How to explain to non-IT managers how to build a resilient IT infrastructure
About a year ago, I was faced with a rather serious task: to put a story about Agile and DevOps into a 2-hour lecture for managers.
So began my return from the soft-plane training to Agile in the direction of IT. And according to the organizers, over 1,000 product managers passed through this lecture, of which about 48/50 people heard the word “balancer” (Load Balancer) for the first time in my class.
I even had a comic deity "a great balancer, a master of updates without downtime, cheap to implement A / B tests without programming, and generally a quiet sleep of a manager at night."
Of course, IT colleagues can laugh at this simplification, and even resent the fact that the world has not converged on the word "balancer" and how much attention can be paid to it.
')
But when in my room 48 people out of 50 did not hear about the phenomenon of load balancing, it is a little sad. And the developers of the backends of some mobile applications, even large banks can sin the lack of such schemes.
My favorite yellow bank, for example, updates the backend server of a mobile application at 5 am Moscow time about 2 times a week. Why do I know this? Because in Novosibirsk, where I returned for a year to live in 2016, at that time it was already 9 am, and error 000 popped out to me. It is terrible to imagine that this is already dinner for the Far East.
Perhaps we have a chance to make this world a little better, if managers think about the resiliency at the time of budgeting server capacity, and there will not be 1 server for everything, but a configuration that is truly commensurate with the degree of risk and load on the system.
The very first question that arises in the formulation of any task, of course: why?
There is such a framework:
Why do we need it? | Why is it them?
If we imagine that “we” are a lot of people from IT, not only developers and related specialists, but also technology consultants, HR and Agile-coaches, who are in daily contact with managers who do not have an IT background.
For myself, the first question I answered is quite simple: increasing the technical literacy of managers greatly reduces the likelihood of inadequate tasks and increases the happiness of developers.
Why knowledge of this for managers who are really far from IT?
We are all people, and we all want to sleep well. Managers often take responsibility for things that they cannot really influence. The level of stress in this case is comparable with the passengers of the aircraft, who have aerophobia.
And this is probably the only argument that will not be like a snobbery “well, how can you not know such obvious things” or “every person should blindfold at times simplify an indefinite integral”. In my experience, if a person is “elbows in the console”, then even unconsciously, but he can often operate with such stamps.
The illustrations below do not claim to be absolute truth and have no independent value; all the more, these simplifications should not be used as a guide to action when building fault-tolerant architectures, since I intend not to draw various subtle points there, such as caching. This is just a simplified model.
