Fast C / C ++ cache, thread safety
Comparative testing of multithreaded caches implemented in C / C ++ and a description of how the LRU / MRU O (n) Cache series cache is designed ** RU
For decades, many caching algorithms have been developed: LRU, MRU, ARC, and others ... However, when the cache was needed for multi-threaded work, a googling on this topic gave one and a half options, and the question on StackOverflow remained unanswered. Found a solution from Facebook that relies on Intel TBB's thread-safe repository containers. The latter also has a multi-threaded LRU cache while still in beta testing, and therefore to use it you must explicitly specify in the project:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true Otherwise, the compiler will show an error as in the Intel TBB code there is a check:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif I wanted to somehow compare the performance of the caches - which one to choose? Or write your own? Earlier, when comparing single-threaded caches ( link ), I received offers to try other conditions with other keys and realized that a more convenient extensible bench was required for testing. To make it easier to add competing algorithms to tests, I decided to wrap them in a standard interface:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; }; Similarly, the interfaces are wrapped: working with the operating system, getting settings, test cases, etc. The sources are uploaded to the repository . Now there are two test cases on the stand: insert / search up to 1,000,000 items with a key of randomly generated numbers and up to 100,000 items with a string key (taken from 10MB lines of wiki.train.tokens). To estimate the execution time, each test cache is first heated to the target volume without time measurements, then the semaphore drops the data stream for adding and searching data. The number of streams and test case settings are set in assets / settings.json . Step-by-step instructions for compiling and describing JSON settings are described in the WiKi repository . The time is recorded from the moment the semaphore is lowered until the last thread stops. Here's what happened:
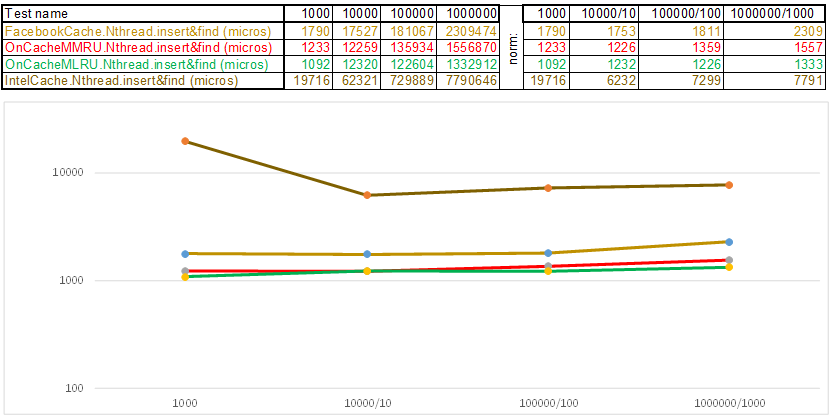
Test case1 is a key in the form of an array of random numbers uint64_t keyArray [3]:
Test case2 - key as a string:
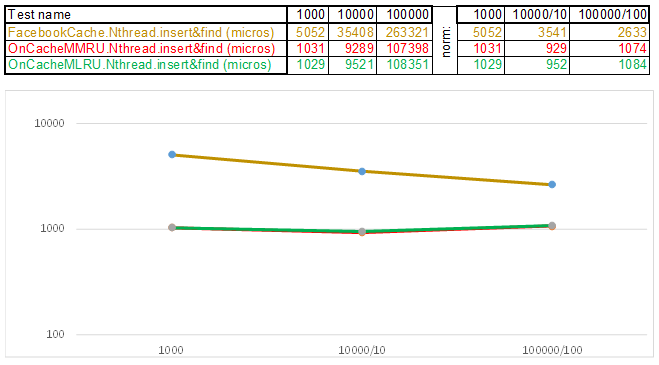
Please note that the amount of inserted / searched data at each step of the test case increases 10 times. Then I divide the time for processing the next volume by 10, 100, 1000, respectively ... If the algorithm, according to the time complexity, behaves like O (n), then the timeline will remain approximately parallel to the X axis. get 3-5 fold superiority over Facebook cache in O (n) Cache ** RU algorithms when working with a string key:
- The hash function, instead of counting each letter of a string, simply casts a pointer to the given string to the uint64_t keyArray [3] and counts the sum of the integers. That is, it works like the transfer "Guess the melody" - and I guess the melody by 3 notes ... 3 * 8 = 24 letters if the Latin alphabet, and this already allows you to scatter the lines well enough on the hash baskets. Yes, many lines can be collected in a hash basket, and then the algorithm starts to accelerate:
- Skip List in each basket allows you to quickly move irregularly first on different hashes (basket id = hash% number of baskets, so different hashes may appear in one basket), then within one hash along the vertices:
