Sources of inspiration when developing under UDB
Well, we already know everything that is needed for programming UDB. But one thing - to know, and quite another - to be able to. Therefore, today we will discuss where and how you can get inspiration to enhance your own skills, where to gain experience. As can be seen from the translation of the documentation , there is dry knowledge, which is not even always tied to real practice (I drew attention to this in a rather lengthy note to the latest translation to date). Actually, the statistics of viewing articles shows that fewer and fewer people read translations. There was even a proposal to interrupt this cycle as uninteresting, but only two parts remained, therefore, in the end, it was simply decided to reduce the pace of their preparation. In general, the documentation for the controller is a necessary piece, but not self-sufficient. Where else to get inspiration?

First of all, I can recommend an excellent document AN82156 Designing PSoC Creator Components with UDB Datapaths . In it you will find typical solutions, as well as several typical projects. And at the beginning of the document development is carried out using the UDB Editor, and towards the end - using the Datapath Config Tool, that is, the document covers all aspects of development. But unfortunately, looking at the price of a single PSoC chip, I would say that if it can only solve the issues described in this document, then the controller is greatly overvalued. PWMs and standard serial ports can be done without PSoC. Fortunately, the range of tasks solved by PSoC is much wider. Therefore, having finished reading AN82156, we begin to look for other sources of inspiration.
The next useful source is the examples that come with the PSoC Creator. I have already referred to them in a note to one of the parts of the translation of the company documentation (you can see here ). They are stored around here (the disk may vary):
')
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
You should look for files * .v, that is, verilog texts, or * .vhd, since the syntax of the VHDL language requires a little more description, and in this language you can sometimes find interesting nuances hidden from the programmer's eyes on Verilog. The trouble is that these are not examples, but ready-made solutions. This is great, they are perfectly debugged, but we, ordinary programmers, have different goals with Cypress programmers. Our task is to do something auxiliary in a short time, and then begin using it in our projects, for which most of the time will be spent. It should ideally solve the tasks set before us today, and if tomorrow we want to insert the same code into another project, where everything will be slightly different, then tomorrow we will do it for that situation. For developers, the Cypress component is the final product, so they can spend most of their time on it. And they must foresee everything, everything, everything. So, when I looked at these texts, I felt sad. They are too complicated for someone who has just started looking to find inspiration for their first developments. But as reference books these texts are quite suitable. They contain many valuable designs that are necessary when creating your own things.
Also there are very interesting places. For example, there are, now I will say in the style of “oil buttery”, models for modeling (a long time ago one stern teacher discouraged me from translating a simulation somehow differently than “modeling”). They can be found in the catalog.
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
The most interesting directory for a programmer on Verilog is:
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
The description of the components in the documentation is good. But here are described behavioral models for all standard components. Sometimes this is better than the documentation (which is written in heavy language, plus some essential details are omitted from it). When the behavior of a component is unclear, it is worth starting to try to understand it with viewing files from this directory. At first I tried to search on Google, but very often I found only reasoning on found forums and no specifics. Here is exactly the specifics.
But nevertheless, a reference book is great, and where to find a textbook, what should we learn from? Honestly, nothing special. There are few good ready-made examples for the UDB Editor. I was terribly lucky that when I suddenly decided to play RGB LEDs, I came across a beautiful example under the UDB Editor (I wrote about it in the article that started the whole cycle). But if you work with a search engine a lot, then there are still examples for the Datapath Config Tool, which is why I did the previous article so that everyone would understand how to use this tool. And the wonderful page on which the mass of examples is collected, is located here .
On this page are developments made by third-party developers, but verified by Cypress. That is, just what we need: we are also third-party developers, but we want to learn from something that is precisely verified. Let's look at an example by which I found this page - the hardware square root calculator. End users include it in the signal processing path, throwing the component onto the circuit. In this example, we will practice analyzing such a code, and then everyone will be able to embark on an independent voyage. So, the necessary example can be downloaded by reference .
Inspect it. There are examples (which everyone will consider independently) and there are libraries located in the \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib directory.
