Creating a procedural puzzle generator
This post describes the level generator for my Linjat puzzle game . Fasting can be read without preparation, but it is easier to learn if you play in several levels. I posted the source code on github ; Everything discussed in the article is in the
Approximate plan of the post:
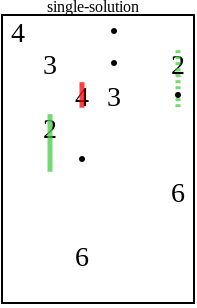
To understand how the level generator works, you need to, unfortunately, deal with the rules of the game. Fortunately, they are very simple. A puzzle consists of a grid containing empty squares, numbers and points. Example:
')

The goal of the player is to draw a vertical or horizontal line through each of the numbers, subject to three conditions:
Solution example:
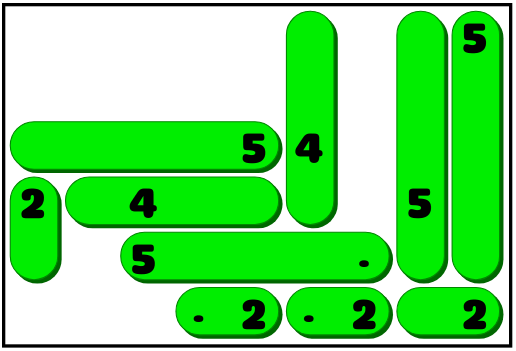
Hooray! The game design is ready, the UI is implemented, and now the only thing left is to find a few hundred good puzzles. And for such games, it usually does not make sense to try to create such puzzles manually. This is a job for the computer.
What makes the puzzle for this game good? I am inclined to believe that puzzle games can be divided into two categories. There are games in which you explore a complex state space from start to finish (for example, Sokoban or Rush Hour ), and in which it may not be obvious what conditions exist in the game. And there are games in which all the states are known from the very beginning, and we gradually sculpt the state space using the process of eliminating the excess (for example, Sudoku or Picross ). My game definitely belongs to the second category.
Players have very different requirements for these different types of puzzles. In the second case, they expect that the puzzle can only be solved by deduction, and that they will never need to go back / guess the trial and error process [0] [1] .
It is not enough to know whether the puzzle can be solved only by logic. In addition, we need to somehow understand how good the puzzles are. Otherwise, most levels will be just a trivial slag. In an ideal situation, this principle could also be used to create a smooth progress curve so that when a player passes the game, the levels gradually become more difficult.
The first step to meeting these requirements is to create a game solver optimized for this purpose. Solver rough backtracking allows you to quickly and accurately determine whether a puzzle is solvable; in addition, it can be modified to determine whether a solution is unique. But he cannot give an idea of how difficult the puzzle really is, because people solve them differently. Solver should imitate human behavior.
How does a person solve this puzzle? Here are a couple of obvious moves that the in-game tutorial teaches:
Such reasoning is the very basis of the game. The player looks for ways to stretch a little one line, and then studies the field again, because it can give him the information to make another logical conclusion. Creating a solver following these rules will be enough to determine if a person can solve a puzzle without going back.
However, this does not tell us anything about the complexity or interestingness of the level. In addition to deciding, we somehow need to numerically estimate the complexity.
An obvious first idea for the evaluation function: the more moves you need to solve a puzzle, the more difficult it is. This is probably a good metric in other games, but my most likely more important is the number of permissible moves that the player has. If a player can make 10 logical conclusions, he will most likely find one of them very quickly. If the right move is only one, then it will take more time.
That is, as a first approximation, we need the decision tree to be deep and narrow: there is a long dependence of the moves from beginning to end, and at each point in time there are only a small number of ways to move up the chain [2] .
How do we determine the width and depth of a tree? A one-time solution of the puzzle and evaluation of the created tree will not give an exact answer. The exact order of the moves made affects the shape of the tree. We need to consider all possible solutions and do something like optimization for them in the best and worst cases. I am familiar with the technique of rough search of search graphs in puzzle games , but for this project I wanted to create a one-pass solver, and not some kind of exhaustive search. Due to the optimization phase, I tried to ensure that the execution time of the solver was measured not in seconds, but in milliseconds.
