5 ways to deploy PHP code in terms of hayload
If the highload were taught at school, there would be such a task in the textbook on this subject. “The N social network has 2,000 servers, on which there are 150,000 files of 900 MB of PHP code and a staging cluster for 50 machines. The code is deployed to servers 2 times a day, the staging cluster code is updated every few minutes, and there is also “hotfixes” - small sets of files that are laid out out of turn on all or on a dedicated part of servers, without waiting for the full calculation. Question: are such conditions considered a highload and how are they deployed? Write at least 5 deployment options. ” We can only dream about a task book on a highload, but now we know that Yuri Nasretdinov ( youROCK ) would definitely have solved this problem and received a “top five”.
Yuri didn’t stop at a simple solution, but additionally gave a report in which he revealed the topic of the concept of “deploy code”, told about classic and alternative solutions of large-scale code deployment in PHP, analyzed their performance and presented a self-writing system of MDK deployment.
In English, the term “deploy” means bringing the troops on alert, and in Russian we sometimes say “pour code into battle”, which means the same thing. You take the code in the already compiled or in the original, if it is PHP, form, upload to servers that serve user traffic, and then, with magic, in some way, switch the load from one version of the code to another. All this is included in the concept of "code deployment".
Deploy process usually consists of several stages.
')
After everything is collected, the phase of the deployment itself begins - uploading the code to the production servers . It is about this phase on the example of Badoo and will be discussed.
If you have a file with a file system image, then how to mount it? In Linux, you need to create an intermediate Loop device , attach a file to it, and after that you can already mount this block device.
A loop device is a crutch that Linux needs to mount a file system image. There are operating systems in which this crutch is not required.

How does the deployment process happen with the help of files, which we also call loops for simplicity? There is a directory in which the source code and automatically generated content are located. We take an empty image of the file system - now it is EXT2, and earlier we used ReiserFS. Mount an empty file system image in a temporary directory, copy all the contents there. If we don’t need production to get something, then we don’t copy everything. After that, unmount the device, and get an image of the file system in which the necessary files are located. Next, we archive the image and upload it to all servers , unzip it and mount it.
To begin with, let’s thank Richard Stallman - without his license, there wouldn’t be a majority of the utilities that we use.

I divided the methods of PHP code deployment into 4 categories.
Each method has both advantages and disadvantages, because of which we refused them. Consider these 4 ways in more detail.
I chose SVN not by chance - according to my observations, in such a form deploy exists exactly in the case of SVN. The system is quite lightweight , it allows you to quickly and easily deploy it - just run svn up and everything is ready.
But this method has one big disadvantage: if you do svn up, and in the process of updating the source code, when new requests come from the repository, they will see the state of the file system, which did not exist in the repository. You will have some new files, and some old ones - this is a non-atomic way of deployment , which is not suitable for high loads, but only for small projects. Despite this, I know projects that are still so deplorable, and so far everything is working for them.
There are two options for how to do this: upload files using the utility directly to the server and upload “on top” to update.
Since you first completely fill all the code into a directory that does not already exist on the server, and only then switch traffic, this method is atomic - no one sees the intermediate state. In our case, creating 150,000 files and deleting the old directory, in which there are also 150,000 files, creates a heavy load on the disk subsystem . We have very hard drives, and the server doesn’t feel very good after such an operation for about a minute. Since we have 2000 servers, it takes 2000 MB to fill up 2000 times.
This scheme can be improved by first pouring on some number of intermediate servers, for example, 50, and then adding them to the rest. This solves possible problems with the network, but the problem of creating and deleting a huge number of files does not disappear anywhere.
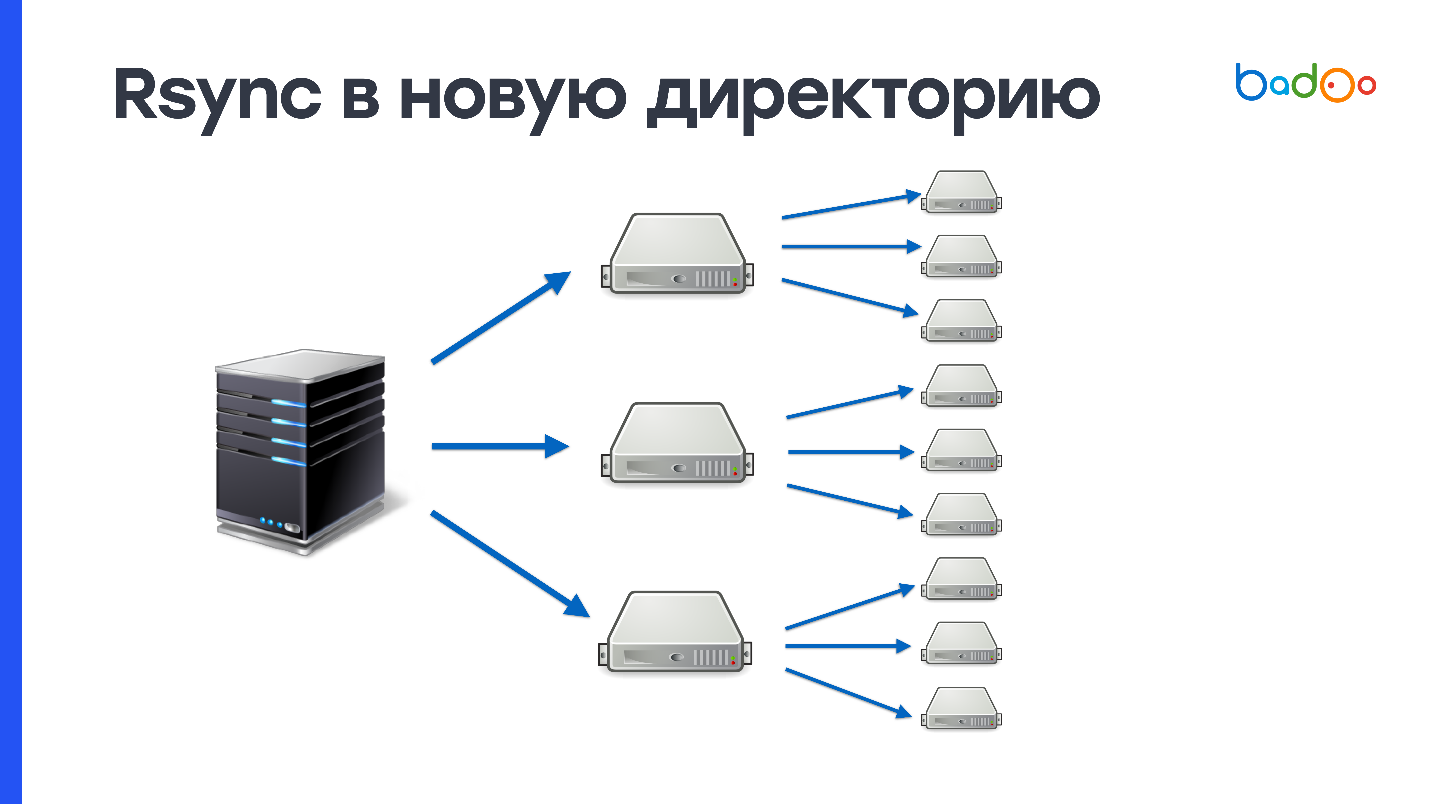
If you used rsync, you know that this utility can not only fill directories, but also update existing ones. Sending only changes is a plus, but since we upload changes to the same directory in which we serve the combat code, there will also be some intermediate state there - this is a minus.
