Multi-threaded associative containers in C ++. Yandex report
From the report of the senior developer Sergey Murylev you can learn about the multi-threaded associative container for the standard library, which is being developed in the framework of WG21. Sergey spoke about the pros and cons of popular solutions to this problem and the path chosen by the developers.
- You probably already guessed from the title that today's report will be about how we, in the framework of Working Group 21, made our container, similar to std :: unordered_map, but for a multi-threaded environment.
In many programming languages - Java, C #, Python - this is already there and is quite widely used. And in our beloved, fastest and most powerful C ++, this was not the case. But we consulted and decided to do such a thing.
')

Before you add something to the standard, you need to think about how people will use it. Then to make a more correct interface, which will most likely be adopted by the committee - preferably, without any amendments. And so that in the end there was not such that they did one thing, but it turned out another.
The most famous and widely used option is the caching of large heavy calculations. There is a fairly well-known service Memcached, which simply caches web server responses in memory. It is clear that you can do about the same thing on the side of your application if you have a competitive associative container. Both approaches have their pros and cons. But if you do not have such a container, you will either have to make your own bike, or use some Memcached.
The next most popular use case is event deduplication. I think many in this room write all sorts of distributed systems, and they know that often queues are used to communicate between components, such as Apache Kafka and Amazon Kinesis. They are distinguished by such a feature that they have one message to one concuster can come several times. This is called at least once delivery, which means a guarantee of delivery at least once: more is possible, less is impossible.
Consider this in terms of real life. Imagine that we have some backend of some chat or social network where the exchange of messages takes place. This can lead to someone writing a message and then sending someone a push notification to someone later. It is clear that if users see this, they will not be happy about it. It is argued that this problem can be solved with the help of such a wonderful multi-threaded container.
The next, not so often used case is when we just need to save something somewhere on the server side, some metadata for the user. For example, we can save the time when the user last authenticated, in order to understand the next time he asked for a username and password.
The last option on this slide is counting statistics. From real life applications, you can give an example of using a Facebook virtual machine. They made a whole virtual machine to optimize PHP, and in this virtual machine they try to write to the built-in hash table the arguments with which they were called for all the built-in functions. And if they have a result in the cache, then they try to just give it away and not count anything.

To add something big and complicated to the standard is not a simple and quick job. As a rule, if something big is added, it goes through a technical specification. At the moment, the standard is a big move to expand support for multithreading in the standard library. And exactly now the proposal P0260R3 about multi-threaded queues goes there. This proposal is about a very similar data structure to us, and our design solutions are in many ways similar.
As a matter of fact, one of the main concepts of their design is that their interface is different from the standard std :: queue. What is the point? If you look at the standard queue, in order to extract an element from it, you need to do two operations. You need to do a front operation to read, and a pop operation to remove. If we work in multithreading conditions, then we can have some kind of operation on the queue between these two calls, and it may turn out that we consider one element and delete another, which seems conceptually incorrect. Therefore, these two calls were replaced by one there, and some more calls from the category of try push and try pop were added. But the general idea is that a multi-threaded container will not be the same as a regular interface.
Also, multithreaded queues have many different implementations that solve several different tasks. The most frequent task is the task of producers and consumers, when we have some flows that produce some tasks and some flows that take tasks from the queue and process them.
The second case is when we need to have just some kind of synchronized queue. In the case of producers and consumers, we have a queue that is bounded above and below. If we try, conditionally speaking, to extract from an empty queue, then we move to the waiting state. And the same thing happens if we try to add something that does not fit in the queue.
Also in this proposal, it is described that we have a separately made interface that allows you to distinguish which implementation we have inside is blocking, or lock free. The fact that it’s written everywhere in the proposal is lock free, in fact it is written in books as wait free. This means that our algorithm works out for a fixed number of operations. Lock free there means a little different, but that is not the point.
