Sometimes more is less. When reducing the load increases the delay
As in most posts , there is a problem with a distributed service, let's call this service Alvin. This time I did not find the problem myself, I was told by the guys from the client side.
One day, I woke up with a disgruntled letter due to large delays from Alvin, whom we planned to launch soon. In particular, the client was faced with a delay of the 99th percentile in the region of 50 ms, much higher than our delay budget. This was surprising, since I thoroughly tested the service, especially for delays, because this is the subject of frequent complaints.
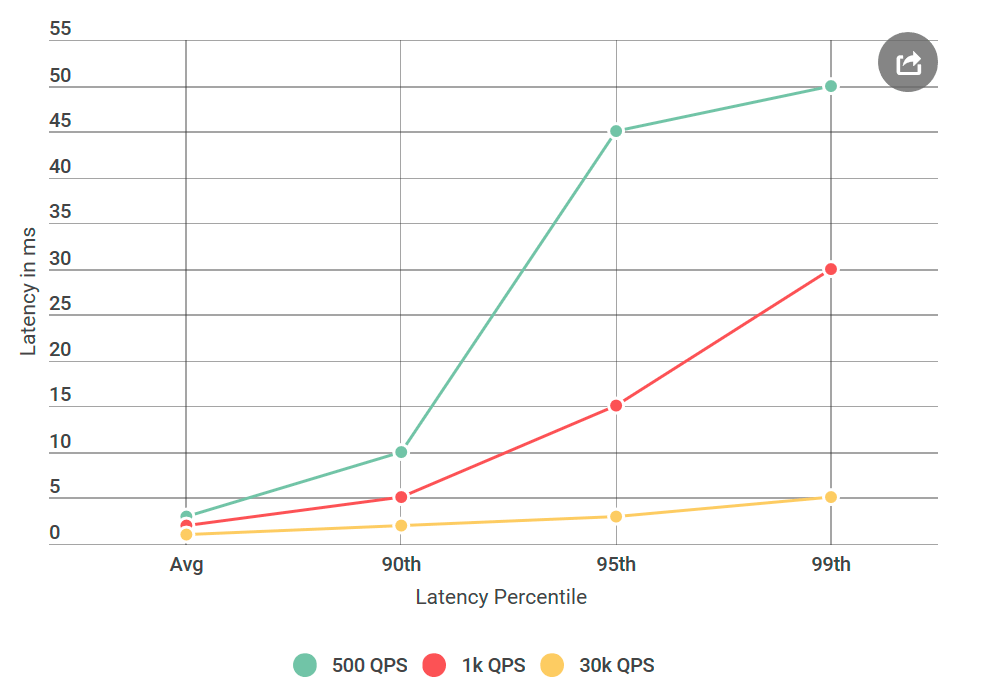
Before giving Alvin to testing, I conducted many experiments with 40 thousand requests per second (QPS), all showed a delay of less than 10 ms. I was ready to state that I did not agree with their results. But once again looking at the letter, I noticed something new: I definitely did not test the conditions they mentioned, their QPS was much lower than mine. I tested on 40k QPS, and they only on 1k. I started another experiment, this time with lower QPS, just to appease them.
As I write about this in a blog, you probably already understood: their numbers turned out to be correct. I checked my virtual client again and again, with the same result: a low number of requests not only increases the delay, but increases the number of requests with a delay of more than 10 ms. In other words, if at 40k QPS about 50 requests per second exceeded 50 ms, then at 1k QPS every second there were 100 requests above 50 ms. Paradox!
')
Faced with the problem of latency in a distributed system with many components, the first thing to do is to make a short list of suspects. Let's dig a little deeper into the architecture of Alvin:
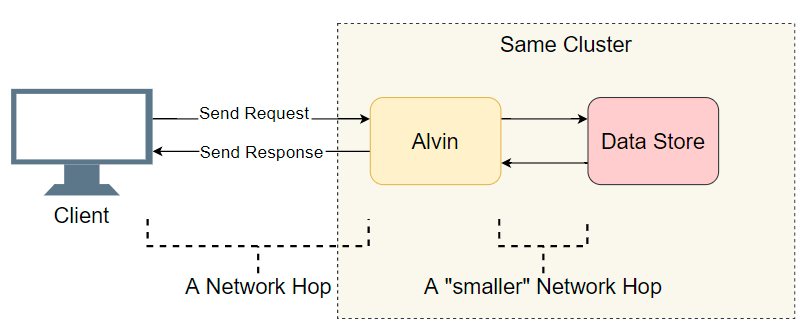
A good starting point is a list of I / O transitions performed (network calls / disk search, etc.). Let's try to figure out where the delay is. In addition to the obvious I / O with the client, Alvin takes an extra step: he accesses the data store. However, this storage works in the same cluster with Alvin, so there should be less delay there than with the client. So, the list of suspects:
Let's try to cross out some items.
