A couple of words in defense of the monolith
We compare the features of microservice and monolithic architecture, their advantages and disadvantages. The article was prepared for Habr on the materials of our mitap Hot Backend , which was held in Samara on February 9, 2019. We consider the factors of choice of architecture, depending on the specific task.
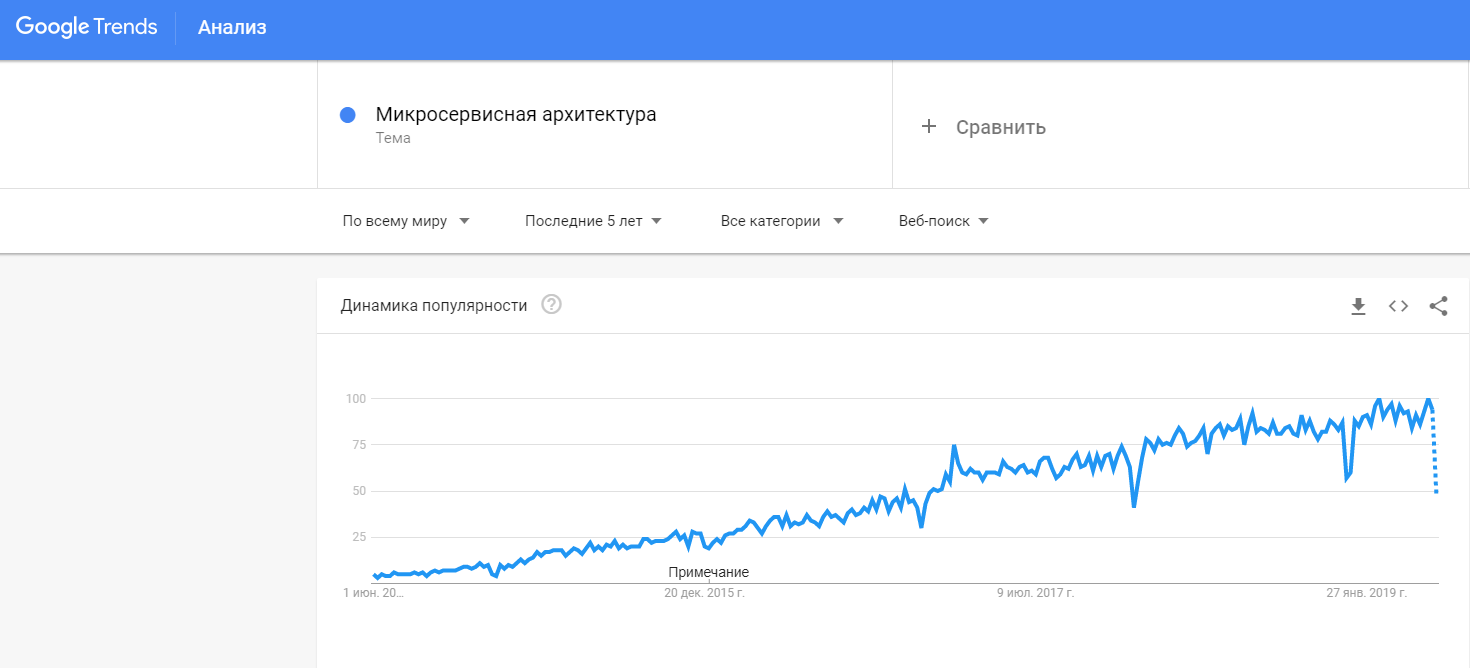
Even 5 years ago no one had heard of microservices. However, their popularity is increasing from year to year, according to Google Trends statistics .