I decided not to. Instead, my solver doesn’t actually make one move at a time, but solves the puzzle in layers: by taking a state, it finds all valid moves that can be made. Then he applies all these moves at the same time and starts anew in the new state. The number of layers and the maximum number of moves found on one layer are then used as approximate values of the depth and width of the search tree as a whole.
Here is how with this model the solution to one of the difficult puzzles looks. Dotted lines are lines stretched on this layer of the solver, solid lines are those that have not changed. The green lines are the correct length, the red lines are not yet complete.

The next problem is that all the moves made by the player are created equal. What we listed at the beginning of this section is just common sense. Here is an example of a more complex deduction rule, the search for which will require a little more thought. Consider this field:

Points in C and D can only be covered with a top five and a middle four (and no number can cover both points at the same time). This means that the four in the middle must cover one point of two, and therefore cannot be used to cover A. Therefore, point A must close the four in the lower left corner.
Obviously, it would be foolish to consider this chain of reasoning as equal to the simple conclusion "this point can be reached only from this number." Is it possible in the evaluation function to give these more complex rules more weight? Unfortunately, in the layer-based solver this is impossible, because it does not guarantee finding a solution with the lowest cost. This is not only a theoretical problem - in practice it is often the case that a part of a field is solved either by a single complicated argument or by a chain of much simpler moves. In fact, a layer-based solver finds the shortest, and not the least costly way, and this cannot be reflected in the evaluation function.
As a result, I came to this decision: I changed the solver so that each layer consisted of only one type of reasoning. The algorithm bypasses the rules of reasoning in an approximate order of complexity. If a rule finds any moves, they are applied, and this completes the iteration, and the next iteration starts the list from the very beginning.
Then the assessment is assigned to the decision: each layer is assigned costs based on one rule that was used in it. It still does not guarantee that the solution will be the most low-cost, but with the correct selection of weights, the algorithm will at least not find a costly solution if there is a cheap one.
In addition, it is very much like how people solve puzzles. They first try to find easy solutions, and begin to actively move their brains only if there are no simple moves.
The previous section determined whether a particular level was good or bad. But this is not enough, we still need to somehow generate levels so that the solver can evaluate them. It is very unlikely that a randomly generated world will be solvable, let alone interesting.
The basic idea (it is by no means new) is the alternate use of a solver and a generator. Let's start with a puzzle, which is probably unsolvable: we just place in the random squares of the cell the number from two to five:

Solver works until he can further develop:
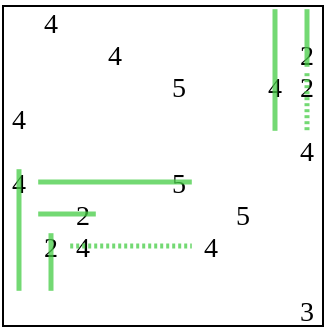
Then the generator adds more information in the puzzle in the form of a dot, after which the execution of the solver continues.
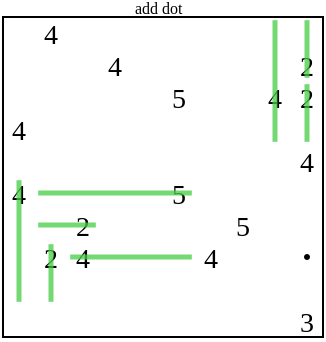
In this case, the added point of the solver is not enough for further development. Then the generator will continue to add new points until it satisfies the solver:

And then the solver continues his usual work:

This process continues either until the puzzle is solved, or until there is more information to add (for example, when each cell that can be reached from a number already contains a point).
This method only works if the added new information cannot invalidate any of the previously made conclusions. This would be difficult to do when adding numbers to the grid [3] . But adding new points to the field has this property; at least for the reasoning rules that I use in this program.
