You are not google

Developers are crazy about the strangest things. We all prefer to consider ourselves super-rational creatures, but when it comes to choosing a technology, we fall into a kind of madness, jumping from a comment on HackerNews to a post in some blog, and now as if in oblivion, we are helpless We are sailing towards the brightest light source and dutifully bow before it, completely forgetting about what we were originally looking for.
This is not at all like rational people make decisions. But exactly the way developers decide to use, for example, MapReduce.
As Joe Hellerstein noted in his lecture on databases for bachelor students (in the 54th minute):
The fact is that there are about 5 companies in the world that perform such large-scale tasks. As for everyone else ... they are spending incredible resources to ensure resiliency of the system, which they really do not need. People had a kind of “guglomania” in the 2000s: “we will do everything exactly as Google does, because we also manage the largest data processing service in the world ...” [ironically shakes his head and waits for laughter from the audience]

How many floors are there in your data center building? Google decided to stop at four, at least in this particular data center located in Mays County, Oklahoma.
Yes, your system is more resilient than you need, but think about what it may cost. It's not just the need to process large amounts of data. You are probably exchanging a complete system — with transactions, indices, and query optimization — for something relatively weak. This is a significant step backwards. How many Hadoop users go for it consciously? How many of them make a really balanced decision?
MapReduce / Hadoop is a very simple example. Even the followers of the "cargo cult" have already understood that the planes will not solve all their problems. Nevertheless, the use of MapReduce allows you to make an important generalization: if you use the technology created for a large corporation, but at the same time solve small problems, you may be acting rashly. Even so, it is most likely that you are guided by mystical ideas that by imitating giants like Google and Amazon, you will reach the same vertices.

Yes, this article is another adversary of the "cargo cult". But wait, I have a useful checklist for you, which you can use to make better decisions.
Cool framework: UNPHAT
The next time you google any new cool technique (re) of building your system, I urge you to stop and just use the UNPHAT framework:
- Don't even try to think about possible solutions before understanding (Understand) the problem. Your main goal is to “solve” a problem in terms of a problem, not in terms of solutions.
- List (eNumerate) several possible solutions. No need to immediately point your finger at your favorite option.
- Consider a separate solution, and then read the documentation (Paper) , if available.
- Determine the historical context (Historical context) in which the solution was created.
- Compare the advantages (Advantages) with disadvantages. Analyze what the authors of the decision had to sacrifice in order to achieve their goal.
- Think (Think) ! Think soberly and calmly how well this solution is suited to meet your needs. What exactly needs to change for you to change your mind? For example, how much less data should be in order for you to choose not to use Hadoop?
You are not amazon
Using UNPHAT is easy. Recall my recent conversation with a company that hastily decided to use Cassandra for the process of intensively reading data loaded at night.
Since I was already familiar with the documentation for Dynamo and knew that Cassandra is a derivative system, I understood that in these databases the main focus was on the ability to write (in Amazon there was a need to make the “add to cart” action never did not fail). I also appreciated that the developers sacrificed data integrity - and, in fact, every feature inherent in a traditional RDBMS. But after all, the company with which I spoke, the ability to record was not a priority. To be honest, the project meant creating one big record per day.

Amazon sells a lot of things. If the function "add to cart" suddenly stopped working, they would have lost a LOT of money. Do you have a problem of the same order?
This company decided to use Cassandra, because the PostgreSQL query in question took a few minutes, and they decided that these were technical limitations from their hardware. After clearing a couple of moments, we realized that the table consisted of approximately 50 million lines of 80 bytes each. Her reading from the SSD would have taken about 5 seconds if she had to walk through it completely. It is slow, but it is still two orders of magnitude faster than the speed at which the request was executed.
At this stage, I had many questions (U = understand, understand the problem!) And I began to weigh about 5 different strategies that could solve the initial problem (N = eNumerate, list several possible solutions!), But in any case it was already quite clear to the point that using Cassandra was a completely wrong decision. All they needed was a little patience to set up, probably a new design for the database, and perhaps (although unlikely), the choice of a different technology ... But definitely not a data storage in a “key-value” format with the ability to write intensively Amazon created for their shopping cart!
You are not LinkedIn
I was quite surprised to find that one student startup decided to build his architecture around Kafka. It was amazing. As far as I could tell, their business conducted only a few dozen very large operations per day. Perhaps a few hundred on the most successful days. With such bandwidth, the main data repository could be handwritten notes in an ordinary book.
For comparison, recall that Kafka was created to handle all analytical events on LinkedIn. This is just a huge amount of data. Even a couple of years ago, it was about 1 trillion events a day , with a peak load of 10 million messages per second. Of course, I understand that Kafka can be used to work with lower loads, but that it is 10 orders less than that?

