Building a service-oriented architecture on Rails + Kafka
Hi, Habr! I present to you the post, which is a text adaptation of the performance of Stella Cotton on RailsConf 2018 and the translation of the article “Building a Service-oriented Architecture with Rails and Kafka” by Stella Cotton.
Recently, the transition of projects from monolithic architecture in favor of microservices is clearly visible. In this guide, we will learn the basics of Kafka and how an event-oriented approach can improve your Rails application. We will also talk about the problems of monitoring and the scalability of services that work through an event-oriented approach.
I am sure that you would like to have information about how your users came to your platform or which pages they visit, which buttons click, etc. A truly popular application can generate billions of events and send a huge amount of data to analytics services, which can be a serious challenge for your application.
As a rule, an integral part of web applications requires the so-called real-time data flow . Kafka provides a fail-safe link between producers , those who generate events, and consumers , those who receive these events. There may even be several producers and consumers in one application. In Kafka, every event exists for a given time, so several consumers can read the same event over and over. The Kafka Cluster includes several brokers who are Kafka instances.
')
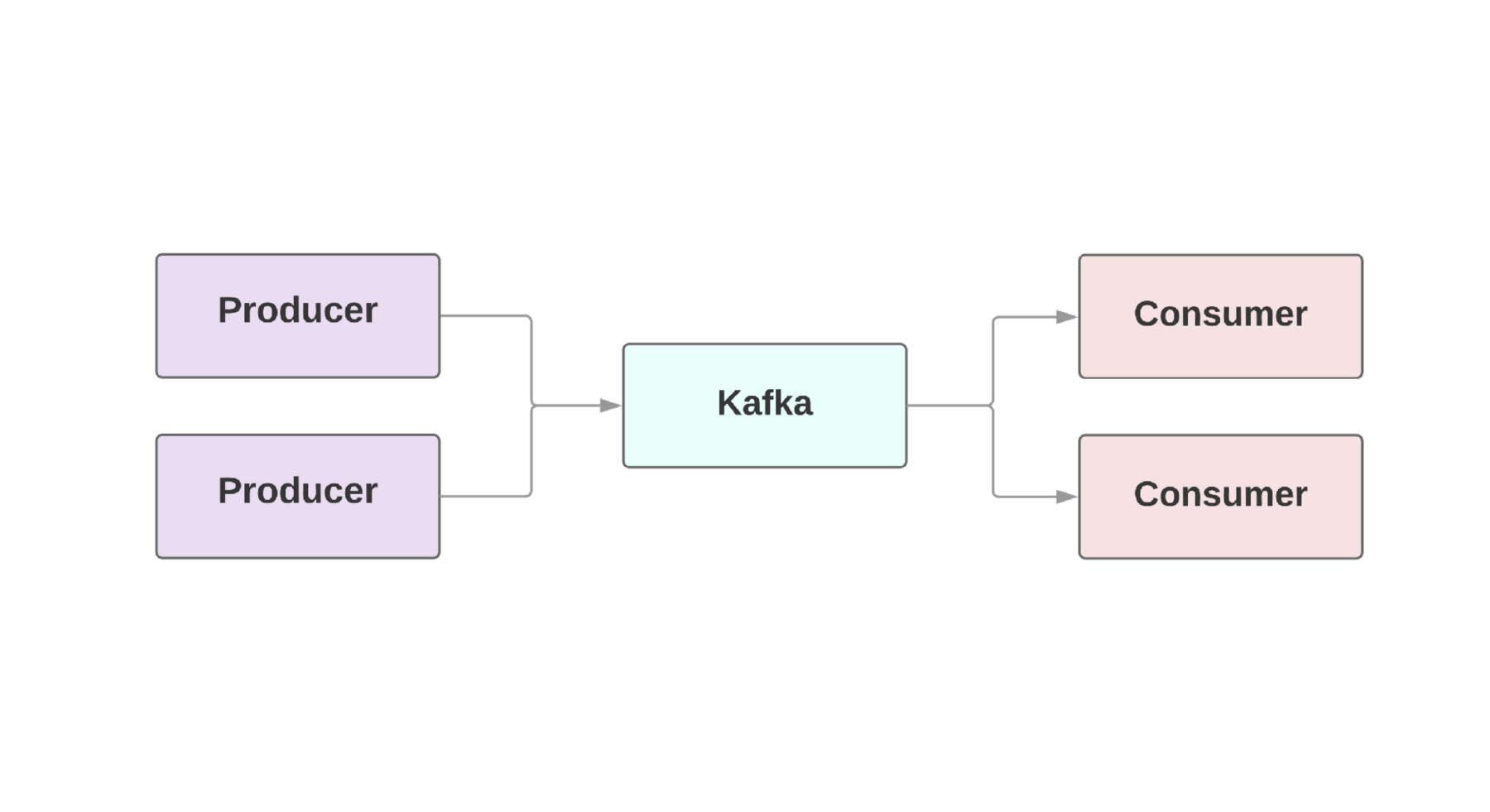
A key feature of Kafka is high speed event processing. Traditional queuing systems, such as AMQP, have an infrastructure that monitors the processed events for each consumer. When the number of consumers grows to a decent level, the system hardly begins to cope with the load, because it has to monitor