Where should the algorithm add points? In the end, I decided to add them to the empty space, which can be closed in the initial state with the greatest number of lines, so that each point would try to provide as little information as possible. I did not specifically try to place a point in the place where it would be useful to advance in solving the puzzle at the time when the solver gets stuck. This creates a very convenient effect: most of the points seem to be completely useless at the beginning of the puzzle, which makes the puzzle more difficult than it actually is. If all this is a set of obvious moves that a player can make, but for some reason not one of them fails to work properly. The result is that the puzzle generator behaves a bit piggy.
This process does not always create a solution, but it is quite fast (about 50-100 milliseconds), so to generate a level, you can simply repeat it several times. Unfortunately, he usually creates mediocre puzzles. From the very beginning, there are too many obvious moves, the field fills up very quickly and the decision tree turns out to be rather shallow.
The process described above created mediocre puzzles. In the final step, I use these levels as the basis for the optimization process. It works as follows.
The optimizer creates a pool that contains up to 10 puzzle options. The pool is initialized by a newly generated random puzzle. At each iteration, the optimizer selects one puzzle from the pool and performs its mutation.
A mutation removes all points, and then slightly changes the numbers (ie, decreases / increases the value of a randomly selected number or moves the number to another cell of the grid). You can apply multiple mutations to a field at the same time. Then we run the solver in the special level generation mode described in the previous section. He adds a sufficient number of points to the puzzle so that it becomes solvable again.
After that, we start the solver again, this time in normal mode. During this run, the solver tracks a) the depth of the decision tree, b) the frequency of the need for different kinds of rules, c) the width of the decision tree at different points in time. The puzzle is evaluated based on the criteria described above. The evaluation function prefers deep and narrow solutions, and levels of increased complexity also give more weight to puzzles that require the use of more complex reasoning rules.
Then a new puzzle is added to the pool. If the pool contains more than 10 puzzles, the worst is discarded.
This process is repeated several times (I was satisfied with approximately 10,000-50000 iterations). After that, the version of the puzzle with the highest score is saved to the database of puzzle levels. Here is how the progress of the best puzzle looks during one optimization run:

I tried using other ways to structure optimization. In one version, annealing imitation was used; others were genetic algorithms with various crossover operations. None of the solutions proved to be as good as a naive algorithm with a pool of options going to the top.
When a puzzle has a unique unique solution, an interesting difficulty arises. Is it possible to allow the player to assume that the decision is one and draw conclusions based on this? Will it be fair if the puzzle generator assumes that the player will do just that?
In a post on HackerNews, I said that there are four possible approaches to this situation:
Initially, I chose the latter option, and it was a terrible mistake. It turned out that I took into account only one way in which the uniqueness of the solution led to information leakage, and it is actually quite rare. But there are others; one of them was essentially present in every level that I generated and often led to the decision becoming trivial. Therefore, in May 2019, I changed the Hard and Expert modes using the third option.
The most annoying case is the deuce with a dotted line in this field:
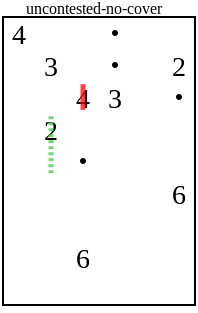
Why can a sly player make such a conclusion? Deuce can cover any of the four adjacent squares. There are no dots in any of them, so they do not have to be closed by a line. And the square below has no overlaps with any other numbers. If there is a unique solution, then this should be the case when other numbers cover the remaining three squares, and the two close the square under it.
The solution is to add a few more points when recognizing such cases:

Another common case is the two with a dotted line in this field:
The squares on the left and on top of the two are no different. None of them has a point, and none can be reached from any other number. Any solution in which the mark of two closes the upper square will have a corresponding solution in which it covers the left square, and vice versa. If there was a unique unique solution, then this could not be, and the two should have covered the bottom square.
I decided to use this type of cases in the way “if it hurts, then don't touch”. Solver applied this rule at an early stage in the list of priorities and assigned a large negative weight to such moves. Puzzles with this feature are usually discarded by the optimizer, and the few remaining ones are discarded during the final selection of levels for the published game.
