How to connect the script to a third-party site
Hi Habr! This is the first post on our blog. Many people know us as a chat for the site, we started with it, and now we occupy a leading position in the field of business messengers. We gradually evolved into a comprehensive business solution that provides many opportunities for clients: callback, communication with clients via instant messengers, social networks, mobile applications, virtual PBX, CRM functions and much more.
For several years we have successfully solved a lot of technical problems, accumulated a lot of interesting things, and in some unique experience, of course, wrote our crutches and bicycles. With this post we begin a series of articles in which we will share our development experience, building processes in a completely remote team, tell you about our architecture, technical solutions that allow us to efficiently serve hundreds of thousands of customers around the world.

')
Jivosite today is:
Since most people know us as a chat for the site, perhaps we will begin with it. In this article, using the example of our many years of experience in chat, we will tell you how best to connect your code to a third-party site and what you should pay attention to. This article will be useful to those who plan or are already developing a plug-in service, and just to everyone who is interested in this topic.
The theater begins with a hanger, and the plug-in service with an insert code. It is the entry point for any service or module to the site. As a rule, it can be found in the installation instructions, after which you need to add it to the HTML code of the site, and then “magic” happens, which in a certain way loads and initializes the script.
It would seem that it could be easier to connect the script to the site? By standard, you just need to add the script tag to the page's HTML code. But in fact this is an important stage, hiding a lot of pitfalls. For example, user identification, implementation of a backup script loading channel, customization of appearance or logic, page loading speed, and so on. But let's get everything in order.
It’s just so interesting to connect the script to very few people, for sure the script executes some logic, and this logic is tied to the user. For example, the ID of the counter, APP_ID from the social network, in our case it is the ID of the created communication channel. That is, the script must identify the user in requests to the server. For identification of the client through the insert code there are three options for implementation.
Option 1
To transfer the ID directly in the link to the file and on the server side in some way to throw it into the script. In this case, the server will have to enter the ID into a file on the fly or form a JS string with the ID that will load file.js. This logic is similar to the implementation of JSONP requests.

For a long time, we worked on this principle, but the disadvantages of this approach are that the “idle” load on the server is added and the need to implement server caching.
Option # 2
Async attribute - tells the browser that you do not need to wait for the script to load to build the DOM, the script must be executed immediately after the download. This reduces the page load time, but there is a downside: the script can be executed before the DOM is ready to go.
One of the most popular implementations, so do major services, only syntax is different, but the essence is the same.

This approach has two main drawbacks, the first - the code-inserts are complicated, and the second - the order of execution of this code is very important, otherwise nothing will work. In addition, it is necessary to make a choice between speed (async) and stability (without async), most choose the 2nd option.
Option # 3
Similar to the first option, transfer the ID in the link to the file, but retrieve it in the browser, not on the server. This is not as simple as it seems, but possible. The browser API has the document.currentScript property; it returns a link to the script that is loaded and is currently running in the browser. Knowing this, you can calculate the ID, for this you need to get the document.currentScript.src property and regularly pull out the ID from it.
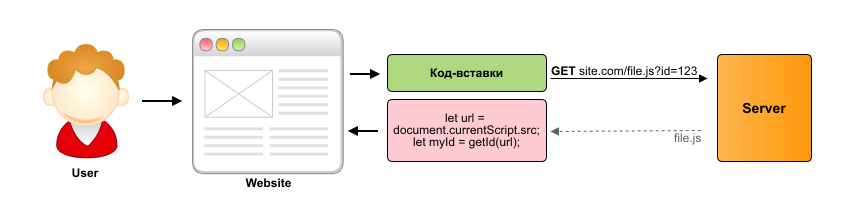
There is one thing: document.currentScript is not supported by all browsers. For browsers that do not support this property, we have come up with an interesting hack. In the file.js code, you can throw a special “fake” exception wrapped in try / catch, after which the error stack will contain the URL of the script in which the error occurred. The URL will contain the ID, which we get the same regularity.
That kind of magic happens, but it works. There are no problems with the order of execution, the insert code looks simple and there is no overhead projector on the server. For the last two years we have been using this approach, although the code-insert itself is different, but the principle is the same.
In most cases, the connected scripts have any settings that are responsible for the appearance or logic of the work. These settings need to be "prokidyvat" in the plugin script, for this there are two fundamentally different approaches.
Approach # 1
This approach also includes the transfer of settings in the GET parameters of the url script, similar to option # 1 from the “Identification” section. The approach is that if the client wants to change the settings, then he needs to edit the insert code and update it on the site.