')
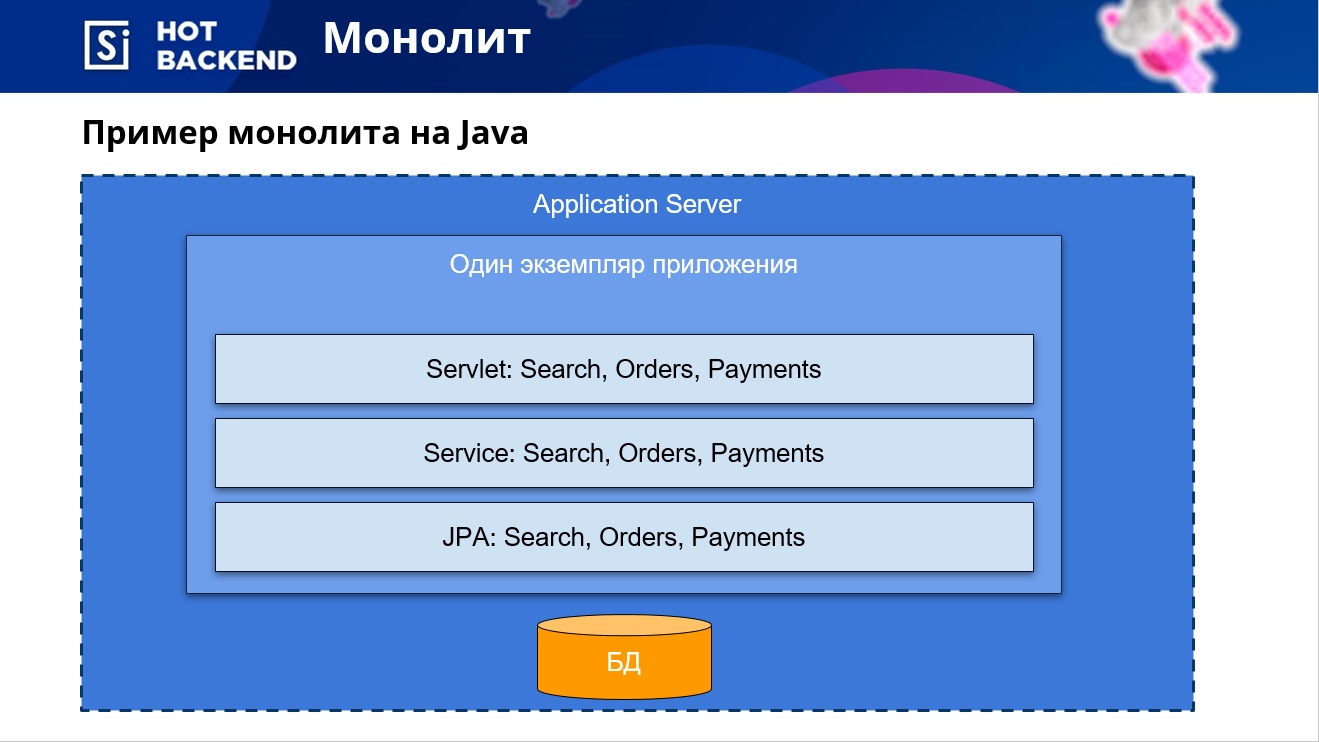
If the project uses a monolithic architecture, then the developer has only one application, all components and modules of which work with a single base.
The microservice architecture assumes a breakdown into modules that run as separate processes and can have separate servers. Each microservice works with its database, and all these services can communicate with each other both synchronously (http) and asynchronously. At the same time to optimize the architecture, it is desirable to minimize the relationship between services.
The diagram below is simplified, reflecting primarily the business components.

At least four advantages of microservice architecture can be distinguished:
Independent scaling and deployment
An independent deployment is provided for each microservice, and this is convenient when updating individual modules. If the load on the module increases, the corresponding microservice can be scaled without affecting the rest. This allows you to flexibly distribute the load and save resources.
Independent development
Each microservice (for example, a memory module) can be developed by one team in order to increase the speed of creating a software product.
Resilience
The failure of one microservice does not affect the performance of other modules.
Heterogeneity
Each team is free to choose its own language and technology implementation of microservices, however, it is desirable that they have compatible interfaces.
Among the developers, you can hear the opinion that the monolithic architecture is outdated, it is difficult to accompany and scale, it quickly grows into a “big lump of dirt” and is practically anti-pattern, that is, its presence in the code is undesirable. As proof of this view, large companies are often cited, for example, Netflix, which switched to microservice architecture in their projects.
Let's see if everyone really should move from monolith to microservices following the example of the largest brands?
Problem one: decomposition
Ideally, the application should be divided into microservices in such a way that they interact with each other as little as possible, otherwise the application will be difficult to maintain. In this case, decomposition is difficult to implement at the beginning of development, when business problems and the subject area may still change with the appearance of new requirements. Refactoring is expensive.
If it becomes necessary to transfer part of the functions from service A to service B, then there may be difficulties: for example, services are made in different languages, internal calls to services become networked, other libraries need to be connected. We can check the correctness of refactoring only with the help of tests.

Problem Two: Transactions
Another problem is connected with the fact that microservices do not have the concept of distributed transactions. We can guarantee the architectural integrity of a business operation only within one microservice. If the operation involves several microservices, different databases can be used there, and such a transaction will have to be abandoned. To solve this problem, there are different methods used in business, when accessibility is more important than integrity. At the same time, compensating mechanisms are provided in case something goes wrong. For example, if the goods are not in stock, you need to make a refund to the buyer's account.