This is not a complete list, during the testing with a deliberate search for errors, I found many other rules for unique solutions. But most of them seemed rare and were quite detectable, so they didn’t simplify the game very much. If someone solves the puzzle, using similar reasoning, then I will not blame them for it.
Initially, the game was developed as an experiment on procedural generation of puzzles. The design of the game and the generator went hand in hand, so the techniques themselves are difficult to apply directly in other games.
A question to which I have no answer: did investing of such efforts in procedural generation justify itself?Player feedback on level design was very controversial. In positive comments, it was usually said that there is always a tricky trick in the puzzles. In most of the negative reviews they wrote to me that the game lacks a gradient of complexity.
I have a couple more puzzles in the embryonic stage, and I liked the generator so much that most likely for them I use a similar procedural approach. I will change only one thing: from the very beginning I will conduct active playtesting with the search for errors.
[0] Or at least it seemed so to me. But when I watched the players live, almost half of them just made guesses, and then worked them out iteratively. Anyway.
[1] The readers of my article are also worth reading the article by Solving Minesweeper and making it better than Magnus Hoff.
[2] I’ll clarify that the depth / narrowness of the tree is a metric that I considered significant for my game, and not for all other puzzles. For example, there is a good argument that the Rush Hour puzzle is interesting if it has several ways to solve almost, but not quite the same length. But it happened because Rush Hour is a game for finding the shortest solution, and not just any solution.
[3] With the exception of adding units. In the first version of the puzzle there were no points, and the plan was to add units to the generator if necessary. But it seemed too restrictive.
src/main.cc .Approximate plan of the post:
- Linjat is a logic game in which you need to close all the numbers and points in the grid with lines.
- Puzzles are procedurally generated using a combination of solver, generator and optimizer.
- Solver tries to solve the puzzles the way a person would do it, and assigns an interesting score to each puzzle.
- The puzzle generator is created in such a way that it is easy to change one part of the puzzle (number) and at the same time all other parts (points) change so that the puzzle remains solvable.
- The puzzle optimizer repeatedly solves levels and generates new variations from the most interesting ones found so far.
rules
To understand how the level generator works, you need to, unfortunately, deal with the rules of the game. Fortunately, they are very simple. A puzzle consists of a grid containing empty squares, numbers and points. Example:
')
The goal of the player is to draw a vertical or horizontal line through each of the numbers, subject to three conditions:
- The line through the number must be the same length as the number.
- Lines can not intersect.
- All points must be closed lines.
Solution example:
Hooray! The game design is ready, the UI is implemented, and now the only thing left is to find a few hundred good puzzles. And for such games, it usually does not make sense to try to create such puzzles manually. This is a job for the computer.
Requirements
What makes the puzzle for this game good? I am inclined to believe that puzzle games can be divided into two categories. There are games in which you explore a complex state space from start to finish (for example, Sokoban or Rush Hour ), and in which it may not be obvious what conditions exist in the game. And there are games in which all the states are known from the very beginning, and we gradually sculpt the state space using the process of eliminating the excess (for example, Sudoku or Picross ). My game definitely belongs to the second category.
Players have very different requirements for these different types of puzzles. In the second case, they expect that the puzzle can only be solved by deduction, and that they will never need to go back / guess the trial and error process [0] [1] .
It is not enough to know whether the puzzle can be solved only by logic. In addition, we need to somehow understand how good the puzzles are. Otherwise, most levels will be just a trivial slag. In an ideal situation, this principle could also be used to create a smooth progress curve so that when a player passes the game, the levels gradually become more difficult.
Solver
The first step to meeting these requirements is to create a game solver optimized for this purpose. Solver rough backtracking allows you to quickly and accurately determine whether a puzzle is solvable; in addition, it can be modified to determine whether a solution is unique. But he cannot give an idea of how difficult the puzzle really is, because people solve them differently. Solver should imitate human behavior.
