ResNet50. Its implementation
Hello. The neural network library is described in my previous article . Here I decided to show how you can use the trained network from TF (Tensorflow) in your decision, and whether it is worth it.
Under the cut, there is a comparison with the original TF implementation, a demo image recognition application, and so ... conclusions. Who cares, please.
How ResNet works can be found, for example, here .
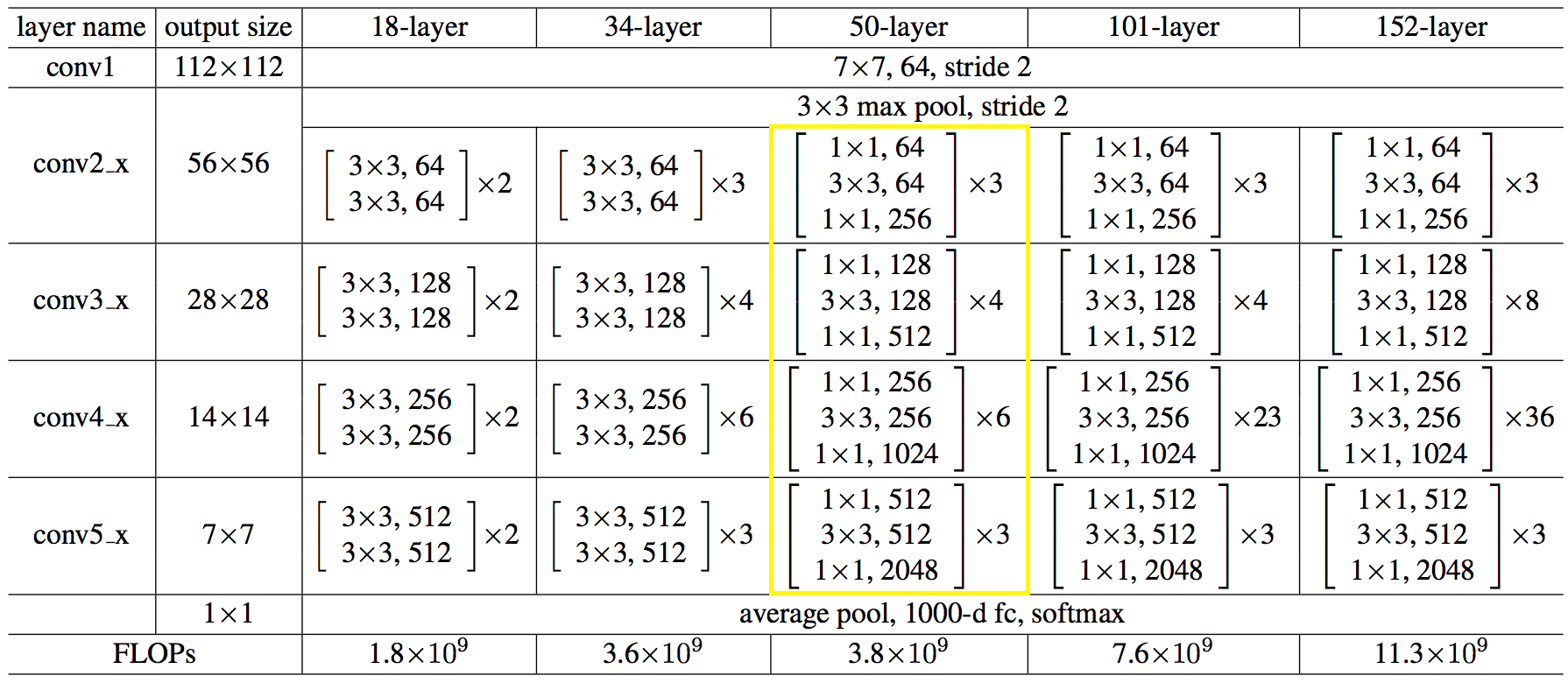
This is how the network structure looks like in numbers:
')
By code it turned out not easier and not more complicated than on python.
→ The full code is available here.
You can do it easier, load the network architecture and weights from files,
Made an application for interest. You can download from here . The volume is large due to the weights of the network. Source codes are there, you can use for an example.
The application was created only for the article, it will not be supported, therefore it did not include in the project repository.

Now, what happened compared to TF.
Indications after run of 100 images, on average. Machine: i5-2400, GF1050, Win7, MSVC12.
The values of the recognition results are the same up to the 3rd digit.
→ Test code
In fact, all the pitiable sad of course.
For the CPU, I decided not to use the MKL-DNN, I thought to bring it myself: I redistributed the memory for sequential reading, I loaded the vector registers to the maximum. Perhaps it was necessary to lead to matrix multiplication, and / or even some hacks. Rested here, at first it was worse, it would be better to use the MKL all the same.
On the GPU, time is spent on copying memory from / to the memory of a video card, and not all operations are performed on the GPU.
Conclusions which can be drawn from all this fuss:
- not to show off, but to use well-known proven solutions, have already come to mind more or less like. I myself sat on mxnet when I got to it with native use, see below;
- do not try to use native C interface ML frameworks. And use them in the language in which the developers were oriented, that is, python.
The easy way to use the ML functionality from your own language is to make a python service process, and send a picture of it using a socket, you get a division of responsibility and the absence of heavy code.
All perhaps. The article turned out to be short, but the conclusions, I think, are valuable, and apply not only to ML.
Thank.
PS: if anyone has the desire and strength to try to catch up to TF, welcome !)
Under the cut, there is a comparison with the original TF implementation, a demo image recognition application, and so ... conclusions. Who cares, please.
How ResNet works can be found, for example, here .
This is how the network structure looks like in numbers:
')
By code it turned out not easier and not more complicated than on python.
C ++ code for creating a network:
auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output"); → The full code is available here.
You can do it easier, load the network architecture and weights from files,
like this:
string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length); // Create net sn::Net snet(jnArch, weightPath); Made an application for interest. You can download from here . The volume is large due to the weights of the network. Source codes are there, you can use for an example.
The application was created only for the article, it will not be supported, therefore it did not include in the project repository.
Now, what happened compared to TF.
Indications after run of 100 images, on average. Machine: i5-2400, GF1050, Win7, MSVC12.
The values of the recognition results are the same up to the 3rd digit.
→ Test code
| CPU: time / img, ms | GPU: time / img, ms | CPU: RAM, Mb | GPU: RAM, Mb | |
|---|---|---|---|---|
| Skynet | 410 | 120 | 600 | 1200 |
| Tensorflow | 250 | 25 | 400 | 1400 |
In fact, all the pitiable sad of course.
For the CPU, I decided not to use the MKL-DNN, I thought to bring it myself: I redistributed the memory for sequential reading, I loaded the vector registers to the maximum. Perhaps it was necessary to lead to matrix multiplication, and / or even some hacks. Rested here, at first it was worse, it would be better to use the MKL all the same.
On the GPU, time is spent on copying memory from / to the memory of a video card, and not all operations are performed on the GPU.
Conclusions which can be drawn from all this fuss:
- not to show off, but to use well-known proven solutions, have already come to mind more or less like. I myself sat on mxnet when I got to it with native use, see below;
- do not try to use native C interface ML frameworks. And use them in the language in which the developers were oriented, that is, python.
The easy way to use the ML functionality from your own language is to make a python service process, and send a picture of it using a socket, you get a division of responsibility and the absence of heavy code.
All perhaps. The article turned out to be short, but the conclusions, I think, are valuable, and apply not only to ML.
Thank.
PS: if anyone has the desire and strength to try to catch up to TF, welcome !)
Source: https://habr.com/ru/post/449864/
All Articles