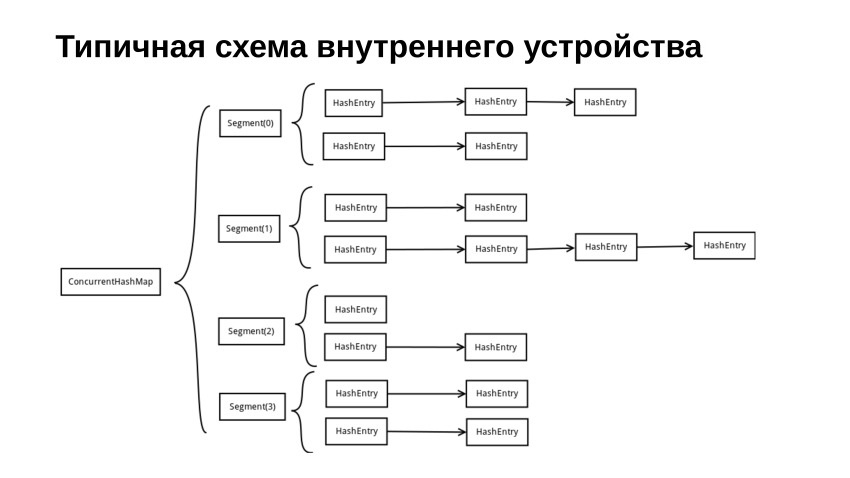
Let's look at a typical scheme of how the implementation of our hash table might look like if it is locked. It is divided into a number of segments. Each segment, as a rule, contains some kind of blocking, such as Mutex, Spinlock, or something even more cunning. And besides Mutex or Spinlock, it also contains within itself the usual hash table, which is protected by this business.
In this picture, we have drawn a hash table, which is made on the lists. In fact, in our reference implementation, we wrote an open address hash table for performance reasons. Performance considerations, in principle, are the same, why std :: vector is faster than std :: list, because the vector, relatively speaking, is stored sequentially in memory. When we go on it, we have a sequential access, which is well cached. If we use some kind of sheets, then we will have a lot of jumps between different sections of memory. And the whole thing, as a rule, ends up losing productivity.
At the very beginning, when we want to find something in this hash table, we take the hash code from the key. You can take it modulo and do something else with it so that we get the segment number, and already in the segment we are looking, as in a regular hash table, but we, of course, take the lock.

The main ideas of our design. Of course, we also made an interface that does not match std :: unordered_map. The reason is this. We have, for example, in the usual std :: unordered_map there is such a wonderful thing as iterators. First, not all implementations can support them normally. And those that can support, as a rule, are some lock free implementations that require the presence of either a garbage collection, or some smart pointers that wipe out memory for it.
In addition, there are several other types of operations that we threw out. In fact, iterators, they are in many places. For example, they are in Java. But, as a rule, oddly enough, they are not synchronized there. And if you try to do something with them from different streams, they can easily go into an invalid state, and you can get an exception in Java, and if you write this on pluses, then this will most likely be an undefined behavior, which is even worse . And by the way, on the topic of undefined behavior: in my opinion, the comrades from Facebook in their library folly, which is posted in the open source on GitHub, did just that. Just copied the interface with Java and got such great iterators.
We also have no memory reclamation, that is, if we have added something to the container and occupied it for memory, we will not give it back, even if we delete everything. Another prerequisite for this decision was that we have a hash table with open addressing inside. It works on a linear data structure that, like vector, does not return back memory.
The next conceptual point is that we never, under any circumstances, give out references and pointers to internal objects to anyone. This was done in order to prevent the need for the garbage collection, and not to force smart pointers. It is clear that if we store some large enough objects, it will be unprofitable to store them by value inside. But, in this case, we can always wrap them in some smart pointers of our choice. And, if we want, for example, to do some kind of synchronization on values, we can wrap them in some boost :: synchronized_value.
We looked at the fact that some time ago the class that returned the number of active links to this object was removed from the shared_ptr class. And we came to the conclusion that we also need to throw out several functions, namely, size, count, empty, buckets_count, because as soon as we return this value from the function, it immediately ceases to be valid, because someone can same moment to change.