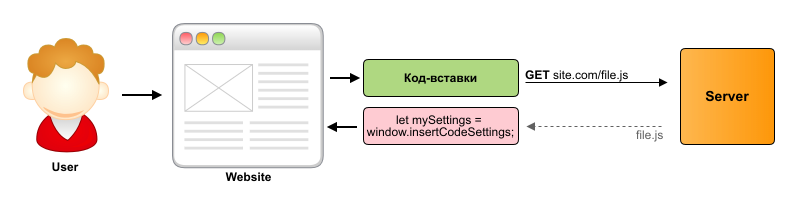
This is good because all the settings are stored on the client and they do not need to be stored on the server, develop and maintain all the related business logic. The main disadvantage of this approach is the inconvenience for the client, he has to do everything manually, and if there are a lot of settings, the insert code turns into a hard-to-keep sheet, in which it is easy to make a mistake. And in order for the updates to take effect, you need to update the site, these are extra gestures of developers and admins.
Approach # 2
The second approach is that in case of need to change the settings, the client does not need to modify the code-inset, all settings are stored on the server. In order to change the settings, you need to go to the graphic panel, change the necessary parameters and click the "Save" button. After this, the settings are automatically applied to his site!

No need to understand the code and do it for the sake of this deployment, this can be done by a person who is far from JavaScript, such as a manager. Of course, this option is much more convenient and simpler for users, which is why we use it. But you have to pay for convenience, this approach requires the development and maintenance of logic on the server and implies an additional load on it. In the following articles we will definitely describe how we process 150M of such requests daily.
It is very important to quickly come to a mature version of the code insert. Because it will be extremely difficult to update the already installed insertion codes. An example from our practice: in the first versions, we used numeric IDs, but for security reasons, we replaced them with alphanumeric ones. It turned out that it is very difficult to achieve a change in the already installed insert code. Many do not even know what HTML is and how sites are arranged. For example, the site was made by freelancers, a studio or website was created through a CMS / designer, etc. In most cases, our clients work only with the widget settings panel. Since those times, we still have a revait's old ID with new ones in nginx, in which there are about 40K entries.
Because of this feature, we are forced to maintain the backward compatibility of the insert code for all refactorings, which in our memory was about 5.
Since the script connects to a third-party site that already has JavaScript and CSS code for the site and other services, the primary goal is not to harm the site so that our code does not change the logic, much less break it. This could be a javascript error that stops the flow of execution, or styles that override site styles. But the site code may also affect the plug-in script, for example, a library is used which modifies the browser API, after which the code stops working or does not work the way we expect.
There are different options for code isolation. For example, you can use prefixes in JS variables, closures, in order not to clutter the global context, use something like BEM for styles. But the easiest way is to run the code in the iframe, it solves most of the isolation problems, but imposes certain restrictions. We use a hybrid version, about code isolation we will tell more in the next articles.
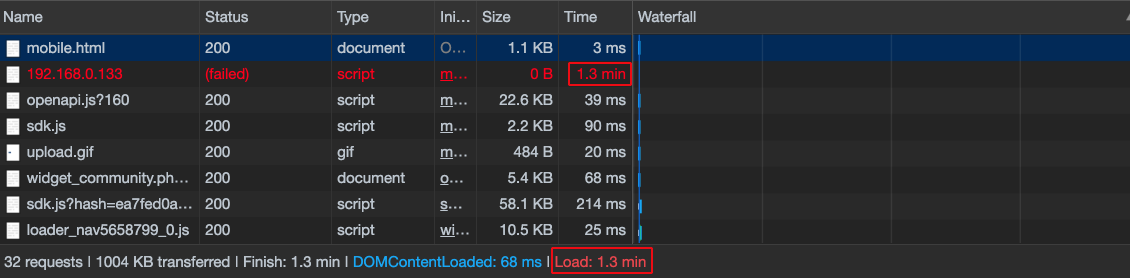
The onload event occurs after the web page is fully loaded, including images, styles, and external scripts. An important feature is that on most sites JS-logic, third-party scripts and ads start to work when this event occurs. A very important point for all connected scripts is to prevent a negative impact on this event.
This happens when the server from which the script is loaded responds for a long time or does not respond at all: then the onload event is postponed and further loading of the page is in fact blocked. In the case when the server is unavailable, the onload event will occur only after a request timeout of more than 60 s. Thus, problems on the script's return server essentially “break” websites, which is unacceptable.
Personal experience
In the past I worked at a company that had a site with simultaneous online 100K, online dating. In those days, the “Share on social networks” buttons were popular. In order for them to appear on the site, it was necessary to connect a script (sdk) from the required social networks. One day, colleagues came running to us and said that our site is not working! We looked at the monitoring, in which everything was fine, and at first did not understand what the problem was. When we started to understand more deeply, we realized that the Twitter cdn servers had fallen down, and their SDK could not load, it blocked us from loading the site for ~ 1.5 minutes. That is, after opening the site, a small HTML was loaded (the rest of the SPA) and only after 1.5 minutes everything was loaded, the same request timeout worked. We had to urgently organize hotfix and remove their script from the site. After repeating this situation, we decided to remove the “Share” block altogether.
