistic introduction about what ellipsis is in general and gapping as one of its types.
Whatever ideas you may hold of a language, it’s hard to argue that the superficial level of expression (text or speech) is not the only one. Said phrase is the tip of the iceberg. Iceberg itself includes a pragmatic assessment, building a syntactic structure, selection of lexical material, and so on. Ellipsis is a phenomenon that beautifully connects the surface level with the deep level. This is the omission of duplicate syntactic structure elements. If we represent the syntactic structure of a sentence in the form of a tree and in this tree it will be possible to select identical subtrees, then often (but not always), in order for the sentence to be natural, duplicate elements are deleted. Such a deletion is called an ellipsis (Example 1).
(1) I was never called back, and I don’t understand why
Gaps obtained by ellipsis can be uniquely restored from the linguistic context. Compare the first example with the second (2), where there is a pass, but what exactly is missing there is not clear. This case is not an ellipse.
(2)
Gapping is one of the frequency types of ellipsis. Consider the example (3) and understand how it works.
(3) I took her for Italian, and his - for the Swede.
In all examples there are more than two sentences (clauses), they are composed among themselves. In the first clause, a verb is present (linguists, rather, they say “predicate”) and its participants accepted : I , her and for Italian . In the second clause there is no pronounced verb, there are only “remnants” (or remnants) that are not syntactically interconnected between him and the Swede , but we understand how the pass is restored.
To restore the pass, we refer to the first clause and copy the entire structure from it (example 4). We replace only those parts for which there are “parallel” remnants in the incomplete clause. We copy the predicate, we replace it with it , for Italian we replace it with a remnant for a Swede . For me, there was no parallel remnant, which means we copy it without replacement.
(4) I took her for Italian, and I took him for the Swede.
It seems that to restore the pass, it is enough to determine whether there is a gapping in this offer, find an incomplete clause and the complete clause associated with it (from which the recovery material is taken), and then understand what “remnants” (remnants) and what they correspond to in full. It seems these conditions are enough to effectively fill the gap. In this way, we are trying to imitate a process in the head of a person reading or hearing a text that may have omissions.
So, why do you need it?
It is clear that a person who hears for the first time about the ellipsis and the processing difficulties associated with it may have a logical question "Why?" Skeptics would like to
Theorists have been studying ellipsis in different languages for about 50 years, describe limitations, highlight common patterns in different languages. At the same time, we are unaware of the existence of the corpus illustrating any type of ellipsis in more than a few hundred examples. This is partly due to the rarity of the phenomenon (for example, on our data, gapping is found in no more than 5 sentences out of 10 thousand). So the creation of such a body is already an important result.
In applied systems working with textual data, the rarity of a phenomenon makes it possible to simply ignore it. The inability of the syntactic parser to recover gaps when mapping exactly will not bring many errors. But from the rare phenomena there is an extensive and variegated linguistic periphery. It seems that the experience of solving such a problem in itself should be interesting to those who want to create systems that work not only on simple, short, clean texts with common vocabulary, that is, on spherical texts in a vacuum that are practically not found in nature.
Few parsers can boast an effective system for defining and resolving ellipsis. But the ABBYY internal parser has a module responsible for restoring gaps, and it is based on hand-written rules. Thanks to this parser ability, we were able to create a large case for the competition. A potential benefit to the original parser is to replace a slow-running module. Also, while working on the case, we conducted a detailed analysis of the errors of the current system.
How we created the hull
Our body is primarily intended for training automatic systems, which means that it is extremely important that it is voluminous and diverse. Guided by this, we built the data collection work as follows. For the corpus, we selected texts of various genres: from technical documentation and patents to news and posts from social media. All of them were marked up by the ABBYY parser. Within a month, we distributed data among linguists-razmetovchik. The markers were asked, without changing the markup, to evaluate it on a scale:
0 - there is no mapping in the offer, the markup is irrelevant.
1 - there is a mapping, and its layout is correct.
2 - there is a mapping, but there is something wrong with the markup.
3 - difficult case, is it a mapping at all?
As a result, each of the groups was useful to us. Examples from category 1 fell into the positive class of our dataset. We basically did not want to redeclare the examples from categories 2 and 3 manually in order to save time, but these examples were useful to us later to evaluate our received corps. According to them you can judge what cases the system marks stably wrong, which means that they do not fall into our body. And finally, by including in the corpus the examples assigned by razmetovchiki to category 0, we gave the systems the opportunity to “learn from the mistakes of others”, that is, not only to imitate the behavior of the original system, but to work better than it.
Each example was evaluated by two markers. After that, slightly more than half of the sentences came from the original data into the corpus. Of them consists of the whole positive class of examples and part of the negative. We decided to make the negative class twice as positive, so that, on the one hand, the classes were comparable in size, and on the other, the negative class prevailing in the language.
To keep this proportion, we had to add more negative examples to the corpus, in addition to the described examples of category 0. Let us give an example (5) of category 0, which can confuse not only the car, but also the person.
