How do we deal with copying content, or the first adversarial attack in the sale
Hey.
Did you know that ad platforms often copy content from competitors in order to increase the number of ads? They do it like this: ring up the sellers and offer them to be accommodated on their platform. And sometimes they copy ads without permission from users. Avito is a popular venue, and we often face such unfair competition. Read about how we deal with this phenomenon under the cut.

Problem
Copying content from Avito to other platforms exists in several categories of goods and services. This article will only discuss cars. In the previous post, I told you about how we did auto-hide the number on cars.

But it turned out (judging by the search results of other platforms) that we launched this feature on three ad sites at once.
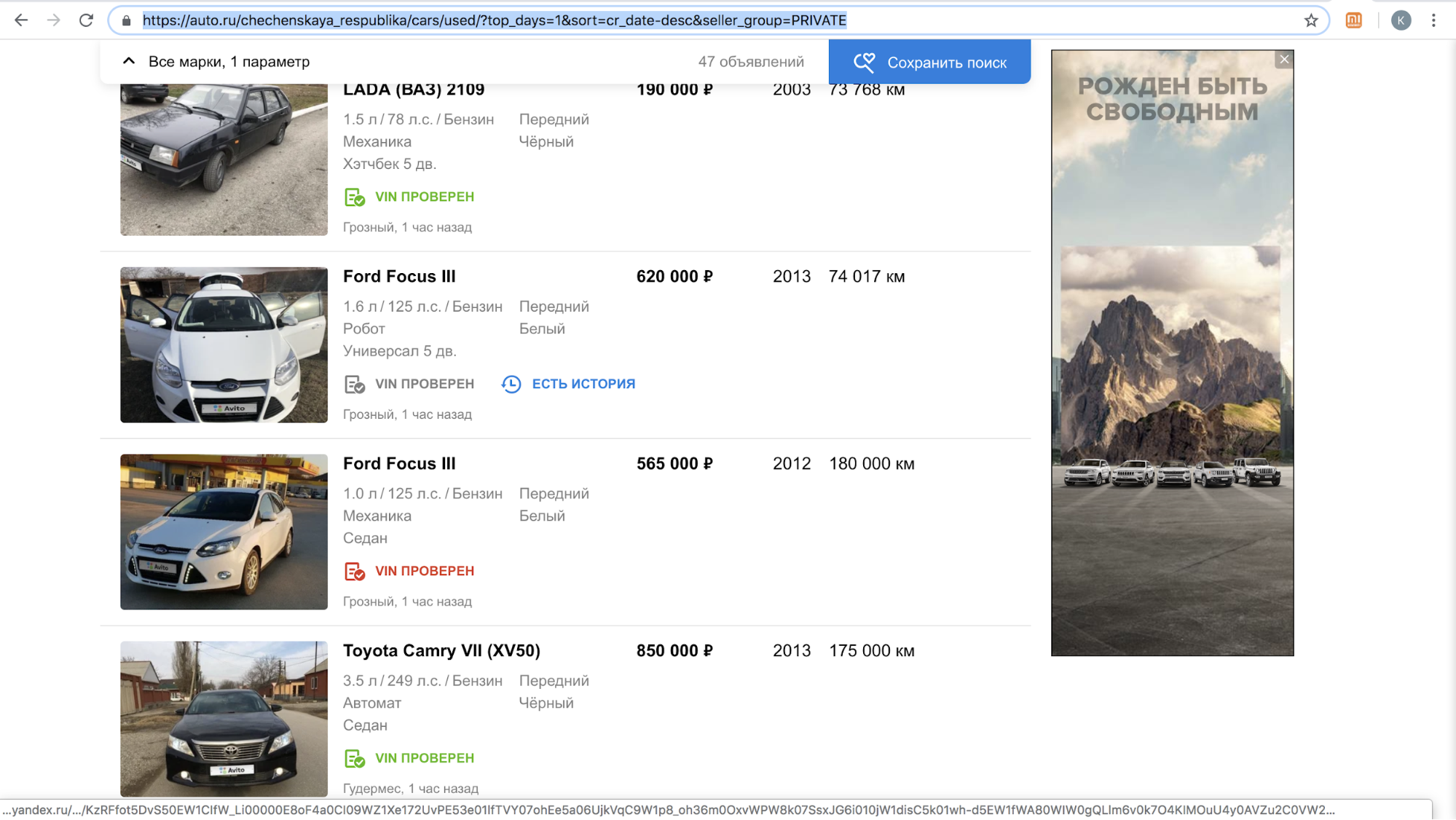
After the launch of one of these sites, we temporarily stopped calling our users with offers to copy an ad to their platform: there was too much content with the Avito logo on their site, only in November 2018 - more than 70,000 ads. For example, this is how their search results per day in the Chechen Republic looked like.
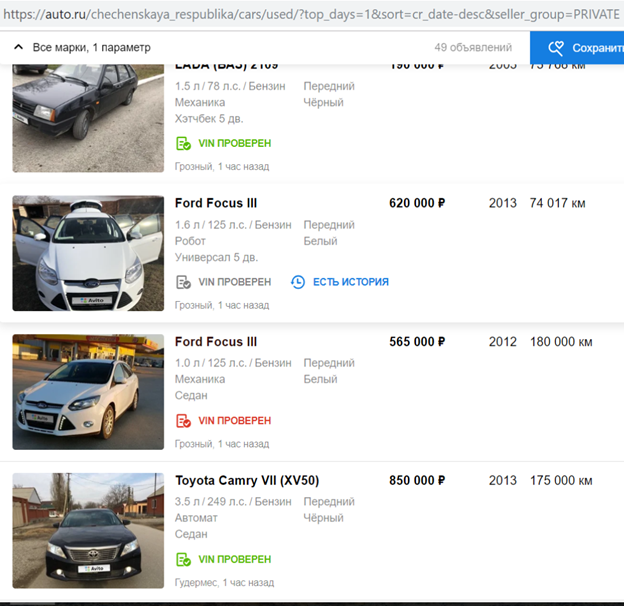
After training their license plate hiding algorithm so that it automatically detects and closes the Avito logo, they resumed the process.