For each type (integer or with a fixed point) and for each digit capacity there is its own solution. This we should note. Versatility is good when developing in the UDB Editor, but when developing using the Datapath Edit Tool, as you can see, people suffer like this. Do not be afraid if you do not work out universally (but if it works out, all the better).
At the top level (circuit design), I will not dwell, we are studying not working with PSoC, but working with UDB. Let's see a variant of medium complexity - 16 bit, but integer. It is located in the CJCU_B_Isqrt16_v1_0 directory.
The first thing to do is reveal the transition graph of the firmware automaton. Without it, we won’t even guess what kind of square root algorithm is used, since Google offers several fundamentally different algorithms to choose from.
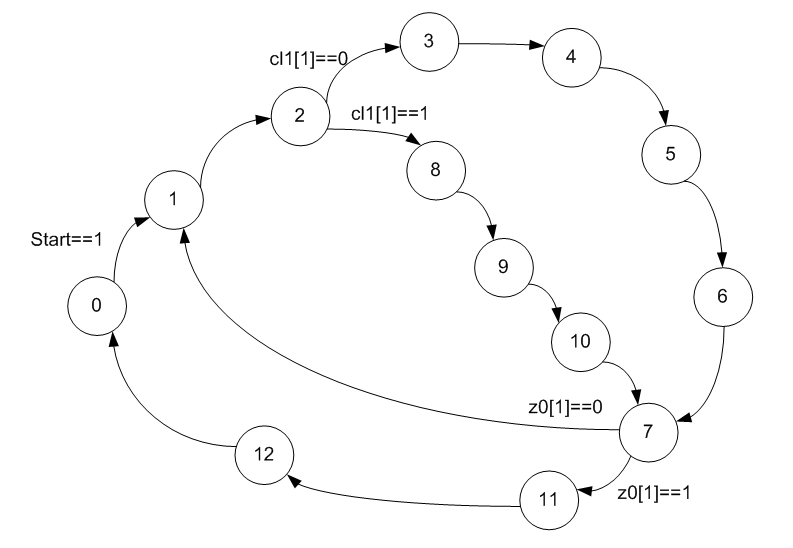
So far, nothing is clear, but it is predictable. Need to add more information. We look at the coding of states. It is striking that they are not encoded in the usual incremental binary code.

I have already mentioned such an approach in my articles, but I have never used it in concrete examples. I recall that the dynamic configuration memory of the ALU has only three address inputs. That is, the ALU can perform one of eight operations. If the state of the automaton is greater, then the rule “for each state has its own operation” becomes impracticable. Therefore, the states are selected in which the operations for the ALU are identical, they have three bits supplied to the RAM address of the dynamic configuration (usually the least significant ones), are encoded in the same way, and the rest are different. How to make such a solitaire is a developer’s problem. The developers of the studied code have been folded exactly as shown above.
We add this information to the graph, plus we paint in similar state colors that perform the same function in the ALU.
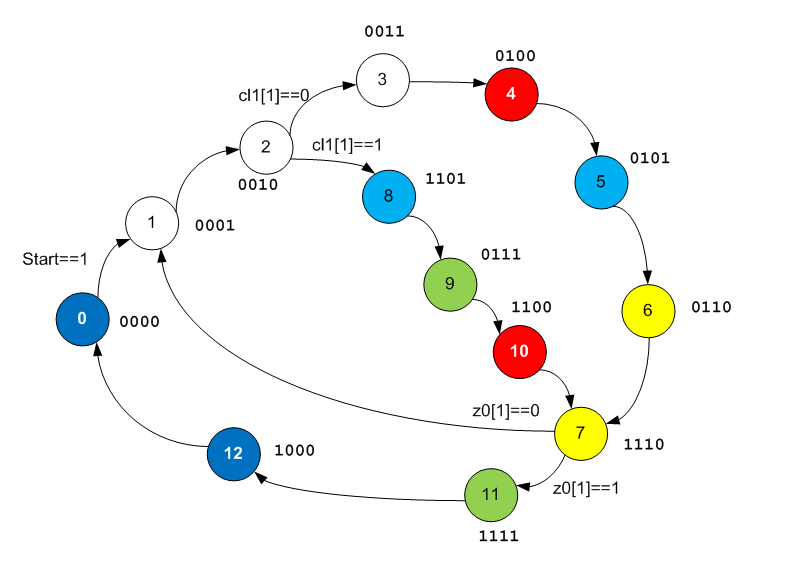
No patterns have not yet manifested, but continue to open the graph. Open the Datapath Edit Tool and learn the logic already in it.