Posting changes works like this. Rsync lists the files on the server side, from which it is deployed, and on the receiving side. After that, it counts stat from all files and sends the entire list to the receiving side. On the server from which it is deployed, the difference between these values is considered, and it is determined which files should be sent.
In our conditions, this process takes about 3 MB of traffic and 1 second of CPU time . It seems that it is a little, but we have 2000 servers, and everything turns out at least one minute of CPU time. This is not such a fast way, but definitely better than sending it entirely through rsync. It remains to somehow solve the problem of atomicity and will be almost perfect.
Whatever single file you upload, it is relatively easy to do with BitTorrent or the UFTP utility. One file is easier to unpack, you can atomically replace it in Unix, and it is easy to check the integrity of the file generated on the build server and delivered to the end machines by calculating the MD5 or SHA-1 amounts from the file (in the case of rsync, you do not know what is on the end servers ).
For hard drives, sequential recording is a big plus - a 900 MB file for an unallocated hard drive will be recorded in about 10 seconds. But you still need to record these same 900 MB and transfer them over the network.
This Open Source utility was originally designed to transfer files over the network with long delays, for example, through a network based on satellite communications. But UFTP turned out to be suitable for uploading files to a large number of machines, because it works via UDP protocol based on Multicast. One Multicast address is created, all the machines that want to receive the file subscribe to it, and the switches ensure delivery of the package copies to each machine. So we shift the burden of data transmission to the network. If your network can handle it, then this method works much better than BitTorrent.
You can try this open source utility on your cluster. Despite the fact that it works via the UDP protocol, it has a NACK - negative acknowledgment mechanism, which forces to re-send packets lost during delivery. This is a reliable way to deploy .
tar.gz
An option that combines the disadvantages of both approaches. Not only do you have to write 900 MB to the disk sequentially, after that you need to randomly read and write once again to write the same 900 MB and create 150,000 files. The performance of this method is even worse than rsync.
phar
PHP supports archives in the format of phar (PHP Archive), is able to give their contents and include files. But not all projects are easy to put in one phar - code adaptation is needed. Just because the code from this archive does not work. In addition, one file cannot be changed in the archive ( Yuri from the future: in theory it is still possible ), it is required to reload the entire archive. Also, despite the fact that the phar-archives work with OPCache, when the cache is deployed, you need to reset it, because otherwise there will be garbage in the OPCache from the old phar-file.
hhbc
This method is native for HHVM - HipHop Virtual Machine and it is used by Facebook. This is something like a phar-archive, but it does not contain the source code, but the compiled byte-code of the HHVM virtual machine - a PHP interpreter from Facebook. It is forbidden to change anything in this file: you cannot create new classes, functions and some other dynamic features in this mode are disabled. Due to these limitations, the virtual machine can use additional optimizations. According to Facebook, this can bring up to 30% of the speed of code execution. This is probably a good option for them. It is also impossible to change one file here ( Yuri from the future: in fact, it is possible, because it is sqlite-base ). If you want to change one line, you need to redo the entire archive again.
For this method it is forbidden to use eval and dynamic include. This is true, but not quite. Eval can be used, but if it does not create new classes or functions, and you cannot include include from directories that are outside this archive.
loop
This is our old version, and it has two big advantages. First, it looks like a regular directory . You are mounting the loop, and for the code it doesn't matter - it works with files, both on the develop-environment and on the production-environment. The second is that the loop can be mounted in read and write mode, and you can change one file, if you need to change something urgently to production.
But the loop has cons. The first is that it works strangely with the docker. I will tell about it a bit later.
The second is if you use symlink on the last loop as a document_root, then you will have problems with OPCache. He is not very good at having symlink on the way, and starts to confuse which versions of the files to use. Therefore, OPCache has to be discarded during a delay.
Another problem is that superuser privileges are required to mount file systems. And you should not forget to mount them at the start / restart of the machine, because otherwise there will be an empty directory instead of the code.
If you create a docker-container and forward a folder inside it in which loops or other block devices are mounted, then two problems arise: the new mount points do not get inside the docker container, and those loops that were at the time of creation docker-container cannot be unmounted because they are occupied by the docker-container.
Naturally, this is generally incompatible with deployment, because the number of loop devices is limited, and it is unclear how the new code should fall into the container.
We tried to do strange things, for example, to raise a local NFS server or mount a directory using SSHFS, but for various reasons, this did not stick to us. As a result, we assigned rsync from the last “magnifying glass” to the real directory in cron, and it executed the command once a minute:
Here,
This method was suggested by Rasmus Lerdorf, the author of PHP, and he knows how to deploy.
How to make an atomic deployment, and in any of the ways that I talked about? Take symlink and write it as document_root. At any given time, symlink points to one of two directories, and you make rsync to a neighboring directory, that is, to the one in which the code does not point.