First of all, I converted Alvin to a ping-ping server that does not process requests. Upon receiving the request, it returns an empty response. If the delay is reduced, then the error in the implementation of Alvin or the data warehouse is nothing unheard of. In the first experiment we get the following schedule:
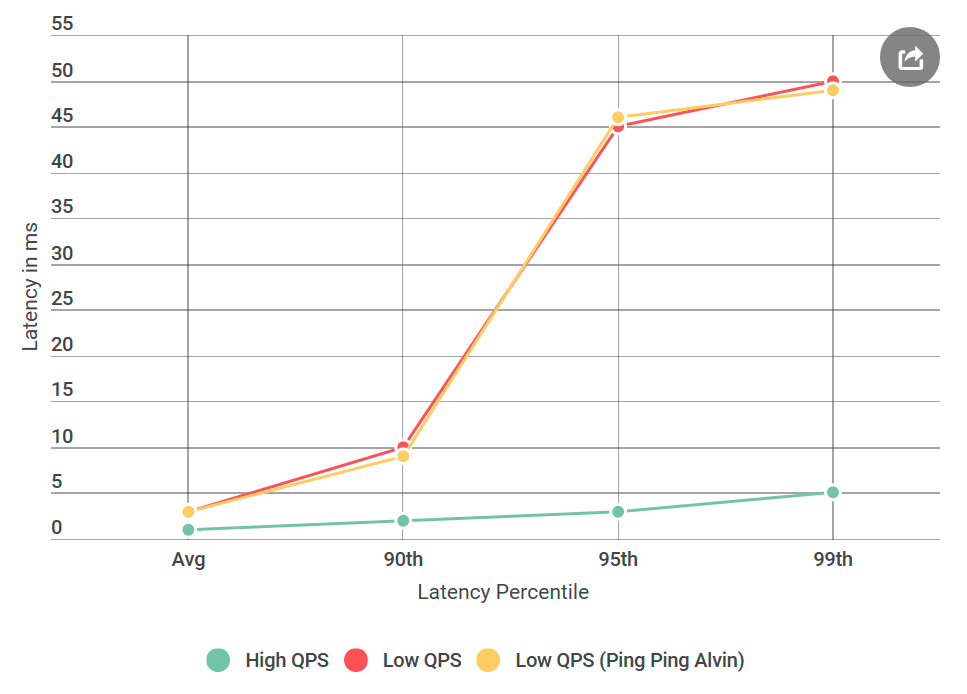
As you can see, there is no improvement when using the ping-ping server. This means that the data warehouse does not increase the delay, and the list of suspects is halved:
Great! The list is rapidly shrinking. I thought I almost figured out the reason.
Now is the time to introduce you to a new player: gRPC . It is Google’s open source library for in-process RPC communication. Although
The presence of
So that you understand what the code looks like, my client / Alvin implementation is not much different from the client-server async examples .
Having crossed out the data store, I thought I was almost done: “Now it’s easy! Apply the profile and find out where the delay occurs. ” I am a big fan of accurate profiling , because CPUs are very fast and most often are not a bottleneck. Most delays occur when the processor has to stop processing in order to do something else. Exact profiling of the CPU is done precisely for this: it accurately records all context switches and makes it clear where delays occur.
I took four profiles: under high QPS (small delay) and with a ping-pong server on a low QPS (large delay), both on the client side and on the server side. And just in case, I also took a sample of the processor profile. When comparing profiles, I usually look for an anomalous call stack. For example, on the bad side with high latency, there are much more context switches (10 or more times). But in my case, the number of context switches almost coincided. To my horror, there was nothing substantial there.
I was desperate. I did not know what other tools could be used, and my next plan was essentially to repeat experiments with different variations, and not to clearly diagnose the problem.
From the very beginning, I was worried about the specific delay time of 50 ms. This is a very big time. I decided that I would cut the pieces out of the code until I could figure out exactly which part causes this error. Then followed an experiment that worked.