In the first versions of the code-inset, we did not take this into account, and in the case of technical problems on our side, we put it mildly, inconvenience to our customers, but over time we fixed it.
Decision
The solution is simple, you have to subscribe to the event of a full site load and only then load the script, for this you need to use the insert code, and not the script tag.

The results of the analysis of the mobile version of habr.com
Most pay attention to the speed of loading the site, according to many studies, this directly affects the profits, besides search algorithms when ranking began to take into account the page load time. In this regard, site owners often use these tools to assess the performance of the site. Therefore, it is very important to optimally connect the code to the site, so it directly affects its load time.
This means that you need to use modern page load optimization techniques. For example, use Gzip, cache static files and requests, use asynchronous script downloads, statics compression with modern algorithms such as WebP / Brotli / etc, and use other optimizations. We regularly conduct audits and respond to warnings and recommendations to meet current requirements.
In the first versions we downloaded statics from the application servers. But this approach has disadvantages: expensive traffic, remoteness from site visitors and excessive load on the channel of servers. You can easily clog the channel of the application servers with the habr effect of the sites, since the static traffic is very “heavy”.
In order to save budget, stability and reduce network latency, it is optimal to load statics from servers specifically designed for this. You can use ready-made CDN-providers, but on a large scale it is expensive and you have to limit yourself to the opportunities offered by one or another provider.
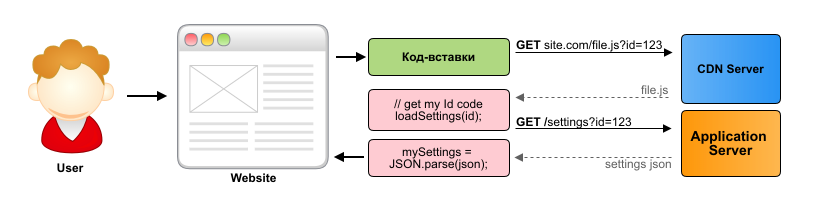
We implemented it simply, ordered low-cost servers in Russia, Europe and America with unlimited traffic and a wide channel. This is cheap, does not impose any restrictions on us, we can customize everything for ourselves, and fault tolerance is provided by the mechanism working in the browser. At the moment, 1TB of statics is downloaded daily from our CDN servers.
Unfortunately, the world is not perfect, fires occur, uplinks fall, DCs completely go under water, the RKN blocks subnets, and people make mistakes. However, it is necessary to be able to handle such situations and continue working.
Monitoring
First you need to understand that something went wrong. You can, of course, wait until users come and complain, but it is better to set up monitoring and alerts, and after releases, check if everything is in order. We monitor many different parameters, both server and client, and if something went wrong, we immediately see it. For example, the number of widget downloads or the anomalous surge in traffic on CDN servers has decreased.
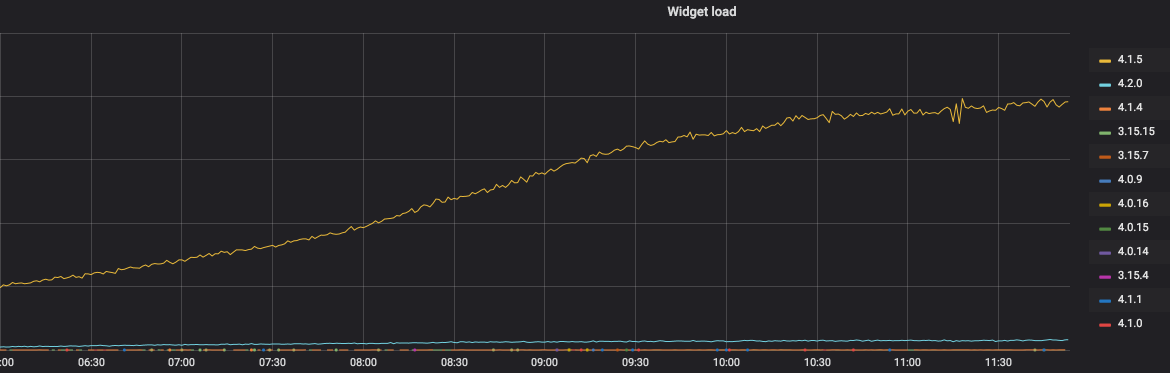
The total number of widget downloads for each version
Error collection
JavaScript is a very specific language, and it’s easy to make a mistake. In addition, the zoo of browsers in the modern web is very large; what works in the latest Chrome is not a fact that will work in Safari or Firefox. Therefore, it is very important to set up a collection of errors from the browser and respond in time to surges. If your code works in an iframe, you can do this by tracking the global window.onerror handler and in case of an error send data to the server. If the code works outside the iframe, then it is very difficult to implement error collection.