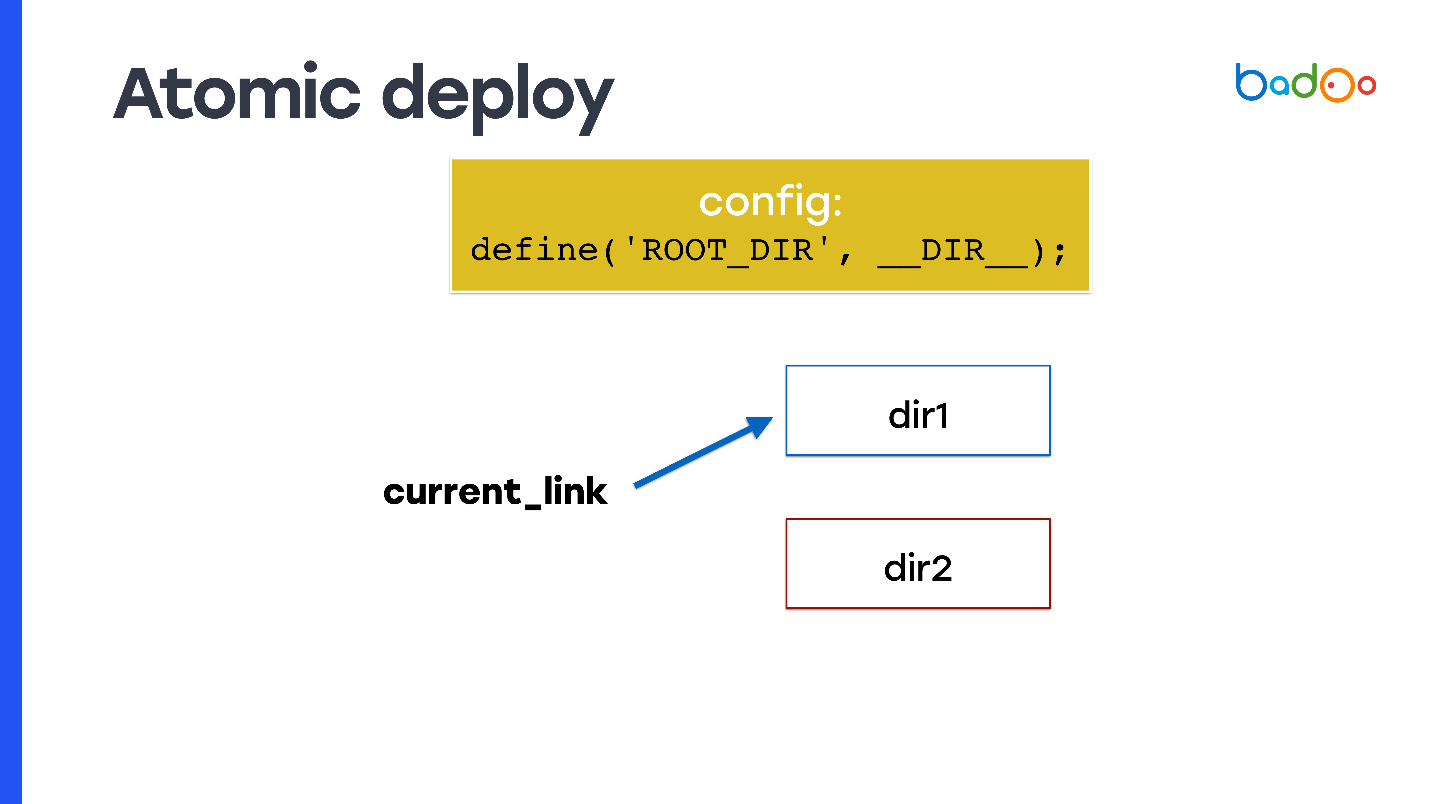
But the problem arises: the PHP code does not know in which of the directories it was launched. Therefore, you need to use, for example, a variable that you set somewhere at the beginning in the config - it will fix from which directory the code was run, and from which to add new files. In the slide, it is called
Use this constant when referring to all files within the code you use in production. So you get the property of atomicity: requests that arrive before you switch symlink continue to include files from the old directory in which you did not change anything, and new requests that came after switching symlink start working from the new directory and serviced new code.

But it needs to be written in the code. Not all projects are ready for this.
Rasmus suggests instead of manually modifying the code and creating constants, modify Apache a little bit, or use nginx.
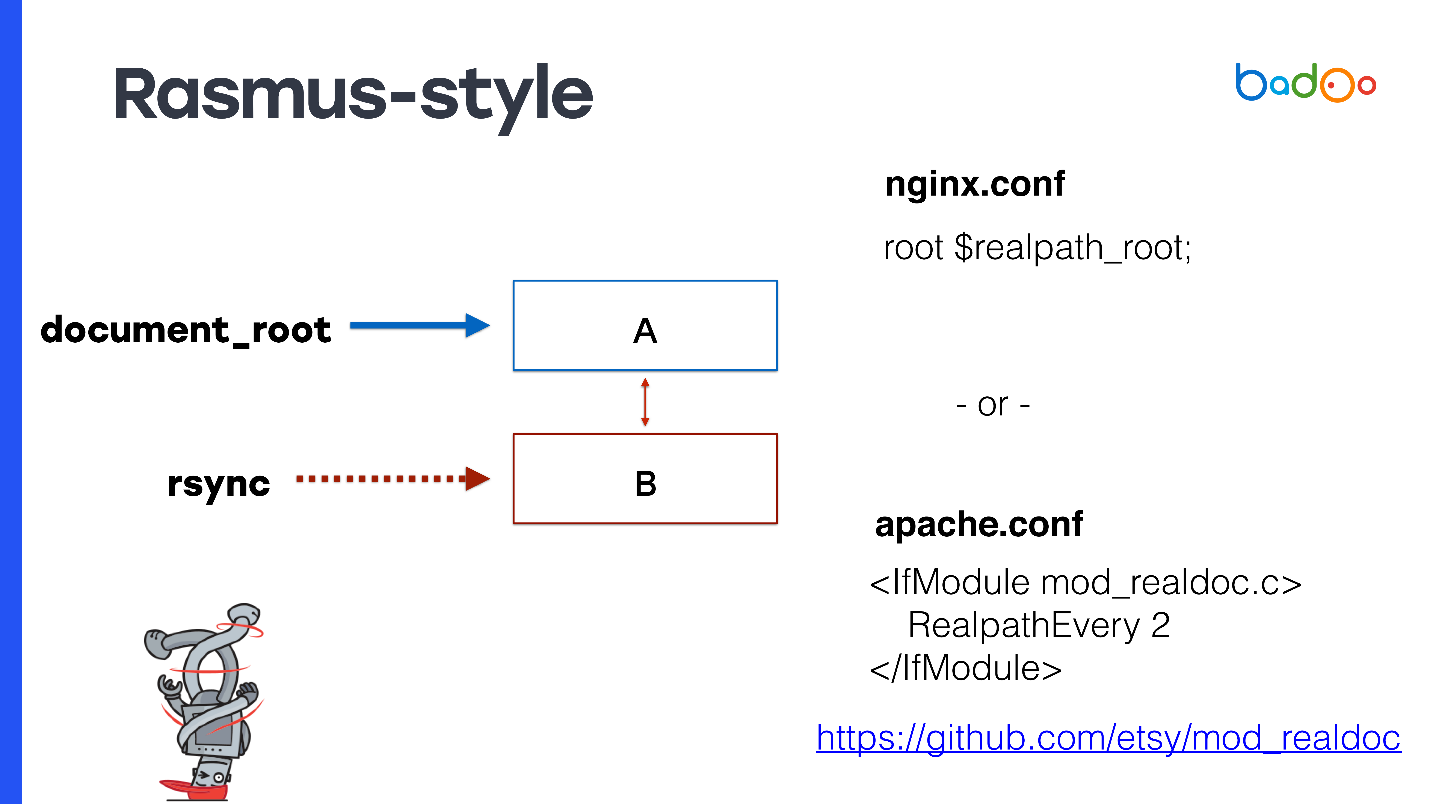
As document_root, specify the symlink for the latest version. If you have nginx, then you can register
This method has some interesting advantages - OPCache PHP already comes with real paths, they do not contain symlink. Even the very first file to which the request came will already be full, and there will be no problems with OPCache. Since document_root is used, this works with any PHP project. You do not need to adapt anything.
There is no need for fpm reload, it is not necessary to reset OPCache during a deployment, which is why the processor server is heavily loaded, because it has to re-parse all the files again. In my experiment, the OPCache reset increased the CPU consumption by about 2-3 times by about half a minute. It would be nice to reuse it and this method allows you to do it.