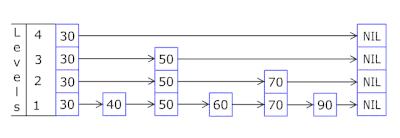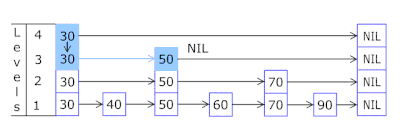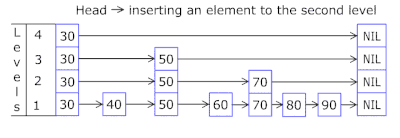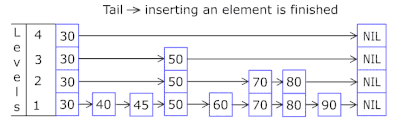
- Nodes in which keys are stored and data are taken from a previously allocated array of nodes, the number of nodes coincides with the cache capacity. Atomic identifier indicates which node to take next - if it reaches the end of the node pool, it starts with 0 = so the allocator walks in a circle overwriting the old nodes ( LRU cache in OnCacheMLRU ).
For the case when it is necessary that the most popular items in search queries are saved in the cache, the second class OnCacheMMRU is created , the algorithm is as follows: in the class constructor, besides the cache capacity, the second parameter is passed to uint32_t uselessness if the number of search queries that wanted the current node from the cyclic pool is less border uselessness, then the node is reused for the next insert operation (to be evicted). If the node’s popularity (std :: atomic <uint32_t> used {0}) is high on this circle, then at the time of the cyclic pool allocator request, the node will survive, but the popularity counter will be reset to 0. This node will have one more pass of the allocator on the pool of nodes and get a chance to gain popularity again to continue to exist. That is, it is a mixture of MRU algorithms (where the most popular ones hang in the cache forever) and MQ (where the lifetime is tracked). The cache is constantly updated and it works very fast - instead of 10 servers you can put 1
In large, the caching algorithm spends time on the following:
- Maintaining the cache infrastructure (containers, allocators, tracking the lifetime and popularity of items)
- Calculation of the hash and key comparison operations when adding / searching data
- Search Algorithms: Red-Black Tree, Hash Table, Skip List, ...
It was necessary to simply reduce the operating time of each of these points, given the fact that the simplest algorithm turns out to be most efficient in terms of time complexity, since any logic takes CPU cycles. That is, no matter what you write, these are operations that should pay off in time in comparison with the simple iteration method: while another function is called, the search will have to go through another hundred or two nodes. In this light, multi-threaded caches will always be single-threaded, since protecting the baskets through std :: shared_mutex and nodes via std :: atomic_flag in_use is not free. Therefore, for issuing on the server, I use the OnCacheSMRU single-thread cache in the main thread of the Epoll server (only parallel operations with the DBMS, disk, and cryptography have been made into parallel workflows). For comparative evaluation, a single-flow test case version is used:
Test case1 is a key in the form of an array of random numbers uint64_t keyArray [3]:

Test case2 - key as a string:
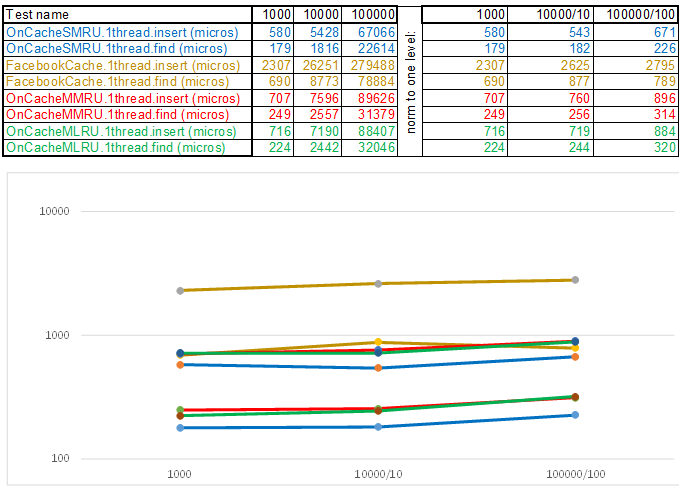
In conclusion, I want to tell you what else can be interesting to extract from the source of the test bench:
- The JSON parsing library, consisting of a single file, specjson.h, is a small, simple, fast algorithm for those who do not want to drag a few megabytes of someone else’s code into their project in order to parse the settings file or incoming JSON of a known format.