We also at one of the previous meetings asked us to add a sort of mode so that we could access our container in single-threaded mode, as usual std :: unordered_map. Such semantics allows us to clearly distinguish where we are working in multi-threaded mode, and where not. And to avoid some unpleasant situations when people take a multi-threaded container, expect that everything will be fine with them, take iterators, and then suddenly it turns out that everything is bad.

At this meeting in Hawaii an entire proposal was written against us. :) We were told that such things have no place in the standard, because there are a lot of ways to make our multi-threaded associative container.
Each has its pros and cons - and it is not clear how to use what we will eventually do. As a rule, it is used when you need some kind of extreme performance. And it seems that our boxed solution does not fit, it is necessary to optimize for each specific case.
The second point of this proposal was that our interface was incompatible with posting Facebook on GitHub from its standard library.
In fact, there were no special problems. There simply was a question from the category "I did not read, but I condemn." They just looked - the interface is different, it means that it is not compatible.
The idea of the proposal was also that such problems should be solved with the help of the so-called policy based design, when it is necessary to make an additional template parameter in which you can transfer a bit mask with which features we want to enable and which ones to disable. Indeed, this sounds a bit wild and leads to the fact that we get about 2 ^ n implementations, where n is the number of different features.

In code, it looks like this. We have some parameter and some number of predefined constants that can be passed there. Oddly enough, this proposal was rejected.

Because, in fact, the committee has already taken the position that there will be such things when a multithreaded queue has passed through SG1. There was not even a vote on this issue. But two questions were put to the vote.
The first. Many people wanted us on the side of our reference implementation to support reading without taking any locks. So that we have a completely non-blocking reading. It really makes sense: as a rule, the most popular use is caching. And it is very beneficial for us to have a quick reading.
Second moment. Everyone had heard enough of the previous comrade, who was talking about policy based design. Everybody had an idea - and what, let me give my idea too! And everyone voted to ensure that the policy based design was. Although I must say, this whole story lasts a long time ago, and before us were colleagues from Intel, Arch Robinson and Anton Malakhov. And they already had several proposals on this topic. They did offer to add the lock free implementation based on the SeepOrderedList algorithm. And they also had a policy based design with the memory complaint.
And this proposal did not like the Library Evolution Working Group. He was wrapped up with the reason that we just would have an unlimited increase in the number of words in the standard. It will simply be impossible to adequately verify and simply implement in code.
We have no comments to the ideas themselves. We have, for the most part, comments on the reference implementation. And of course, we have a couple of ideas that can be made to make it clearer. But as a matter of fact, next time we will go about the same proposal. We sincerely hope that we will not have, as with modules, five visits with the same proposal. We sincerely believe in ourselves, and that we will be missed further in the next call, and that the Library Evolution Working Group will nevertheless insist on its opinion, will not allow us to push through policy based design. Because our opponent does not stop. He decided to prove to everyone that this is necessary. But as they say, time will tell. I have everything, thank you for your attention.
- You probably already guessed from the title that today's report will be about how we, in the framework of Working Group 21, made our container, similar to std :: unordered_map, but for a multi-threaded environment.
In many programming languages - Java, C #, Python - this is already there and is quite widely used. And in our beloved, fastest and most powerful C ++, this was not the case. But we consulted and decided to do such a thing.
')
Before you add something to the standard, you need to think about how people will use it. Then to make a more correct interface, which will most likely be adopted by the committee - preferably, without any amendments. And so that in the end there was not such that they did one thing, but it turned out another.
The most famous and widely used option is the caching of large heavy calculations. There is a fairly well-known service Memcached, which simply caches web server responses in memory. It is clear that you can do about the same thing on the side of your application if you have a competitive associative container. Both approaches have their pros and cons. But if you do not have such a container, you will either have to make your own bike, or use some Memcached.
The next most popular use case is event deduplication. I think many in this room write all sorts of distributed systems, and they know that often queues are used to communicate between components, such as Apache Kafka and Amazon Kinesis. They are distinguished by such a feature that they have one message to one concuster can come several times. This is called at least once delivery, which means a guarantee of delivery at least once: more is possible, less is impossible.