an increasing number of conditions. Also, there are big problems with consistency between the consumer and the event processing system. For example, is it worth immediately marking a message as sent as soon as it is processed by the system? And if the consumer at the other end falls without receiving a message?
Kafka also has a fault tolerant architecture. The system runs as a cluster on one or more servers, which can be horizontally scaled by adding new machines. All data is written to disk and copied to several brokers. In order to understand the possibilities of scalability, it is worth looking at such companies as Netflix, LinkedIn, Microsoft. All of them send trillions of messages per day through their Kafka clusters!
Heroku provides a Kafka cluster add-on that can be used for any environment. For ruby applications, we recommend using ruby-kafka gem . The minimal implementation looks like this:
After configuring the config, you can use the heme to send messages. Thanks to the asynchronous sending of events, we can send messages from anywhere:
We'll talk about the serialization formats below, but for now we use the good old JSON. The
Some of the features that make Kafka a useful tool also make it a fail-safe replacement of RPC between services. Take a look at an example of e-commerce applications:
When a user
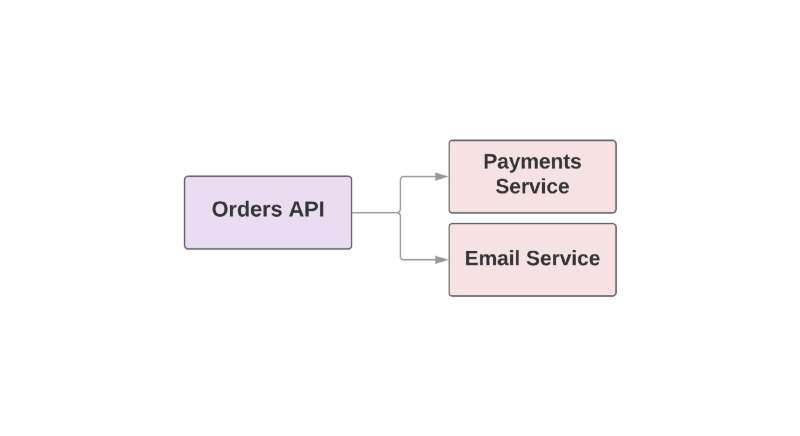
One of the problems with this approach is that the service superior in the hierarchy is responsible for monitoring the availability of the downstream service. If the service for sending letters turned out to be not the best day, the higher service needs to know about it. And if the sending service is not available, then you need to repeat a certain set of actions. How can Kafka help in this situation?