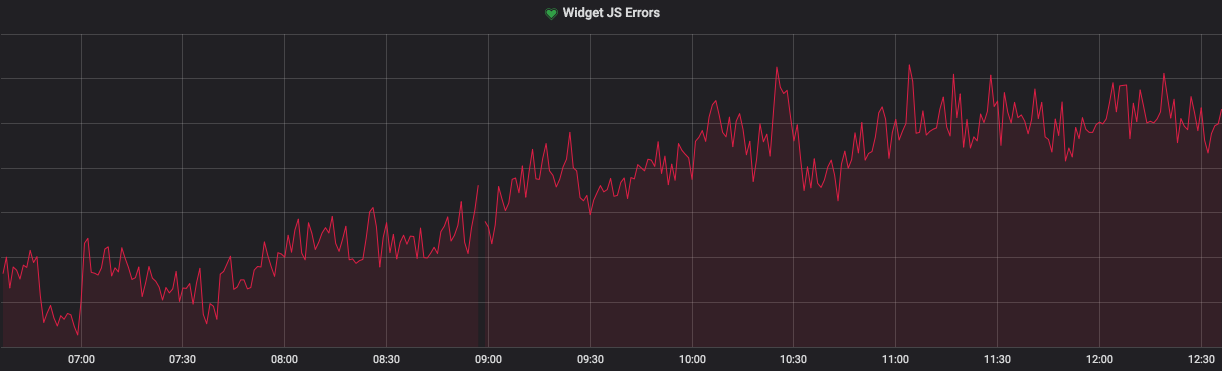
The total number of errors from all sites and browsers
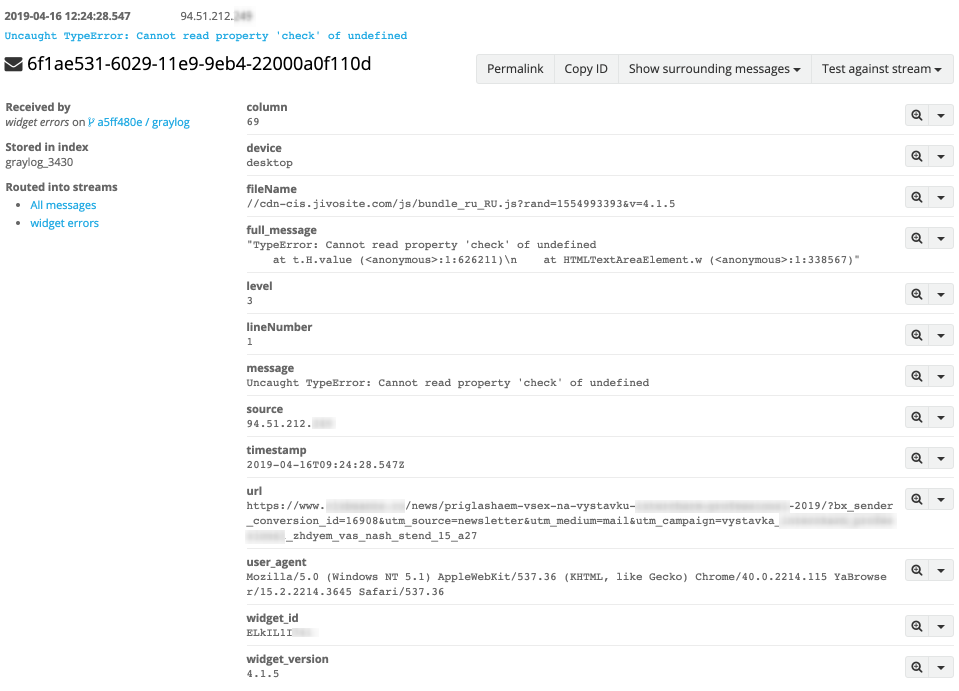
Information on a specific error
CDN Failover
I already wrote above that everything has a tendency to fall, so it is important to handle these situations and better - automatically. We went through several stages of the fullback CDN-servers, started with manual, and eventually found a way to do it automatically and optimally for the browser.
In manual mode, it worked simply: the administrators received an SMS stating that the CDN was down, they performed certain manipulations, after which the widget began to load from the application servers. This could take from 5 minutes to 2 hours.
To implement an automatic fallback, you need to somehow detect that the script has started downloading, but this is not as easy as it seems. The browser does not allow to monitor the intermediate status of loading the script tag, such as the onprogress event in XMLHttpRequest, and reports only the event at the end of the download and execution of the script. It is also impossible to find out in a reasonable time that the server is currently unavailable, the only onerror event is triggered when the request times out, more than 1 minute. Within a minute, a visitor can already leave the page, and the script will not load.