We draw attention to the fact that we have two Datapath blocks, connected in a chain. When we do something of our own, we might also need this (although the Datapath Edit Tool can create already chained blocks, so it's not a big deal):
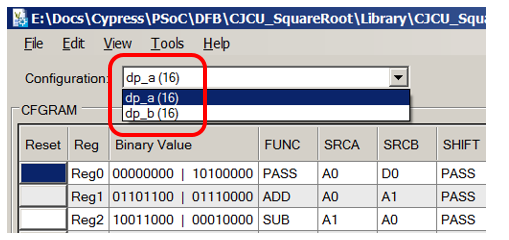
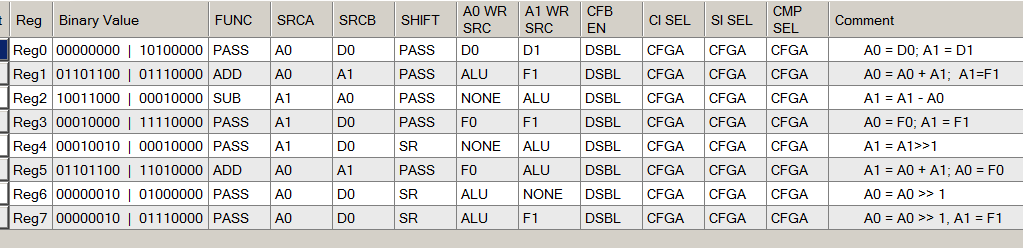
When reading (and filling) the column corresponding to the ALU, always open the document with the following pattern:

True, the developers of this example took care of us and filled in the comment fields. Now we can use them to understand what is set up. At the same time, we note for ourselves that writing comments is always useful both for those who will accompany the code, and for us, when in six months we will forget about it.
Look at the X000 code corresponding to states 0 and 12:

From the comment it is already clear what is there (the contents of register D0 are copied to register A0, and the contents of D1 are copied to register A1. Knowing this, we train our intuition for the future and find a similar entry in the settings fields:

In the same place, we see that the ALU operates in the PASS mode, the shift register is also PASS , so no other actions are actually performed.
Along the way, we look at the Verilog text and see where the value of the registers D0 and D1 equals:

If desired, the same can be seen in the Datapath Config Tool by selecting the View-> Initial Register Values menu:
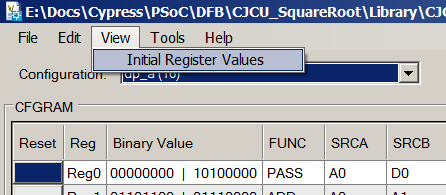
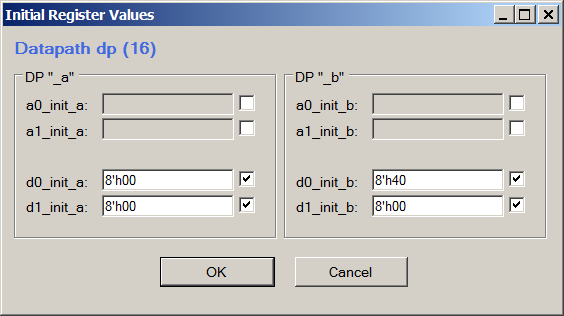
For viewing it is more convenient to analyze Verilog code directly, to create your own version - work through the editor, so as not to keep in mind the syntax.
