Operating Systems: Three Easy Pieces. Part 5: Planning: Multi-Level Feedback Queue (translation)
Introduction to operating systems
Hi, Habr! I want to bring to your attention a series of articles-translations of one interesting in my opinion literature - OSTEP. This material takes a rather in-depth look at the work of unix-like operating systems, namely, working with processes, various schedulers, memory, and other similar components that make up a modern OS. The original of all materials you can see here . Please note that the translation was made unprofessionally (fairly freely), but I hope I saved the general meaning.
Laboratory work on this subject can be found here:
Other parts:
')
- Part 1: Intro
- Part 2: Abstraction: the process
- Part 3: Introduction to the Process API
- Part 4: Scheduler Introduction
- Part 5: MLFQ Scheduler
And you can also look to me on the channel in the telegram =)
Planning: Multi-Level Feedback Queue
In this lecture we will talk about the problems of developing one of the most famous approaches to
Planning, which is called Multi-Level Feedback Queue (MLFQ). The MLFQ planner was first described in 1962 by Fernando J. Corbató in a system called the Compatible Time-Sharing System (CTSS). These works (including later works on Multics) were subsequently presented to the Turing Award. The planner was subsequently improved and acquired the look that can be found already in some modern systems.
The MLFQ algorithm tries to solve 2 fundamental overlapping problems.
Firstly , it tries to optimize the turnaround time, which, as we considered in the previous lecture, is optimized by launching the shortest tasks at the beginning of the queue. However, the OS does not know how long this or that process will work, and this is the necessary knowledge for the operation of the SJF and STCF algorithms. Secondly , MLFQ tries to make the system responsive to users (for example, for those who sit and stare at the screen while waiting for the task to complete) and thus minimize the response time. Unfortunately, algorithms like RR reduce the response time, but extremely badly affect the turnover time metric. Hence our problem: How to design a planner who will meet our requirements and at the same time be unaware of the nature of the process, in general? How can the planner explore the characteristics of the tasks he runs and thus make better planning decisions?
The crux of the problem: How to plan a task without perfect knowledge? How to develop a scheduler that simultaneously minimizes response time for interactive tasks and at the same time minimizes turnover time without knowing the time of task execution?
Note: we are learning from previous events
The MLFQ lineup is an excellent example of a system that learns from past events to predict the future. Similar approaches are often found in the OS (and many other branches in computer science, including hardware prediction branches and caching algorithms). Such trips work when tasks have behavioral phases and are thus predictable.
However, with such a technique one should be careful, because predictions can very easily turn out to be wrong and lead the system to making worse decisions than there would be without knowledge at all.
MLFQ: Basic Rules
Consider the basic rules of the MLFQ algorithm. And although there are several implementations of this algorithm, the basic approaches are similar.
In the implementation that we will consider, there will be several separate queues in MLFQ, each of which will have a different priority. At any time, the task ready for execution is in the same queue. MLFQ uses priorities to decide which task to run for execution, i.e. the task with a higher priority (the task from the queue with the highest priority) will be launched first.
Undoubtedly, there can be more than one task in a particular queue, so they will have the same priority. In this case, the RR mechanism will be used to schedule the launch among these tasks.
Thus, we arrive at two basic rules for MLFQ:
- Rule1: If priority (A)> Priority (B), task A will be launched (B will not)
- Rule2: If Priority (A) = Priority (B), A & B are started using RR
Based on the above, the key elements to planning MLFQ are priorities. Instead of assigning a fixed priority to each task, MLFQ changes its priority depending on the observed behavior.
For example, if a task constantly quits working on the CPU while waiting for keyboard input, MLFQ will maintain the process priority at a high level, because this is how the interactive process should work. If, on the contrary, the task is constantly and intensively using the CPU for a long period, MLFQ will lower its priority. Thus, MLFQ will study the behavior of the processes at the time of their work and use the behavior.
Let's draw an example of how the queues might look at some point in time and then you get something like this:

In this diagram, 2 processes A and B are in the queue with the highest priority. Process C is somewhere in the middle, and process D is at the very end of the queue. According to the MLFQ algorithm descriptions above, the scheduler will only perform tasks with the highest priority according to RR, and tasks C, D will be out of business.
Naturally static snapshot will not give a complete picture of how MLFQ works.
It is important to understand exactly how the picture changes over time.
Attempt 1: How to change priority
At this point, it is necessary to decide how MLFQ will change the priority level of the task (and thus the position of the task in the queue) in the course of its life cycle. To do this, you need to keep in mind the workflow: a number of interactive tasks with a short working time (and thus frequent CPU release) and several long tasks that use the CPU all their working time, and the response time for such tasks is not important. And so you can make the first attempt to implement the MLFQ algorithm with the following rules:
- Rule3: When a task enters the system, it is placed in a queue with the highest
- priority.
- Rule4a: If a task uses the entire time window assigned to it, then its
- priority drops.
- Rule4b: If the Task frees the CPU before the expiration of its time window, then it
- stays with the same priority.
