Solving the Best Reverser problem with PHDays 9
Hello!
My name is Marat Gayanov, I want to share with you my solution to the problem from the Best Reverser competition , to show how to make keygen for this case.
In this competition, participants are provided with ROM games for the Sega Mega Drive ( best_reverser_phd9_rom_v4.bin ).
')
The task: to choose such a key, which together with the participant’s email address will be recognized as valid.
So the solution is ...
The program accepts not every key: you need to fill in the entire field, this is 16 characters. If the key is shorter, then you will see the message: “Wrong length! Try again ... ".
Let's try to find this line in the program, for which we use the binary search (Alt-B). What will we find?
Let's find not only this, but also a number of other service lines: “Wrong key! Try again ... ”and“ YOU ARE THE BEST REVERSER! ”.


The labels
Put a break on reading the address
The debugger leads on
There is nothing interesting in the block itself. It is much more interesting who transfers control here. Enjoying a call stack:

Click and get here - on instruction

We see that all possible messages were found in one place. But let's find out where the control is transferred to the

Put a break to the address

This is a good find, we will get everything out through it. But first, mark the key bytes for convenience:

Scroll up from this place, we see that the mail is stored next to the key:

We plunge deeper and deeper, and it's time to find the criterion for the correctness of the key. Rather, the first half of the key.
It is logical to assume that immediately after checking the length will follow other operations with the key. Consider the block immediately after the check:

This block is preliminary work. The function
I called the function like this because it considers something like a 2-byte hash. This is the most understandable name that I picked up.
I will not consider the function itself, but I will write it on python right away. She does simple things, but her description with screenshots will take a lot of space.
The most important thing about it is to say: the starting address is supplied to the input, and the work is on 4 bytes from this address. That is, they fed the input of the first byte of the key, and the function will work with the 1,2,3,4th. The fifth filed, the function works from 5,6,7,8th. In other words, in this block calculations are performed over the first half of the key. The result is written to the register
So, the
Immediately write the function decoding hash:
I didn’t think up a better decoding function, and it’s not quite correct. Therefore, I will check it this way (not right now, but much later):
Check the work


The register
Check passed.
Next,

The receipt of such a hash
We can’t go further if we don’t know how the program works with the hash. Surely it moves from
Let me remind you that we are now at the last break
The script will stop at the instruction
Remember: the hash is stored at

Let's catch instructions that read from




How to choose the right / the right ones?
Back to the beginning:
This block determines whether the program will go to

We see that in the register
Where is put zero? Just scroll up:
If the
then we get zero in
If we put a break on instruction
If we enter different keys, mail, we will see that
We find out what blocks they write in
And we will find this

This block belongs to the
Through the call stack, we find out that the function

Remember we found 4 blocks earlier?
The fact that
What to look for:
What's going on here:
How many times is this cycle executed?
Let's figure it out. Run this script:

We deal with the sub_5EC function.
Significant piece of code:

where
This piece can be rewritten in pseudocode:
That is, 4 bytes from
How to rewrite
I like the second method more, but what if for different authorization data the values returned are different? Check it out.
The script will help in this:
I just compared the conclusions to the console with different keys, mails.
Running the script several times with different keys, we will see that the
So, the
At the queue
Significant piece of code:
We decipher:
The
Imagine the function
We have not yet seen the address

This block changes the contents at the address
Imagine a block like this:
This cycle counts the hash and here is its main feature:
Let's find out what is passed to it through the
We have already met with the construction
Decipher some code:
The essence comes down to a simple action: at each iteration, take
If so, what exactly does
Now we have everything to write a complete function to calculate the key hash.
The correct key is this key, whose final hash is
Now it's just to find out:
The output of the program says that there is one option: the first hash should be
What characters do we need for their first hash to be
Since
The algorithm is as follows:
A bunch of options, choose any.
The first half of the key is ready, what about the second?
This is the easiest part.
The responsible piece of code is located at
The

Let's make the code clearer:
In the register
The correctness criterion is obtained as follows:
We write the function of selecting the second half of the key:
Mail necessarily caps.

