Large Hadron Collider and Classmates
Continuing the theme of contests on machine learning in Habré, we want to acquaint readers with two more platforms. They are certainly not as huge as kaggle, but they definitely deserve attention.

Personally, I don't like kaggle too much for several reasons:
- firstly, competitions there often last several months, and for active participation one has to spend a lot of forces;
- secondly, public kernels (public solutions). Adherents of kaggle advise to treat them with the tranquility of Tibetan monks, but in reality it is quite a shame when what you were walking for a month or two suddenly turns out to be laid out on a platter for everyone.
Fortunately, machine learning competitions are held on other platforms, and a couple of such competitions will be discussed.
| IDAO | SNA Hackathon 2019 |
|---|---|
| Official language: English, Organizers: Yandex, Sberbank, HSE | Official Russian language, Organizers: Mail.ru Group |
| Online Round: Jan 15 - Feb 11, 2019; On-Site Final: Apr 4-6, 2019 | online - from February 7 to March 15; offline from March 30 to April 1. |
| For some set of data about a particle in a large hadron collider (about a trajectory, impulse, and other rather complex physical parameters) determine whether it is muon or not From this setting 2 tasks were highlighted: - in one you just had to send your prediction, - and in the other - the full code and model for the prediction, and the implementation of the imposed rather stringent restrictions on the time and memory usage | For the SNA Hackathon competition, logs of content hits from open groups were collected in users' news feeds for February-March 2018. The test set is hidden the last week and a half of March. Each entry in the log contains information about what and to whom it was shown, as well as how the user reacted to this content: set “class”, commented, ignored or hidden from the tape. The essence of the tasks of SNA Hackathon is that for each user of the social network Odnoklassniki otranzhirovat his tape, as high as possible raising those posts that get the "class". At the online stage the task was divided into 3 parts: 1. rank posts for various collaborative features 2. rank posts by the images they contain 3. rank posts by the text they contain |
| Complex custom metric, something like ROC-AUC | Average ROC-AUC by users |
| Prizes for the first stage - T-shirts for N places, passage to the second stage, where accommodation and food were paid during the competition Second phase - ??? (For certain reasons, I was not present at the awards ceremony, and I could not find out what they ended up being for prizes). They promised laptops to all members of the winning team. | The prizes for the first stage are T-shirts for the 100 best participants, the passage to the second stage, where they paid for travel to Moscow, room and board during the competition. Also closer to the end of the first stage, the prizes were announced the best in 3 tasks at stage 1: everyone won on the RTX 2080 TI video card! The second stage is a team one, in teams there were from 2 to 5 people, the prizes: 1st place - 300 000 rubles 2nd place - 200 000 rubles 3rd place - 100 000 rubles Jury Prize - 100 000 rubles |
| The official group in the telegram, ~ 190 participants, communication in English, the questions had to wait for an answer for several days | Official group in the telegram, ~ 1500 participants, active discussion of tasks between participants and organizers |
| The organizers provided two basic solutions, simple and advanced. The idleness required less than 16 GB of RAM, and the advanced 16 did not fit. At the same time, running a little ahead, the participants failed to significantly surpass the advanced solution. Difficulties to launch these solutions were not. It should be noted that in the advanced example there was a comment with a hint as to where to start improving the solution. | Basic primitive solutions were provided for each of the tasks, easily surpassed by the participants. In the first days of the contest, participants faced several difficulties: first, the data were given in the Apache Parquet format, and not all combinations of Python and the parquet package worked without errors. The second difficulty was to download images from the mail cloud, at the moment there is no easy way to download a large amount of data at a time. As a result, these problems delayed the participants for a couple of days. |
IDAO. First stage
The task was to classify the muon / non-muon particles according to their characteristics. The key feature of this task was the presence in the training data of the weight column, which the organizers themselves interpreted as confidence in the answer for this line. The problem was that quite a few lines contained negative weights.