From our point of view, copying the content of competitors, using it for commercial purposes is unethical and unacceptable. We receive complaints from our users who are unhappy with this in our support. And here is an example of the reaction in one of the stores.
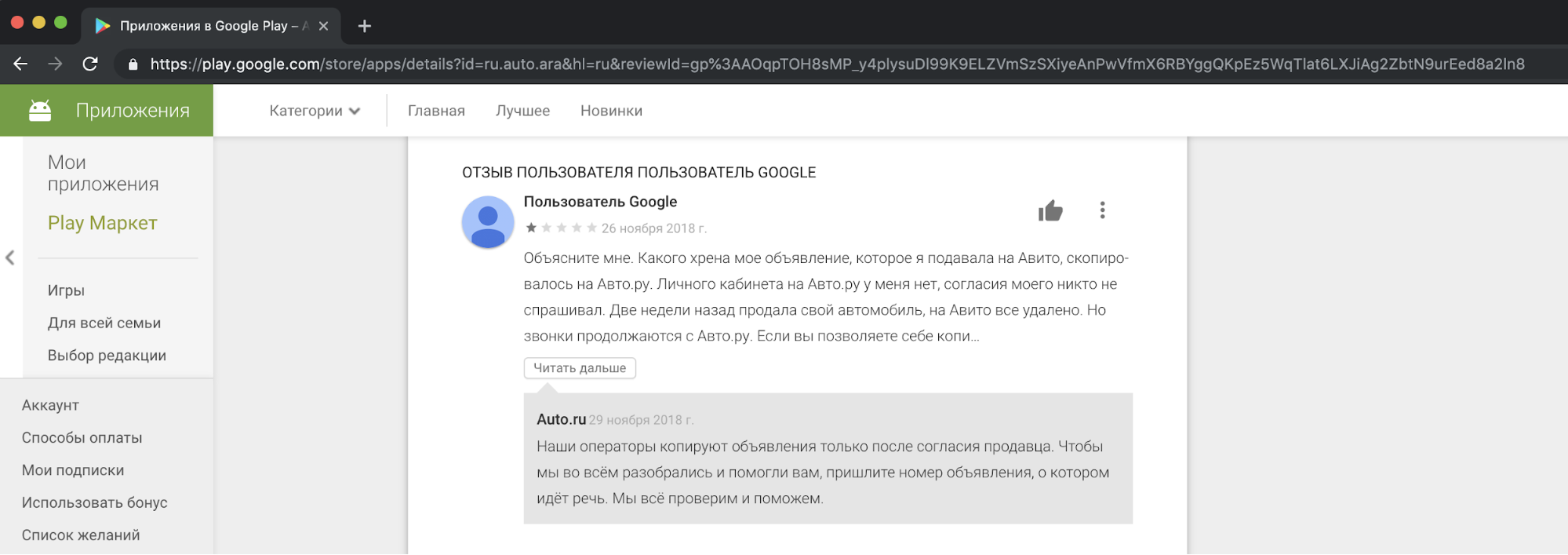
It must be said that asking people for consent to copy ads does not justify such actions. This is a violation of the laws "On Advertising" and "On Personal Data", Avito rules, trademark rights and the database of announcements.
We did not manage to agree peacefully with a competitor, and we did not want to leave the situation as it is.
Ways to solve the problem
The first method is legal. Similar precedents have already been in other countries. For example, the well-known American klassifayd Craigslist sued large sums of money from sites copying from it.
The second way to solve the problem of copying is to add a large watermark to the image so that it cannot be cut off.
The third way is technological. We may hinder the process of copying our content. It is logical to assume that some model is involved in hiding Avito’s logo from competitors. It is also known that many models are subject to "attacks" that prevent them from working correctly. This article is about them.
Adversarial attack

