Performance tuning and troubleshooting databases these days
Unfortunately, now the role of specialists in performance tuning and troubleshooting of databases is cut only to the last — troubleshooting'a: almost always, specialists are turned to only when problems have reached a critical point, and they need to be solved “just yesterday”. And even that is good if they address, but do not delay the problem by buying an even more expensive and powerful hardware without a detailed performance audit and load tests. After all, quite often there are disappointments: purchased equipment worth 2-5 times more expensive, and only 30-40% won in performance, the entire increase from which in a few months is eaten either by an increase in the number of users, or by exponential growth of data, coupled with the complication of logic.
And now, at a time when the number of architects, testers and DevOps engineers is actively growing, while Java Core developers are optimizing even work with strings , it is time for database optimizers to come slowly but surely. With each release, DBMS become so smarter and more complicated that the study of both documented and undocumented nuances and optimizations requires a huge amount of time. A huge number of articles are published every month and major Oracle conferences are held. Sorry for the banal analogy, but in this situation, when database administrators become similar to the pilots of airplanes with countless toggle switches, buttons, light bulbs and screens, it is already indecent to load them with the subtleties of performance optimization.
Of course, DBAs, like pilots, in most cases can quite easily solve obvious and simple problems when they are either easily diagnosable or visible in various “tops” (Top events, top SQL, top segments ...). And that is easy to find in MOS or Google, even if they do not know the solution. It is much more difficult when even the symptoms are hidden behind the complexity of the system and need to be extracted among the vast amount of diagnostic information collected by the Oracle DBMS itself.
One of the simplest and most striking examples of this is the analysis of filter and access predictions: in large and loaded systems, it is often the case that such a problem is easily overlooked. the load is fairly evenly spread over different requests (with joins on different tables, with slight differences in conditions, etc.), and the top segments do not show anything special, they say, "well, yes, these tables need data most often and more of them" . In such cases, you can start the analysis with the statistics from SYS.COL_USAGE $: col_usage.sql
')
However, for the full analysis of this information is not enough, because it does not show combinations of predicates. In this case, an analysis of v $ active_session_history and v $ sql_plan can help us:
As can be seen from the query itself, it displays the top 50 search columns and the predicates themselves by the number of times ASH hits in the last 3 hours. Despite the fact that ASH stores only every second snapshots, the sample on the loaded bases is very representative. There are several points to clarify:
Depending on the need, this script can be easily modified to collect additional information in other sections, for example, taking into account sectioning or expectations. And having already analyzed this information together with the analysis of the statistics of the table and its indices, the general data scheme and business logic, you can pass recommendations to developers or architects for choosing a solution, for example: options for denormalizing or changing the partitioning scheme or indexes.
It is also quite often forgotten to analyze SQL * net traffic, and there are also many subtleties, for example: fetch-size, SQLNET.COMPRESSION, extended datatypes, which allow reducing the number of roundtripes, etc., but this is a topic for a separate article.
In conclusion, I would like to say that now that users are becoming less tolerant of delays, performance optimization is becoming a competitive advantage.
And now, at a time when the number of architects, testers and DevOps engineers is actively growing, while Java Core developers are optimizing even work with strings , it is time for database optimizers to come slowly but surely. With each release, DBMS become so smarter and more complicated that the study of both documented and undocumented nuances and optimizations requires a huge amount of time. A huge number of articles are published every month and major Oracle conferences are held. Sorry for the banal analogy, but in this situation, when database administrators become similar to the pilots of airplanes with countless toggle switches, buttons, light bulbs and screens, it is already indecent to load them with the subtleties of performance optimization.
Of course, DBAs, like pilots, in most cases can quite easily solve obvious and simple problems when they are either easily diagnosable or visible in various “tops” (Top events, top SQL, top segments ...). And that is easy to find in MOS or Google, even if they do not know the solution. It is much more difficult when even the symptoms are hidden behind the complexity of the system and need to be extracted among the vast amount of diagnostic information collected by the Oracle DBMS itself.