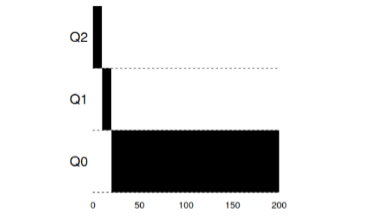
Example 1: Single long-term task
As you can see in this example, the task for admission is set with the highest priority. After a time window of 10ms, the process decreases in priority by the scheduler. After the next time window, the task finally goes down to the lowest priority in the system, where it remains.
Example 2: They brought a short task
Now let's see an example of how MLFQ tries to get close to SJF. In this example, there are two tasks: A, which is a long-playing task that constantly occupies the CPU and B, which is a short interactive task. Suppose that A has been working for some time at the time when task B arrived.
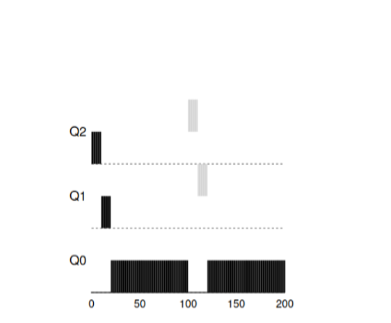
This graph shows the results of the script. Task A, like any task using a CPU, is at the bottom. Task B will arrive at time T = 100 and will be placed in the queue with the highest priority. Since the time of her work is small, it will end before it reaches the last stage.
From this example, one should understand the main goal of the algorithm: since the algorithm does not know a long task or a short one, first of all it assumes that the task is short and gives it the highest priority. If this is a really short task, then it will be completed quickly, otherwise if it is a long task, then it will slowly move in priority down and will soon prove that it is a really long task that does not require a response.
Example 3: What about input and output?
Now let's take a look at an example with I / O. As stated in rule 4b, if a process frees a processor without fully using its processor time, it remains at the same priority level. The intentions of this rule are quite simple - if an interactive task performs many I / O operations, for example, expecting a user to press a key or mouse, such a task will release the processor before the allotted window. We would not like to omit such a task by priority, and thus it will remain at the same level.

This example shows how the algorithm will work with such processes — Interactive Task B, which only needs a CPU for 1ms before executing the I / O process and Long Task A, which the CPU uses all its time.
MLFQ keeps process B with the highest priority as it continues all the time
release the CPU. If B is an interactive task, then the algorithm in this case achieved its goal of launching interactive tasks quickly.
Problems with the current MLFQ algorithm
In the previous examples, we built the basic version of MLFQ. And it seems that he does his job well and honestly, distributing processor time honestly between long tasks and allowing short tasks or tasks intensively addressing input and output to work quickly. Unfortunately, this approach contains several serious problems.
First , the hunger problem: if the system has a lot of interactive tasks, they will consume all the CPU time and thus no long task will be able to perform (they starve).
Secondly , smart users could write their programs so that
cheat the planner. Cheating is to do something to make
scheduler to issue process more CPU time. Algorithm which
described above is quite vulnerable to such attacks: before the time window is almost
ran out need to perform an I / O operation (to some, no matter what file)
and thus free up the CPU. Such behavior will allow you to remain in the same
queue itself and again get a larger percentage of CPU time. If done
this is correct (for example, running 99% of the window time before releasing the CPU),
such a task can simply monopolize the processor.
Finally, a program can change its behavior over time. Those tasks
who used the CPU, can become interactive. In our example, similar
tasks will not receive proper treatment from the scheduler, as others would receive
(initial) interactive tasks.
Question to the audience: what attacks on the scheduler could have been made in the modern world?
Attempt 2: Raising Priority
Let's try to change the rules and see if we can avoid problems with
fasting What could we do to ensure that related
CPU tasks will get their time (even if not for long).
As a simple solution, you can suggest periodically
increase the priority of all such tasks in the system. There are many ways
to achieve this, let's try to put something simple as an example: translate
Immediately all tasks in the highest priority, hence the new rule:
- Rule5 : After a certain period S, transfer all tasks in the system to the highest queue.
Our new rule solves two problems at once. First, the processes
guaranteed not to starve: tasks in the highest queue will share
CPU time according to the RR algorithm and so all processes will get
CPU time Secondly, if some process that previously used
only the processor becomes interactive, then it will remain in line with the highest
priority after once receiving a priority increase to the highest.
Consider an example. In this scenario, we consider one process using

CPU and two interactive, short processes. On the left in the figure, the figure shows behavior without increasing priority, and thus the long task begins to starve after arriving at the system of two interactive tasks. In the figure on the right, every 50ms priority increase is performed and thus all processes are guaranteed to get CPU time and will be periodically started. 50ms in this case is taken as an example, actually this number is somewhat higher.
Obviously, adding the time of a periodic increase in S leads to
natural question: what value should be set? One of the honored
system engineers John Ousterhout called similar values in systems like voo-doo
constant as they in some way demanded black magic for the correct
exhibiting. And unfortunately S has that kind of flavor. If you set the value too
big - long tasks will starve. And if you set the value too low,
interactive tasks will not get the proper CPU time.
Attempt 3: Better Accounting
Now we have another problem that needs to be solved: how not
let our planner fool? The blame for this opportunity is
rules 4a, 4b, which allow the task to maintain priority, freeing the processor
before the expiration of the allotted time. How to cope with it?