For example:
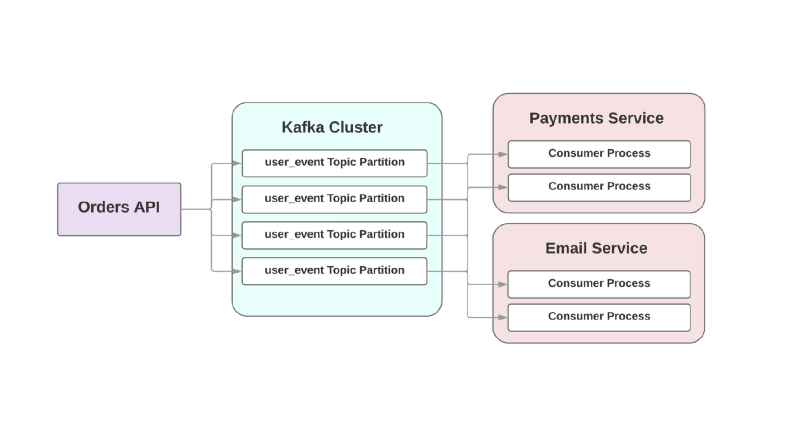
In this event-oriented approach, a superior service can record an event in Kafka that an order has been created. Due to the so-called at least once approach, the event will be recorded in Kafka at least once and will be available to downstream consumer to read. If the service of sending letters lies, the event will wait on the disk until the consumer rises and reads it.
Another problem with an RPC-oriented architecture is in fast-growing systems: the addition of a new downstream service entails a change in the superior one. For example, you would like to add one more step after creating an order. In an event-oriented world, you will need to add another consumer to handle a new type of event.

In a post titled “ What do you mean by“ Event-Driven ”by Martin Fowler discusses the confusion around event-oriented applications. When developers discuss similar systems, they actually talk about a huge number of different applications. In order to give a general understanding of the nature of such systems, Fowler identified several architectural patterns.
Let's take a look at what these patterns are. If you want to know more, I advise you to read his report at GOTO Chicago 2017.
The first Fowler pattern is called Event Notification . In this scenario, the producer service notifies consumers of an event that has occurred using a minimum amount of information:
If consumers need more information about the event, they query producer and get more data.
The second pattern is called Event-Carried State Transfer . In this scenario, the producer provides additional information about the event and the consumer can store a copy of this data without making additional calls:
The third template Fowler called Event-Sourced and it is rather architectural. Template implementation involves not just communication between your services, but also saving the presentation of the event. This ensures that even if you lose the database, you can still restore the state of the application by simply running the saved stream of events. In other words, each event saves a certain state of the application at a certain point.
The big problem with this approach is that the application code always changes, and with it the format or amount of data that the producer gives out can change. This makes the recovery of the application state problematic.
And the last pattern is Command Query Responsibility Segregation , or CQRS. The idea is that the actions you apply to an object, for example: create, read, update, should be divided into different domains. This means that one service should be responsible for the creation, another for updating, etc. In object-oriented systems, everything is often stored in the same service.
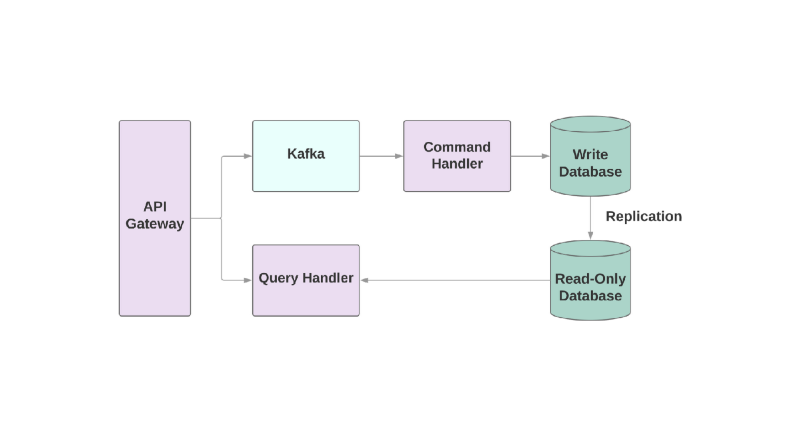
A service that writes to the database will read the event stream and process commands. But any requests occur only in the read-only database. Dividing the logic of reading and writing into two different services increases the complexity, but allows you to optimize performance separately for these systems.