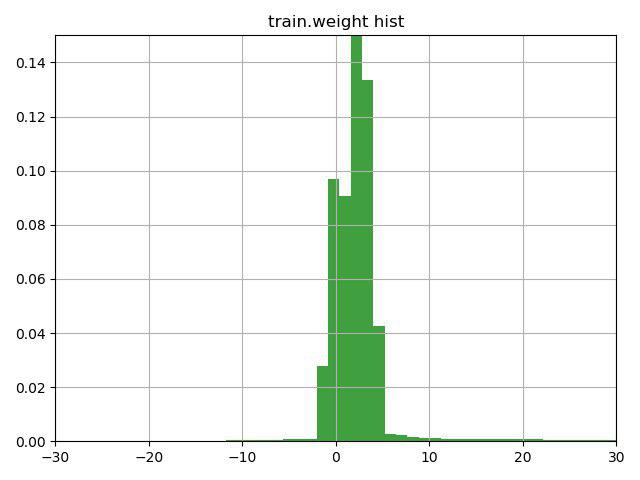
Thinking a few minutes above the line with a hint (the hint just paid attention to this feature of the weight column) and plotting this graph, we decided to check 3 options:
1) invert the target at the lines with negative weight (and weight, respectively)
2) shift the weights to the minimum value, so that they start from 0
3) do not use weights for strings
The third option was the worst, but the first two improved the result, the best option was number 1, which immediately brought us to the current second place in the first task and the first in the second.
Our next step was to view the data for missing values. The organizers gave us already combed data, where the missing values were quite small, and they were replaced by -9999.
We found missing values in the MatchedHit_ {X, Y, Z} [N] and MatchedHit_D {X, Y, Z} [N] columns, and only when N = 2 or 3. As we understood, some particles did not fly through all 4 detectors and stopped at either 3 or 4 plates. The data also included Lextra_ {X, Y} [N] columns, which apparently describe the same as MatchedHit_ {X, Y, Z} [N], but using some kind of extrapolation. These meager guesses suggested that instead of missing values in MatchedHit_ {X, Y, Z} [N] you can substitute Lextra_ {X, Y} [N] (only for X and Y coordinates). MatchedHit_Z [N] was well filled with a median. These manipulations allowed us to reach 1 intermediate place for both tasks.

Considering that for the victory in the first stage nothing was given, it would be possible to dwell on this, but we continued, drew several beautiful pictures and came up with new features.

For example, we found that if we construct the intersection points of a particle from each of the four detector plates, then we can see that the points on each of the plates are grouped into 5 rectangles with a 4: 5 aspect ratio and center at the point (0,0), and the first rectangle has no points.
| Plate number / size of rectangles | one | 2 | 3 | four | five |
|---|---|---|---|---|---|
| Plate 1 | 500x625 | 1000x1250 | 20002500 | 4000x5000 | 8000x10000 |
| Plate 2 | 520x650 | 1040x1300 | 2080x2600 | 4160x5200 | 8320x10400 |
| Plate 3 | 560x700 | 1120x1400 | 2240x2800 | 4480x5600 | 8960x11200 |
| Plate 4 | 600x750 | 1200x1500 | 2400x3000 | 4800x6000 | 9600x12000 |
Having determined these dimensions, we added 4 new categorical features for each particle — the number of the rectangle in which it intersects each plate.