Now the cons. Since you do not reuse OPCache, and you have 2 directories, you need to store copies of the file in memory for each directory - under OPCache, 2 times more memory is required.
There is another limitation that may seem strange - you can not deploy more often than once in max_execution_time . Otherwise there will be the same problem, because while rsync is going to one of the directories, requests from it can still be processed.
If you use Apache for some reason, then a third-party module is needed, which Rasmus also wrote.
Rasmus says the system is good and I recommend it to you too. For 99% of projects, it is suitable, both for new projects and for existing ones. But, of course, we are not like that and decided to write our decision.
Basically, our requirements are no different from the requirements for most web projects. We just want fast deploying on styling and production, low resource consumption , reusable OPCache and fast rollback.
But there are two more requirements that may differ from the rest. First of all, it is an opportunity to apply patches atomically . We call patches changes in one or several files that rule something in production. We want to do it quickly. Basically, the system that Rasmus offers is coping with the task of patches.
We also have CLI scripts that can work for several hours , and they still need to work with a consistent version of the code. In this case, these solutions, unfortunately, either do not suit us, or we must have very many directories.
Possible solutions:
Here N is the number of calculations that occur in a few hours. We can have dozens of them, which means having to spend a very large amount of space for additional copies of the code.
Therefore, we invented a new system and called it MDK. It stands for Multiversion Deployment Kit - a multi-version deployment tool. We made it based on the following prerequisites.
Took the tree storage architecture from Git. We need to have a consistent version of the code in which the script works, that is, snapshots are needed. Snapshots are supported by LVM, but there they are implemented inefficiently, with experimental file systems like Btrfs and Git. We took the implementation of snapshots from git.
Renamed all files from file.php to file.php. <Version>. Since all our files are stored simply on disk, then if we want to store several versions of the same file, we must add a suffix with the version.
I love Go, so for speed wrote a system on Go.
We took the idea of snapshots from Git. I simplified it a little bit and tell you how it is implemented in MDK.
There are two types of files in MDK. The first is maps. The pictures below are green and correspond to the directories in the repository. The second type is the files themselves, which are in the same place as usual, but with a suffix in the form of a file version. Files and maps are versioned based on their content, in our case simply MD5.
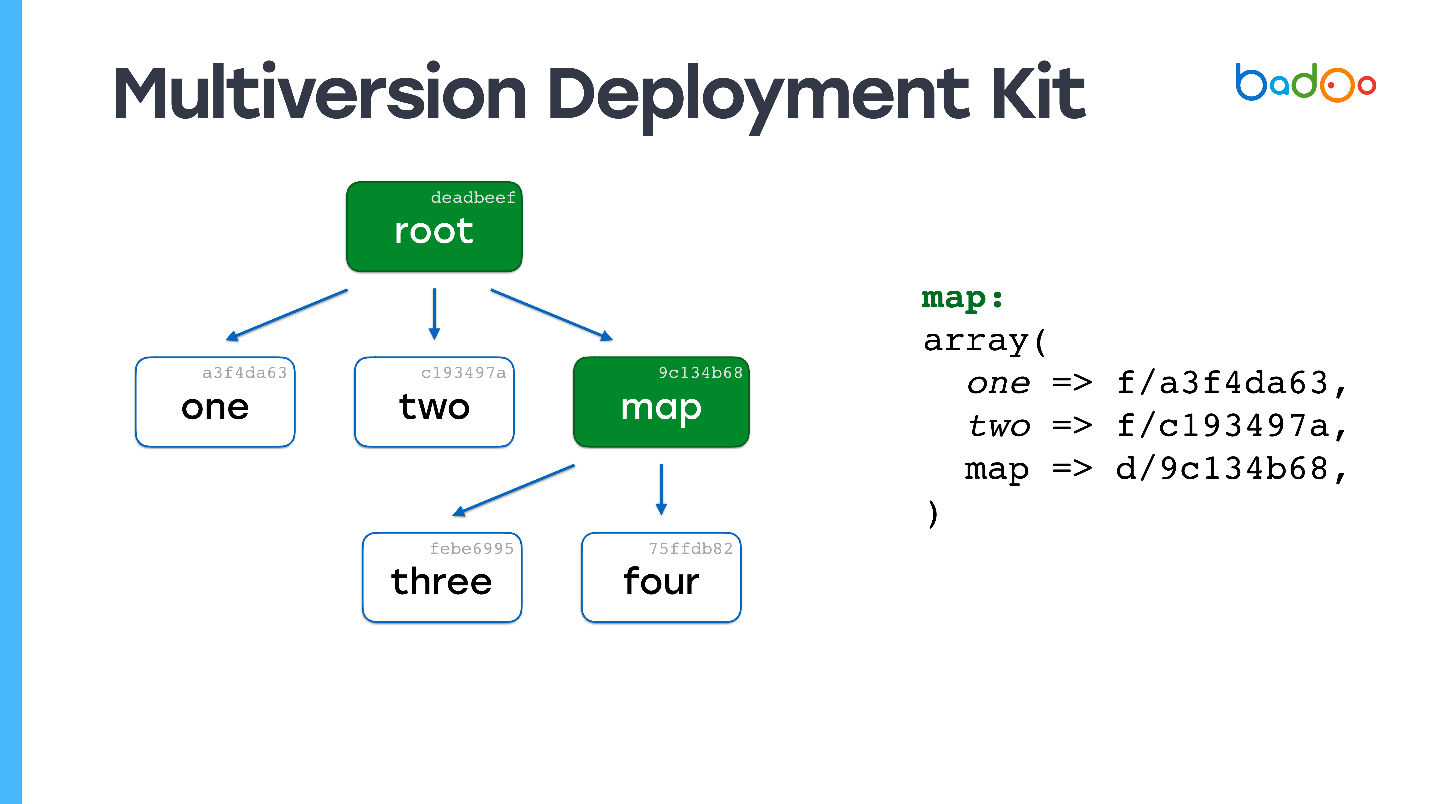
Suppose we have a certain hierarchy of files in which the root map refers to certain versions of files from other maps , and they, in turn, refer to other files and maps, and fix certain versions. We want to change some file.

Perhaps you have already seen a similar picture: we change the file at the second nesting level, and in the corresponding map — map *, the three * version of the file is updated, its contents are modified, the version changes — and the version also changes in the root map. If we change something, we always get a new root card, but all files that we have not changed are reused.
Links remain on the same files as they were. This is the basic idea of creating snapshots in any way, for example, in ZFS it is implemented in about the same way.

On the disk we have: symlink to the most recent root card — the code that will be served from the web, several versions of root maps, several files, possibly with different versions, and in the subdirectories there are maps for the corresponding directories.
I foresee the question: " And how do you handle this web request? What files will the custom code come in? "
Yes, I deceived you - there are also files without versions, because if you receive a request for index.php, and you don’t have it in the directory, then the site will not work.

All PHP files have files that we call stubs , because they contain two lines: require from the file in which the function is declared, which can work with these cards, and require from the correct version of the file.