We tried different options, simple and complex, but eventually came to a solution with a ping request from a CDN server. It works this way: we first ping the CDN server, if answered, then we load the widget from it. To implement this scheme optimally for the browser and our servers, we use a light HEAD request (without a body), and we do not do it on subsequent downloads until the widget version is updated, since the widget is already in the browser cache.
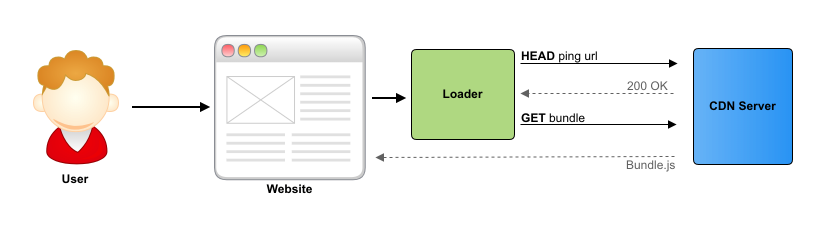
Thus, we received a very fast and automatically detecting the availability of a statics server and in the case of a drop, we switch to a backup server with almost no delays.
To upload your script to a third-party site, you need to take into account many points, but it’s difficult to implement this logic in the insert code, since it will simply turn into “meat”. But we still need to do this, for this we have created a small module that controls all this logic “under the hood” and loads the main code of the widget. It is loaded first and implements CDN Failover, caching, backward compatibility with old insert codes, A / B testing, gradual display of the new version of the widget, and many other functions.
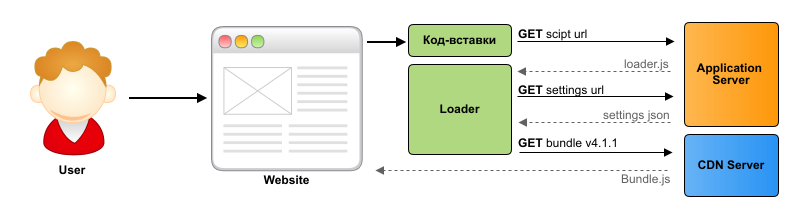
Thus, in stages, we arrived at a scheme that covers the main cases of loading and initializing the widget. It has proven its effectiveness over the years of use on a large number of different sites. At the same time, the insert code remains simple and universal, since there is no logic in it and we can change it at any time, without forcing users to change the insert code.
And finally, it is worth mentioning about third-party services that connect to the site or in some way interact with the sites: search bots, analytics, various parsers and so on. These services leave an imprint at work, about this, too, should not be forgotten. I'll tell you a few cases from our practice.
Googlebot
In our operator’s application, there is a “Visitors” function in which you can view visitors currently browsing the site and various information on them: time on the site, page, number of pages viewed, and so on. At a certain point, customers began to complain that visitors from other sites, that is, on a website for the sale of iPhones, a customer who allegedly had a “Buy face cream” page, “hang out” at them. When they started to figure it out, they found out that it was GoogleBot, which, when going from site to site, cached LocalStorage first and subsequently transferred incorrect data to the server.
The solution is simple, the server started to ignore data from GoogleBot.
Yandex.Metrica
There is a great feature in the metric - the web viewer, which allows you to see what the user has seen and done, in the form of a screencast. To do this, the metric records all user actions, and after the special metric bot walks through the sites, performs the same actions and records it. The problem was that, according to our data, Firefox was turned on in mobile emulation mode to emulate the mobile browser of the user, but the bot had a userAgent desktop.
This led to the fact that when viewing mobile user sessions in the web browser, the desktop version of the widget was opened on the record, although in reality the users had a mobile one. Our clients thought that this is the case, and filled us with complaints. , , , , .
, , , .
, . . , , NodeJS , 250 - , .
, !
For several years we have successfully solved a lot of technical problems, accumulated a lot of interesting things, and in some unique experience, of course, wrote our crutches and bicycles. With this post we begin a series of articles in which we will share our development experience, building processes in a completely remote team, tell you about our architecture, technical solutions that allow us to efficiently serve hundreds of thousands of customers around the world.
')
Jivosite today is:
- 250K customers worldwide;
- 150M widget hits per day;
- 3.5M messages per day;
- 10M chats per month;
- 1M simultaneous connections;
- 250+ servers in production.
Since most people know us as a chat for the site, perhaps we will begin with it. In this article, using the example of our many years of experience in chat, we will tell you how best to connect your code to a third-party site and what you should pay attention to. This article will be useful to those who plan or are already developing a plug-in service, and just to everyone who is interested in this topic.