Thanks for attention! All code is available here .
My name is Marat Gayanov, I want to share with you my solution to the problem from the Best Reverser competition , to show how to make keygen for this case.
Description
In this competition, participants are provided with ROM games for the Sega Mega Drive ( best_reverser_phd9_rom_v4.bin ).
')
The task: to choose such a key, which together with the participant’s email address will be recognized as valid.
So the solution is ...
Instruments
- IDA Pro 6.8
- Plugin smd_ida_tools
Key length check
The program accepts not every key: you need to fill in the entire field, this is 16 characters. If the key is shorter, then you will see the message: “Wrong length! Try again ... ".
Let's try to find this line in the program, for which we use the binary search (Alt-B). What will we find?
Let's find not only this, but also a number of other service lines: “Wrong key! Try again ... ”and“ YOU ARE THE BEST REVERSER! ”.
The labels
WRONG_LENGTH_MSG , YOU_ARE_THE_BEST_MSG and WRONG_KEY_MSG I set to make it convenient.Put a break on reading the address
0x0000FDFA - find out who is working with the message “Wrong length! Try again ... ". And we will start the debugger (it will stop several times before the key can be entered, just press F9 at each stop). Enter your email, key ABCD .The debugger leads on
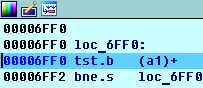
0x00006FF0 tst.b (a1)+ :There is nothing interesting in the block itself. It is much more interesting who transfers control here. Enjoying a call stack:
Click and get here - on instruction
0x00001D2A jsr (sub_6FC0).l :We see that all possible messages were found in one place. But let's find out where the control is transferred to the
WRONG_KEY_LEN_CASE_1D1C block. We will not put breaks, just hover the cursor on the arrow going to the block. The caller is located at the address 0x000017DE loc_17DE (which I will rename to CHECK_KEY_LEN ):Put a break to the address
0x000017EC cmpi.b 0x20 (a0, d0.l) (the instruction in this context looks to see if there is an empty character at the end of the key character array), restart, re-enter the mail and the ABCD key. The debugger stops and shows that at the address 0x00FF01C7 (which is currently stored in register a0 ) is the key entered:This is a good find, we will get everything out through it. But first, mark the key bytes for convenience:
Scroll up from this place, we see that the mail is stored next to the key:
We plunge deeper and deeper, and it's time to find the criterion for the correctness of the key. Rather, the first half of the key.
The criterion of the correctness of the first half of the key
Preliminary calculations
It is logical to assume that immediately after checking the length will follow other operations with the key. Consider the block immediately after the check:
This block is preliminary work. The function
get_hash_2b (in the original was sub_1526 ) is called twice. First, the address of the first byte of the key is transferred to it (register a0 contains the address KEY_BYTE_0 ), the second time - the fifth ( KEY_BYTE_4 ).I called the function like this because it considers something like a 2-byte hash. This is the most understandable name that I picked up.
I will not consider the function itself, but I will write it on python right away. She does simple things, but her description with screenshots will take a lot of space.
The most important thing about it is to say: the starting address is supplied to the input, and the work is on 4 bytes from this address. That is, they fed the input of the first byte of the key, and the function will work with the 1,2,3,4th. The fifth filed, the function works from 5,6,7,8th. In other words, in this block calculations are performed over the first half of the key. The result is written to the register
d0 .So, the