It is done this way, and not with the symlinks to the latest version, because if you use b.php without a version from the a.php file, then since it is written to require_once, the system will remember which root card it started from, it will use it, and get a consistent version of the files.
For the rest of the files, we just have symlink to the latest version.
The model is very similar to git push.
Suppose there is a file named "one" on the server. We send to him the root card.

In the root map, intermittent arrows indicate links to files that we do not have. We know their names and versions because they are in the map. We request them from the server. The server sends, and it turns out that one of the files is also a map.
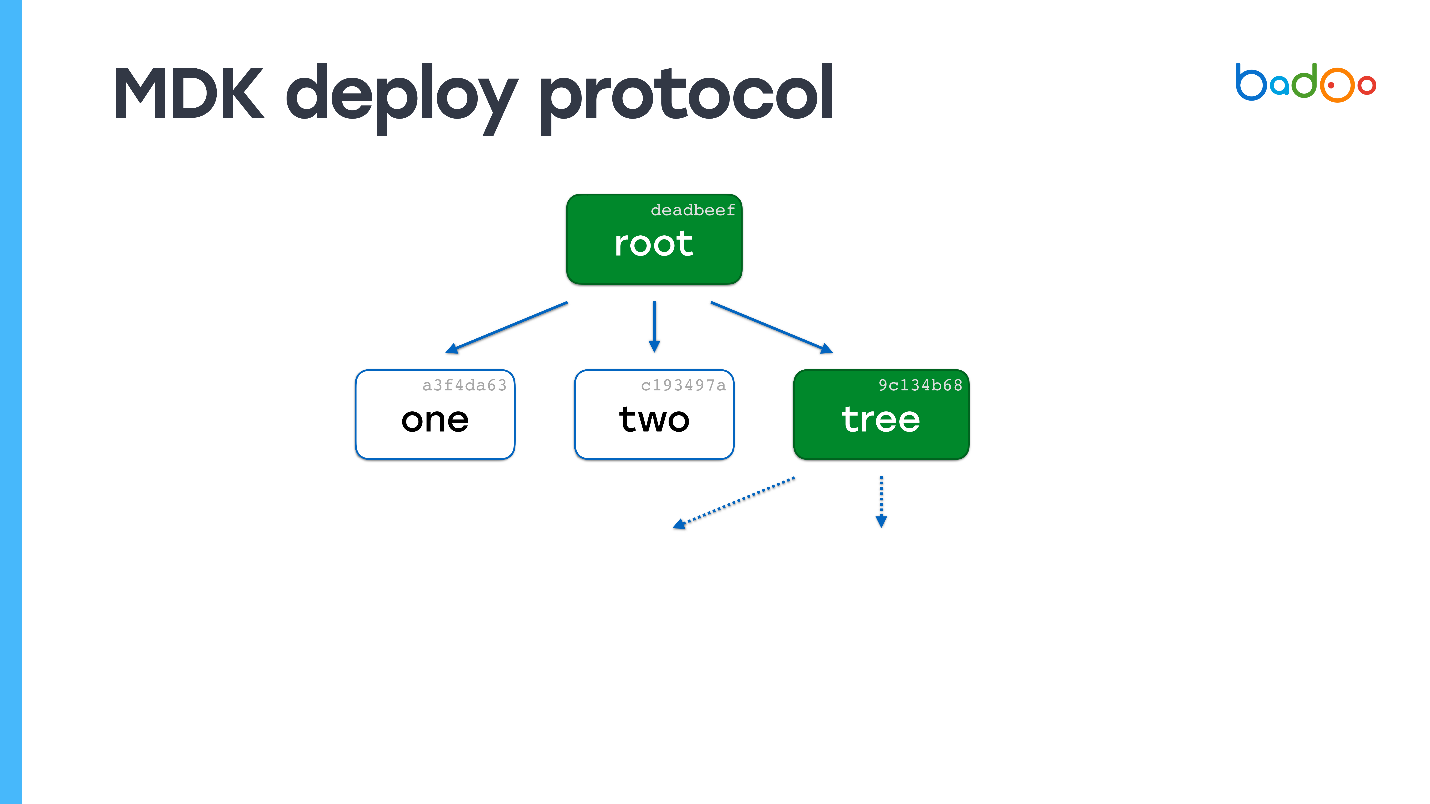
We look - we do not have a single file at all. Again we request files that are missing. The server sends them. No more cards left - the deployment process is complete.
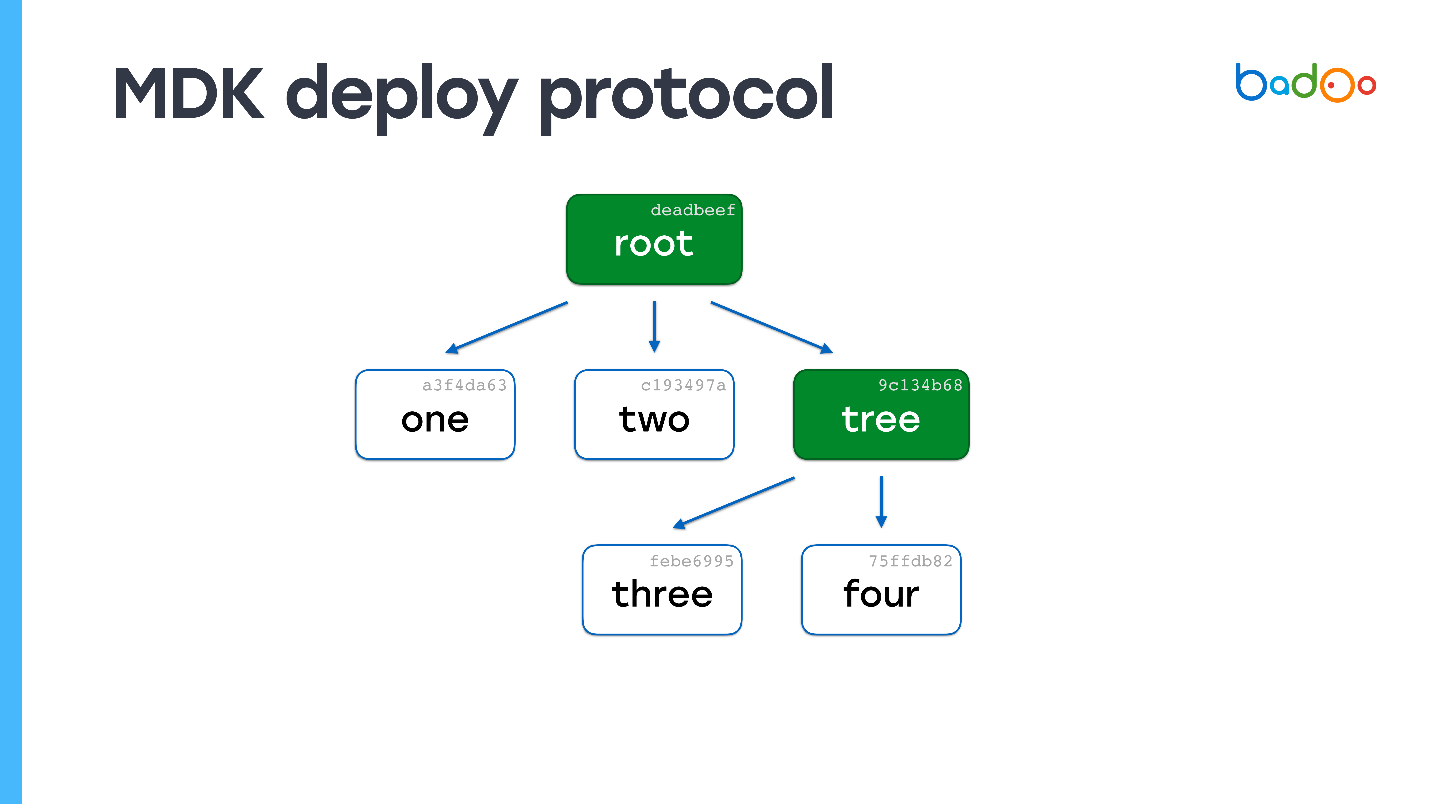
You can easily guess what will happen if the files are 150,000, and one has changed. We will see in the root map that one card is missing, go to the level of nesting and get the file. In terms of computational complexity, the process hardly differs from copying files directly, but it also preserves consistency and code snapshots.