Let's talk about some of the problems you may encounter when integrating Kafka into your service-oriented application.
The first problem may be slow consumer. In an event-oriented system, your services should be able to handle events instantly when they are received from a superior service. Otherwise they will just hang without any alerts about the problem or timeouts. The only place where timeouts can be defined is a socket connection with Kafka brokers. If the service does not process the event quickly enough, the connection may be interrupted by timeout, but restoring the service requires additional time because the creation of such sockets is expensive.
If the consumer is slow, how can you increase the speed of event handling? In Kafka, you can increase the number of consumers in a group, so more events can be processed in parallel. But it will take at least 2 consumer per service: in the event that one drops, the damaged sections can be reassigned.
It is also very important to have metrics and alerts to monitor the speed of event processing. ruby-kafka can work with ActiveSupport alerts, it also has StatsD and Datadog modules, which are enabled by default. In addition, hem provides a list of recommended metrics for monitoring.
Another important aspect of building systems with Kafka is designing consumers with the ability to handle failures. Kafka is guaranteed to send the event at least once; excluded the case when the message did not go at all. But it is important that consumers are prepared to handle recurring events. One way to do this is to always use
One of the surprises when working with Kafka can be its simple attitude to the data format. You can send anything in bytes and the data will be sent to the consumer without any verification. On the one hand, it gives flexibility and allows you to not care about the format of the data. On the other hand, if the producer decides to change the sent data, there is a chance that some consumer will eventually break down.
Before building an event-oriented architecture, select a data format and analyze how it will help to further register and develop patterns.
One of the formats recommended for use is, of course, JSON. This format is human-readable and supported by all known programming languages. But there are pitfalls. For example, the size of the final data in JSON can become frighteningly large. The format requires storing key-value pairs, which is quite flexible, but the data are duplicated in each event. Changing the schema is also a difficult task, since there is no built-in support for overlaying one key onto another if you need to rename the field.
The team that created Kafka recommends using Avro as a serialization system. Data is sent in binary form, and this is not the most human-readable format, but inside there is more reliable support for the schemes. The target object in Avro includes both schema and data. Avro also supports simple types, such as numbers, as well as complex ones: dates, arrays, etc. In addition, it allows you to include documentation inside the scheme, which allows you to understand the purpose of a specific field in the system and contains many other built-in tools for working with the scheme.
avro-builder is a gem created by Salsify, which offers ruby-like DSL for creating schemes. In more detail about Avro it is possible to read in this article .
If you are interested in how to host Kafka or how it is used in Heroku, there are several reports that may be of interest to you.
Jeff Chao's at the DataEngConf SF '17 conference “ Beyond 50,000 Partitions: How to Operate the Pill on the Limits of Kafka at Scale ”
Pavel Pravosud at Dreamforce '16 Conference “ Dogfooding Kafka: How We Built Heroku's Real-Time Platform Event Stream ”
Enjoy watching!
Recently, the transition of projects from monolithic architecture in favor of microservices is clearly visible. In this guide, we will learn the basics of Kafka and how an event-oriented approach can improve your Rails application. We will also talk about the problems of monitoring and the scalability of services that work through an event-oriented approach.
What is Kafka?
I am sure that you would like to have information about how your users came to your platform or which pages they visit, which buttons click, etc. A truly popular application can generate billions of events and send a huge amount of data to analytics services, which can be a serious challenge for your application.
As a rule, an integral part of web applications requires the so-called real-time data flow . Kafka provides a fail-safe link between producers , those who generate events, and consumers , those who receive these events. There may even be several producers and consumers in one application. In Kafka, every event exists for a given time, so several consumers can read the same event over and over. The Kafka Cluster includes several brokers who are Kafka instances.
