Neural networks prefer textures and how to deal with it.

Recently, several articles criticized ImageNet, perhaps the most well-known set of images used to train neural networks.
In the first article, Approximating CNNs with bag-of-local features models works surprisingly well on ImageNet, the authors take a model similar to bag-of-words and use fragments from the image as the “words”. These fragments can be up to 9x9 pixels. And at the same time, on such a model, where any information about the spatial arrangement of these fragments is completely absent, the authors obtain accuracy from 70 to 86% (for example, the accuracy of the usual ResNet-50 is ~ 93%).
In the second article, ImageNet-trained CNNs are biased along texture, the authors come to the conclusion that the ImageNet data set itself and how people and neural networks perceive images are to blame, and suggest using the new dataset - Stylized-ImageNet.
More details about what people see in pictures, and what neural networks see
ImageNet
The ImageNet data set was created in 2006 by the efforts of Professor Fei-Fei Li and continues to evolve to this day. At the moment, it contains about 14 million images belonging to more than 20 thousand different categories.
Since 2010, a subset of this data set, known as ImageNet 1K with ~ 1 million images and a thousand classes, has been used in the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) competition. At this competition in 2012, AlexNet “shot”, a convolutional neural network that reached top-1 accuracy of 60% and top-5 at 80%.
It is on this subset of dataset that people from the academic environment are measured by their SOTA when they offer new network architectures.
A little about the learning process on this dataset. It will be about the training protocol on ImageNet in the academic environment. That is, when we are shown in the article the results of some SE block, ResNeXt or DenseNet network, the process looks like this: the network is trained for 90 epochs, the learning rate decreases by 30 and 60 epoch, each time 10 times, as an optimizer A normal SGD with a small weight decay is selected, only RandomCrop and HorizontalFlip are used from augmentations, the image is usually resized to 224x224 pixels.
Here is an example pytorch script for learning on ImageNet.
BagNet
Returning to the previously mentioned articles. In the first of these, the authors wanted a model that would be easier to interpret than ordinary deep networks. Inspired by the idea of bag-of-feature models, they create their own family of models - BagNets. Using the usual ResNet-50 network as a basis.
Replacing some 3x3 convolutions in 1x1 in ResNet-50, they achieve that the receptive field of neurons on the last convolutional layer is significantly reduced, up to 9x9 pixels. Thus, they limit the information available to a single neuron to a very small fragment of the entire image - a patch of several pixels. It should be noted that for the untouched ResNet-50, the size of the receptive field is more than 400 pixels, which completely covers the image, which is usually resized to 224x224 pixels.
This patch is the maximum fragment of the image from which the model could extract spatial data. At the end of the model, all the data was simply summed up and the model could not in any way know where each patch is relative to the other patches.
In total, three variants of networks with receptive field 9x9, 17x17 and 33x33 were tested. And, despite the complete lack of spatial information, such models were able to achieve good accuracy in the classification on ImageNet. Top-5 accuracy for patches 9x9 was 70%, for 17x17 - 80%, for 33x33 - 86%. For comparison, the ResNet-50 top-5 accuracy is approximately 93%.

The structure of the model is shown in the figure above. Each patch of qxqx3 pixels cut from the image is converted into a vector 2048 in length by the network. Then this vector is fed to the input of the linear classifier, which gives scores for each of the 1000 classes. By collecting the scores of each patch in a 2d array, you can get a heatmap for each class and each pixel of the original image. The final scores for the image were obtained by summing the heatmap of each class.
Examples of heatmaps for some classes:

As you can see, the biggest contribution to the benefit of one or another class is made by patches located at the edges of the objects. Patches from the background are almost ignored. So far everything is going fine.
Look at the most informative patches:

For example, the authors took four classes. For each of them, we chose 2x7 most significant patches (that is, patches where the score of this class was the highest). The top row of 7 patches is taken from the images of the corresponding class only, the bottom one - from the entire image sample.
With these pictures you can see remarkable. For example, for the tench class (tench, fish) fingers are a characteristic feature. Yes, ordinary human fingers on a green background. And all because almost all the images with this class there is a fisherman who, in fact, holds this fish in his hands, bragging about the trophy.

For laptop computers, character keys are the letter keys. Typewriter keys are also counted in this class.
For a book cover a characteristic feature are letters on a colored background. Let it even be the inscription on a T-shirt or on the package.
It would seem that this problem should not bother us. Since it is inherent only in a narrow class of networks with a very limited receptive field. But then, the authors considered a correlation between the logits (network outputs before the final softmax) assigned to each BagNet class with different receptive field, and the logits from VGG-16, which has a sufficiently large receptive field. And they found it quite high.

The authors wondered if BagNet contained any hints about how other networks make decisions.
For one of the tests, they used such a technique as Image Scrambling. Which consisted in using a texture generator based on gram matrices to create a picture where the textures are saved, but spatial information is missing.

