Hackathon DevDays'19 (part 2): a parser of sound messages for Telegram and grammar checker in IntelliJ IDEA
We continue to talk about the projects of the spring hackathon DevDays, which was attended by students of the master program "Software Engineering / Software Engineering" .

By the way, we want to invite readers to join the VK-group of magistracy . In it, we will publish the latest news about recruitment and study. Video from the day of open doors will also be found in the group. We remind: the event will be held on April 29, details on the website .
')
Idea author
Khoroshev Artyom
Line-up
Khoroshev Artem - project manager / developer / QA
Anton Eliseev - business analyst / marketing specialist
Maria Kuklina - UI Designer / Developer
Pavel Bakhvalov - UI Designer / Developer / QA
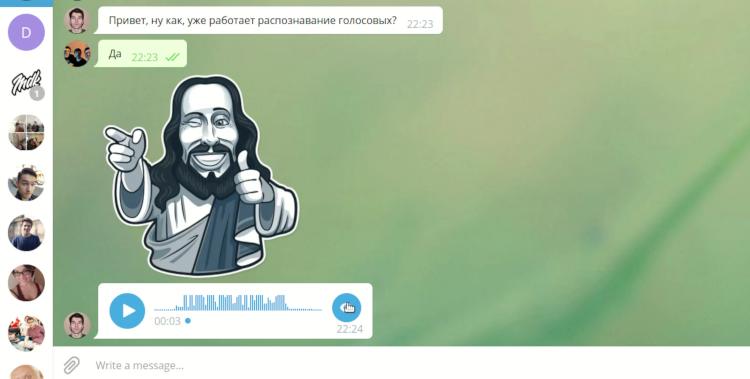
From our point of view, Telegram is a modern and convenient messenger, and its PC version is popular and open source, as a result of which it is possible to modify it. The client offers quite rich functionality. In addition to standard text messages, it contains voice calls, video messages, voice messages. And it is the latter that sometimes brings inconvenience to their recipient. Often there is no possibility to listen to the voice message while at the computer or laptop. Ambient noise, lack of headphones may interfere, or you do not want someone to hear the contents of the message. There are almost no such problems if you use telegrams on a smartphone, because you can simply bring it to your ear, unlike a laptop or PC. We tried to solve this problem.
The task of our project on DevDays was to add to the desktop client Telegram (hereinafter Telegram Desktop) the ability to broadcast the received voice messages into text.
All analogues at the moment are bots with which you can send an audio message, and receive text in response. This does not suit us very well: it is not very convenient to send a message to the bot, I would like to have native functionality. In addition, any bot is a third party that acts as an intermediary between the speech recognition API and the user, and this is at least unsafe.
As noted earlier, the telegram-desktop has two weight advantages: ease and speed. And this is no accident, because it is completely written in C ++. And since we decided to add new functionality directly to the client, we had to develop it in C ++.
 There were 4 people in our team. Initially, two people were searching for a suitable speech recognition library, one person studied the source code of Telegram-desktop, another one deployed a build of the Telegram Desktop project. Later, everyone was doing fix UI and debugging.
There were 4 people in our team. Initially, two people were searching for a suitable speech recognition library, one person studied the source code of Telegram-desktop, another one deployed a build of the Telegram Desktop project. Later, everyone was doing fix UI and debugging.
It seemed that the implementation of the conceived functionality was not difficult, but, as always happens, difficulties arose.
The solution of the problem consisted of two independent subtasks: choosing the appropriate means for speech recognition and implementing the UI for new functionality.
When choosing a library for voice recognition, we immediately had to abandon all offline APIs, because language models take up a lot of space. But we are talking only about one language. It became clear that you have to use the online API. Later it turned out that the speech recognition services of such giants as Google, Yandex and Microsoft are not at all free, and we will have to be content with the trial period. As a result, Google Speech-To-Text was chosen, as it allows you to get a token to use the service, which is enough for a whole year.
The second problem we encountered is associated with some drawbacks of C ++ - the zoo of various libraries in the absence of a central repository. It so happened that Telegram Desktop depends on many other libraries of specific versions. In the official repository there is an assembly instruction for the project. As well as a large number of open issues about build issues, for example, one and two . All problems were connected with the fact that the build script was written for Ubuntu 14.04, and in order to successfully build a telegram for Ubuntu 18.04, it was necessary to make changes.
Telegram Desktop itself is built for a long time: on a laptop with an Intel Core i5-7200U, a complete build (-j 4 flag) with all dependencies takes about three hours. Of these, about 30 minutes are taken by the linking of the client itself (it later turned out that in the Debug configuration, linking takes about 10 minutes), and the linking stage has to be repeated every time after making changes.