')
A key feature of Kafka is high speed event processing. Traditional queuing systems, such as AMQP, have an infrastructure that monitors the processed events for each consumer. When the number of consumers grows to a decent level, the system hardly begins to cope with the load, because it has to monitor an increasing number of conditions. Also, there are big problems with consistency between the consumer and the event processing system. For example, is it worth immediately marking a message as sent as soon as it is processed by the system? And if the consumer at the other end falls without receiving a message?
Kafka also has a fault tolerant architecture. The system runs as a cluster on one or more servers, which can be horizontally scaled by adding new machines. All data is written to disk and copied to several brokers. In order to understand the possibilities of scalability, it is worth looking at such companies as Netflix, LinkedIn, Microsoft. All of them send trillions of messages per day through their Kafka clusters!
Configuring Kafka in Rails
Heroku provides a Kafka cluster add-on that can be used for any environment. For ruby applications, we recommend using ruby-kafka gem . The minimal implementation looks like this:
# config/initializers/kafka_producer.rb require "kafka" # Configure the Kafka client with the broker hosts and the Rails # logger. $kafka = Kafka.new(["kafka1:9092", "kafka2:9092"], logger: Rails.logger) # Set up an asynchronous producer that delivers its buffered messages # every ten seconds: $kafka_producer = $kafka.async_producer( delivery_interval: 10, ) # Make sure to shut down the producer when exiting. at_exit { $kafka_producer.shutdown } After configuring the config, you can use the heme to send messages. Thanks to the asynchronous sending of events, we can send messages from anywhere:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end We'll talk about the serialization formats below, but for now we use the good old JSON. The
topic argument refers to the log in which Kafka will record this event. Topics are spread over different sections that allow you to separate the data of a specific topic across different brokers for better scalability and reliability. And it is really a good idea to have two or more sections for each topic, because if one of the sections drops, your events will still be recorded and processed. Kafka guarantees that events are delivered in the order of a queue within a section, but not within the whole topic. If the order of events is important, then sending partition_key ensures that all events of a particular type will be saved on one section.Kafka for your services
Some of the features that make Kafka a useful tool also make it a fail-safe replacement of RPC between services. Take a look at an example of e-commerce applications:
def create_order create_order_record charge_credit_card # call to Payments Service send_confirmation_email # call to Email Service end When a user
create_order an order, the create_order function is create_order . This creates an order in the system, debits money from the card and sends an email with confirmation. As you can see, the last two steps are rendered into separate services.One of the problems with this approach is that the service superior in the hierarchy is responsible for monitoring the availability of the downstream service. If the service for sending letters turned out to be not the best day, the higher service needs to know about it. And if the sending service is not available, then you need to repeat a certain set of actions. How can Kafka help in this situation?
For example:
In this event-oriented approach, a superior service can record an event in Kafka that an order has been created. Due to the so-called at least once approach, the event will be recorded in Kafka at least once and will be available to downstream consumer to read. If the service of sending letters lies, the event will wait on the disk until the consumer rises and reads it.
Another problem with an RPC-oriented architecture is in fast-growing systems: the addition of a new downstream service entails a change in the superior one. For example, you would like to add one more step after creating an order. In an event-oriented world, you will need to add another consumer to handle a new type of event.
Inclusion of events in service-oriented architecture
In a post titled “ What do you mean by“ Event-Driven ”by Martin Fowler discusses the confusion around event-oriented applications. When developers discuss similar systems, they actually talk about a huge number of different applications. In order to give a general understanding of the nature of such systems, Fowler identified several architectural patterns.
Let's take a look at what these patterns are. If you want to know more, I advise you to read his report at GOTO Chicago 2017.
Event notification
The first Fowler pattern is called Event Notification . In this scenario, the producer service notifies consumers of an event that has occurred using a minimum amount of information:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" } If consumers need more information about the event, they query producer and get more data.
Event-Carried State Transfer
The second pattern is called Event-Carried State Transfer . In this scenario, the producer provides additional information about the event and the consumer can store a copy of this data without making additional calls:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" } Event-sourced
The third template Fowler called Event-Sourced and it is rather architectural. Template implementation involves not just communication between your services, but also saving the presentation of the event. This ensures that even if you lose the database, you can still restore the state of the application by simply running the saved stream of events. In other words, each event saves a certain state of the application at a certain point.