In adult education, and learning new information is part of training, it is important to understand that any information must be repeated at least three times in order to increase the likelihood that it will actually be learned.
For example, such a scheme is likely to be associated with a meme “do not try to leave Omsk” and only approve a person in the thought that “everything is difficult, and they also want a lot of servers”.
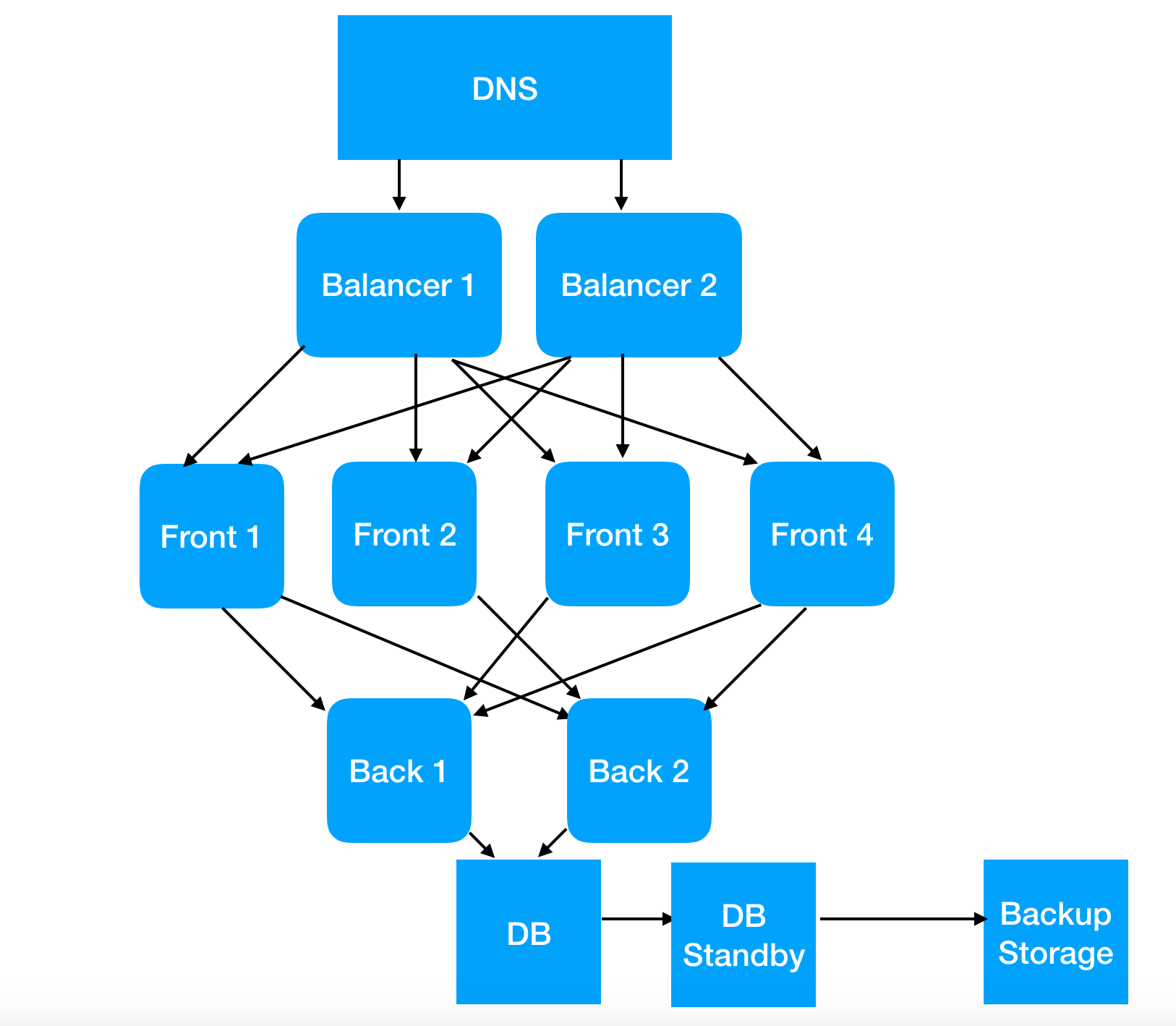
But this scheme, shown first, can create an association of the word “balancer” in a person with the phenomenon of server load balancing. Without any guarantees of the correctness of the understanding of this process, but with the confident knowledge that it exists and why it is needed.
Let's parse a little Agile-manifest points in this place and say “that is, without diminishing the value of what is on the right, we more appreciate what is on the left”.
For example, because this scheme allows us to understand how to set up an A / B testing system without writing tons of source code, and how to update the server without drinking for courage (to the manager, not to the admin) before that.
And this very understanding opens the way for the manager to the wonderful world of CI / CD, because if we already know the minimum labor costs in order to make the infrastructure partially fault tolerant, we are less afraid of frequent releases. And this radically changes the approach to update policies in general.
Well, it’s not for me to tell you that smaller edits laid out at 1/10 of the capacity (even if it is 1 server out of 3, but only 10% of traffic is given to it), this is a strong decrease in the passions during the update. Even if the servers completely stop processing every 10th request.
We once had a 20% drop with RPS 600, and it was quickly eliminated, it seems even without the participation of people. It was then that I, as a technical PM, who was responsible for all the backends of the direction, practically began to breathe the word “balancer” to other managers.
As my experience shows, this knowledge is extremely useful precisely so that managers can understand how to make the risks from the release minimal and become interested in CI / CD and various technological experiments.
Sometime about 4 years ago, about the same story in my practice was to tell developers about GitFlow-like “branching” systems for stabilizing releases and a moratorium on commits to a release branch that are supported at hook level, but lately it has become less and less and less required.
In my opinion, now it is really important to improve the technical literacy of non-technical managers. Not necessarily at all in this way, of course.
So began my return from the soft-plane training to Agile in the direction of IT. And according to the organizers, over 1,000 product managers passed through this lecture, of which about 48/50 people heard the word “balancer” (Load Balancer) for the first time in my class.