How does a person solve this puzzle? Here are a couple of obvious moves that the in-game tutorial teaches:
- If a point can be reached with only one number, then to close the point you need to draw a line out of this number. In this example, the point can be reached only from the triple, but not from the four:
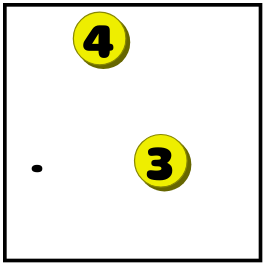
And this leads to this situation:
- If the line does not fit in one direction, then it must be placed in another. In the example shown above, the four can no longer be placed vertically, so we know that it will be horizontal:
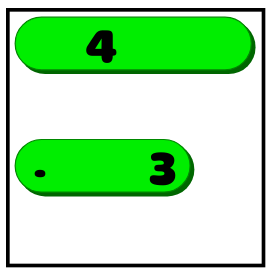
- If it is known that a line of length X must be in a certain position (vertical / horizontal) and not enough empty space to place a line of X empty cells on both sides, then it is necessary to cover several squares in the middle. If in the example shown above, the four were a troika, we would not know whether it stretches all the way to the right or left. But we would know that the line should cover two middle squares:
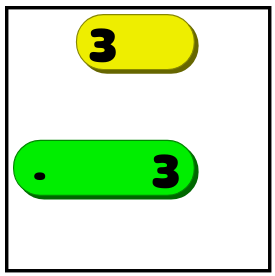
Such reasoning is the very basis of the game. The player looks for ways to stretch a little one line, and then studies the field again, because it can give him the information to make another logical conclusion. Creating a solver following these rules will be enough to determine if a person can solve a puzzle without going back.
However, this does not tell us anything about the complexity or interestingness of the level. In addition to deciding, we somehow need to numerically estimate the complexity.
An obvious first idea for the evaluation function: the more moves you need to solve a puzzle, the more difficult it is. This is probably a good metric in other games, but my most likely more important is the number of permissible moves that the player has. If a player can make 10 logical conclusions, he will most likely find one of them very quickly. If the right move is only one, then it will take more time.
That is, as a first approximation, we need the decision tree to be deep and narrow: there is a long dependence of the moves from beginning to end, and at each point in time there are only a small number of ways to move up the chain [2] .
How do we determine the width and depth of a tree? A one-time solution of the puzzle and evaluation of the created tree will not give an exact answer. The exact order of the moves made affects the shape of the tree. We need to consider all possible solutions and do something like optimization for them in the best and worst cases. I am familiar with the technique of rough search of search graphs in puzzle games , but for this project I wanted to create a one-pass solver, and not some kind of exhaustive search. Due to the optimization phase, I tried to ensure that the execution time of the solver was measured not in seconds, but in milliseconds.
I decided not to. Instead, my solver doesn’t actually make one move at a time, but solves the puzzle in layers: by taking a state, it finds all valid moves that can be made. Then he applies all these moves at the same time and starts anew in the new state. The number of layers and the maximum number of moves found on one layer are then used as approximate values of the depth and width of the search tree as a whole.
Here is how with this model the solution to one of the difficult puzzles looks. Dotted lines are lines stretched on this layer of the solver, solid lines are those that have not changed. The green lines are the correct length, the red lines are not yet complete.
The next problem is that all the moves made by the player are created equal. What we listed at the beginning of this section is just common sense. Here is an example of a more complex deduction rule, the search for which will require a little more thought. Consider this field:
Points in C and D can only be covered with a top five and a middle four (and no number can cover both points at the same time). This means that the four in the middle must cover one point of two, and therefore cannot be used to cover A. Therefore, point A must close the four in the lower left corner.
Obviously, it would be foolish to consider this chain of reasoning as equal to the simple conclusion "this point can be reached only from this number." Is it possible in the evaluation function to give these more complex rules more weight? Unfortunately, in the layer-based solver this is impossible, because it does not guarantee finding a solution with the lowest cost. This is not only a theoretical problem - in practice it is often the case that a part of a field is solved either by a single complicated argument or by a chain of much simpler moves. In fact, a layer-based solver finds the shortest, and not the least costly way, and this cannot be reflected in the evaluation function.