get_hash_2b function: # key_4s - def get_hash_2b(key_4s): # def transform(b): # numbers -. if b <= 0x39: r = b - 0x30 # Letter case and @ else: # @ABCDEF if b <= 0x46: r = b - 0x37 else: # WXYZ if b >= 0x57: r = b - 0x57 # GHIJKLMNOPQRSTUV else: r = 0xff - (0x57 - b) + 1 # a9+b return r # key_4b = bytearray(key_4s, encoding="ascii") # codes = [transform(b) for b in key_4b] # part0 = (codes[0] & 0xff) << 0xc part1 = (codes[1] << 0x8) & 0xf00 part2 = (codes[2] << 0x4) & 0xf0 hash_2b = (part0 | part1) & 0xffff hash_2b = (hash_2b | part2) & 0xffff hash_2b = (hash_2b | (codes[3] & 0xf)) return hash_2b Immediately write the function decoding hash:
# 4- def decode_hash_4s(hash_2b): # def transform(b): if b <= 0x9: return b + 0x30 if b <= 0xF: return b + 0x37 if b >= 0x0: return b + 0x57 return b - 0xa9 # b0 = transform(hash_2b >> 12) b1 = transform((hash_2b & 0xfff) >> 8) b2 = transform((hash_2b & 0xff) >> 4) b3 = transform(hash_2b & 0xf) # key_4s = [chr(b0), chr(b1), chr(b2), chr(b3)] key_4s = "".join(key_4s) return key_4s I didn’t think up a better decoding function, and it’s not quite correct. Therefore, I will check it this way (not right now, but much later):
key_4s == decode_hash_4s(get_hash_2b(key_4s)) Check the work
get_hash_2b . We are interested in the state of the d0 register after executing the function. We 0x000017FE breaks on 0x000017FE , 0x00001808 , key, enter ABCDEFGHIJKLMNOP .The register
d0 contains the values 0xABCD , 0xEF01 . And what will get_hash_2b give? >>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01 Check passed.
Next,
xor eor.w d0, d5 produced, the result is entered in d5 : >>> hex(0xabcd ^ 0xef01) 0x44cc The receipt of such a hash
0x44CC consists of preliminary calculations. Then everything just gets complicated.Where the hash goes
We can’t go further if we don’t know how the program works with the hash. Surely it moves from
d5 to memory, since the register is useful somewhere else. We can find such an event through tracing (watching d5 ), but not manual, but automatic. This script will help: #include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } } Let me remind you that we are now at the last break
0x00001808 eor.w d0, d5 . Insert the script ( Shift-F2 ), click RunThe script will stop at the instruction
0x00001C94 move.b (a0, a1.l), d5 , but by this time d5 has already been cleared. However, we see that the value from d5 moved by instruction 0x00001C56 move.w d5,a6 : it is written into memory at address 0x00FF0D46 (2 bytes).Remember: the hash is stored at
0x00FF0D46 .Let's catch instructions that read from
0x00FF0D46-0x00FF0D47 (set break for reading). Got 4 blocks:How to choose the right / the right ones?
Back to the beginning:
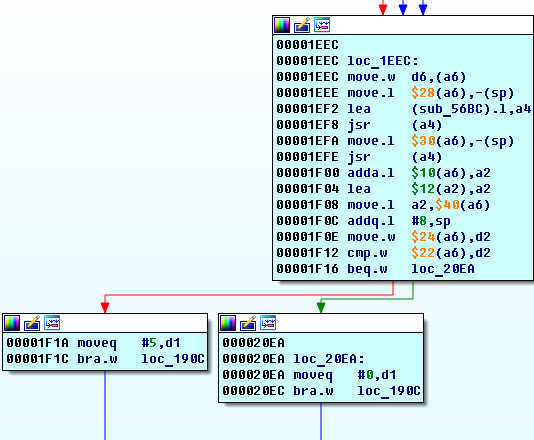
This block determines whether the program will go to
LOSER_CASE or WINNER_CASE :We see that in the register
d1 must be zero to win.Where is put zero? Just scroll up:
If the
loc_1EEC is met in the loc_1EEC block: *(a6 + 0x24) == *(a6 + 0x22) then we get zero in
d5 .If we put a break on instruction
0x00001F16 beq.w loc_20EA , then we see that a6 + 0x24 = 0x00FF0D6A and the value 0x4840 is stored there. And in a6 + 0x22 = 0x00FF0D68 is stored.If we enter different keys, mail, we will see that
0xCB4C - . The first half of the key will be accepted only if in 0x00FF0D6A will also be 0xCB4C . This is the criterion of the correctness of the first half of the key.We find out what blocks they write in
0x00FF0D6A - put a break on the record, enter the mail and the key again.And we will find this
loc_EAC block (in fact, there are 3 of them, but the first two simply zero out 0x00FF0D6A ):This block belongs to the
sub_E3E function.Through the call stack, we find out that the function
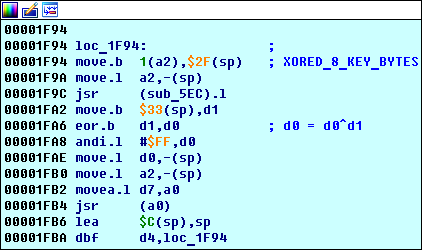
sub_E3E is called in blocks loc_1F94 , loc_203E :Remember we found 4 blocks earlier?
loc_1F94 we saw there - this is the beginning of the main key processing algorithm.The first important cycle loc_1F94
The fact that
loc_1F94 is a loop can be seen from the code: it is executed d4 times (see instruction 0x00001FBA d4,loc_1F94 ):What to look for:
- There is a
sub_5ECfunction. - The instruction 0x00001FB4 jsr (a0) calls the sub_E3E function (this can be seen by a simple trace).