Despite the problems, we managed to realize the conceived idea, as well as update the build script for Ubuntu 18.04. Work demonstration can be seen on the link . We also apply several animations. A button appeared near all voice messages, allowing you to translate a message into text. When you click the right mouse button, you can optionally specify the language that will be used for the broadcast. The link is available for download client.
Repository
In our opinion, it turned out a good Proof of Concept functionality that would be convenient for many users. We hope to see it in future releases of Telegram Desktop.
Idea author
Tankov Vladislav
Line-up
Tankov Vladislav (timlid, work with LanguageTool and IntelliJ IDEA)
Nikita Sokolov (working with LanguageTool and creating UI)
Alexander Khvorov (work with LanguageTool and performance optimization)
Alexander Sadovnikov (support for parsing markup languages and code)
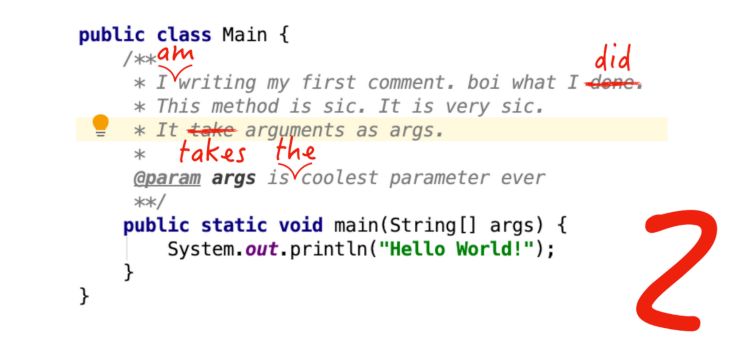
We developed a plugin for IntelliJ IDEA that checks various texts (comments and documentation, literal strings in code, Markdown text or XML markup) for grammatical, spelling and stylistic fidelity (in English, this is called proofreading).
The idea of the project was to extend the standard spellcheck IntelliJ IDEA to Grammarly scales, to make a kind of Grammarly inside IDE.
Look at what happened, you can link .
Well, below we will tell you more about the possibilities of the plug-in, as well as the difficulties encountered when creating it.
Motivation
There are many products created for writing texts in natural languages, but documentation and code comments are written most often in development environments. At the same time, IDEs do an excellent job of finding errors in writing code, but are poorly suited for texts in natural languages. Because of this, it is very easy to make mistakes in grammar, punctuation, or style, and the development environment does not indicate them. The most critical is to make a mistake in the writing of the user interface, since not only the clarity of the code will suffer, but also the users of the developed application.
One of the most popular and developed development environments is IntelliJ IDEA, as well as IDE based on IntelliJ Platform. The IntelliJ Platform already has a built-in spellchecker, however, it does not eliminate even the simplest grammatical errors. We decided to integrate one of the popular natural language analysis systems into IntelliJ IDEA.
Implementation
 We did not set ourselves the task of creating our own text verification system, so we took advantage of the existing solution. The most suitable option was LanguageTool . The license allowed us to use it freely for our purposes: it is free, written in Java and uploaded in open-source. In addition, it supports 25 languages and has been developing for more than fifteen years. Despite its openness, LanguageTool is a serious competitor to paid text verification solutions, and the fact that it is able to work locally is literally its killer feature.
We did not set ourselves the task of creating our own text verification system, so we took advantage of the existing solution. The most suitable option was LanguageTool . The license allowed us to use it freely for our purposes: it is free, written in Java and uploaded in open-source. In addition, it supports 25 languages and has been developing for more than fifteen years. Despite its openness, LanguageTool is a serious competitor to paid text verification solutions, and the fact that it is able to work locally is literally its killer feature.
The plugin code is in the GitHub repository . The whole project was written on Kotlin with a slight addition of Java for the UI. During the hackathon, we managed to implement support for Markdown, JavaDoc, HTML and Plain Text. After the hackathon, XML support, string literals in Java, Kotlin and Python, as well as spell checking were added in a large update.
Difficulties
Pretty quickly, we realized that if we feed the entire text to LanguageTool every time, the IDEA interface would hang on any more or less serious texts, since the inspection itself blocks the flow of UI. The problem was solved by checking `ProgressManager.checkCancelled` - this function throws an exception if the IDEA believes that it is time to stop the inspections.
This completely eliminated the hangs, but it is impossible to use it: the text is being processed for too long. In this case, in our case, very often a very small part of the text changes and I want to somehow cache the results. That is what we did. In order not to check everything every time, we deterministically split the text into pieces and checked only those that have changed. Since texts can be large and do not want to load the cache, we did not store the texts themselves, but their hashes. This made it possible to achieve smooth operation of the plug-in even on large files.