Consider this in terms of real life. Imagine that we have some backend of some chat or social network where the exchange of messages takes place. This can lead to someone writing a message and then sending someone a push notification to someone later. It is clear that if users see this, they will not be happy about it. It is argued that this problem can be solved with the help of such a wonderful multi-threaded container.
The next, not so often used case is when we just need to save something somewhere on the server side, some metadata for the user. For example, we can save the time when the user last authenticated, in order to understand the next time he asked for a username and password.
The last option on this slide is counting statistics. From real life applications, you can give an example of using a Facebook virtual machine. They made a whole virtual machine to optimize PHP, and in this virtual machine they try to write to the built-in hash table the arguments with which they were called for all the built-in functions. And if they have a result in the cache, then they try to just give it away and not count anything.
Link from the slide
To add something big and complicated to the standard is not a simple and quick job. As a rule, if something big is added, it goes through a technical specification. At the moment, the standard is a big move to expand support for multithreading in the standard library. And exactly now the proposal P0260R3 about multi-threaded queues goes there. This proposal is about a very similar data structure to us, and our design solutions are in many ways similar.
As a matter of fact, one of the main concepts of their design is that their interface is different from the standard std :: queue. What is the point? If you look at the standard queue, in order to extract an element from it, you need to do two operations. You need to do a front operation to read, and a pop operation to remove. If we work in multithreading conditions, then we can have some kind of operation on the queue between these two calls, and it may turn out that we consider one element and delete another, which seems conceptually incorrect. Therefore, these two calls were replaced by one there, and some more calls from the category of try push and try pop were added. But the general idea is that a multi-threaded container will not be the same as a regular interface.
Also, multithreaded queues have many different implementations that solve several different tasks. The most frequent task is the task of producers and consumers, when we have some flows that produce some tasks and some flows that take tasks from the queue and process them.
The second case is when we need to have just some kind of synchronized queue. In the case of producers and consumers, we have a queue that is bounded above and below. If we try, conditionally speaking, to extract from an empty queue, then we move to the waiting state. And the same thing happens if we try to add something that does not fit in the queue.
Also in this proposal, it is described that we have a separately made interface that allows you to distinguish which implementation we have inside is blocking, or lock free. The fact that it’s written everywhere in the proposal is lock free, in fact it is written in books as wait free. This means that our algorithm works out for a fixed number of operations. Lock free there means a little different, but that is not the point.
Let's look at a typical scheme of how the implementation of our hash table might look like if it is locked. It is divided into a number of segments. Each segment, as a rule, contains some kind of blocking, such as Mutex, Spinlock, or something even more cunning. And besides Mutex or Spinlock, it also contains within itself the usual hash table, which is protected by this business.
In this picture, we have drawn a hash table, which is made on the lists. In fact, in our reference implementation, we wrote an open address hash table for performance reasons. Performance considerations, in principle, are the same, why std :: vector is faster than std :: list, because the vector, relatively speaking, is stored sequentially in memory. When we go on it, we have a sequential access, which is well cached. If we use some kind of sheets, then we will have a lot of jumps between different sections of memory. And the whole thing, as a rule, ends up losing productivity.
At the very beginning, when we want to find something in this hash table, we take the hash code from the key. You can take it modulo and do something else with it so that we get the segment number, and already in the segment we are looking, as in a regular hash table, but we, of course, take the lock.
Link from the slide
The main ideas of our design. Of course, we also made an interface that does not match std :: unordered_map. The reason is this. We have, for example, in the usual std :: unordered_map there is such a wonderful thing as iterators. First, not all implementations can support them normally. And those that can support, as a rule, are some lock free implementations that require the presence of either a garbage collection, or some smart pointers that wipe out memory for it.
In addition, there are several other types of operations that we threw out. In fact, iterators, they are in many places. For example, they are in Java. But, as a rule, oddly enough, they are not synchronized there. And if you try to do something with them from different streams, they can easily go into an invalid state, and you can get an exception in Java, and if you write this on pluses, then this will most likely be an undefined behavior, which is even worse . And by the way, on the topic of undefined behavior: in my opinion, the comrades from Facebook in their library folly, which is posted in the open source on GitHub, did just that. Just copied the interface with Java and got such great iterators.