If the monolith gives us architectural integrity automatically, then with microservices you need to invent your own mechanism and use libraries with ready-made solutions. When distributing operations between services, it is better to request data synchronously, and perform subsequent actions asynchronously. If it is impossible to access one of the services, the team will be queued as soon as it becomes available again.
In this regard, it is necessary to revise the approach to the user interface. The user should receive a notification that some actions are performed not immediately, but within a certain time. When the application is processed, he receives an invitation to see the results.

Problem Three: Report Building
If we use a monolithic architecture with a single database, to build a complex report, we can write select and pull up several data plates: sooner or later they will be output. However, on microservices this data can be scattered across different databases.
For example, we need to display a list of companies with certain metrics. When displaying a simple list of companies, everything works. And if you need to add metrics that are in a different database? Yes, we can make an additional request and request a metric using the TIN. And if this list needs to be filtered and sorted? The list of companies can be very large, and then we have to enter an additional service with its database - reports.

Problem Four: High Complexity
Work on distributed services is more difficult: all requests are carried out over the network and can “plug in”, you need to provide a callback mechanism (will it call again? How many times?). These are “bricks” that gradually accumulate and contribute to the increase in the complexity of the project.
Services can be developed by several different teams, and you need to document them, keep the documentation up to date, warn other teams when changing versions. These are additional labor costs.
If each team has independent deployment, you need to maintain at least the previous version and disable it only after all consumers of the service switch to the new API.
Of course, we can take out all the API in a kind of artifact that will be publicly available. But, first, services can be written in different languages, and secondly, it is not recommended to do so. For example, in one of our projects, we abandoned this at the request of the customer related to security concerns. Each microservice has a separate repository, and the customer does not give access to them.
In the development process, everything can work correctly, and then - no. It happens that in case of exceptions, the application tries to process them endlessly, and this gives a big load - the whole system “falls”. To avoid such situations, you need to configure everything, for example, limit the number of attempts, not return this call to the queue at the same second, etc.


Problem Five: the complexity of testing, tracing and debugging
To test any problem, you need to download all involved microservices. Debugging becomes a non-trivial task, and all logs need to be collected somewhere in one place. At the same time logs need as much as possible to figure out what happened. To track the problem you need to understand the entire path that passed the message. Unit tests are not enough here, since errors are likely at the interface of services. When making changes, you can make sure that it works only after running on the stand. We can limit each microservice to a certain amount of memory (for example, 500 megabytes), but there are times of peak load when it takes up to two gigabytes. There are times when the system starts to slow down. As a result, resources can be spent on something that does not belong to the immediate tasks of the client: for example, there are only two business microservices, and half of the resources are spent on three additional microservices that support the work of the others.

When choosing between monolithic and microservice architecture, first of all you need to proceed from the complexity of the domain and the need for scaling.
If the subject area is simple, and the global addition of the number of users is not expected, then microservices can be used without doubt. In other cases, it is better to start development on a monolith and save resources if scaling is not required. If the subject area is complex, and at the initial stage final requirements are not defined, it is also better to start with a monolith - in order not to redo microservices several times. With the further development of the project, its individual parts can be singled out in microservices.