As usual, with hindsight it seems that everything was obvious. I put the client on the same machine with Alvin - and sent a request to
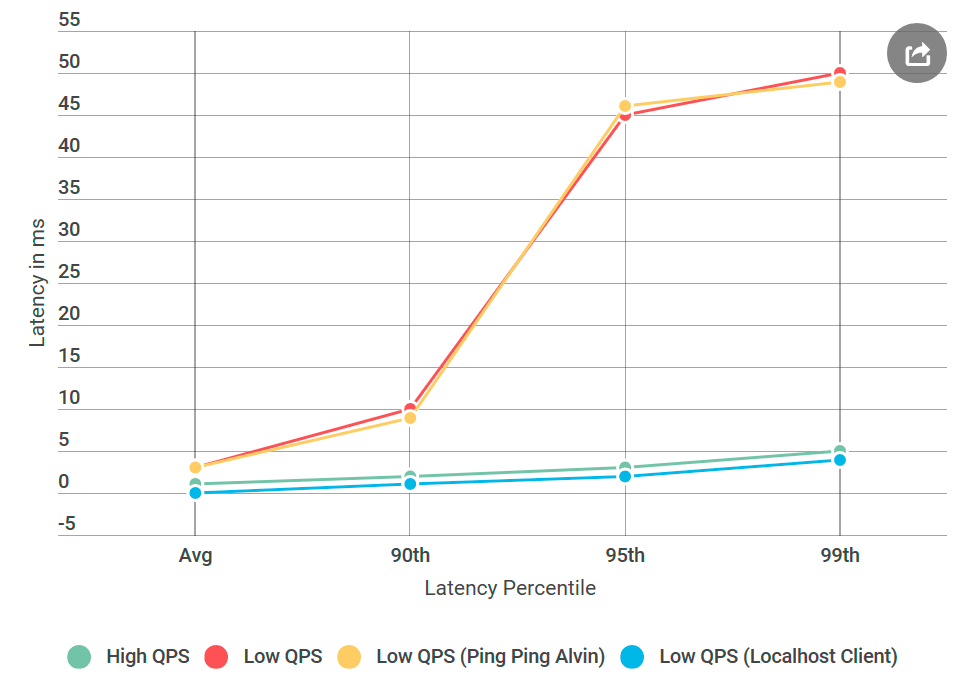
Something was wrong with the network.
I must admit that my knowledge of network technologies is terrible, especially given the fact that I work with them daily. But the network was the main suspect, and I needed to learn how to debug it.
Fortunately, the Internet loves those who want to learn. The combination of ping and tracert seemed like a good enough start to debug network transport problems.
First, I launched PsPing on Alvin 's TCP port. I used the default settings - nothing special. Of the more than a thousand pings, none exceeded 10 ms, except for the first to warm up. This contradicts the observed increase in the delay of 50 ms in the 99th percentile: there for every 100 queries we should have seen about one query with a delay of 50 ms.
Then I tried the tracert : maybe the problem is on one of the nodes along the route between Alvin and the client. But the tracer returned empty-handed.
Thus, the reason for the delay was not my code, not the implementation of gRPC and not the network. I already began to worry that I would never understand.
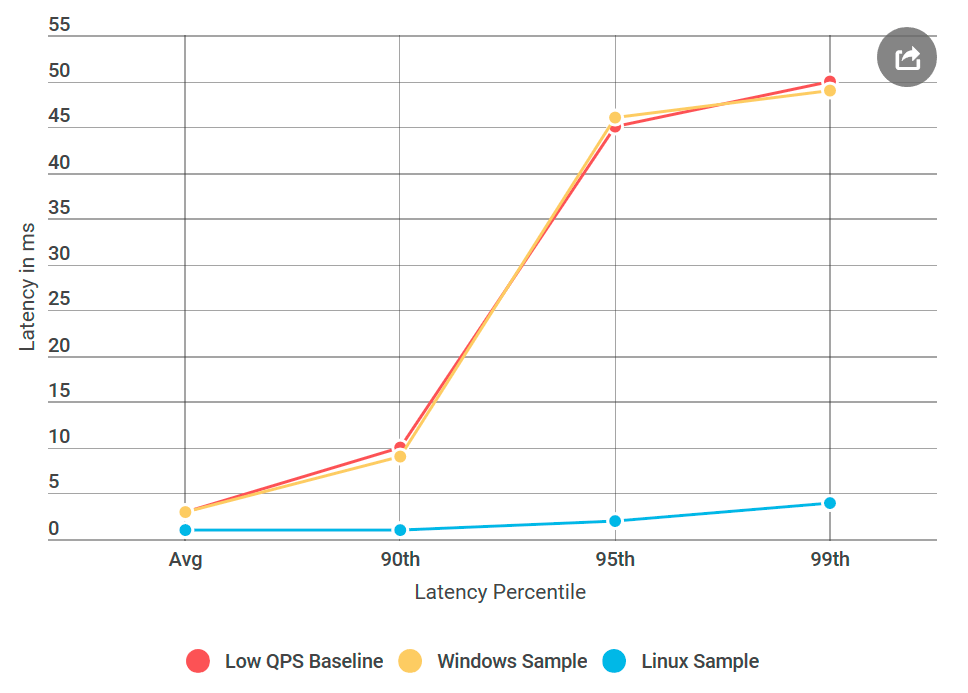
And that's what happened: in the Linux ping-pong server there were no such delays as that of a similar Windows node, although the data source was not different. It turns out the problem is in the implementation of gRPC for Windows.