MDK has no minuses :) It allows you to quickly and atomically deploy small changes , and scripts to work for days , because we can keep all the files that are deposited during the week. They will occupy an adequate amount of space. You can also reuse OPCache, and the CPU eats almost nothing.
Monitoring is quite difficult, but possible . All files are versioned by content, and you can write a cron that will go through all the files and check the name and content. You can also check that the root map refers to all files, that there are no broken links in it. Moreover, the integrity is checked during the delay.
You can easily roll back the changes , because all the old maps are in place. We can just throw a card, everything will be there right away.
For me, plus the fact that MDK is written in Go means it works fast.
I deceived you again, there are still minuses. For the project to work with the system, a significant modification of the code is required, but it is simpler than it might seem at first glance. The system is very complex , I would not recommend it to implement, if you do not have such requirements as that of Badoo. Also, anyway, sooner or later the place runs out, so the Garbage Collector is required .
We wrote special utilities to edit the files — real ones, not stubs, for example, mdk-vim. You specify a file, it finds the version you need and edits it.
We have 50 servers on the staging, on which we deploy in 3-5 seconds . Compared to everything except rsync, this is very fast. On production we deploy about 2 minutes , small patches - 5-10 s .
If for some reason you have lost the entire folder with the code on all servers (which should never happen :)) then the process of full filling takes about 40 minutes . We have this happened once, though at night in a minimum of traffic. Therefore, no one was hurt. The second file was on a pair of servers for 5 minutes, so it is not worthy of mention.
The system is not in Open Source, but if you're interested, write in the comments - maybe we will post it ( Yuri from the future: the system is still not in Open Source at the time of this writing ).
Listen to Rasmus, he is not lying . In my opinion, its rsync method in conjunction with realpath_root is the best, although loops also work quite well.
Think with your head : look at what exactly your project needs, and do not try to create a spacecraft where there is enough "corncob". But if all the same your requirements are similar, then a system similar to MDK will suit you.
Yuri didn’t stop at a simple solution, but additionally gave a report in which he revealed the topic of the concept of “deploy code”, told about classic and alternative solutions of large-scale code deployment in PHP, analyzed their performance and presented a self-writing system of MDK deployment.
The concept of "warm code"
In English, the term “deploy” means bringing the troops on alert, and in Russian we sometimes say “pour code into battle”, which means the same thing. You take the code in the already compiled or in the original, if it is PHP, form, upload to servers that serve user traffic, and then, with magic, in some way, switch the load from one version of the code to another. All this is included in the concept of "code deployment".
Deploy process usually consists of several stages.
')
- Getting the code from the repository , in any way you want: clone, fetch, checkout.
- Build - build . For PHP code, the build phase may be missing. In our case, this is, as a rule, autogeneration of translation files, uploading static files to CDNs and some other operations.
- Delivery to end servers - deployment.
After everything is collected, the phase of the deployment itself begins - uploading the code to the production servers . It is about this phase on the example of Badoo and will be discussed.
Old Depoo System in Badoo
If you have a file with a file system image, then how to mount it? In Linux, you need to create an intermediate Loop device , attach a file to it, and after that you can already mount this block device.
A loop device is a crutch that Linux needs to mount a file system image. There are operating systems in which this crutch is not required.
How does the deployment process happen with the help of files, which we also call loops for simplicity? There is a directory in which the source code and automatically generated content are located. We take an empty image of the file system - now it is EXT2, and earlier we used ReiserFS. Mount an empty file system image in a temporary directory, copy all the contents there. If we don’t need production to get something, then we don’t copy everything. After that, unmount the device, and get an image of the file system in which the necessary files are located. Next, we archive the image and upload it to all servers , unzip it and mount it.
Other existing solutions
To begin with, let’s thank Richard Stallman - without his license, there wouldn’t be a majority of the utilities that we use.
I divided the methods of PHP code deployment into 4 categories.
- Based on version control system : svn up, git pull, hg up.
- On the basis of the utility rsync - in a new directory or "on top".
- A single file - no matter how: phar, hhbc, loop.
- A special way that Rasmus Lerdorf suggested is rsync, 2 directories and realpath_root .
Each method has both advantages and disadvantages, because of which we refused them. Consider these 4 ways in more detail.
Depla based on version control system svn up
I chose SVN not by chance - according to my observations, in such a form deploy exists exactly in the case of SVN. The system is quite lightweight , it allows you to quickly and easily deploy it - just run svn up and everything is ready.
But this method has one big disadvantage: if you do svn up, and in the process of updating the source code, when new requests come from the repository, they will see the state of the file system, which did not exist in the repository. You will have some new files, and some old ones - this is a non-atomic way of deployment , which is not suitable for high loads, but only for small projects. Despite this, I know projects that are still so deplorable, and so far everything is working for them.
Rsync based warmup
There are two options for how to do this: upload files using the utility directly to the server and upload “on top” to update.
rsync to a new directory
Since you first completely fill all the code into a directory that does not already exist on the server, and only then switch traffic, this method is atomic - no one sees the intermediate state. In our case, creating 150,000 files and deleting the old directory, in which there are also 150,000 files, creates a heavy load on the disk subsystem . We have very hard drives, and the server doesn’t feel very good after such an operation for about a minute. Since we have 2000 servers, it takes 2000 MB to fill up 2000 times.
This scheme can be improved by first pouring on some number of intermediate servers, for example, 50, and then adding them to the rest. This solves possible problems with the network, but the problem of creating and deleting a huge number of files does not disappear anywhere.
rsync "on top"
If you used rsync, you know that this utility can not only fill directories, but also update existing ones. Sending only changes is a plus, but since we upload changes to the same directory in which we serve the combat code, there will also be some intermediate state there - this is a minus.
