Improving software performance with Intel tools for developer. Numerical modeling of astrophysical objects
We are starting a series of articles about various situations in which the use of Intel tools for developers has significantly increased the speed of the software and its quality.
Our first story took place at Novosibirsk University, where researchers developed a software tool for numerical simulation of magnetohydrodynamic problems in hydrogen ionization. This work was carried out in the framework of the global project of modeling astrophysical objects AstroPhi ; Intel Xeon Phi processors were used as a hardware platform. As a result of using Intel Advisor and Intel Trace Analyzer and Collector , the computing performance increased 3 times, and the speed of solving one task was reduced from a week to two days.
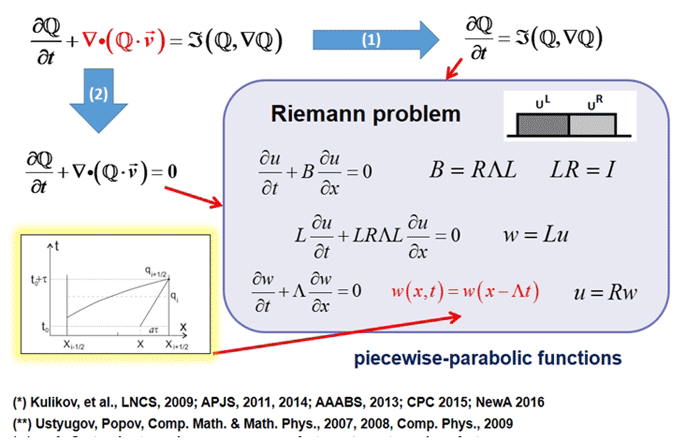
Mathematical modeling plays an important role in modern astrophysics, as in any science; This is a universal tool for the study of nonlinear evolutionary processes in the universe. Modeling complex astrophysical processes in high resolution requires huge computational resources. The AstroPhi NSU project develops astrophysical program code for supercomputers based on Intel Xeon Phi processors. Students learn to write modeling programs for a highly parallelized runtime environment, gaining important knowledge that they will further need when working with other supercomputers.
')
The numerical simulation method used in the project had several important advantages:
The first three factors are key for realistic modeling of significant physical effects in astrophysical problems.
A team of researchers has created a new modeling tool for multi-parallel architectures based on Intel Xeon Phi. Its main task was to avoid bottlenecks in the exchange of data between nodes and simplify the development of the code as much as possible. The parallelization tool uses MPI, and for vectorization, Intel Advanced Vector Extensions 512 (Intel AVX-512) instructions add support for 512-bit SIMD and allow the program to pack 8 double-precision floating-point numbers or 16 single-precision (32-bit) ) in vectors 512 bits long. Thus, twice as many data items are processed per instruction as with AVX / AVX2 and fourfold more than with SSE.
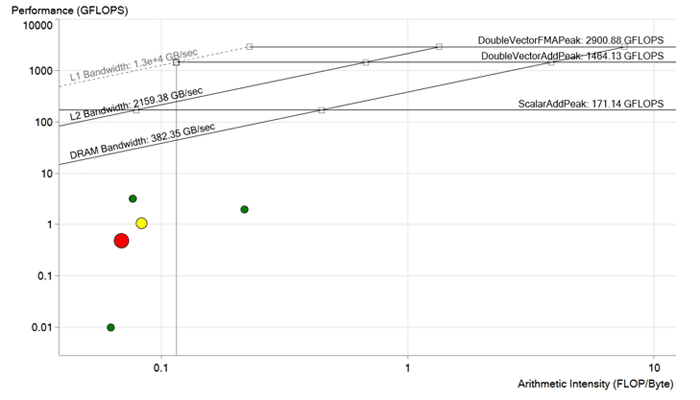
Picture before optimization. Each point is a processing cycle. The bigger and redder the point, the longer the cycle lasts and the more noticeable is the effect of its optimization. The red dot lies well below the DRAM throughput limit and is calculated with a capacity of less than 1 GFLOP. It has a lot of potential for improvement.
Before optimization, the code had certain problems with dependencies and vector sizes. The goal of the optimization was to remove vector dependencies and improve data loading operations into memory using the optimal size of vectors and arrays for Xeon Phi. Intel Advisor and Intel Trace Analyzer and Collector , two tools from Intel Parallel Studio XE, were used for optimization.
Intel Advisor is, as its name implies, Advisor is a software tool that evaluates the degree of optimization — vectorization (using AVX or SIMD instructions) and parallelization to achieve maximum performance. Using this tool, the team was able to do a review of the cycles, highlighting those who work with low productivity, indicating the potential for improvement and determining what could be improved and whether the game was worth the candle. Intel Advisor sorted out cycles by potential, added messages to the source for better readability of the compiler's report. He also provided important information such as the number of repetitions of loops, data dependencies, and memory access patterns for safe and efficient vectoring.
Intel Trace Analyzer and Collector is another tool for optimizing code. It includes profiling MPI communications and analysis functionality to improve weak and strong scaling. This graphical tool helped the team understand the application's MPI behavior, quickly find bottlenecks and, most importantly, increase performance on the Intel architecture.