Ideally, the adversarial example for the network looks like a noise indistinguishable by the human eye, but for the classifier it adds a sufficient signal to the class that is absent in the picture. As a result, a picture, for example, with a panda, is classified with high confidence as a gibbon. Creating adversarial noise is possible not only for image classification networks, but also for segmentation, detection. An interesting example is the recent work from Keen Labs: they tricked the Tesla autopilot with dots on the pavement and a rain detector by displaying just such adversarial noise . There are also attacks for other domains, for example, sound: the famous attack on Amazon Alexa and other voice assistants consisted in playing commands indistinguishable by the human ear (hackers offered to buy something on Amazon).
The creation of adversarial noise for models that analyze images is possible due to the non-standard use of the gradient necessary for training the model. Usually, in the method of back propagation of error, using the calculated gradient of the objective function, only the weights of the layers of the network change so that it is less mistaken in the training dataset. Just as with network layers, you can calculate the gradient of the objective function from the input image and change it. Changing the input image using a gradient was applied for various known algorithms. Remember Deepdream ?

If we iteratively compute the gradient of the objective function from the input image and add this gradient to it, more information about the prevailing class from ImageNet will appear in the image: more dog faces appear, thus reducing the value of the loss function and the model becomes more confident in the dog class. Why are dogs in the example? Just in ImageNet from 1000 classes - 120 classes of dogs . A similar approach to changing the image was used in the Style Transfer algorithm, known mainly due to the Prisma application.
To create an adversarial example, you can also use an iterative method for changing the input image.
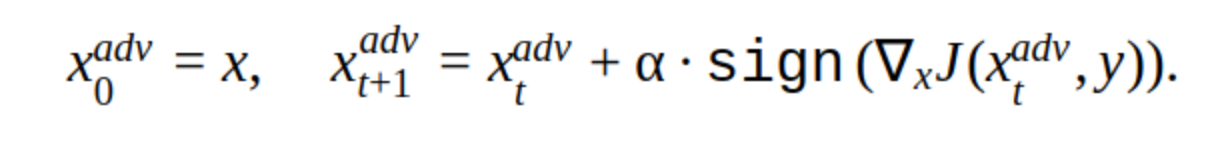
This method has several modifications, but the basic idea is simple: the original image is iteratively shifted in the direction of the gradient of the loss function of the classifier J (because only the sign is used) with the increment α. 'y' is the class that is represented in the image to reduce network confidence in the correct answer. Such an attack is called non targeted. You can choose the optimal step and the number of iterations so that the change in the input image is indistinguishable from the usual for a person. But in terms of time costs, such an attack does not suit us. 5-10 iterations for one image in the sale is a long time.
An alternative to iterative methods is the FGSM method.

This is the single-shot method, i.e. to use it, you need to count the gradient of the loss function once on the input image, and the adversarial noise to add to the picture is ready. This method is obviously more productive. It can be applied in production.
Creating adversarial examples
We decided to start with hacking our own model.
This is a picture that reduces the probability of finding a license plate for our model.