Similarly, parse (first peeping in the comments) all the other functions of the ALU:
We remake the transition graph of the automaton in view of the new knowledge:

Something is already looming, but so far I can not put with confidence on this graph any of the algorithms found by Google. Rather, about some you can confidently say that it is not they, but even on the plausible to the end I still can not give a confident answer that it is they. Confused by the active use of registers FIFO F0 and F1. Generally, in the file
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
you can see that F1 is used to pass the argument and return the result:

But one argument and one result. Why so many appeals to the FIFO in the course of work? And what have FIFO0? Cut me into pieces, and it seems that the authors took advantage of the regime that occurred in the translations of the documentation, when instead of a full-fledged FIFO, this block acted as a single register. Suppose the authors decided to expand the register set. If this is so, then their methodology will be useful to us in our practical work, let's study the details. In fact, the documentation tells about different approaches to working with FIFO. It is possible - so, it is possible - so, and it is possible - commercials. And no specifics. Again we have a chance to learn advanced foreign practical experience. What do authors do with FIFO?
First, here are the signal assignments:
Secondly, here is the connection to Datapath:
From the description of the controller is not particularly clear what it all means. But from Application Note I found out that this is the fault of all this:

By the way, precisely because of this setting, this block cannot be described using the UDB Editor. When these control bits are in the ON state, the FIFO can work for different sources and receivers. If Dx_LOAD is equal to one, then Fx is exchanged with the system bus, if zero, then with the register selected here:

It turns out that F0 always exchanges with the register A0, and F1 in states 12 and 0 - with the system bus (for unloading the result and loading the argument), in the other states - with A1.
Further, from the Verilog code, we found out that in F0 the data will be loaded in states 1 and 4, and in F1 - in states 1, 3, 9, 11.
Add the knowledge to the graph. To avoid confusion in the sequence of operations, it is also time to replace the assignment mark “a la UDB Editor” with Verilog arrows to emphasize that the source is the signal value that he had before entering the block.

From the point of view of the analysis of the algorithm, everything is already clear. Before us is a modification of this algorithm:
Only in relation to our system, it will look more like this:
States 4 and 10 explicitly encode the string:
for different branches.
The string is:
clearly coded with either a pair of states 6 and 7, or a pair of states 9 and 7. So far I want to exclaim: “Well, the authors are the inventors!”, but very soon it becomes clear why there is such complexity with two branches and bypass).
State 2 encodes a conditional transition. State 7 encodes the loop statement. The comparison operation in step 2 is very expensive. In general, on most steps, the register A0 contains the variable one. But in step 1, the variable one is unloaded into F0, and instead the value res + one is loaded, then in step 2 subtraction is performed for the purpose of comparison, and in steps 3 and 8 it is restored to the value one . Why in step 4 A0 is again copied to F0, I did not understand. Perhaps this is some kind of rudiment.
It remains to figure out who res here, and who - op . We know that the condition compares op and the sum of res + one. At state 1, A0 ( one ) and A1 are added. So A1 is res . It turns out that in the state of 11 A1 - also res , and that he will fall into F1, fed to the output of the function. F1 in state 1 is clearly op . I propose to introduce color differentiation ofpants variables. Denote by res - red, op - green, and one - brown (not quite contrast, but the other colors are even less contrasting).
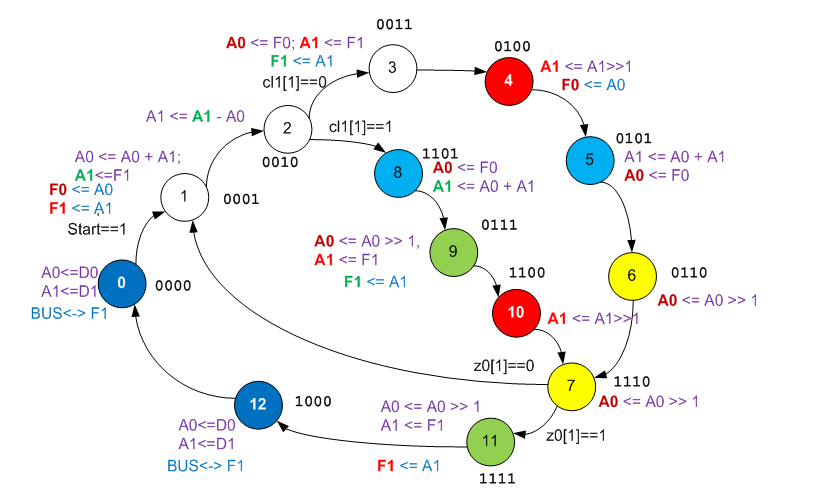
Actually, the whole truth is revealed. We see how A1 changes temporarily with F1 for comparison and computation, as the same difference is used for comparison (in fact, generation of bit C) and for participation in the formula. We even see why the empty space (traversal) in the C algorithm is encoded with a long branch of the automaton transition graph (in this branch, the registers are exchanged, identical to the exchange that takes place in the main code branch). We see everything.