What's going on here:
- The
sub_5ECfunction writes the result of its execution to thed0register (a separate section is devoted to this below). - The
d1register stores the byte atsp+0x33(0x00FFFF79, the debugger tells us), it is equal to the second byte from the key hash address (0x00FF0D47). This is easy to prove if you put a break on the record at0x00FFFF79: it will work on the instruction0x00001F94 move.b 1(a2), 0x2F(sp). Registera2at this moment stores the address0x00FF0D46- the hash address, that is,0x1(a2) = 0x00FF0D46 + 1- the address of the second byte of the hash. - Register
d0is writtend0^d1. - The resulting xor'a result is given to the
sub_E3Efunction, whose behavior depends on its previous calculations (shown below). - Repeat.
How many times is this cycle executed?
Let's figure it out. Run this script:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); } 0x00001F92 subq.l 0x1,d4 - here it is determined what will be in d4 immediately before the cycle:We deal with the sub_5EC function.
sub_5EC
Significant piece of code:
where
0x2c(a2) always 0x00FF1D74 .This piece can be rewritten in pseudocode:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF That is, 4 bytes from
0x00FF1D74 are the address, since they are treated like a pointer.How to rewrite
sub_5EC function on python?- Or make a memory dump and work with it.
- Or just write down all the output values.
I like the second method more, but what if for different authorization data the values returned are different? Check it out.
The script will help in this:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } } I just compared the conclusions to the console with different keys, mails.
Running the script several times with different keys, we will see that the
sub_5EC function always returns the next value from the array: def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1 So, the
sub_5EC function sub_5EC ready.At the queue
sub_E3E .sub_E3E
Significant piece of code:
We decipher:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2 The
sub_E3E function is reduced to such steps:- Save input argument to array.
- Calculate the offset.
- Pull out 2 bytes at
0x00011FC0 + offset(ROM). - Result =
( >> 8) ^ (2 0x00011FC0 + offset).
Imagine the function
sub_E3E in this form: def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some dump_00011FC0 is just a file where I saved 4096 bytes from [0x00011FC0:00011FC0+4096] .Activity about 1FC4
We have not yet seen the address
0x00001FC4 , but it is easy to find, because the block goes almost immediately after the first cycle.This block changes the contents at the address
0x00FF0D46 (register a2 ), and that is where the hash of the key is stored, so we are now studying this block. Let's see what happens here.- The condition that determines whether the left or right branch will be selected is:
( ) & 0b1 != 0. That is, the first bit of the hash is checked. - If you look at both branches, you will see:
- In both cases, there is a shift to the right by 1 bit.
- In the left branch above the hash operation
0x8000performed. - In both cases, the processed hash value is written to the address
0x00FF0D46, that is, the hash is replaced with the new value. - Further calculations are not critical, because, roughly speaking, there are no write operations in
(a2)(there is no instruction where the second operand would be(a2)).
Imagine a block like this:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new The second important cycle loc_203E
loc_203E - cycle, 0x0000206C bne.s loc_203E .This cycle counts the hash and here is its main feature:
jsr (a0) is a call to the sub_E3E function, which we have already considered - it relies on the previous result of its own work and on some input argument (above it was passed through the d2 register, and here through d0 ).Let's find out what is passed to it through the
d0 register.We have already met with the construction