It can be seen that this method has a drawback: the changes that it adds to the picture are noticeable to the eye. Also this method is non-targeted, but it can be changed to make a targeted attack. Then the model will predict the place for the license plate in another place. This is the T-FGSM method.
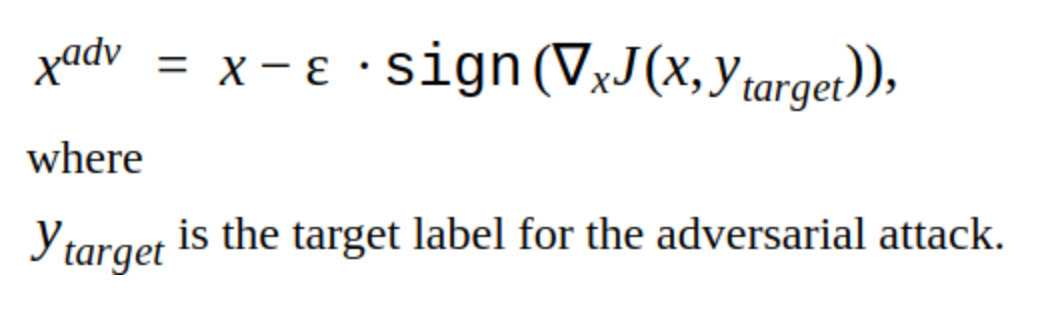
In order to break our model with this method, you need to change the input image a little more noticeably.

So far it is impossible to say that the results are perfect, but at least the efficiency of the methods has been verified. We also tried ready-made libraries for hacking Foolbox, CleverHans and ART-IBM networks, but with their help it was not possible to break our network for detection. The methods given there are better suited for classification networks. This is a general trend in network hacking: for object detection, it is more difficult to make an attack, especially when it comes to complex models, for example, Mask RCNN.
Attack testing
Everything that was described so far did not go beyond our internal experiments, but we had to figure out how to test the attacks on the detectors of other ad serving platforms.
It turns out that when submitting ads to one of the platforms, license plate detection occurs automatically, so you can upload photos and check how the detection algorithm copes with the new adversarial example many times.
It is perfectly! But…
None of the attacks that worked on our model worked when tested on another platform. Why did it happen? This is a consequence of the differences in the models and how poorly the adversarial attacks are generalized to different network architectures. Because of the difficulty of replaying attacks, they are divided into two groups: the white box and the black box.

Those attacks that we did on our model - it was a white box. What we need is a black box with additional restrictions on the inference: there is no API, all you can do is manually upload photos and check attacks. If there was an API, then you could make a substitute model.

The idea is to create a dataset of input images and answers of the black box model, on which several models of different architectures can be trained, so as to approximate the black box model. Then you can hold a white box attack on these models and they are more likely to work on the black box. In our case, this implies a lot of manual work, so this option did not suit us.
Break the deadlock
In search of interesting work on black box attacks, an article was found ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector
The authors of the article made attacks on the object detection network of self-driving machines by iteratively adding images, other than the true class, to the background of the stop sign.


Such an attack is clearly visible to the human eye, however, it successfully breaks down the work of the object detection network, which is what we need. Therefore, we decided to neglect the desired invisibility of the attack in favor of efficiency.
We wanted to check whether the detection model was retrained, does it use information about the car, or does Avito only need a die?
To do this, create this image:

We uploaded it as a car to the ad platform with a black box model. Got:

So, you can only change Avito's plate, the rest of the information in the input image is not necessary for detecting the black box model.
After several attempts, the idea of adding to the Avito plate an adversarial noise obtained by the FGSM method, which broke our own model, but with a rather large coefficient ε, arose. It turned out like this:

By car, it looks like this:

We uploaded photos to the platform with a black box model. The result was successful.

Applying this method to several other photos, we found that it does not work often. Then after several attempts, we decided to focus on the other most prominent part of the issue - the border. It is known that the initial convolutional layers of the network have activation on simple objects like lines, angles. By breaking the border line, we can prevent the network from correctly detecting the number area. This can be done, for example, by adding noise in the form of white squares of random size along the entire border of the number.

By uploading such a picture onto the platform with a black box model, we got a successful adversarial example.

Having tried this approach on a set of other pictures, we found out that the black box model can no longer detect Avito's plate (the set was assembled by hand, there are fewer than a hundred pictures, and it is certainly not representative, but it takes more time to make more). An interesting observation: the attack is successful only when combining noise in the letters Avito and random white squares in a frame; the use of these methods separately does not give a successful result.
As a result, we rolled out this algorithm in the prod, and this is what came of it :)
Multiple ads found


Something fresher:
We even got into the advertising platform:
Total
As a result, we managed to make an adversarial attack, which in our implementation does not increase the image processing time. The time we spent creating an attack is two weeks before the New Year. If it had not happened during this time to do it, they would have placed a watermark. Now the adversarial license plate is disabled, because now a competitor is calling users, invites them to upload photos into the advertisement themselves or replace the photo of the car with stock from the Internet.
')
Source: https://habr.com/ru/post/452142/
All Articles