(5) But by then, Jack was in love with Cindy Page, now Mrs. Jack Switek.
In the second clause, he is not recovering in love , because it means that now Cindy Page has become Mrs. Jack Switek because she married him.
In general, for such a relatively rare syntactic phenomenon as gapping, almost any random sentence of a language is a negative example, because the probability that there will be a gapping in a random sentence is tiny. However, the use of such negative examples can lead to retraining on punctuation marks. In our case, examples for the negative class were obtained by simple criteria: the presence of a verb, the presence of a comma or a dash, the minimum sentence length is not less than 6 tokens.
For the competition, we selected a part (in a ratio of 1: 5) from the training corps, which participants were offered to use to configure their systems. The final versions of the systems were trained in the combined train and dev parts. We labeled the test case manually with our own resources; it is the 10th part of train + dev by volume. Here is the exact number of examples by class:
In addition, we added a raw markup file from the source system to the manually verified training data. It contains more than 100 thousand examples, and the participants could use this data to supplement the training sample. Looking ahead, let's say that only one participant came up with how to significantly increase the training building with the help of dirty data without losing quality.
Markup Format
We deliberately abandoned the use of third-party parsers and developed markup in which all the elements of interest to us are linearly marked in the text line. We used two types of markup. The first, human-readable, is designed to work with markup, and it is convenient to analyze the errors of the resulting systems. With this method, all elements of the mapping are indicated by square brackets inside the sentence. Each pair of brackets is labeled with the name of the corresponding element. We used the following notation:
We give examples of sentences with mapping with bracket marking.
Staple markings suitable for material analysis. In the case, the data is stored in a different format, which, if desired, can be easily converted into a bracket. One line corresponds to one sentence. The columns indicate the presence of a gapping in the sentence, and for each possible label in its column the symbol offsets of the beginning and end of the segment corresponding to the element are given. This is the markup by offset, corresponding to the bracket markup in ().
Tasks for participants
Participants of AGRR-2019 could solve any of the three tasks:
- Binary classification. It is necessary to determine whether there is a gapping in the proposal.
- Permission gapping. You need to restore the position of the skip (V) and the position of the verb controller (cV).
- Full markup. It is necessary to define offsets for all elements of the gapping.
Each next task should solve the previous one. It is clear that any markup is possible only in sentences, in which the binary classification shows a positive class (there is a mapping), and the complete markup includes finding the boundaries of the missed and controlling predicates.
Metrics
For the problem of binary classification, we used standard metrics: accuracy and completeness - and the results of the participants were ranked by f-measure.
For the tasks of resolving the mapping and full markup, we decided to use the character-based f-measure, since the source texts were not tokenized and we didn’t want the difference in the tokenizers used by the participants to affect the results. True-negative examples did not contribute to the character-based f-measure, for each markup element its own f-measure was considered, the final result was obtained by macro-averaging over the whole body. Due to this calculation of the metric, false-positive cases were significantly penalized, which is important in the case when there are many times less positive examples in real data.
The course of the competition
In parallel with the collection of the corps, we accepted applications for participation in the competition. As a result, we have registered more than 40 participants. Then we laid out the training building and launched the competition. Participants had 4 weeks to build their models.
The results evaluation stage was as follows: the participants received 20 thousand sentences without markup, within which the test building was mixed. The teams had to mark these data with their own systems, after which we evaluated the results of the markup on the test package. Mixing the dough in a large amount of data guaranteed us that the case with all the desire could not be able to manually mark out for the few days that were given for the run (automatic marking).
Competition Results
9 teams reached the final, including representatives of two IT companies, researchers from Moscow State University, Moscow Institute of Physics and Technology, National Research University Higher School of Economics and IITP RAS.
All teams, except one, participated in all three competitions. Under the terms of AGRR-2019, all teams published the code of their decisions. The summary table with the results is given in our repository , in the same place you can find links to the posted solutions of the teams with brief descriptions.
Almost all showed high results. Here are estimates of the decisions of the teams that won the prizes:
A detailed description of the top solutions will soon be available in the articles of the participants in the Dialogue book.
So, in this article we told how, taking a rare language phenomenon as a basis, to formulate a task, prepare a corpus and hold competitions. The NLP-community also benefits from such work, because competitions help to compare different architectures and approaches among themselves on specific material, and linguists receive a corpus of a rare phenomenon with the possibility of its replenishment (using the decisions of the winners). The assembled case is several times larger than the volumes of currently existing buildings (and for gapping, the volume of the body is an order of magnitude greater than the volume of the buildings, not only for Russian, but generally for all languages). All data and links to the decisions of the participants can be found in our githaba.
May 30 at the special session of the " Dialogue " dedicated to the competitions on automatic analysis of gapping, the results of AGRR-2019 will be summed up. We will tell about the organization of the competition and dwell in detail on the content of the created corps, and the participants will present selected architectures with which they solved the problem.
NLP Advanced Research Group
Source: https://habr.com/ru/post/453974/
All Articles