The big problem with this approach is that the application code always changes, and with it the format or amount of data that the producer gives out can change. This makes the recovery of the application state problematic.
Command Query Responsibility Segregation
And the last pattern is Command Query Responsibility Segregation , or CQRS. The idea is that the actions you apply to an object, for example: create, read, update, should be divided into different domains. This means that one service should be responsible for the creation, another for updating, etc. In object-oriented systems, everything is often stored in the same service.
A service that writes to the database will read the event stream and process commands. But any requests occur only in the read-only database. Dividing the logic of reading and writing into two different services increases the complexity, but allows you to optimize performance separately for these systems.
Problems
Let's talk about some of the problems you may encounter when integrating Kafka into your service-oriented application.
The first problem may be slow consumer. In an event-oriented system, your services should be able to handle events instantly when they are received from a superior service. Otherwise they will just hang without any alerts about the problem or timeouts. The only place where timeouts can be defined is a socket connection with Kafka brokers. If the service does not process the event quickly enough, the connection may be interrupted by timeout, but restoring the service requires additional time because the creation of such sockets is expensive.
If the consumer is slow, how can you increase the speed of event handling? In Kafka, you can increase the number of consumers in a group, so more events can be processed in parallel. But it will take at least 2 consumer per service: in the event that one drops, the damaged sections can be reassigned.
It is also very important to have metrics and alerts to monitor the speed of event processing. ruby-kafka can work with ActiveSupport alerts, it also has StatsD and Datadog modules, which are enabled by default. In addition, hem provides a list of recommended metrics for monitoring.
Another important aspect of building systems with Kafka is designing consumers with the ability to handle failures. Kafka is guaranteed to send the event at least once; excluded the case when the message did not go at all. But it is important that consumers are prepared to handle recurring events. One way to do this is to always use
UPSERT to add new records to the database. If the entry already exists with the same attributes, the call will essentially be inactive. In addition, you can add a unique identifier to each event and simply skip events that have already been processed previously.Data formats
One of the surprises when working with Kafka can be its simple attitude to the data format. You can send anything in bytes and the data will be sent to the consumer without any verification. On the one hand, it gives flexibility and allows you to not care about the format of the data. On the other hand, if the producer decides to change the sent data, there is a chance that some consumer will eventually break down.
Before building an event-oriented architecture, select a data format and analyze how it will help to further register and develop patterns.
One of the formats recommended for use is, of course, JSON. This format is human-readable and supported by all known programming languages. But there are pitfalls. For example, the size of the final data in JSON can become frighteningly large. The format requires storing key-value pairs, which is quite flexible, but the data are duplicated in each event. Changing the schema is also a difficult task, since there is no built-in support for overlaying one key onto another if you need to rename the field.
The team that created Kafka recommends using Avro as a serialization system. Data is sent in binary form, and this is not the most human-readable format, but inside there is more reliable support for the schemes. The target object in Avro includes both schema and data. Avro also supports simple types, such as numbers, as well as complex ones: dates, arrays, etc. In addition, it allows you to include documentation inside the scheme, which allows you to understand the purpose of a specific field in the system and contains many other built-in tools for working with the scheme.
avro-builder is a gem created by Salsify, which offers ruby-like DSL for creating schemes. In more detail about Avro it is possible to read in this article .
Additional Information
If you are interested in how to host Kafka or how it is used in Heroku, there are several reports that may be of interest to you.
Jeff Chao's at the DataEngConf SF '17 conference “ Beyond 50,000 Partitions: How to Operate the Pill on the Limits of Kafka at Scale ”
Pavel Pravosud at Dreamforce '16 Conference “ Dogfooding Kafka: How We Built Heroku's Real-Time Platform Event Stream ”
Enjoy watching!
Source: https://habr.com/ru/post/450028/
All Articles