As a result, I came to this decision: I changed the solver so that each layer consisted of only one type of reasoning. The algorithm bypasses the rules of reasoning in an approximate order of complexity. If a rule finds any moves, they are applied, and this completes the iteration, and the next iteration starts the list from the very beginning.
Then the assessment is assigned to the decision: each layer is assigned costs based on one rule that was used in it. It still does not guarantee that the solution will be the most low-cost, but with the correct selection of weights, the algorithm will at least not find a costly solution if there is a cheap one.
In addition, it is very much like how people solve puzzles. They first try to find easy solutions, and begin to actively move their brains only if there are no simple moves.
Generator
The previous section determined whether a particular level was good or bad. But this is not enough, we still need to somehow generate levels so that the solver can evaluate them. It is very unlikely that a randomly generated world will be solvable, let alone interesting.
The basic idea (it is by no means new) is the alternate use of a solver and a generator. Let's start with a puzzle, which is probably unsolvable: we just place in the random squares of the cell the number from two to five:
Solver works until he can further develop:
Then the generator adds more information in the puzzle in the form of a dot, after which the execution of the solver continues.
In this case, the added point of the solver is not enough for further development. Then the generator will continue to add new points until it satisfies the solver:
And then the solver continues his usual work:
This process continues either until the puzzle is solved, or until there is more information to add (for example, when each cell that can be reached from a number already contains a point).
This method only works if the added new information cannot invalidate any of the previously made conclusions. This would be difficult to do when adding numbers to the grid [3] . But adding new points to the field has this property; at least for the reasoning rules that I use in this program.
Where should the algorithm add points? In the end, I decided to add them to the empty space, which can be closed in the initial state with the greatest number of lines, so that each point would try to provide as little information as possible. I did not specifically try to place a point in the place where it would be useful to advance in solving the puzzle at the time when the solver gets stuck. This creates a very convenient effect: most of the points seem to be completely useless at the beginning of the puzzle, which makes the puzzle more difficult than it actually is. If all this is a set of obvious moves that a player can make, but for some reason not one of them fails to work properly. The result is that the puzzle generator behaves a bit piggy.
This process does not always create a solution, but it is quite fast (about 50-100 milliseconds), so to generate a level, you can simply repeat it several times. Unfortunately, he usually creates mediocre puzzles. From the very beginning, there are too many obvious moves, the field fills up very quickly and the decision tree turns out to be rather shallow.
Optimizer
The process described above created mediocre puzzles. In the final step, I use these levels as the basis for the optimization process. It works as follows.
The optimizer creates a pool that contains up to 10 puzzle options. The pool is initialized by a newly generated random puzzle. At each iteration, the optimizer selects one puzzle from the pool and performs its mutation.
A mutation removes all points, and then slightly changes the numbers (ie, decreases / increases the value of a randomly selected number or moves the number to another cell of the grid). You can apply multiple mutations to a field at the same time. Then we run the solver in the special level generation mode described in the previous section. He adds a sufficient number of points to the puzzle so that it becomes solvable again.
After that, we start the solver again, this time in normal mode. During this run, the solver tracks a) the depth of the decision tree, b) the frequency of the need for different kinds of rules, c) the width of the decision tree at different points in time. The puzzle is evaluated based on the criteria described above. The evaluation function prefers deep and narrow solutions, and levels of increased complexity also give more weight to puzzles that require the use of more complex reasoning rules.
Then a new puzzle is added to the pool. If the pool contains more than 10 puzzles, the worst is discarded.
This process is repeated several times (I was satisfied with approximately 10,000-50000 iterations). After that, the version of the puzzle with the highest score is saved to the database of puzzle levels. Here is how the progress of the best puzzle looks during one optimization run:
I tried using other ways to structure optimization. In one version, annealing imitation was used; others were genetic algorithms with various crossover operations. None of the solutions proved to be as good as a naive algorithm with a pool of options going to the top.