The solution in this case can be considered the best accounting of CPU time on each
MLFQ level. Instead of forgetting the time the program used
processor for the allotted period, should be considered and save it. After
the process has spent its allotted time should lower it to the next
priority level. Now it doesn't matter how the process will use its time - how
constantly computing on the processor or as a multitude of calls. In this way,
Rule 4 should be rewritten as follows:
- Rule4 : After a task has spent its allotted time in the current queue (no matter how many times it has released the CPU), the priority of such a task decreases (it moves down the queue).
Let's look at an example:
 "
"The figure shows what happens if you try to trick the scheduler as
if it were with the previous rules 4a, 4b, the result will be left. With new
the rule is the result on the right. Prior to protection, any process could cause I / O to complete and
thus dominate the CPU, after enabling protection, regardless of the behavior
I / O, it will still go down in the queue anyway and thus can not unfairly
take possession of CPU resources.
Improving MLFQ and other problems
With the above improvements, new problems arise: one of the main
questions - how to parameterize a similar scheduler? Those. How much should be
queues? What should be the window size of the program within the queue? how
program priority should often be increased in order to avoid starvation and
take into account the change in the behavior of the program? To these questions, there is no simple
response and only experiments with loads and subsequent configuration
a planner can lead to some kind of satisfactory balance.
For example, most MLFQ implementations allow you to assign different
time intervals to different queues. High priority queues usually
assigned short intervals. These queues consist of interactive tasks,
switching between them is quite sensitive and should take 10 or less
ms In contrast, low-priority queues consist of long tasks that use
CPU. And in this case, long time intervals fit very well (100ms).
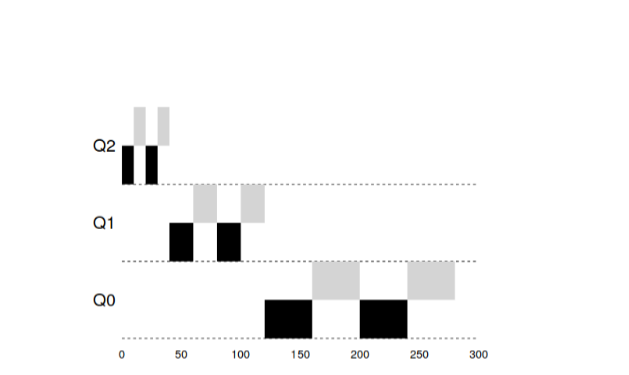
In this example, there are 2 tasks that have worked in the high-priority queue 20
ms, broken into windows for 10ms. 40ms in the middle queue (window in 20ms) and in the low-priority
The queue time window has become 40ms, where the tasks have completed their work.
Implementing MLFQ in the Solaris OS is a class of time-sharing planners.
The scheduler provides a set of tables that define exactly how it should
change the priority of the process over the course of its life, what should be the size
allocated window and how often you need to raise the priorities of the task. Administrator
systems can interact with this table and force the scheduler to behave
differently. The default for this table is 60 queues with a gradual increase
window size from 20ms (high priority) to several hundred ms (lowest priority), and
also with a boost of all tasks once a second.
Other MLFQ planners do not use a table or any specific
the rules that are described in this lecture, on the contrary, they calculate priorities using
mathematical formulas. For example, the scheduler in FreeBSD uses the formula to
calculating the current priority of the task, based on how much process
used the CPU. In addition, CPU utilization decays over time, and so
This way, the priority is raised somewhat differently than described above. This is true
called decay algorithms. Since version 7.1, FreeBSD uses the ULE scheduler.
Finally, many planners have other features. For example, some
planners reserve higher levels for the operating system and such
Thus, no user process will be able to get the highest priority in
the system. Some systems allow you to give advice to help.
Scheduler correctly set priorities. So for example, using the nice command
You can increase or decrease the priority of the task and thus increase or decrease
reduce the chances of the program for processor time.
MLFQ: Results
We have described a planning approach called MLFQ. His name
concluded in the principle of operation - it has several queues and uses feedback
to prioritize the task.
The final rules will be as follows:
- Rule1 : If priority (A)> Priority (B), task A will be launched (B will not)
- Rule2 : If Priority (A) = Priority (B), A & B are started using RR
- Rule3 : When a task enters the system, it is placed in the queue with the highest priority.
- Rule4 : After a task has spent its allotted time in the current queue (no matter how many times it has released the CPU), the priority of such a task decreases (it moves down the queue).
- Rule5 : After a certain period S, transfer all tasks in the system to the highest queue.
MLFQ is interesting for the following reason - instead of requiring knowledge of
the nature of the problem in advance; the algorithm studies the past behavior of the task and exposes
priorities are appropriate. Thus, he tries to sit at once on two chairs - to achieve performance for small tasks (SJF, STCF) and honestly run long,
CPU-loading jobs. Therefore, many systems, including BSD and their derivatives,
Solaris, Windows, Mac use some form of algorithm as a scheduler.
MLFQ as a base.
Additional materials:
Source: https://habr.com/ru/post/450116/
All Articles