One of the simplest and most striking examples of this is the analysis of filter and access predictions: in large and loaded systems, it is often the case that such a problem is easily overlooked. the load is fairly evenly spread over different requests (with joins on different tables, with slight differences in conditions, etc.), and the top segments do not show anything special, they say, "well, yes, these tables need data most often and more of them" . In such cases, you can start the analysis with the statistics from SYS.COL_USAGE $: col_usage.sql
')
col owner format a30 col oname format a30 heading "Object name" col cname format a30 heading "Column name" accept owner_mask prompt "Enter owner mask: "; accept tab_name prompt "Enter tab_name mask: "; accept col_name prompt "Enter col_name mask: "; SELECT a.username as owner ,o.name as oname ,c.name as cname ,u.equality_preds as equality_preds ,u.equijoin_preds as equijoin_preds ,u.nonequijoin_preds as nonequijoin_preds ,u.range_preds as range_preds ,u.like_preds as like_preds ,u.null_preds as null_preds ,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when FROM sys.col_usage$ u , sys.obj$ o , sys.col$ c , all_users a WHERE a.user_id = o.owner# AND u.obj# = o.obj# AND u.obj# = c.obj# AND u.intcol# = c.col# AND a.username like upper('&owner_mask') AND o.name like upper('&tab_name') AND c.name like upper('&col_name') ORDER BY a.username, o.name, c.name ; col owner clear; col oname clear; col cname clear; undef tab_name col_name owner_mask; However, for the full analysis of this information is not enough, because it does not show combinations of predicates. In this case, an analysis of v $ active_session_history and v $ sql_plan can help us:
with ash as ( select sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ,count(*) cnt from ( select h.sql_id ,h.SQL_PLAN_HASH_VALUE plan_hash_value ,decode(p.OPERATION ,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME ,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME) ) table_name ,OBJECT_ALIAS ALIAS ,p.ACCESS_PREDICATES ,p.FILTER_PREDICATES -- , : -- ,h.sql_plan_operation -- ,h.sql_plan_options -- ,decode(h.session_state,'ON CPU','ON CPU',h.event) event -- ,h.current_obj# from v$active_session_history h ,v$sql_plan p where h.sql_opname='SELECT' and h.IN_SQL_EXECUTION='Y' and h.sql_plan_operation in ('INDEX','TABLE ACCESS') and p.SQL_ID = h.sql_id and p.CHILD_NUMBER = h.SQL_CHILD_NUMBER and p.ID = h.SQL_PLAN_LINE_ID -- 3 : -- and h.sample_time >= systimestamp - interval '3' hour ) -- : -- where table_name='&OWNER.&TABNAME' group by sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ) ,agg_by_alias as ( select table_name ,regexp_substr(ALIAS,'^[^@]+') ALIAS ,listagg(ACCESS_PREDICATES,' ') within group(order by ACCESS_PREDICATES) ACCESS_PREDICATES ,listagg(FILTER_PREDICATES,' ') within group(order by FILTER_PREDICATES) FILTER_PREDICATES ,sum(cnt) cnt from ash group by sql_id ,plan_hash_value ,table_name ,alias ) ,agg as ( select table_name ,'ALIAS' alias ,replace(access_predicates,'"'||alias||'".','"ALIAS".') access_predicates ,replace(filter_predicates,'"'||alias||'".','"ALIAS".') filter_predicates ,sum(cnt) cnt from agg_by_alias group by table_name ,replace(access_predicates,'"'||alias||'".','"ALIAS".') ,replace(filter_predicates,'"'||alias||'".','"ALIAS".') ) ,cols as ( select table_name ,cols ,access_predicates ,filter_predicates ,sum(cnt)over(partition by table_name,cols) total_by_cols ,cnt from agg ,xmltable( 'string-join(for $c in /ROWSET/ROW/COL order by $c return $c,",")' passing xmltype( cursor( (select distinct nvl( regexp_substr( access_predicates||' '||filter_predicates ,'("'||alias||'"\.|[^.]|^)"([A-Z0-9#_$]+)"([^.]|$)' ,1 ,level ,'i',2 ),' ') col from dual connect by level<=regexp_count( access_predicates||' '||filter_predicates ,'("'||alias||'"\.|[^.]|^)"([A-Z0-9#_$]+)"([^.]|$)' ) ) )) columns cols varchar2(400) path '.' )(+) order by total_by_cols desc, table_name, cnt desc ) select table_name ,cols ,sum(cnt)over(partition by table_name,cols) total_by_cols ,access_predicates ,filter_predicates ,cnt from cols where rownum<=50 order by total_by_cols desc, table_name, cnt desc; As can be seen from the query itself, it displays the top 50 search columns and the predicates themselves by the number of times ASH hits in the last 3 hours. Despite the fact that ASH stores only every second snapshots, the sample on the loaded bases is very representative. There are several points to clarify:
- The cols field displays the search columns themselves, and total_by_cols shows the sum of entries in the context of these columns.
- I think it is quite obvious that this information is in itself an insufficient problem marker, since for example, several one-time fulkans can easily spoil the statistics, so you will have to consider the queries themselves and their frequency (v $ sqlstats, dba_hist_sqlstat)
- Grouping by OBJECT_ALIAS within SQL_ID, plan_hash_value is important for combining index and table predicates by object, since when accessing a table via an index, the predicates will be split into different lines of the plan:
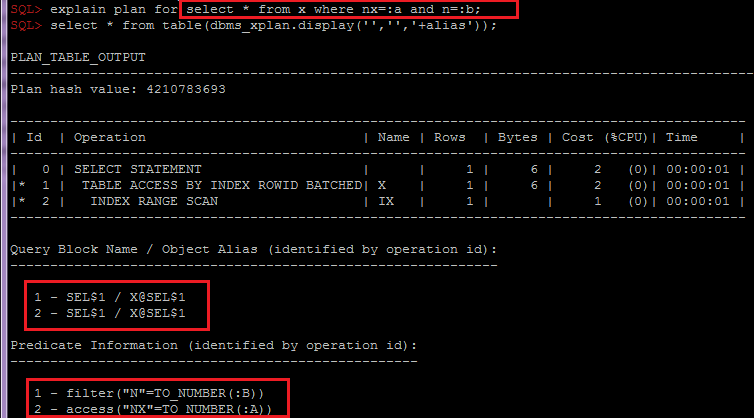
Depending on the need, this script can be easily modified to collect additional information in other sections, for example, taking into account sectioning or expectations. And having already analyzed this information together with the analysis of the statistics of the table and its indices, the general data scheme and business logic, you can pass recommendations to developers or architects for choosing a solution, for example: options for denormalizing or changing the partitioning scheme or indexes.
It is also quite often forgotten to analyze SQL * net traffic, and there are also many subtleties, for example: fetch-size, SQLNET.COMPRESSION, extended datatypes, which allow reducing the number of roundtripes, etc., but this is a topic for a separate article.
In conclusion, I would like to say that now that users are becoming less tolerant of delays, performance optimization is becoming a competitive advantage.
Source: https://habr.com/ru/post/451676/
All Articles