Entry point
The theater begins with a hanger, and the plug-in service with an insert code. It is the entry point for any service or module to the site. As a rule, it can be found in the installation instructions, after which you need to add it to the HTML code of the site, and then “magic” happens, which in a certain way loads and initializes the script.
<script src="https://site.com/file.js"></script> It would seem that it could be easier to connect the script to the site? By standard, you just need to add the script tag to the page's HTML code. But in fact this is an important stage, hiding a lot of pitfalls. For example, user identification, implementation of a backup script loading channel, customization of appearance or logic, page loading speed, and so on. But let's get everything in order.
Identification
It’s just so interesting to connect the script to very few people, for sure the script executes some logic, and this logic is tied to the user. For example, the ID of the counter, APP_ID from the social network, in our case it is the ID of the created communication channel. That is, the script must identify the user in requests to the server. For identification of the client through the insert code there are three options for implementation.
Option 1
<script async src="https://site.com/file.js?id=123"></script> To transfer the ID directly in the link to the file and on the server side in some way to throw it into the script. In this case, the server will have to enter the ID into a file on the fly or form a JS string with the ID that will load file.js. This logic is similar to the implementation of JSONP requests.
For a long time, we worked on this principle, but the disadvantages of this approach are that the “idle” load on the server is added and the need to implement server caching.
Option # 2
<script src="https://site.com/file.js" [async]></script> <script type=”text/javascript”> window.serviceNameId = “123”; // ServiceNameModule.init({id: “123”}); </script> Async attribute - tells the browser that you do not need to wait for the script to load to build the DOM, the script must be executed immediately after the download. This reduces the page load time, but there is a downside: the script can be executed before the DOM is ready to go.
One of the most popular implementations, so do major services, only syntax is different, but the essence is the same.
This approach has two main drawbacks, the first - the code-inserts are complicated, and the second - the order of execution of this code is very important, otherwise nothing will work. In addition, it is necessary to make a choice between speed (async) and stability (without async), most choose the 2nd option.
Option # 3
<script async src="https://site.com/file.js?id=123"></script> Similar to the first option, transfer the ID in the link to the file, but retrieve it in the browser, not on the server. This is not as simple as it seems, but possible. The browser API has the document.currentScript property; it returns a link to the script that is loaded and is currently running in the browser. Knowing this, you can calculate the ID, for this you need to get the document.currentScript.src property and regularly pull out the ID from it.
There is one thing: document.currentScript is not supported by all browsers. For browsers that do not support this property, we have come up with an interesting hack. In the file.js code, you can throw a special “fake” exception wrapped in try / catch, after which the error stack will contain the URL of the script in which the error occurred. The URL will contain the ID, which we get the same regularity.
That kind of magic happens, but it works. There are no problems with the order of execution, the insert code looks simple and there is no overhead projector on the server. For the last two years we have been using this approach, although the code-insert itself is different, but the principle is the same.
Settings
In most cases, the connected scripts have any settings that are responsible for the appearance or logic of the work. These settings need to be "prokidyvat" in the plugin script, for this there are two fundamentally different approaches.
Approach # 1
<script async src="https://site.com/file.js"></script> <script type=”text/javascript”> window.serviceName = {color: “red”, title: “”, ...}; // ServiceNameModule.init({color: “red”, title: “”, ...}); </script> This approach also includes the transfer of settings in the GET parameters of the url script, similar to option # 1 from the “Identification” section. The approach is that if the client wants to change the settings, then he needs to edit the insert code and update it on the site.
This is good because all the settings are stored on the client and they do not need to be stored on the server, develop and maintain all the related business logic. The main disadvantage of this approach is the inconvenience for the client, he has to do everything manually, and if there are a lot of settings, the insert code turns into a hard-to-keep sheet, in which it is easy to make a mistake. And in order for the updates to take effect, you need to update the site, these are extra gestures of developers and admins.
Approach # 2
<script async src="https://site.com/file.js?id=123"></script> The second approach is that in case of need to change the settings, the client does not need to modify the code-inset, all settings are stored on the server. In order to change the settings, you need to go to the graphic panel, change the necessary parameters and click the "Save" button. After this, the settings are automatically applied to his site!
No need to understand the code and do it for the sake of this deployment, this can be done by a person who is far from JavaScript, such as a manager. Of course, this option is much more convenient and simpler for users, which is why we use it. But you have to pay for convenience, this approach requires the development and maintenance of logic on the server and implies an additional load on it. In the following articles we will definitely describe how we process 150M of such requests daily.
backward compatibility
It is very important to quickly come to a mature version of the code insert. Because it will be extremely difficult to update the already installed insertion codes. An example from our practice: in the first versions, we used numeric IDs, but for security reasons, we replaced them with alphanumeric ones. It turned out that it is very difficult to achieve a change in the already installed insert code. Many do not even know what HTML is and how sites are arranged. For example, the site was made by freelancers, a studio or website was created through a CMS / designer, etc. In most cases, our clients work only with the widget settings panel. Since those times, we still have a revait's old ID with new ones in nginx, in which there are about 40K entries.