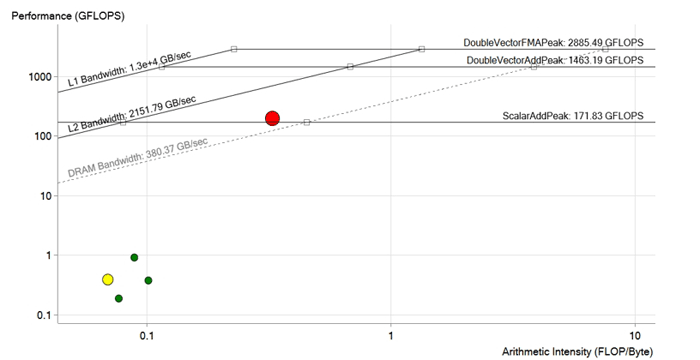
Picture after optimization. During the optimization of the red cycle, the dependencies of the vectorization were removed, load operations into memory were optimized, the sizes of vectors and arrays were adapted for Intel Xeon Phi and AVX-512 instructions. Performance increased to 190 GFLOPS, i.e., about 200 times. Now it is above the DRAM limit and is most likely limited by L2 cache characteristics.
So, after all the improvements and optimizations, the team achieved a performance of 190 GFLOPS with an arithmetic intensity of 0.3 FLOP / b, 100% utilization and a memory bandwidth of 573 GB / s.

Fragment of optimized code
Our first story took place at Novosibirsk University, where researchers developed a software tool for numerical simulation of magnetohydrodynamic problems in hydrogen ionization. This work was carried out in the framework of the global project of modeling astrophysical objects AstroPhi ; Intel Xeon Phi processors were used as a hardware platform. As a result of using Intel Advisor and Intel Trace Analyzer and Collector , the computing performance increased 3 times, and the speed of solving one task was reduced from a week to two days.
Task Description
Mathematical modeling plays an important role in modern astrophysics, as in any science; This is a universal tool for the study of nonlinear evolutionary processes in the universe. Modeling complex astrophysical processes in high resolution requires huge computational resources. The AstroPhi NSU project develops astrophysical program code for supercomputers based on Intel Xeon Phi processors. Students learn to write modeling programs for a highly parallelized runtime environment, gaining important knowledge that they will further need when working with other supercomputers.
')
The numerical simulation method used in the project had several important advantages:
- no artificial viscosity
- Galilean invariance,
- guarantee of non-reduction of entropy,
- simple parallelization
- potentially infinite extensibility.
The first three factors are key for realistic modeling of significant physical effects in astrophysical problems.
A team of researchers has created a new modeling tool for multi-parallel architectures based on Intel Xeon Phi. Its main task was to avoid bottlenecks in the exchange of data between nodes and simplify the development of the code as much as possible. The parallelization tool uses MPI, and for vectorization, Intel Advanced Vector Extensions 512 (Intel AVX-512) instructions add support for 512-bit SIMD and allow the program to pack 8 double-precision floating-point numbers or 16 single-precision (32-bit) ) in vectors 512 bits long. Thus, twice as many data items are processed per instruction as with AVX / AVX2 and fourfold more than with SSE.
Picture before optimization. Each point is a processing cycle. The bigger and redder the point, the longer the cycle lasts and the more noticeable is the effect of its optimization. The red dot lies well below the DRAM throughput limit and is calculated with a capacity of less than 1 GFLOP. It has a lot of potential for improvement.
Code optimization
Before optimization, the code had certain problems with dependencies and vector sizes. The goal of the optimization was to remove vector dependencies and improve data loading operations into memory using the optimal size of vectors and arrays for Xeon Phi. Intel Advisor and Intel Trace Analyzer and Collector , two tools from Intel Parallel Studio XE, were used for optimization.
Intel Advisor is, as its name implies, Advisor is a software tool that evaluates the degree of optimization — vectorization (using AVX or SIMD instructions) and parallelization to achieve maximum performance. Using this tool, the team was able to do a review of the cycles, highlighting those who work with low productivity, indicating the potential for improvement and determining what could be improved and whether the game was worth the candle. Intel Advisor sorted out cycles by potential, added messages to the source for better readability of the compiler's report. He also provided important information such as the number of repetitions of loops, data dependencies, and memory access patterns for safe and efficient vectoring.
Intel Trace Analyzer and Collector is another tool for optimizing code. It includes profiling MPI communications and analysis functionality to improve weak and strong scaling. This graphical tool helped the team understand the application's MPI behavior, quickly find bottlenecks and, most importantly, increase performance on the Intel architecture.
Picture after optimization. During the optimization of the red cycle, the dependencies of the vectorization were removed, load operations into memory were optimized, the sizes of vectors and arrays were adapted for Intel Xeon Phi and AVX-512 instructions. Performance increased to 190 GFLOPS, i.e., about 200 times. Now it is above the DRAM limit and is most likely limited by L2 cache characteristics.
Result
So, after all the improvements and optimizations, the team achieved a performance of 190 GFLOPS with an arithmetic intensity of 0.3 FLOP / b, 100% utilization and a memory bandwidth of 573 GB / s.
Fragment of optimized code
Source: https://habr.com/ru/post/451716/
All Articles