Posting changes works like this. Rsync lists the files on the server side, from which it is deployed, and on the receiving side. After that, it counts stat from all files and sends the entire list to the receiving side. On the server from which it is deployed, the difference between these values is considered, and it is determined which files should be sent.
In our conditions, this process takes about 3 MB of traffic and 1 second of CPU time . It seems that it is a little, but we have 2000 servers, and everything turns out at least one minute of CPU time. This is not such a fast way, but definitely better than sending it entirely through rsync. It remains to somehow solve the problem of atomicity and will be almost perfect.
Warm one file
Whatever single file you upload, it is relatively easy to do with BitTorrent or the UFTP utility. One file is easier to unpack, you can atomically replace it in Unix, and it is easy to check the integrity of the file generated on the build server and delivered to the end machines by calculating the MD5 or SHA-1 amounts from the file (in the case of rsync, you do not know what is on the end servers ).
For hard drives, sequential recording is a big plus - a 900 MB file for an unallocated hard drive will be recorded in about 10 seconds. But you still need to record these same 900 MB and transfer them over the network.
Lyrical digression about UFTP
This Open Source utility was originally designed to transfer files over the network with long delays, for example, through a network based on satellite communications. But UFTP turned out to be suitable for uploading files to a large number of machines, because it works via UDP protocol based on Multicast. One Multicast address is created, all the machines that want to receive the file subscribe to it, and the switches ensure delivery of the package copies to each machine. So we shift the burden of data transmission to the network. If your network can handle it, then this method works much better than BitTorrent.
You can try this open source utility on your cluster. Despite the fact that it works via the UDP protocol, it has a NACK - negative acknowledgment mechanism, which forces to re-send packets lost during delivery. This is a reliable way to deploy .
Deploy options in one file
tar.gz
An option that combines the disadvantages of both approaches. Not only do you have to write 900 MB to the disk sequentially, after that you need to randomly read and write once again to write the same 900 MB and create 150,000 files. The performance of this method is even worse than rsync.
phar
PHP supports archives in the format of phar (PHP Archive), is able to give their contents and include files. But not all projects are easy to put in one phar - code adaptation is needed. Just because the code from this archive does not work. In addition, one file cannot be changed in the archive ( Yuri from the future: in theory it is still possible ), it is required to reload the entire archive. Also, despite the fact that the phar-archives work with OPCache, when the cache is deployed, you need to reset it, because otherwise there will be garbage in the OPCache from the old phar-file.
hhbc
This method is native for HHVM - HipHop Virtual Machine and it is used by Facebook. This is something like a phar-archive, but it does not contain the source code, but the compiled byte-code of the HHVM virtual machine - a PHP interpreter from Facebook. It is forbidden to change anything in this file: you cannot create new classes, functions and some other dynamic features in this mode are disabled. Due to these limitations, the virtual machine can use additional optimizations. According to Facebook, this can bring up to 30% of the speed of code execution. This is probably a good option for them. It is also impossible to change one file here ( Yuri from the future: in fact, it is possible, because it is sqlite-base ). If you want to change one line, you need to redo the entire archive again.
For this method it is forbidden to use eval and dynamic include. This is true, but not quite. Eval can be used, but if it does not create new classes or functions, and you cannot include include from directories that are outside this archive.
loop
This is our old version, and it has two big advantages. First, it looks like a regular directory . You are mounting the loop, and for the code it doesn't matter - it works with files, both on the develop-environment and on the production-environment. The second is that the loop can be mounted in read and write mode, and you can change one file, if you need to change something urgently to production.
But the loop has cons. The first is that it works strangely with the docker. I will tell about it a bit later.
The second is if you use symlink on the last loop as a document_root, then you will have problems with OPCache. He is not very good at having symlink on the way, and starts to confuse which versions of the files to use. Therefore, OPCache has to be discarded during a delay.
Another problem is that superuser privileges are required to mount file systems. And you should not forget to mount them at the start / restart of the machine, because otherwise there will be an empty directory instead of the code.
Docker problems
If you create a docker-container and forward a folder inside it in which loops or other block devices are mounted, then two problems arise: the new mount points do not get inside the docker container, and those loops that were at the time of creation docker-container cannot be unmounted because they are occupied by the docker-container.
Naturally, this is generally incompatible with deployment, because the number of loop devices is limited, and it is unclear how the new code should fall into the container.
We tried to do strange things, for example, to raise a local NFS server or mount a directory using SSHFS, but for various reasons, this did not stick to us. As a result, we assigned rsync from the last “magnifying glass” to the real directory in cron, and it executed the command once a minute:
rsync /var/loop/<N>/ /var/www/ Here,
/var/www/ is the directory that is promoted to the container. But on machines with docker containers, we don’t need to run PHP scripts often, so the fact that rsync is not atomic suits us. But still this method is very bad, of course. I would like to make a deployment system that works well with docker.rsync, 2 directories and realpath_root
This method was suggested by Rasmus Lerdorf, the author of PHP, and he knows how to deploy.
How to make an atomic deployment, and in any of the ways that I talked about? Take symlink and write it as document_root. At any given time, symlink points to one of two directories, and you make rsync to a neighboring directory, that is, to the one in which the code does not point.
But the problem arises: the PHP code does not know in which of the directories it was launched. Therefore, you need to use, for example, a variable that you set somewhere at the beginning in the config - it will fix from which directory the code was run, and from which to add new files. In the slide, it is called
ROOT_DIR .Use this constant when referring to all files within the code you use in production. So you get the property of atomicity: requests that arrive before you switch symlink continue to include files from the old directory in which you did not change anything, and new requests that came after switching symlink start working from the new directory and serviced new code.
But it needs to be written in the code. Not all projects are ready for this.
Rasmus-style
Rasmus suggests instead of manually modifying the code and creating constants, modify Apache a little bit, or use nginx.
As document_root, specify the symlink for the latest version. If you have nginx, then you can register
root $realpath_root , Apache will need a separate module with settings that can be seen on the slide. It works like this - when a request arrives, nginx or Apache, once in a while, consider realpath () from the path, saving it from the symlinks, and pass this path as document_root. In this case, document_root will always point to the usual directory without symlinks, and your PHP code may not think about the directory from which it is called.This method has some interesting advantages - OPCache PHP already comes with real paths, they do not contain symlink. Even the very first file to which the request came will already be full, and there will be no problems with OPCache. Since document_root is used, this works with any PHP project. You do not need to adapt anything.
There is no need for fpm reload, it is not necessary to reset OPCache during a deployment, which is why the processor server is heavily loaded, because it has to re-parse all the files again. In my experiment, the OPCache reset increased the CPU consumption by about 2-3 times by about half a minute. It would be nice to reuse it and this method allows you to do it.
Now the cons. Since you do not reuse OPCache, and you have 2 directories, you need to store copies of the file in memory for each directory - under OPCache, 2 times more memory is required.