Unique unique solution
When a puzzle has a unique unique solution, an interesting difficulty arises. Is it possible to allow the player to assume that the decision is one and draw conclusions based on this? Will it be fair if the puzzle generator assumes that the player will do just that?
In a post on HackerNews, I said that there are four possible approaches to this situation:
- Declare the uniqueness of the solution from the very beginning and force the generator to create levels that require this type of reasoning. This is a bad decision, because it complicates the understanding of the rules. And usually these are the details people forget.
- Do not guarantee the uniqueness of the decision: potentially have a lot of decisions and make them all. In fact, it does not solve the problem, but pushes it away.
- Just assume that this is a very rare event that is not important in practice. (This is the solution that was used in the initial implementation.)
- Modify the puzzle generator so that it does not generate puzzles in which knowledge of the uniqueness of the solution would help. (Probably the right decision, but requiring additional work.)
Initially, I chose the latter option, and it was a terrible mistake. It turned out that I took into account only one way in which the uniqueness of the solution led to information leakage, and it is actually quite rare. But there are others; one of them was essentially present in every level that I generated and often led to the decision becoming trivial. Therefore, in May 2019, I changed the Hard and Expert modes using the third option.
The most annoying case is the deuce with a dotted line in this field:
Why can a sly player make such a conclusion? Deuce can cover any of the four adjacent squares. There are no dots in any of them, so they do not have to be closed by a line. And the square below has no overlaps with any other numbers. If there is a unique solution, then this should be the case when other numbers cover the remaining three squares, and the two close the square under it.
The solution is to add a few more points when recognizing such cases:
Another common case is the two with a dotted line in this field:
The squares on the left and on top of the two are no different. None of them has a point, and none can be reached from any other number. Any solution in which the mark of two closes the upper square will have a corresponding solution in which it covers the left square, and vice versa. If there was a unique unique solution, then this could not be, and the two should have covered the bottom square.
I decided to use this type of cases in the way “if it hurts, then don't touch”. Solver applied this rule at an early stage in the list of priorities and assigned a large negative weight to such moves. Puzzles with this feature are usually discarded by the optimizer, and the few remaining ones are discarded during the final selection of levels for the published game.
This is not a complete list, during the testing with a deliberate search for errors, I found many other rules for unique solutions. But most of them seemed rare and were quite detectable, so they didn’t simplify the game very much. If someone solves the puzzle, using similar reasoning, then I will not blame them for it.
Conclusion
Initially, the game was developed as an experiment on procedural generation of puzzles. The design of the game and the generator went hand in hand, so the techniques themselves are difficult to apply directly in other games.
A question to which I have no answer: did investing of such efforts in procedural generation justify itself?Player feedback on level design was very controversial. In positive comments, it was usually said that there is always a tricky trick in the puzzles. In most of the negative reviews they wrote to me that the game lacks a gradient of complexity.
I have a couple more puzzles in the embryonic stage, and I liked the generator so much that most likely for them I use a similar procedural approach. I will change only one thing: from the very beginning I will conduct active playtesting with the search for errors.
Notes
[0] Or at least it seemed so to me. But when I watched the players live, almost half of them just made guesses, and then worked them out iteratively. Anyway.
[1] The readers of my article are also worth reading the article by Solving Minesweeper and making it better than Magnus Hoff.
[2] I’ll clarify that the depth / narrowness of the tree is a metric that I considered significant for my game, and not for all other puzzles. For example, there is a good argument that the Rush Hour puzzle is interesting if it has several ways to solve almost, but not quite the same length. But it happened because Rush Hour is a game for finding the shortest solution, and not just any solution.
[3] With the exception of adding units. In the first version of the puzzle there were no points, and the plan was to add units to the generator if necessary. But it seemed too restrictive.
Source: https://habr.com/ru/post/452090/
All Articles