.... /script/widget/config/15**90 /script/widget/config/bqZB**rjW5; /script/widget/config/15**94 /script/widget/config/qtfx**xnTi; /script/widget/config/15**95 /script/widget/config/fqmpa**4YX; /script/widget/config/15**97 /script/widget/config/Vr21g**nuT; /script/widget/config/15**98 /script/widget/config/8NXL5**F8E; /script/widget/config/15**00 /script/widget/config/Th2HN**6RJ; .... Because of this feature, we are forced to maintain the backward compatibility of the insert code for all refactorings, which in our memory was about 5.
Code isolation
Since the script connects to a third-party site that already has JavaScript and CSS code for the site and other services, the primary goal is not to harm the site so that our code does not change the logic, much less break it. This could be a javascript error that stops the flow of execution, or styles that override site styles. But the site code may also affect the plug-in script, for example, a library is used which modifies the browser API, after which the code stops working or does not work the way we expect.
<script type="text/javascript"> // mootools.js var JSON = new Hash({ encode: function () {}, decode: function () {} // ... }); // JSON.parse(json); // Uncaught TypeError: JSON.parse is not a function </script> <style type="text/css"> // body * { padding: 20px; } form input { display: block; border: 2px solid red; } </style> There are different options for code isolation. For example, you can use prefixes in JS variables, closures, in order not to clutter the global context, use something like BEM for styles. But the easiest way is to run the code in the iframe, it solves most of the isolation problems, but imposes certain restrictions. We use a hybrid version, about code isolation we will tell more in the next articles.
Block download site
The onload event occurs after the web page is fully loaded, including images, styles, and external scripts. An important feature is that on most sites JS-logic, third-party scripts and ads start to work when this event occurs. A very important point for all connected scripts is to prevent a negative impact on this event.
This happens when the server from which the script is loaded responds for a long time or does not respond at all: then the onload event is postponed and further loading of the page is in fact blocked. In the case when the server is unavailable, the onload event will occur only after a request timeout of more than 60 s. Thus, problems on the script's return server essentially “break” websites, which is unacceptable.
Personal experience
In the past I worked at a company that had a site with simultaneous online 100K, online dating. In those days, the “Share on social networks” buttons were popular. In order for them to appear on the site, it was necessary to connect a script (sdk) from the required social networks. One day, colleagues came running to us and said that our site is not working! We looked at the monitoring, in which everything was fine, and at first did not understand what the problem was. When we started to understand more deeply, we realized that the Twitter cdn servers had fallen down, and their SDK could not load, it blocked us from loading the site for ~ 1.5 minutes. That is, after opening the site, a small HTML was loaded (the rest of the SPA) and only after 1.5 minutes everything was loaded, the same request timeout worked. We had to urgently organize hotfix and remove their script from the site. After repeating this situation, we decided to remove the “Share” block altogether.
In the first versions of the code-inset, we did not take this into account, and in the case of technical problems on our side, we put it mildly, inconvenience to our customers, but over time we fixed it.
Decision
<script type='text/javascript'> (function(){ var initCode = function () { // insert script tag }; document.readyState === 'complete' ? initCode() : w.addEventListener('load', initCode, false); })(); </script> The solution is simple, you have to subscribe to the event of a full site load and only then load the script, for this you need to use the insert code, and not the script tag.
Google Pagespeed
The results of the analysis of the mobile version of habr.com
Most pay attention to the speed of loading the site, according to many studies, this directly affects the profits, besides search algorithms when ranking began to take into account the page load time. In this regard, site owners often use these tools to assess the performance of the site. Therefore, it is very important to optimally connect the code to the site, so it directly affects its load time.
This means that you need to use modern page load optimization techniques. For example, use Gzip, cache static files and requests, use asynchronous script downloads, statics compression with modern algorithms such as WebP / Brotli / etc, and use other optimizations. We regularly conduct audits and respond to warnings and recommendations to meet current requirements.
CDN
In the first versions we downloaded statics from the application servers. But this approach has disadvantages: expensive traffic, remoteness from site visitors and excessive load on the channel of servers. You can easily clog the channel of the application servers with the habr effect of the sites, since the static traffic is very “heavy”.
In order to save budget, stability and reduce network latency, it is optimal to load statics from servers specifically designed for this. You can use ready-made CDN-providers, but on a large scale it is expensive and you have to limit yourself to the opportunities offered by one or another provider.