- Approach with injecting implementation of platform-specific operations in the form of (class LinuxSystem: public ISystem {...}) instead of the traditional (#ifdef _WIN32). So it is more convenient to wrap, for example, semaphores, work with dynamically connected libraries, services — in classes, only code and headers from a specific operating system. If you need another operating system, you inject another implementation (class WindowsSystem: public ISystem {...}).
- The stand is going to CMake - the CMakeLists.txt project is easy to open in Qt Creator or Microsoft Visual Studio 2017. Working with a project through CmakeLists.txt allows you to automate some preparatory operations — for example, copy test case files and setup files to the installation directory:
# Coping assets (TODO any change&rerun CMake to copy): FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets) FILE(GLOB_RECURSE SpecAssets ${CMAKE_CURRENT_SOURCE_DIR}/assets/*.* ${CMAKE_CURRENT_SOURCE_DIR}/assets/* ) FOREACH(file ${SpecAssets}) FILE(RELATIVE_PATH ITEM_PATH_REL ${CMAKE_CURRENT_SOURCE_DIR}/assets ${file} ) GET_FILENAME_COMPONENT(dirname ${ITEM_PATH_REL} DIRECTORY) FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname}) FILE(COPY ${file} DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname}) ENDFOREACH() - For those who are mastering the new features of C ++ 17, this is an example of working with std :: shared_mutex, std :: allocator <std :: shared_mutex>, static thread_local in templates (are there nuances - where is the allotment?), Running a large number of tests in flows in different ways with the measurement of execution time:
//Prepare insert threads: for (i = cnt_insert_threads; i; --i) { std::promise<InsertResults> prom; fut_insert_results.emplace_back(prom.get_future()); threads.emplace_back(std::thread (&TestCase2::insert_in_thread, this, curSize, std::move(prom), p_tester)); } // for insert //Prepare find threads: for (i = cnt_find_threads; i; --i) { std::packaged_task<FindResults(TestCase2 *i, int, IAlgorithmTester *)> ta( [](TestCase2 *i, int count, IAlgorithmTester *p_tester){ return i->find_in_thread(count, p_tester); }); fut_find_results.emplace_back(ta.get_future()); threads.emplace_back( std::thread (std::move(ta), this, curSize, p_tester)); } // for find //Banzai!!! auto start = std::chrono::high_resolution_clock::now(); l_cur_system.get()->signal_semaphore(cnt_find_threads + cnt_insert_threads); std::for_each(threads.begin(), threads.end(), std::mem_fn(&std::thread::join)); auto end = std::chrono::high_resolution_clock::now(); - Step by step instructions on how to compile, configure and run this test bench - WiKi .
If you don’t have step-by-step instructions for your operating system, then I would be grateful for your contribution to the repository for the implementation of the ISystem and step-by-step compilation instructions (for WiKi) ... Or just write me - I will try to find time to raise the virtual machine and describe the build steps.
')
Source: https://habr.com/ru/post/450004/
All Articles