We also have no memory reclamation, that is, if we have added something to the container and occupied it for memory, we will not give it back, even if we delete everything. Another prerequisite for this decision was that we have a hash table with open addressing inside. It works on a linear data structure that, like vector, does not return back memory.
The next conceptual point is that we never, under any circumstances, give out references and pointers to internal objects to anyone. This was done in order to prevent the need for the garbage collection, and not to force smart pointers. It is clear that if we store some large enough objects, it will be unprofitable to store them by value inside. But, in this case, we can always wrap them in some smart pointers of our choice. And, if we want, for example, to do some kind of synchronization on values, we can wrap them in some boost :: synchronized_value.
We looked at the fact that some time ago the class that returned the number of active links to this object was removed from the shared_ptr class. And we came to the conclusion that we also need to throw out several functions, namely, size, count, empty, buckets_count, because as soon as we return this value from the function, it immediately ceases to be valid, because someone can same moment to change.
We also at one of the previous meetings asked us to add a sort of mode so that we could access our container in single-threaded mode, as usual std :: unordered_map. Such semantics allows us to clearly distinguish where we are working in multi-threaded mode, and where not. And to avoid some unpleasant situations when people take a multi-threaded container, expect that everything will be fine with them, take iterators, and then suddenly it turns out that everything is bad.
Link from the slide
At this meeting in Hawaii an entire proposal was written against us. :) We were told that such things have no place in the standard, because there are a lot of ways to make our multi-threaded associative container.
Each has its pros and cons - and it is not clear how to use what we will eventually do. As a rule, it is used when you need some kind of extreme performance. And it seems that our boxed solution does not fit, it is necessary to optimize for each specific case.
The second point of this proposal was that our interface was incompatible with posting Facebook on GitHub from its standard library.
In fact, there were no special problems. There simply was a question from the category "I did not read, but I condemn." They just looked - the interface is different, it means that it is not compatible.
The idea of the proposal was also that such problems should be solved with the help of the so-called policy based design, when it is necessary to make an additional template parameter in which you can transfer a bit mask with which features we want to enable and which ones to disable. Indeed, this sounds a bit wild and leads to the fact that we get about 2 ^ n implementations, where n is the number of different features.
In code, it looks like this. We have some parameter and some number of predefined constants that can be passed there. Oddly enough, this proposal was rejected.
Because, in fact, the committee has already taken the position that there will be such things when a multithreaded queue has passed through SG1. There was not even a vote on this issue. But two questions were put to the vote.
The first. Many people wanted us on the side of our reference implementation to support reading without taking any locks. So that we have a completely non-blocking reading. It really makes sense: as a rule, the most popular use is caching. And it is very beneficial for us to have a quick reading.
Second moment. Everyone had heard enough of the previous comrade, who was talking about policy based design. Everybody had an idea - and what, let me give my idea too! And everyone voted to ensure that the policy based design was. Although I must say, this whole story lasts a long time ago, and before us were colleagues from Intel, Arch Robinson and Anton Malakhov. And they already had several proposals on this topic. They did offer to add the lock free implementation based on the SeepOrderedList algorithm. And they also had a policy based design with the memory complaint.
And this proposal did not like the Library Evolution Working Group. He was wrapped up with the reason that we just would have an unlimited increase in the number of words in the standard. It will simply be impossible to adequately verify and simply implement in code.
We have no comments to the ideas themselves. We have, for the most part, comments on the reference implementation. And of course, we have a couple of ideas that can be made to make it clearer. But as a matter of fact, next time we will go about the same proposal. We sincerely hope that we will not have, as with modules, five visits with the same proposal. We sincerely believe in ourselves, and that we will be missed further in the next call, and that the Library Evolution Working Group will nevertheless insist on its opinion, will not allow us to push through policy based design. Because our opponent does not stop. He decided to prove to everyone that this is necessary. But as they say, time will tell. I have everything, thank you for your attention.
Source: https://habr.com/ru/post/449976/
All Articles