LanguageTool supports more than 25 languages, but hardly one user needs them all. I wanted to give the opportunity to download libraries for a specific language on request (if they ticked it in the UI). We even realized it, but it turned out too difficult and unreliable. In particular, we had to load the LanguageTool with a new set of languages with a separate classloader, and then carefully initialize it. At the same time, all the libraries were in the user .m2 repository, and at each start we had to check their integrity. In the end, we decided that if users had problems with the size of the plug-in, then we would supply a separate plug-in for several of the most popular languages.
After hackathon
The hackathon ended, but the work on the plugin continued with a narrower composition. I wanted to support lines, comments, and even language constructs, such as the names of variables and classes. Now it is supported only for Java, Kotlin and Python, but we hope that this list will grow. We fixed a lot of small errors and became more compatible with the built-in Idea spell checker. In addition, there is support for XML and spell checking. All this can be found in the second version, which we published recently.
What's next?
Such a plugin can be useful not only to developers, but also to technical writers (often working, for example, with XML in the IDE). Every day they have to work with natural language, while not having an assistant in the form of editor's hints about possible errors. Our plugin provides such hints and does it with a high degree of accuracy.
We plan to develop a plugin, both by adding new languages and by exploring a general approach to organizing text verification. In the near future, the implementation of stylistics profiles (sets of rules that define style guide for text, for example, “do not write eg, but write the full form”), expand the dictionary and improve the user interface (in particular, we want to give the user the opportunity to not just ignore the word, but add it in the dictionary, indicating part of speech).
By the way, we want to invite readers to join the VK-group of magistracy . In it, we will publish the latest news about recruitment and study. Video from the day of open doors will also be found in the group. We remind: the event will be held on April 29, details on the website .
Telegram Desktop Voice Message Parser
')
Idea author
Khoroshev Artyom
Line-up
Khoroshev Artem - project manager / developer / QA
Anton Eliseev - business analyst / marketing specialist
Maria Kuklina - UI Designer / Developer
Pavel Bakhvalov - UI Designer / Developer / QA
From our point of view, Telegram is a modern and convenient messenger, and its PC version is popular and open source, as a result of which it is possible to modify it. The client offers quite rich functionality. In addition to standard text messages, it contains voice calls, video messages, voice messages. And it is the latter that sometimes brings inconvenience to their recipient. Often there is no possibility to listen to the voice message while at the computer or laptop. Ambient noise, lack of headphones may interfere, or you do not want someone to hear the contents of the message. There are almost no such problems if you use telegrams on a smartphone, because you can simply bring it to your ear, unlike a laptop or PC. We tried to solve this problem.
The task of our project on DevDays was to add to the desktop client Telegram (hereinafter Telegram Desktop) the ability to broadcast the received voice messages into text.
All analogues at the moment are bots with which you can send an audio message, and receive text in response. This does not suit us very well: it is not very convenient to send a message to the bot, I would like to have native functionality. In addition, any bot is a third party that acts as an intermediary between the speech recognition API and the user, and this is at least unsafe.
As noted earlier, the telegram-desktop has two weight advantages: ease and speed. And this is no accident, because it is completely written in C ++. And since we decided to add new functionality directly to the client, we had to develop it in C ++.
There were 4 people in our team. Initially, two people were searching for a suitable speech recognition library, one person studied the source code of Telegram-desktop, another one deployed a build of the Telegram Desktop project. Later, everyone was doing fix UI and debugging.It seemed that the implementation of the conceived functionality was not difficult, but, as always happens, difficulties arose.
The solution of the problem consisted of two independent subtasks: choosing the appropriate means for speech recognition and implementing the UI for new functionality.
When choosing a library for voice recognition, we immediately had to abandon all offline APIs, because language models take up a lot of space. But we are talking only about one language. It became clear that you have to use the online API. Later it turned out that the speech recognition services of such giants as Google, Yandex and Microsoft are not at all free, and we will have to be content with the trial period. As a result, Google Speech-To-Text was chosen, as it allows you to get a token to use the service, which is enough for a whole year.
The second problem we encountered is associated with some drawbacks of C ++ - the zoo of various libraries in the absence of a central repository. It so happened that Telegram Desktop depends on many other libraries of specific versions. In the official repository there is an assembly instruction for the project. As well as a large number of open issues about build issues, for example, one and two . All problems were connected with the fact that the build script was written for Ubuntu 14.04, and in order to successfully build a telegram for Ubuntu 18.04, it was necessary to make changes.
Telegram Desktop itself is built for a long time: on a laptop with an Intel Core i5-7200U, a complete build (-j 4 flag) with all dependencies takes about three hours. Of these, about 30 minutes are taken by the linking of the client itself (it later turned out that in the Debug configuration, linking takes about 10 minutes), and the linking stage has to be repeated every time after making changes.
Despite the problems, we managed to realize the conceived idea, as well as update the build script for Ubuntu 18.04. Work demonstration can be seen on the link . We also apply several animations. A button appeared near all voice messages, allowing you to translate a message into text. When you click the right mouse button, you can optionally specify the language that will be used for the broadcast. The link is available for download client.