VGG-16, trained in ordinary full-fledged pictures, coped with such scrambled pictures pretty well. Its top-5 accuracy dropped from 90% to 80%. That is, even the networks with rather large receptive field still preferred to memorize textures and ignore spatial information. Therefore, their accuracy and did not fall heavily on scrambled images.
The authors conducted a series of experiments where they compared which parts of the images are most significant for BagNet and other networks (VGG-16, ResNet-50, ResNet-152 and DenseNet-169). Everything hinted that the rest of the networks, like BagNet, when making decisions, rely on small fragments of images and make approximately the same mistakes. This was especially noticeable for not very deep networks like VGG.
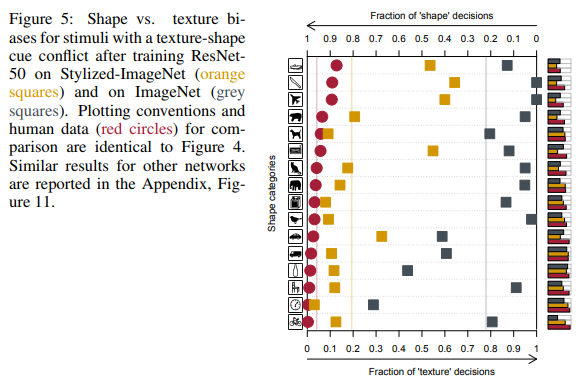
This tendency of networks to make decisions based on textures, unlike us - people who prefer the form (see figure below), prompted the authors of the second article to create a new data set based on ImageNet.
Stylized ImageNet
First of all, the authors of the article using style transfer created a set of images where the form (spatial data) and textures in one image contradicted each other. And compared the results of people and deep convolutional networks of different architectures on a synthesized data set of 16 classes.

In the extreme right figure, people see a cat, a network - an elephant.

Comparison of results of people and neural networks.
As you can see, when referring an object to a particular class, people relied on the shape of objects, neural networks - on textures. In the picture above, people saw a cat, a network - an elephant.
Yes, here you can find fault with the fact that the networks are also somewhat right, and this, for example, could be an elephant, photographed from close range, with a tattoo of a beloved cat. But the fact that the networks, when making decisions, do not behave like people, the authors considered the problem and began to search for ways to solve it.
As mentioned above, relying only on textures, the network is able to achieve a good result at 86% top-5 accuracy. And this is not about several classes where textures help to properly classify images, but about most classes.
The problem is precisely in ImageNet itself, since it will be shown later that the network is able to learn the shape, but does not, because there are enough textures on this data set, and the neurons responsible for the textures are on shallow layers, which are much easier to train.
Using this time a somewhat different mechanism AdaIN fast style transfer, the authors created a new data set - Stylized ImageNet. The shape of the objects was taken from ImageNet, and a set of textures from this competition on Kaggle . The script for generation is available by reference .

Further, for brevity, ImageNet will be denoted as IN , Stylized ImageNet as SIN .
The authors took ResNet-50 and three BagNet with different receptive field and trained on a separate model for each of the data sets.
And that's what they did:
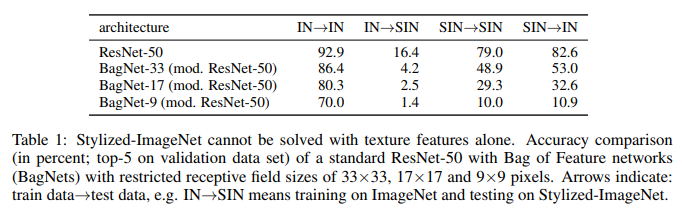
What we see here. ResNet-50, trained on IN, is completely incapacitated on SIN. What partly confirms the fact that when training for IN, the network overrides textures and ignores the shape of objects. At the same time, ResNet-50 trained in SIN does an excellent job with both SIN and IN. That is, if you deprive it of a simple path, the network goes along the difficult path - it teaches the form of objects.
BagNet is finally beginning to behave as expected, especially on small patches, as it has nothing to catch on - textural information is simply not available in the SIN.
In those sixteen classes mentioned earlier, ResNet-50, trained in SIN, began to give answers more similar to those given by people:
In addition to simple training ResNet-50 on SIN, the authors tried to train the network on a mixed set of SIN and IN, including fine-tuning separately on pure IN.

As you can see, when using SIN + IN for training, the results improved not only on the main task - image classification on ImageNet, but also on the task of detecting objects on the PASCAL VOC 2007 data set.
In addition, the networks trained on the SIN have become more resistant to different noise in the data.
Conclusion
Even now, in 2019, after seven years past with AlexNet's success, when neural networks are widely used in computer vision, when ImageNet 1K de facto became the standard for evaluating the performance of models in an academic environment, the mechanism of how neural networks make decisions is not quite clear. . And how does this affect the data sets on which these networks were trained.
The authors of the first article attempted to shed light on how such decisions are made in networks with a bag-of-features-based architecture with a limited receptive field that is easier to interpret. And, comparing the answers from BagNet and the usual deep neural networks, they came to the conclusion that the decision-making processes in them are quite similar.
The authors of the second article compared the way people and neural networks perceive images in which the form and textures contradict each other. And proposed to reduce the differences in perception to use a new data set - Stylized ImageNet. Having received as a bonus a gain in accuracy of classification on ImageNet and detection on third-party data sets.
The main conclusion can be drawn as follows: the networks that study in the pictures, having the ability to memorize the higher-level spatial properties of objects, prefer an easier way to achieve the goal — overfit to textures. If the data set on which they train allows it.
In addition to academic interest, the problem of overfitting on textures is also important for all of us who use pre-trained models for transfer learning in their tasks.
An important consequence for us of all this is that you shouldn’t trust the model models weights that were pre-trained on ImageNet, since for most of them fairly simple augmentations were used that in no way contribute to getting rid of overfitting. And it is better, if there are opportunities, to have models, trained with more serious augmentations, or with Stylized ImageNet + ImageNet in the stash. To always have the opportunity to compare which of them is better suited for our current task.
')
Source: https://habr.com/ru/post/453788/
All Articles