The only question that does not stop torturing me is how the authors switched the FIFO to single-byte mode? Documentation says that for this you need to raise the CLR bits in the Auxiliary Control register to one, but I don’t see that the API has such records. Perhaps someone will understand this and write in the comments.
Well, and develop something of your own - in the reverse order, using the acquired skills.
For the development of skills to develop "firmware" based on UDB is useful not only to read the documentation, but also to draw inspiration from other people's developments. The code attached to PSoC Creator can be useful as a reference book, and the behavioral models supplied by the compiler will help to better understand what was meant in the documentation. The article also provides a link to a set of examples from third-party manufacturers and shows the process of analyzing one of these examples.
On this cycle of author's articles on working with UDB can be considered complete. I would be glad if he helped someone to gain knowledge useful in practice. There are still a couple of translations of documentation ahead, but statistics show that almost no one reads them. They are planned cleanly so as not to throw the topic in half a word.
First of all, I can recommend an excellent document AN82156 Designing PSoC Creator Components with UDB Datapaths . In it you will find typical solutions, as well as several typical projects. And at the beginning of the document development is carried out using the UDB Editor, and towards the end - using the Datapath Config Tool, that is, the document covers all aspects of development. But unfortunately, looking at the price of a single PSoC chip, I would say that if it can only solve the issues described in this document, then the controller is greatly overvalued. PWMs and standard serial ports can be done without PSoC. Fortunately, the range of tasks solved by PSoC is much wider. Therefore, having finished reading AN82156, we begin to look for other sources of inspiration.
The next useful source is the examples that come with the PSoC Creator. I have already referred to them in a note to one of the parts of the translation of the company documentation (you can see here ). They are stored around here (the disk may vary):
')
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
You should look for files * .v, that is, verilog texts, or * .vhd, since the syntax of the VHDL language requires a little more description, and in this language you can sometimes find interesting nuances hidden from the programmer's eyes on Verilog. The trouble is that these are not examples, but ready-made solutions. This is great, they are perfectly debugged, but we, ordinary programmers, have different goals with Cypress programmers. Our task is to do something auxiliary in a short time, and then begin using it in our projects, for which most of the time will be spent. It should ideally solve the tasks set before us today, and if tomorrow we want to insert the same code into another project, where everything will be slightly different, then tomorrow we will do it for that situation. For developers, the Cypress component is the final product, so they can spend most of their time on it. And they must foresee everything, everything, everything. So, when I looked at these texts, I felt sad. They are too complicated for someone who has just started looking to find inspiration for their first developments. But as reference books these texts are quite suitable. They contain many valuable designs that are necessary when creating your own things.
Also there are very interesting places. For example, there are, now I will say in the style of “oil buttery”, models for modeling (a long time ago one stern teacher discouraged me from translating a simulation somehow differently than “modeling”). They can be found in the catalog.
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
The most interesting directory for a programmer on Verilog is:
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
The description of the components in the documentation is good. But here are described behavioral models for all standard components. Sometimes this is better than the documentation (which is written in heavy language, plus some essential details are omitted from it). When the behavior of a component is unclear, it is worth starting to try to understand it with viewing files from this directory. At first I tried to search on Google, but very often I found only reasoning on found forums and no specifics. Here is exactly the specifics.