Repository
In our opinion, it turned out a good Proof of Concept functionality that would be convenient for many users. We hope to see it in future releases of Telegram Desktop.
Enhanced natural language support in IntelliJ IDEA
Idea author
Tankov Vladislav
Line-up
Tankov Vladislav (timlid, work with LanguageTool and IntelliJ IDEA)
Nikita Sokolov (working with LanguageTool and creating UI)
Alexander Khvorov (work with LanguageTool and performance optimization)
Alexander Sadovnikov (support for parsing markup languages and code)
We developed a plugin for IntelliJ IDEA that checks various texts (comments and documentation, literal strings in code, Markdown text or XML markup) for grammatical, spelling and stylistic fidelity (in English, this is called proofreading).
The idea of the project was to extend the standard spellcheck IntelliJ IDEA to Grammarly scales, to make a kind of Grammarly inside IDE.
Look at what happened, you can link .
Well, below we will tell you more about the possibilities of the plug-in, as well as the difficulties encountered when creating it.
Motivation
There are many products created for writing texts in natural languages, but documentation and code comments are written most often in development environments. At the same time, IDEs do an excellent job of finding errors in writing code, but are poorly suited for texts in natural languages. Because of this, it is very easy to make mistakes in grammar, punctuation, or style, and the development environment does not indicate them. The most critical is to make a mistake in the writing of the user interface, since not only the clarity of the code will suffer, but also the users of the developed application.
One of the most popular and developed development environments is IntelliJ IDEA, as well as IDE based on IntelliJ Platform. The IntelliJ Platform already has a built-in spellchecker, however, it does not eliminate even the simplest grammatical errors. We decided to integrate one of the popular natural language analysis systems into IntelliJ IDEA.
Implementation
We did not set ourselves the task of creating our own text verification system, so we took advantage of the existing solution. The most suitable option was LanguageTool . The license allowed us to use it freely for our purposes: it is free, written in Java and uploaded in open-source. In addition, it supports 25 languages and has been developing for more than fifteen years. Despite its openness, LanguageTool is a serious competitor to paid text verification solutions, and the fact that it is able to work locally is literally its killer feature.The plugin code is in the GitHub repository . The whole project was written on Kotlin with a slight addition of Java for the UI. During the hackathon, we managed to implement support for Markdown, JavaDoc, HTML and Plain Text. After the hackathon, XML support, string literals in Java, Kotlin and Python, as well as spell checking were added in a large update.
Difficulties
Pretty quickly, we realized that if we feed the entire text to LanguageTool every time, the IDEA interface would hang on any more or less serious texts, since the inspection itself blocks the flow of UI. The problem was solved by checking `ProgressManager.checkCancelled` - this function throws an exception if the IDEA believes that it is time to stop the inspections.
This completely eliminated the hangs, but it is impossible to use it: the text is being processed for too long. In this case, in our case, very often a very small part of the text changes and I want to somehow cache the results. That is what we did. In order not to check everything every time, we deterministically split the text into pieces and checked only those that have changed. Since texts can be large and do not want to load the cache, we did not store the texts themselves, but their hashes. This made it possible to achieve smooth operation of the plug-in even on large files.
LanguageTool supports more than 25 languages, but hardly one user needs them all. I wanted to give the opportunity to download libraries for a specific language on request (if they ticked it in the UI). We even realized it, but it turned out too difficult and unreliable. In particular, we had to load the LanguageTool with a new set of languages with a separate classloader, and then carefully initialize it. At the same time, all the libraries were in the user .m2 repository, and at each start we had to check their integrity. In the end, we decided that if users had problems with the size of the plug-in, then we would supply a separate plug-in for several of the most popular languages.
After hackathon
The hackathon ended, but the work on the plugin continued with a narrower composition. I wanted to support lines, comments, and even language constructs, such as the names of variables and classes. Now it is supported only for Java, Kotlin and Python, but we hope that this list will grow. We fixed a lot of small errors and became more compatible with the built-in Idea spell checker. In addition, there is support for XML and spell checking. All this can be found in the second version, which we published recently.
What's next?
Such a plugin can be useful not only to developers, but also to technical writers (often working, for example, with XML in the IDE). Every day they have to work with natural language, while not having an assistant in the form of editor's hints about possible errors. Our plugin provides such hints and does it with a high degree of accuracy.
We plan to develop a plugin, both by adding new languages and by exploring a general approach to organizing text verification. In the near future, the implementation of stylistics profiles (sets of rules that define style guide for text, for example, “do not write eg, but write the full form”), expand the dictionary and improve the user interface (in particular, we want to give the user the opportunity to not just ignore the word, but add it in the dictionary, indicating part of speech).
Source: https://habr.com/ru/post/449496/
All Articles