The sun, being a very massive object, is only 6 orders of magnitude heavier than the Earth.
Maybe the developers even made a deliberate decision based on the expected needs and a good understanding of the purpose of Kafka. But I think that they rather fed on (as a rule, justified) community enthusiasm for Kafka and hardly ever wondered if this was really the tool they needed. Just imagine ... 10 orders of magnitude!
I have already mentioned? You are not amazon
Even more popular than Amazon’s distributed data warehouse is an architectural approach to development that provided them with scalability: a service-oriented architecture. As Werner Vogels noted in this 2006 interview he gave to Jim Gray, in 2001, Amazon realized that they had difficulty scaling the interface (front-end parts) and that a service-oriented architecture could help them. This idea infected one developer after another while start-ups consisting of only a couple of developers and practically having no clients, did not begin to split up their software into nanos-services.
By the time Amazon decided to switch to SOA (Service-oriented architecture), they had about 7,800 employees, and their sales volumes exceeded $ 3 billion .

San Francisco’s Bill Graham Auditorium can seat 7,000 people. Amazon had about 7,800 employees when they switched to SOA.
This does not mean that you should postpone the transition to SOA until your company reaches 7,800 employees ... just always think with your head . Is this really the best solution for your task? What kind of task is you facing and are there any other ways to solve it?
If you tell me that the work of your organization, consisting of 50 developers, will simply rise without SOA, then I’m wondering why so many large companies function just fine using a single, but well-organized application.
Even Google is not Google
Examples of using systems for processing high-loaded data streams (Hadoop or Spark) can really cause confusion. Very often, traditional DBMSs are better suited for the available load, and sometimes the data volumes are so small that even the available memory would suffice for them. Did you know that you can buy 1TB of RAM somewhere for $ 10,000? Even if you had a billion users, you would still be able to provide each of them with 1 KB of RAM.
Perhaps this will not be enough for your load, because you will need to produce reading and writing to disk. But do you really need several thousand disks to read and write? Here's how much data you have in fact? GFS and MapReduce were created to solve computing problems across the entire Internet ... for example, to recalculate the search index throughout the Internet .
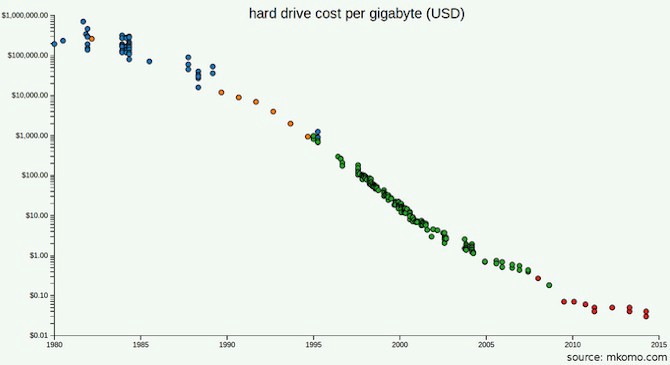
Hard disk prices are now much lower than in 2003, when GFS documentation was published.
Maybe you read the GFS and MapReduce documentation and noticed that one of the problems for Google was not data volumes but bandwidth (processing speed): they used distributed storage because it took too long to transfer bytes from the disks. But what will be the bandwidth of the devices that you will use this year? Considering that you don’t even need to get as many devices as Google needed, maybe it’s better to just buy more modern drives? How much does it cost to use SSD?
Maybe you want to consider the possibility of scaling in advance. Have you done all the necessary calculations? Will you accumulate data faster than SSD prices will go down? How many times will your business need to grow so that all available data no longer fits on one device? As of 2016, Stack Exchange processed 200 million queries per day with support for only 4 SQL servers : the main one for Stack Overflow, one more for everything else, and two copies.
Again, you can resort to UNPHAT and still decide to use Hadoop or Spark. And the decision may even be true. The main thing is that you really use the appropriate technology to solve your problem . By the way, Google is well aware: when they decided that MapReduce is not suitable for indexing, they stopped using it.
First things first, understand the problem
My message may not be something new, but perhaps in this form it will respond to you or maybe it will be easy for you to remember UNPHAT and apply it in life. If not, you can watch Rich Hickey's speech on Hammock Driven Development , or Paul ’s How to Solve it , or Hamming ’s The Art of Doing Science and Engineering . Because the main thing that we all ask is to think!
And really understand the problem you are trying to solve. In the inspirational words of Paul:
“ It is foolish to answer a question that you do not understand. It’s sad to aim for a goal that you don’t want to achieve. ”
Translation into Russian
Translation: Alexander Tregubov
Edited by: Alexey Ivanov (@ponchiknews)
Community: @ponchiknews
Illustration: LucidChart Content Team
')
Source: https://habr.com/ru/post/450230/
All Articles