All this time, I thought I was missing the

Almost done: I started to remove the added flags one by one, until the regression returned, so I was able to pinpoint its cause. It was the infamous TCP_NODELAY , the Nagle switch.
Nagle’s algorithm attempts to reduce the number of packets sent over the network by delaying the transmission of messages until the size of the packet exceeds a certain number of bytes. While this may be nice for the average user, it is destructive for real-time servers, because the OS will delay some messages, causing delays at low QPS.
The big delay on low QPS was caused by optimization of OS. Looking back, the profiling did not detect a delay, because it was done in kernel mode and not in user mode . I don’t know if Nagle’s algorithm can be observed through ETW captures, but that would be interesting.
As for the localhost experiment, it probably didn’t touch the actual network code, and Nagleg’s algorithm didn’t start, so the delay problems disappeared when the client accessed Alvin through localhost.
The next time you see an increase in latency with a decrease in requests per second, Nagle's algorithm should be on your suspect list!
One day, I woke up with a disgruntled letter due to large delays from Alvin, whom we planned to launch soon. In particular, the client was faced with a delay of the 99th percentile in the region of 50 ms, much higher than our delay budget. This was surprising, since I thoroughly tested the service, especially for delays, because this is the subject of frequent complaints.
Before giving Alvin to testing, I conducted many experiments with 40 thousand requests per second (QPS), all showed a delay of less than 10 ms. I was ready to state that I did not agree with their results. But once again looking at the letter, I noticed something new: I definitely did not test the conditions they mentioned, their QPS was much lower than mine. I tested on 40k QPS, and they only on 1k. I started another experiment, this time with lower QPS, just to appease them.
As I write about this in a blog, you probably already understood: their numbers turned out to be correct. I checked my virtual client again and again, with the same result: a low number of requests not only increases the delay, but increases the number of requests with a delay of more than 10 ms. In other words, if at 40k QPS about 50 requests per second exceeded 50 ms, then at 1k QPS every second there were 100 requests above 50 ms. Paradox!
')
Narrowing the search range
Faced with the problem of latency in a distributed system with many components, the first thing to do is to make a short list of suspects. Let's dig a little deeper into the architecture of Alvin:
A good starting point is a list of I / O transitions performed (network calls / disk search, etc.). Let's try to figure out where the delay is. In addition to the obvious I / O with the client, Alvin takes an extra step: he accesses the data store. However, this storage works in the same cluster with Alvin, so there should be less delay there than with the client. So, the list of suspects:
- Network call from client to alvin.
- Network call from Alvin to the data warehouse.
- Search disk in data storage.
- Network call from the data warehouse to Alvin.
- Network call from Alvin to the client.
Let's try to cross out some items.
Data storage with nothing
First of all, I converted Alvin to a ping-ping server that does not process requests. Upon receiving the request, it returns an empty response. If the delay is reduced, then the error in the implementation of Alvin or the data warehouse is nothing unheard of. In the first experiment we get the following schedule:
As you can see, there is no improvement when using the ping-ping server. This means that the data warehouse does not increase the delay, and the list of suspects is halved:
- Network call from client to alvin.
- Network call from Alvin to the client.
Great! The list is rapidly shrinking. I thought I almost figured out the reason.
gRPC
Now is the time to introduce you to a new player: gRPC . It is Google’s open source library for in-process RPC communication. Although
gRPC well optimized and widely used, I first used it in a system of this magnitude, and I expected my implementation to be suboptimal - to say the least.The presence of
gRPC in the stack gave rise to a new question: maybe this is my implementation or is the gRPC itself causing a delay problem? Add to the list of new suspect:- The client calls the
gRPClibrary - The
gRPClibrary on the client makes a network call to thegRPClibrary on the server - The
gRPClibrary refers to Alvin (there is no operation in the case of a ping-pong server)
So that you understand what the code looks like, my client / Alvin implementation is not much different from the client-server async examples .