0x34(a2) - there the function sub_E3E saves the passed argument. This means that previously passed arguments are used in this loop. But not all.Decipher some code:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0 The essence comes down to a simple action: at each iteration, take
d0 saved argument from the end of the array. That is, if 4 is stored in d0 , then we take the fourth element from the end.If so, what exactly does
d0 ? Here I did without scripts, but simply wrote them out, putting a break at the beginning of this block. Here they are: 0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .Now we have everything to write a complete function to calculate the key hash.
Full function hash calculation
def finish_hash(hash_2b): # def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new main_cycle_counter = [17, 2, 2, 3, 4, 38, 10, 30, 4] second_cycle_counter = [2, 2, 2, 2, 2, 4, 2, 4, 28] counters = list(zip(main_cycle_counter, second_cycle_counter)) d2_storage = [] storage_offsets = [0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02] prev_sub_E3E_result = 0x0000 sub_5EC = sub_5EC_gen() for i in range(9): c = counters[i] for _ in range(c[0]): d0 = next(sub_5EC) d1 = hash_2b & 0xff d2 = d0 ^ d1 curr_sub_E3E_result = sub_E3E(prev_sub_E3E_result, d2, d2_storage) prev_sub_E3E_result = curr_sub_E3E_result storage_offset = storage_offsets.pop(0) for _ in range(c[1]): d2 = d2_storage[-storage_offset] curr_sub_E3E_result = sub_E3E(prev_sub_E3E_result, d2, d2_storage) prev_sub_E3E_result = curr_sub_E3E_result hash_2b = transform(hash_2b) return curr_sub_E3E_result Health check
- In the debugger, we set a break to the address
0x0000180A move.l 0x1000,(sp)(immediately after calculating the hash). - Break to the address
0x00001F16 beq.w loc_20EA(comparison of the final hash with the constant0xCB4C). - In the program, enter the key
ABCDEFGHIJKLMNOP, pressEnter. - The debugger stops at
0x0000180A, and we see that the value of0xFFFF44CCis0x44CCd5register,0x44CCis the first hash. - Run the debugger on.
- We stop at
0x00001F16and see that at the address0x00FF0D6Ais0x4840- the final hash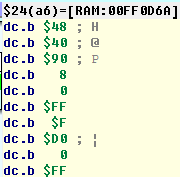
- Now we’ll check our finish_hash (hash_2b) function:
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Looking for the right key 1
The correct key is this key, whose final hash is
0xCB4C (figured out above). Hence the question: what should be the first hash for the final to become 0xCB4C ?Now it's just to find out:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r) The output of the program says that there is one option: the first hash should be
0xFEDC .What characters do we need for their first hash to be
0xFEDC ?Since
0xFEDC = __4_ ^ __4_ , then you only need to find __4_ because the __4_ = __4_ ^ 0xFEDC . And then decode both hashes.The algorithm is as follows:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1 A bunch of options, choose any.
We are looking for the right key 2
The first half of the key is ready, what about the second?
This is the easiest part.
The responsible piece of code is located at
0x00FF2012 , I got to it by manual tracing, starting at 0x00001F16 beg.w loc_20EA (validation of the first half of the key). In the register a0 is the address of the mail, loc_FF2012 is a cycle, because bne.s loc_FF2012 . It is executed as long as there is *(a0+d0) (the next byte of the mail).The
jsr (a3) instruction calls the familiar function get_hash_2b , which now works with the second half of the key.Let's make the code clearer:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch In the register
d2 - ( -1) << 8 . In d3 , the sum of the bytes of the characters in the mail.The correctness criterion is obtained as follows:
__ ^ d2 == ___2 ^ d3 .We write the function of selecting the second half of the key:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1 Keygen
Mail necessarily caps.
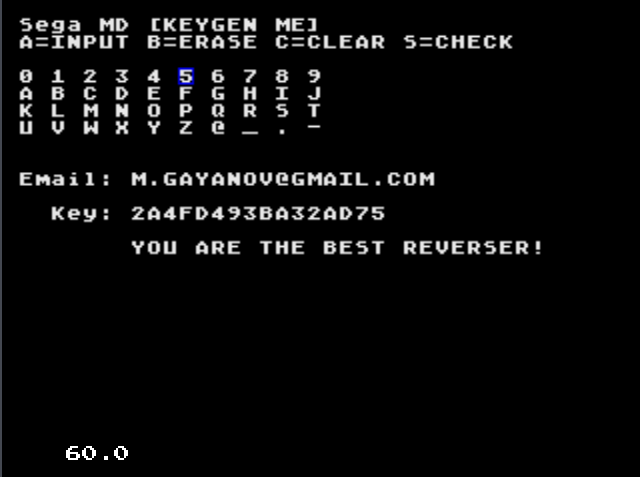
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75 Thanks for attention! All code is available here .
Source: https://habr.com/ru/post/453194/
All Articles