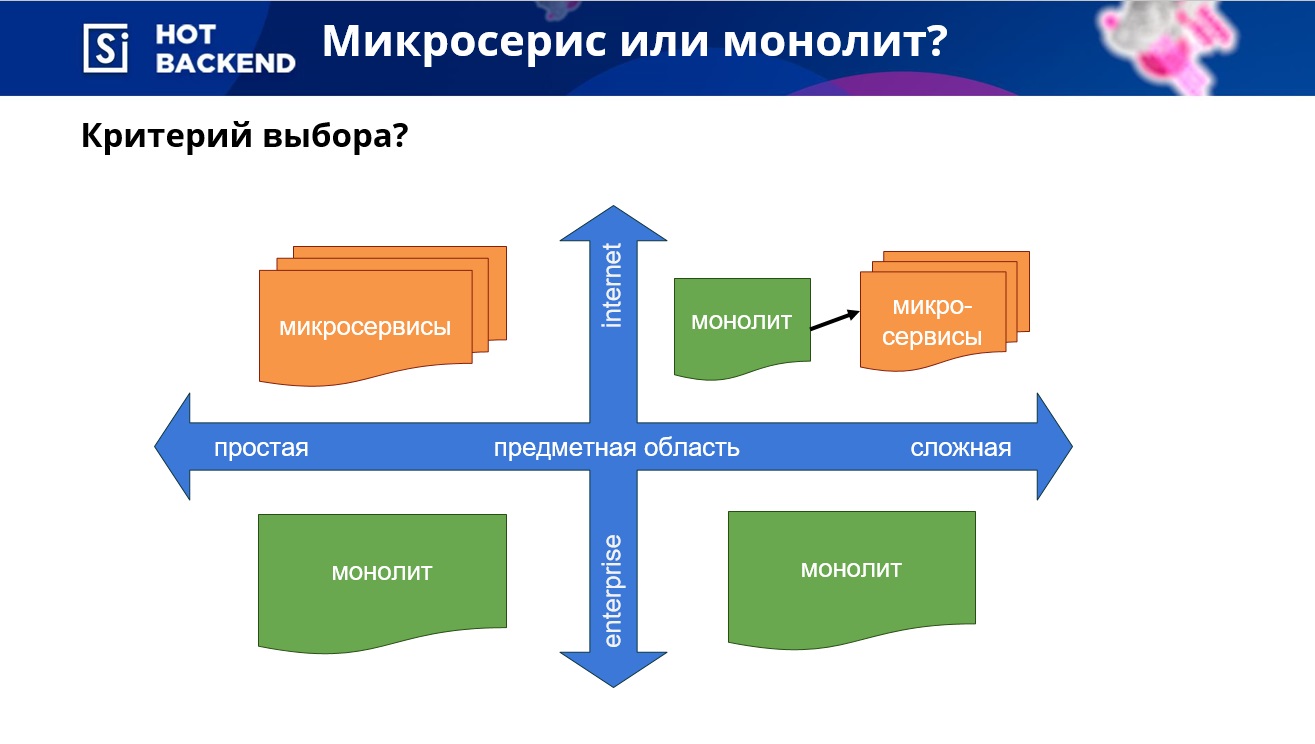
The advantage is the presence of boundaries at the start of the project, because it will help not to disturb them in the development process. It also makes sense to start with a single database, but define its scheme for each module (for example, a payment scheme). Subsequently, this will help simplify the division of modules into microservices. In this case, we observe the boundaries of the modules and can use microservices.
Each module must have its own API, so that later it can be selected and made the module a microservice.

Having determined the boundaries of the modules, you can proceed to decomposition into microservices, if necessary. In about 90% of cases, it will be possible to stay on the monolith, but if necessary, it will be easier and cheaper for you to change the architecture.
In our practice of working with monolith and microservices we came to the following conclusions:
Even 5 years ago no one had heard of microservices. However, their popularity is increasing from year to year, according to Google Trends statistics .
')
Monolith and microservices: examples
If the project uses a monolithic architecture, then the developer has only one application, all components and modules of which work with a single base.
The microservice architecture assumes a breakdown into modules that run as separate processes and can have separate servers. Each microservice works with its database, and all these services can communicate with each other both synchronously (http) and asynchronously. At the same time to optimize the architecture, it is desirable to minimize the relationship between services.
The diagram below is simplified, reflecting primarily the business components.
Microservices: advantages
At least four advantages of microservice architecture can be distinguished:
Independent scaling and deployment
An independent deployment is provided for each microservice, and this is convenient when updating individual modules. If the load on the module increases, the corresponding microservice can be scaled without affecting the rest. This allows you to flexibly distribute the load and save resources.
Independent development
Each microservice (for example, a memory module) can be developed by one team in order to increase the speed of creating a software product.
Resilience
The failure of one microservice does not affect the performance of other modules.
Heterogeneity
Each team is free to choose its own language and technology implementation of microservices, however, it is desirable that they have compatible interfaces.
Among the developers, you can hear the opinion that the monolithic architecture is outdated, it is difficult to accompany and scale, it quickly grows into a “big lump of dirt” and is practically anti-pattern, that is, its presence in the code is undesirable. As proof of this view, large companies are often cited, for example, Netflix, which switched to microservice architecture in their projects.
Let's see if everyone really should move from monolith to microservices following the example of the largest brands?
Transition to microservices: possible difficulties
Problem one: decomposition
Ideally, the application should be divided into microservices in such a way that they interact with each other as little as possible, otherwise the application will be difficult to maintain. In this case, decomposition is difficult to implement at the beginning of development, when business problems and the subject area may still change with the appearance of new requirements. Refactoring is expensive.
If it becomes necessary to transfer part of the functions from service A to service B, then there may be difficulties: for example, services are made in different languages, internal calls to services become networked, other libraries need to be connected. We can check the correctness of refactoring only with the help of tests.
Problem Two: Transactions
Another problem is connected with the fact that microservices do not have the concept of distributed transactions. We can guarantee the architectural integrity of a business operation only within one microservice. If the operation involves several microservices, different databases can be used there, and such a transaction will have to be abandoned. To solve this problem, there are different methods used in business, when accessibility is more important than integrity. At the same time, compensating mechanisms are provided in case something goes wrong. For example, if the goods are not in stock, you need to make a refund to the buyer's account.