Note: The above list is a bit simplified, sincegRPCallows you to use your own (template?) Streaming model, in which thegRPCexecutiongRPCand the user implementation are intertwined. For the sake of simplicity, we will stick to this model.
Profiling will fix everything
Having crossed out the data store, I thought I was almost done: “Now it’s easy! Apply the profile and find out where the delay occurs. ” I am a big fan of accurate profiling , because CPUs are very fast and most often are not a bottleneck. Most delays occur when the processor has to stop processing in order to do something else. Exact profiling of the CPU is done precisely for this: it accurately records all context switches and makes it clear where delays occur.
I took four profiles: under high QPS (small delay) and with a ping-pong server on a low QPS (large delay), both on the client side and on the server side. And just in case, I also took a sample of the processor profile. When comparing profiles, I usually look for an anomalous call stack. For example, on the bad side with high latency, there are much more context switches (10 or more times). But in my case, the number of context switches almost coincided. To my horror, there was nothing substantial there.
Additional debugging
I was desperate. I did not know what other tools could be used, and my next plan was essentially to repeat experiments with different variations, and not to clearly diagnose the problem.
What if
From the very beginning, I was worried about the specific delay time of 50 ms. This is a very big time. I decided that I would cut the pieces out of the code until I could figure out exactly which part causes this error. Then followed an experiment that worked.
As usual, with hindsight it seems that everything was obvious. I put the client on the same machine with Alvin - and sent a request to
localhost . And the delay increase has disappeared!Something was wrong with the network.
Master the skills of a network engineer
I must admit that my knowledge of network technologies is terrible, especially given the fact that I work with them daily. But the network was the main suspect, and I needed to learn how to debug it.
Fortunately, the Internet loves those who want to learn. The combination of ping and tracert seemed like a good enough start to debug network transport problems.
First, I launched PsPing on Alvin 's TCP port. I used the default settings - nothing special. Of the more than a thousand pings, none exceeded 10 ms, except for the first to warm up. This contradicts the observed increase in the delay of 50 ms in the 99th percentile: there for every 100 queries we should have seen about one query with a delay of 50 ms.
Then I tried the tracert : maybe the problem is on one of the nodes along the route between Alvin and the client. But the tracer returned empty-handed.
Thus, the reason for the delay was not my code, not the implementation of gRPC and not the network. I already began to worry that I would never understand.
Now which OS are we on
gRPC widely used in Linux, but for Windows it is exotic. I decided to conduct an experiment that worked: I created a Linux virtual machine, compiled Alvin for Linux and deployed it.And that's what happened: in the Linux ping-pong server there were no such delays as that of a similar Windows node, although the data source was not different. It turns out the problem is in the implementation of gRPC for Windows.
Nagle's algorithm
All this time, I thought I was missing the
gRPC flag. Now I realized that in fact it is in gRPC that the Windows flag is missing. I found the internal RPC library, in which I was sure that it worked well for all the installed Winsock flags. Then I added all these flags to gRPC and deployed Alvin on Windows, in the corrected ping-pong server under Windows!Almost done: I started to remove the added flags one by one, until the regression returned, so I was able to pinpoint its cause. It was the infamous TCP_NODELAY , the Nagle switch.
Nagle’s algorithm attempts to reduce the number of packets sent over the network by delaying the transmission of messages until the size of the packet exceeds a certain number of bytes. While this may be nice for the average user, it is destructive for real-time servers, because the OS will delay some messages, causing delays at low QPS.
gRPC set this flag in the Linux implementation for TCP sockets, but not for Windows. I fixed it .Conclusion
The big delay on low QPS was caused by optimization of OS. Looking back, the profiling did not detect a delay, because it was done in kernel mode and not in user mode . I don’t know if Nagle’s algorithm can be observed through ETW captures, but that would be interesting.
As for the localhost experiment, it probably didn’t touch the actual network code, and Nagleg’s algorithm didn’t start, so the delay problems disappeared when the client accessed Alvin through localhost.
The next time you see an increase in latency with a decrease in requests per second, Nagle's algorithm should be on your suspect list!
Source: https://habr.com/ru/post/451904/
All Articles