But nevertheless, a reference book is great, and where to find a textbook, what should we learn from? Honestly, nothing special. There are few good ready-made examples for the UDB Editor. I was terribly lucky that when I suddenly decided to play RGB LEDs, I came across a beautiful example under the UDB Editor (I wrote about it in the article that started the whole cycle). But if you work with a search engine a lot, then there are still examples for the Datapath Config Tool, which is why I did the previous article so that everyone would understand how to use this tool. And the wonderful page on which the mass of examples is collected, is located here .
On this page are developments made by third-party developers, but verified by Cypress. That is, just what we need: we are also third-party developers, but we want to learn from something that is precisely verified. Let's look at an example by which I found this page - the hardware square root calculator. End users include it in the signal processing path, throwing the component onto the circuit. In this example, we will practice analyzing such a code, and then everyone will be able to embark on an independent voyage. So, the necessary example can be downloaded by reference .
Inspect it. There are examples (which everyone will consider independently) and there are libraries located in the \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib directory.
For each type (integer or with a fixed point) and for each digit capacity there is its own solution. This we should note. Versatility is good when developing in the UDB Editor, but when developing using the Datapath Edit Tool, as you can see, people suffer like this. Do not be afraid if you do not work out universally (but if it works out, all the better).
At the top level (circuit design), I will not dwell, we are studying not working with PSoC, but working with UDB. Let's see a variant of medium complexity - 16 bit, but integer. It is located in the CJCU_B_Isqrt16_v1_0 directory.
The first thing to do is reveal the transition graph of the firmware automaton. Without it, we won’t even guess what kind of square root algorithm is used, since Google offers several fundamentally different algorithms to choose from.
So far, nothing is clear, but it is predictable. Need to add more information. We look at the coding of states. It is striking that they are not encoded in the usual incremental binary code.
I have already mentioned such an approach in my articles, but I have never used it in concrete examples. I recall that the dynamic configuration memory of the ALU has only three address inputs. That is, the ALU can perform one of eight operations. If the state of the automaton is greater, then the rule “for each state has its own operation” becomes impracticable. Therefore, the states are selected in which the operations for the ALU are identical, they have three bits supplied to the RAM address of the dynamic configuration (usually the least significant ones), are encoded in the same way, and the rest are different. How to make such a solitaire is a developer’s problem. The developers of the studied code have been folded exactly as shown above.
We add this information to the graph, plus we paint in similar state colors that perform the same function in the ALU.
No patterns have not yet manifested, but continue to open the graph. Open the Datapath Edit Tool and learn the logic already in it.
We draw attention to the fact that we have two Datapath blocks, connected in a chain. When we do something of our own, we might also need this (although the Datapath Edit Tool can create already chained blocks, so it's not a big deal):
When reading (and filling) the column corresponding to the ALU, always open the document with the following pattern:
True, the developers of this example took care of us and filled in the comment fields. Now we can use them to understand what is set up. At the same time, we note for ourselves that writing comments is always useful both for those who will accompany the code, and for us, when in six months we will forget about it.
Look at the X000 code corresponding to states 0 and 12:
From the comment it is already clear what is there (the contents of register D0 are copied to register A0, and the contents of D1 are copied to register A1. Knowing this, we train our intuition for the future and find a similar entry in the settings fields:
In the same place, we see that the ALU operates in the PASS mode, the shift register is also PASS , so no other actions are actually performed.
Along the way, we look at the Verilog text and see where the value of the registers D0 and D1 equals:
If desired, the same can be seen in the Datapath Config Tool by selecting the View-> Initial Register Values menu:
For viewing it is more convenient to analyze Verilog code directly, to create your own version - work through the editor, so as not to keep in mind the syntax.