There is another limitation that may seem strange - you can not deploy more often than once in max_execution_time . Otherwise there will be the same problem, because while rsync is going to one of the directories, requests from it can still be processed.
If you use Apache for some reason, then a third-party module is needed, which Rasmus also wrote.
Rasmus says the system is good and I recommend it to you too. For 99% of projects, it is suitable, both for new projects and for existing ones. But, of course, we are not like that and decided to write our decision.
New system - MDK
Basically, our requirements are no different from the requirements for most web projects. We just want fast deploying on styling and production, low resource consumption , reusable OPCache and fast rollback.
But there are two more requirements that may differ from the rest. First of all, it is an opportunity to apply patches atomically . We call patches changes in one or several files that rule something in production. We want to do it quickly. Basically, the system that Rasmus offers is coping with the task of patches.
We also have CLI scripts that can work for several hours , and they still need to work with a consistent version of the code. In this case, these solutions, unfortunately, either do not suit us, or we must have very many directories.
Possible solutions:
- loop xN (-staging, -docker, -opcache);
- rsync xN (-production, -opcache xN);
- SVN xN (-production, -opcache xN).
Here N is the number of calculations that occur in a few hours. We can have dozens of them, which means having to spend a very large amount of space for additional copies of the code.
Therefore, we invented a new system and called it MDK. It stands for Multiversion Deployment Kit - a multi-version deployment tool. We made it based on the following prerequisites.
Took the tree storage architecture from Git. We need to have a consistent version of the code in which the script works, that is, snapshots are needed. Snapshots are supported by LVM, but there they are implemented inefficiently, with experimental file systems like Btrfs and Git. We took the implementation of snapshots from git.
Renamed all files from file.php to file.php. <Version>. Since all our files are stored simply on disk, then if we want to store several versions of the same file, we must add a suffix with the version.
I love Go, so for speed wrote a system on Go.
How the Multiversion Deployment Kit works
We took the idea of snapshots from Git. I simplified it a little bit and tell you how it is implemented in MDK.
There are two types of files in MDK. The first is maps. The pictures below are green and correspond to the directories in the repository. The second type is the files themselves, which are in the same place as usual, but with a suffix in the form of a file version. Files and maps are versioned based on their content, in our case simply MD5.
Suppose we have a certain hierarchy of files in which the root map refers to certain versions of files from other maps , and they, in turn, refer to other files and maps, and fix certain versions. We want to change some file.
Perhaps you have already seen a similar picture: we change the file at the second nesting level, and in the corresponding map — map *, the three * version of the file is updated, its contents are modified, the version changes — and the version also changes in the root map. If we change something, we always get a new root card, but all files that we have not changed are reused.
Links remain on the same files as they were. This is the basic idea of creating snapshots in any way, for example, in ZFS it is implemented in about the same way.
How MDK is on disk
On the disk we have: symlink to the most recent root card — the code that will be served from the web, several versions of root maps, several files, possibly with different versions, and in the subdirectories there are maps for the corresponding directories.
I foresee the question: " And how do you handle this web request? What files will the custom code come in? "
Yes, I deceived you - there are also files without versions, because if you receive a request for index.php, and you don’t have it in the directory, then the site will not work.
All PHP files have files that we call stubs , because they contain two lines: require from the file in which the function is declared, which can work with these cards, and require from the correct version of the file.
<?php require_once "mdk.inc"; require mdk_resolve_path("a.php"); It is done this way, and not with the symlinks to the latest version, because if you use b.php without a version from the a.php file, then since it is written to require_once, the system will remember which root card it started from, it will use it, and get a consistent version of the files.
For the rest of the files, we just have symlink to the latest version.
How to Deploy with MDK
The model is very similar to git push.
- We send the contents of the root card.
- On the receiving side, we look at which files are missing. Since the file version is determined by the content, we don’t need to download it a second time ( Yuri from the future: except for the case when a shortened MD5 collision happens, which did happen once in production ).
- We are requesting the missing file.
- We turn to the second point and continue in a circle.
Example
Suppose there is a file named "one" on the server. We send to him the root card.
In the root map, intermittent arrows indicate links to files that we do not have. We know their names and versions because they are in the map. We request them from the server. The server sends, and it turns out that one of the files is also a map.
We look - we do not have a single file at all. Again we request files that are missing. The server sends them. No more cards left - the deployment process is complete.
You can easily guess what will happen if the files are 150,000, and one has changed. We will see in the root map that one card is missing, go to the level of nesting and get the file. In terms of computational complexity, the process hardly differs from copying files directly, but it also preserves consistency and code snapshots.
MDK has no minuses :) It allows you to quickly and atomically deploy small changes , and scripts to work for days , because we can keep all the files that are deposited during the week. They will occupy an adequate amount of space. You can also reuse OPCache, and the CPU eats almost nothing.
Monitoring is quite difficult, but possible . All files are versioned by content, and you can write a cron that will go through all the files and check the name and content. You can also check that the root map refers to all files, that there are no broken links in it. Moreover, the integrity is checked during the delay.
You can easily roll back the changes , because all the old maps are in place. We can just throw a card, everything will be there right away.
For me, plus the fact that MDK is written in Go means it works fast.
I deceived you again, there are still minuses. For the project to work with the system, a significant modification of the code is required, but it is simpler than it might seem at first glance. The system is very complex , I would not recommend it to implement, if you do not have such requirements as that of Badoo. Also, anyway, sooner or later the place runs out, so the Garbage Collector is required .
We wrote special utilities to edit the files — real ones, not stubs, for example, mdk-vim. You specify a file, it finds the version you need and edits it.
MDK in numbers
We have 50 servers on the staging, on which we deploy in 3-5 seconds . Compared to everything except rsync, this is very fast. On production we deploy about 2 minutes , small patches - 5-10 s .
If for some reason you have lost the entire folder with the code on all servers (which should never happen :)) then the process of full filling takes about 40 minutes . We have this happened once, though at night in a minimum of traffic. Therefore, no one was hurt. The second file was on a pair of servers for 5 minutes, so it is not worthy of mention.
The system is not in Open Source, but if you're interested, write in the comments - maybe we will post it ( Yuri from the future: the system is still not in Open Source at the time of this writing ).
Conclusion
Listen to Rasmus, he is not lying . In my opinion, its rsync method in conjunction with realpath_root is the best, although loops also work quite well.
Think with your head : look at what exactly your project needs, and do not try to create a spacecraft where there is enough "corncob". But if all the same your requirements are similar, then a system similar to MDK will suit you.
We decided to return to this topic, which was discussed at HighLoad ++ and, perhaps, then did not receive due attention, because it was only one of many bricks to achieve high performance. But now we have a separate professional conference PHP Russia , completely dedicated to PHP. And here we will come off in full. We will talk in detail about performance , standards , and tools - a lot about that, including refactoring .
Subscribe to the Telegram channel with the updates of the conference program , and see you on May 17th.
Source: https://habr.com/ru/post/449916/
All Articles