I even had a comic deity "a great balancer, a master of updates without downtime, cheap to implement A / B tests without programming, and generally a quiet sleep of a manager at night."
Of course, IT colleagues can laugh at this simplification, and even resent the fact that the world has not converged on the word "balancer" and how much attention can be paid to it.
')
But when in my room 48 people out of 50 did not hear about the phenomenon of load balancing, it is a little sad. And the developers of the backends of some mobile applications, even large banks can sin the lack of such schemes.
My favorite yellow bank, for example, updates the backend server of a mobile application at 5 am Moscow time about 2 times a week. Why do I know this? Because in Novosibirsk, where I returned for a year to live in 2016, at that time it was already 9 am, and error 000 popped out to me. It is terrible to imagine that this is already dinner for the Far East.
Perhaps we have a chance to make this world a little better, if managers think about the resiliency at the time of budgeting server capacity, and there will not be 1 server for everything, but a configuration that is truly commensurate with the degree of risk and load on the system.
What for?
The very first question that arises in the formulation of any task, of course: why?
There is such a framework:
Why do we need it? | Why is it them?
Why do we need it?
If we imagine that “we” are a lot of people from IT, not only developers and related specialists, but also technology consultants, HR and Agile-coaches, who are in daily contact with managers who do not have an IT background.
For myself, the first question I answered is quite simple: increasing the technical literacy of managers greatly reduces the likelihood of inadequate tasks and increases the happiness of developers.
Why is it them?
Why knowledge of this for managers who are really far from IT?
We are all people, and we all want to sleep well. Managers often take responsibility for things that they cannot really influence. The level of stress in this case is comparable with the passengers of the aircraft, who have aerophobia.
And this is probably the only argument that will not be like a snobbery “well, how can you not know such obvious things” or “every person should blindfold at times simplify an indefinite integral”. In my experience, if a person is “elbows in the console”, then even unconsciously, but he can often operate with such stamps.
How can you explain the complex simple pictures
The illustrations below do not claim to be absolute truth and have no independent value; all the more, these simplifications should not be used as a guide to action when building fault-tolerant architectures, since I intend not to draw various subtle points there, such as caching. This is just a simplified model.
In adult education, and learning new information is part of training, it is important to understand that any information must be repeated at least three times in order to increase the likelihood that it will actually be learned.
For example, such a scheme is likely to be associated with a meme “do not try to leave Omsk” and only approve a person in the thought that “everything is difficult, and they also want a lot of servers”.
But this scheme, shown first, can create an association of the word “balancer” in a person with the phenomenon of server load balancing. Without any guarantees of the correctness of the understanding of this process, but with the confident knowledge that it exists and why it is needed.
Let's parse a little Agile-manifest points in this place and say “that is, without diminishing the value of what is on the right, we more appreciate what is on the left”.
For example, because this scheme allows us to understand how to set up an A / B testing system without writing tons of source code, and how to update the server without drinking for courage (to the manager, not to the admin) before that.
What's next?
And this very understanding opens the way for the manager to the wonderful world of CI / CD, because if we already know the minimum labor costs in order to make the infrastructure partially fault tolerant, we are less afraid of frequent releases. And this radically changes the approach to update policies in general.
Well, it’s not for me to tell you that smaller edits laid out at 1/10 of the capacity (even if it is 1 server out of 3, but only 10% of traffic is given to it), this is a strong decrease in the passions during the update. Even if the servers completely stop processing every 10th request.
We once had a 20% drop with RPS 600, and it was quickly eliminated, it seems even without the participation of people. It was then that I, as a technical PM, who was responsible for all the backends of the direction, practically began to breathe the word “balancer” to other managers.
As my experience shows, this knowledge is extremely useful precisely so that managers can understand how to make the risks from the release minimal and become interested in CI / CD and various technological experiments.
Sometime about 4 years ago, about the same story in my practice was to tell developers about GitFlow-like “branching” systems for stabilizing releases and a moratorium on commits to a release branch that are supported at hook level, but lately it has become less and less and less required.
In my opinion, now it is really important to improve the technical literacy of non-technical managers. Not necessarily at all in this way, of course.
Source: https://habr.com/ru/post/453188/
All Articles