Similarly, parse (first peeping in the comments) all the other functions of the ALU:
We remake the transition graph of the automaton in view of the new knowledge:
Something is already looming, but so far I can not put with confidence on this graph any of the algorithms found by Google. Rather, about some you can confidently say that it is not they, but even on the plausible to the end I still can not give a confident answer that it is they. Confused by the active use of registers FIFO F0 and F1. Generally, in the file
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
you can see that F1 is used to pass the argument and return the result:
Same text:
void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); } But one argument and one result. Why so many appeals to the FIFO in the course of work? And what have FIFO0? Cut me into pieces, and it seems that the authors took advantage of the regime that occurred in the translations of the documentation, when instead of a full-fledged FIFO, this block acted as a single register. Suppose the authors decided to expand the register set. If this is so, then their methodology will be useful to us in our practical work, let's study the details. In fact, the documentation tells about different approaches to working with FIFO. It is possible - so, it is possible - so, and it is possible - commercials. And no specifics. Again we have a chance to learn advanced foreign practical experience. What do authors do with FIFO?
First, here are the signal assignments:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12); Secondly, here is the connection to Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn), From the description of the controller is not particularly clear what it all means. But from Application Note I found out that this is the fault of all this:
By the way, precisely because of this setting, this block cannot be described using the UDB Editor. When these control bits are in the ON state, the FIFO can work for different sources and receivers. If Dx_LOAD is equal to one, then Fx is exchanged with the system bus, if zero, then with the register selected here:
It turns out that F0 always exchanges with the register A0, and F1 in states 12 and 0 - with the system bus (for unloading the result and loading the argument), in the other states - with A1.
Further, from the Verilog code, we found out that in F0 the data will be loaded in states 1 and 4, and in F1 - in states 1, 3, 9, 11.
Add the knowledge to the graph. To avoid confusion in the sequence of operations, it is also time to replace the assignment mark “a la UDB Editor” with Verilog arrows to emphasize that the source is the signal value that he had before entering the block.
From the point of view of the analysis of the algorithm, everything is already clear. Before us is a modification of this algorithm:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; } Only in relation to our system, it will look more like this:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; } States 4 and 10 explicitly encode the string:
res >>= 1; for different branches.
The string is:
one >>= 2; clearly coded with either a pair of states 6 and 7, or a pair of states 9 and 7. So far I want to exclaim: “Well, the authors are the inventors!”, but very soon it becomes clear why there is such complexity with two branches and bypass).
State 2 encodes a conditional transition. State 7 encodes the loop statement. The comparison operation in step 2 is very expensive. In general, on most steps, the register A0 contains the variable one. But in step 1, the variable one is unloaded into F0, and instead the value res + one is loaded, then in step 2 subtraction is performed for the purpose of comparison, and in steps 3 and 8 it is restored to the value one . Why in step 4 A0 is again copied to F0, I did not understand. Perhaps this is some kind of rudiment.
It remains to figure out who res here, and who - op . We know that the condition compares op and the sum of res + one. At state 1, A0 ( one ) and A1 are added. So A1 is res . It turns out that in the state of 11 A1 - also res , and that he will fall into F1, fed to the output of the function. F1 in state 1 is clearly op . I propose to introduce color differentiation of
Actually, the whole truth is revealed. We see how A1 changes temporarily with F1 for comparison and computation, as the same difference is used for comparison (in fact, generation of bit C) and for participation in the formula. We even see why the empty space (traversal) in the C algorithm is encoded with a long branch of the automaton transition graph (in this branch, the registers are exchanged, identical to the exchange that takes place in the main code branch). We see everything.
The only question that does not stop torturing me is how the authors switched the FIFO to single-byte mode? Documentation says that for this you need to raise the CLR bits in the Auxiliary Control register to one, but I don’t see that the API has such records. Perhaps someone will understand this and write in the comments.
Well, and develop something of your own - in the reverse order, using the acquired skills.
Conclusion
For the development of skills to develop "firmware" based on UDB is useful not only to read the documentation, but also to draw inspiration from other people's developments. The code attached to PSoC Creator can be useful as a reference book, and the behavioral models supplied by the compiler will help to better understand what was meant in the documentation. The article also provides a link to a set of examples from third-party manufacturers and shows the process of analyzing one of these examples.
On this cycle of author's articles on working with UDB can be considered complete. I would be glad if he helped someone to gain knowledge useful in practice. There are still a couple of translations of documentation ahead, but statistics show that almost no one reads them. They are planned cleanly so as not to throw the topic in half a word.
Source: https://habr.com/ru/post/449960/
All Articles