If the monolith gives us architectural integrity automatically, then with microservices you need to invent your own mechanism and use libraries with ready-made solutions. When distributing operations between services, it is better to request data synchronously, and perform subsequent actions asynchronously. If it is impossible to access one of the services, the team will be queued as soon as it becomes available again.
In this regard, it is necessary to revise the approach to the user interface. The user should receive a notification that some actions are performed not immediately, but within a certain time. When the application is processed, he receives an invitation to see the results.
Problem Three: Report Building
If we use a monolithic architecture with a single database, to build a complex report, we can write select and pull up several data plates: sooner or later they will be output. However, on microservices this data can be scattered across different databases.
For example, we need to display a list of companies with certain metrics. When displaying a simple list of companies, everything works. And if you need to add metrics that are in a different database? Yes, we can make an additional request and request a metric using the TIN. And if this list needs to be filtered and sorted? The list of companies can be very large, and then we have to enter an additional service with its database - reports.
Problem Four: High Complexity
Work on distributed services is more difficult: all requests are carried out over the network and can “plug in”, you need to provide a callback mechanism (will it call again? How many times?). These are “bricks” that gradually accumulate and contribute to the increase in the complexity of the project.
Services can be developed by several different teams, and you need to document them, keep the documentation up to date, warn other teams when changing versions. These are additional labor costs.
If each team has independent deployment, you need to maintain at least the previous version and disable it only after all consumers of the service switch to the new API.
Of course, we can take out all the API in a kind of artifact that will be publicly available. But, first, services can be written in different languages, and secondly, it is not recommended to do so. For example, in one of our projects, we abandoned this at the request of the customer related to security concerns. Each microservice has a separate repository, and the customer does not give access to them.
In the development process, everything can work correctly, and then - no. It happens that in case of exceptions, the application tries to process them endlessly, and this gives a big load - the whole system “falls”. To avoid such situations, you need to configure everything, for example, limit the number of attempts, not return this call to the queue at the same second, etc.
Problem Five: the complexity of testing, tracing and debugging
To test any problem, you need to download all involved microservices. Debugging becomes a non-trivial task, and all logs need to be collected somewhere in one place. At the same time logs need as much as possible to figure out what happened. To track the problem you need to understand the entire path that passed the message. Unit tests are not enough here, since errors are likely at the interface of services. When making changes, you can make sure that it works only after running on the stand. We can limit each microservice to a certain amount of memory (for example, 500 megabytes), but there are times of peak load when it takes up to two gigabytes. There are times when the system starts to slow down. As a result, resources can be spent on something that does not belong to the immediate tasks of the client: for example, there are only two business microservices, and half of the resources are spent on three additional microservices that support the work of the others.
Microservice or monolith: selection criteria
When choosing between monolithic and microservice architecture, first of all you need to proceed from the complexity of the domain and the need for scaling.
If the subject area is simple, and the global addition of the number of users is not expected, then microservices can be used without doubt. In other cases, it is better to start development on a monolith and save resources if scaling is not required. If the subject area is complex, and at the initial stage final requirements are not defined, it is also better to start with a monolith - in order not to redo microservices several times. With the further development of the project, its individual parts can be singled out in microservices.
The advantage is the presence of boundaries at the start of the project, because it will help not to disturb them in the development process. It also makes sense to start with a single database, but define its scheme for each module (for example, a payment scheme). Subsequently, this will help simplify the division of modules into microservices. In this case, we observe the boundaries of the modules and can use microservices.
Each module must have its own API, so that later it can be selected and made the module a microservice.
Having determined the boundaries of the modules, you can proceed to decomposition into microservices, if necessary. In about 90% of cases, it will be possible to stay on the monolith, but if necessary, it will be easier and cheaper for you to change the architecture.
In our practice of working with monolith and microservices we came to the following conclusions:
- Do not go to microservices just because they are used by Netflix, Twitter, Facebook
- Start with two or three microservices that interact with each other, work out all the non-functional requirements (security, fault tolerance, scalability, etc.) in detail, and only then proceed to the other services.
- Automate everything possible
- Set up monitoring
- Write autotests
- Do not use distributed transactions (but this is not a reason to refuse data integrity guarantees).
- If you want to use the microservice architecture, be prepared for the fact that the development can cost you about 3 times more expensive than the monolith. However, both technologies have their own advantages and disadvantages, each of them has its own niche.
Source: https://habr.com/ru/post/453932/
All Articles