We implemented it simply, ordered low-cost servers in Russia, Europe and America with unlimited traffic and a wide channel. This is cheap, does not impose any restrictions on us, we can customize everything for ourselves, and fault tolerance is provided by the mechanism working in the browser. At the moment, 1TB of statics is downloaded daily from our CDN servers.
fault tolerance
Unfortunately, the world is not perfect, fires occur, uplinks fall, DCs completely go under water, the RKN blocks subnets, and people make mistakes. However, it is necessary to be able to handle such situations and continue working.
Monitoring
First you need to understand that something went wrong. You can, of course, wait until users come and complain, but it is better to set up monitoring and alerts, and after releases, check if everything is in order. We monitor many different parameters, both server and client, and if something went wrong, we immediately see it. For example, the number of widget downloads or the anomalous surge in traffic on CDN servers has decreased.
The total number of widget downloads for each version
Error collection
JavaScript is a very specific language, and it’s easy to make a mistake. In addition, the zoo of browsers in the modern web is very large; what works in the latest Chrome is not a fact that will work in Safari or Firefox. Therefore, it is very important to set up a collection of errors from the browser and respond in time to surges. If your code works in an iframe, you can do this by tracking the global window.onerror handler and in case of an error send data to the server. If the code works outside the iframe, then it is very difficult to implement error collection.
The total number of errors from all sites and browsers
Information on a specific error
CDN Failover
I already wrote above that everything has a tendency to fall, so it is important to handle these situations and better - automatically. We went through several stages of the fullback CDN-servers, started with manual, and eventually found a way to do it automatically and optimally for the browser.
In manual mode, it worked simply: the administrators received an SMS stating that the CDN was down, they performed certain manipulations, after which the widget began to load from the application servers. This could take from 5 minutes to 2 hours.
To implement an automatic fallback, you need to somehow detect that the script has started downloading, but this is not as easy as it seems. The browser does not allow to monitor the intermediate status of loading the script tag, such as the onprogress event in XMLHttpRequest, and reports only the event at the end of the download and execution of the script. It is also impossible to find out in a reasonable time that the server is currently unavailable, the only onerror event is triggered when the request times out, more than 1 minute. Within a minute, a visitor can already leave the page, and the script will not load.
We tried different options, simple and complex, but eventually came to a solution with a ping request from a CDN server. It works this way: we first ping the CDN server, if answered, then we load the widget from it. To implement this scheme optimally for the browser and our servers, we use a light HEAD request (without a body), and we do not do it on subsequent downloads until the widget version is updated, since the widget is already in the browser cache.
Thus, we received a very fast and automatically detecting the availability of a statics server and in the case of a drop, we switch to a backup server with almost no delays.
Loader
To upload your script to a third-party site, you need to take into account many points, but it’s difficult to implement this logic in the insert code, since it will simply turn into “meat”. But we still need to do this, for this we have created a small module that controls all this logic “under the hood” and loads the main code of the widget. It is loaded first and implements CDN Failover, caching, backward compatibility with old insert codes, A / B testing, gradual display of the new version of the widget, and many other functions.
Thus, in stages, we arrived at a scheme that covers the main cases of loading and initializing the widget. It has proven its effectiveness over the years of use on a large number of different sites. At the same time, the insert code remains simple and universal, since there is no logic in it and we can change it at any time, without forcing users to change the insert code.
Third Party Services
And finally, it is worth mentioning about third-party services that connect to the site or in some way interact with the sites: search bots, analytics, various parsers and so on. These services leave an imprint at work, about this, too, should not be forgotten. I'll tell you a few cases from our practice.
Googlebot
In our operator’s application, there is a “Visitors” function in which you can view visitors currently browsing the site and various information on them: time on the site, page, number of pages viewed, and so on. At a certain point, customers began to complain that visitors from other sites, that is, on a website for the sale of iPhones, a customer who allegedly had a “Buy face cream” page, “hang out” at them. When they started to figure it out, they found out that it was GoogleBot, which, when going from site to site, cached LocalStorage first and subsequently transferred incorrect data to the server.
The solution is simple, the server started to ignore data from GoogleBot.
Yandex.Metrica
There is a great feature in the metric - the web viewer, which allows you to see what the user has seen and done, in the form of a screencast. To do this, the metric records all user actions, and after the special metric bot walks through the sites, performs the same actions and records it. The problem was that, according to our data, Firefox was turned on in mobile emulation mode to emulate the mobile browser of the user, but the bot had a userAgent desktop.
This led to the fact that when viewing mobile user sessions in the web browser, the desktop version of the widget was opened on the record, although in reality the users had a mobile one. Our clients thought that this is the case, and filled us with complaints. , , , , .
, , , .
Conclusion
, . . , , NodeJS , 250 - , .
, !
Source: https://habr.com/ru/post/452802/
All Articles