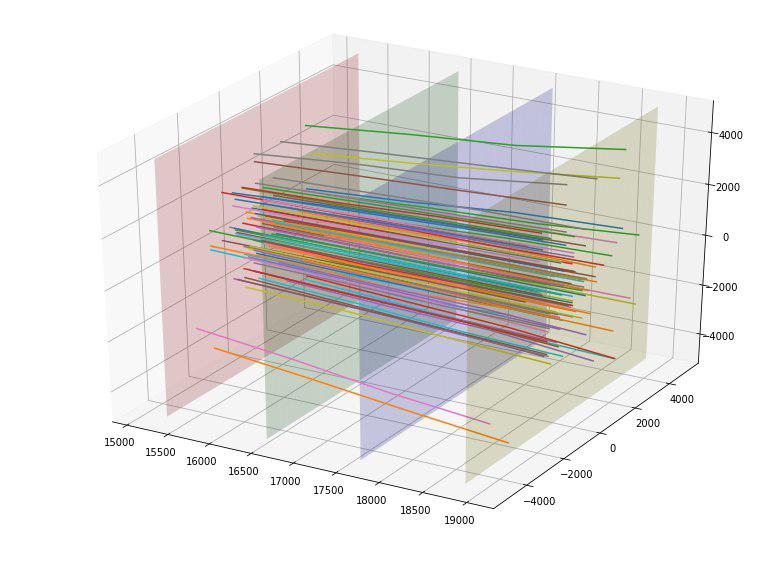
We also noticed that the particles seemed to scatter to the side of the center, and an idea appeared to somehow evaluate the "quality" of this expansion. Ideally, it would probably be possible to come up with some kind of “ideal” parabola depending on the point of the pole and estimate the deviation from it, but we limited ourselves to the “ideal” straight line. By constructing such ideal straight lines for each entry point, we were able to calculate the standard deviation of the trajectory of each particle from this straight line. Since the average deviation for target = 1 turned out to be 152, and for target = 0, it turned out 390, we previously rated this feature as good. And indeed, this feature immediately hit the top of the most useful.
We were delighted, and added the deviation of all 4 intersection points for each particle from the ideal straight line as additional 4 features (and they also worked well).
References to scientific articles on the topic of the competition, given to us by the organizers, suggested that we are not the first to solve this problem and, perhaps, there is some specialized software. Finding on github the repository where the methods IsMuonSimple, IsMuon, IsMuonLoose were implemented, we transferred them to us with a few modifications. The methods themselves were very simple: for example, if the energy is less than a certain threshold, then this is not a muon, otherwise muon. So simple signs obviously could not give a gain in the case of using gradient boosting, so we added another significant "distance" to the threshold. These features also improved a bit. Perhaps by analyzing existing techniques more thoroughly, it was possible to find more powerful methods and add them to the signs.
At the end of the contest, we drew a little on the “quick” solution for the second task, as a result it differed from the baseline in the following points:
- Negative weight lines have inverted target.
- Fill in the missing values in MatchedHit_ {X, Y, Z} [N]
- Reduced depth to 7
- Reduced learning rate to 0.1 (it was 0.19)
As a result, we tried some more features (not very well), picked up the parameters and trained catboost, lightgbm and xgboost, tried different prediction blends, and before the discovery of private chat we confidently won the second task, and the first were among the leaders.
After the opening of the privat, we were in 10th place for 1 task and 3 for the second. All the leaders mixed up, and the speed on the privat turned out to be higher than on the liberboard. It seems that the data were poorly stratified (or, for example, there were no rows with negative weights in the private message) and this was a bit frustrating.
SNA Hackathon 2019 - Texts. First stage
The task was to rank the posts of the user in the social network Odnoklassniki according to the text contained in them, besides the text there were some more characteristics of the post (language, owner, date and time of creation, date and time of viewing).
As a classic approach to working with text, I would highlight two options:
- Mapping each word to an n-dimensional vector space, such that similar words have similar vectors (more details can be found in our article ), then either finding the average word for the text or using mechanisms that take into account the relative position of the words (CNN, LSTM / GRU) .
- Using models that immediately know how to work with whole sentences. For example, Bert. In theory, this approach should work better.
Since this was my first experience with texts, it would be wrong to teach someone, so I will teach myself. These are the tips I would give myself at the beginning of the competition:
- Before you run to train something, look at the data! In addition to the texts directly, there were several columns in the data and much more could be squeezed out of them than I did. The simplest is to make the mean target encoding for part of the columns.
- Don't learn from all the data! There was a lot of data (about 17 million lines) and it was absolutely not necessary to use all of them to test hypotheses. Training and preprocessing were very slow, and I clearly would have had time to test more interesting hypotheses.
- < Controversial tip > Do not look for a killer model. I spent a long time dealing with Elmo and Bert, hoping that they would immediately lead me to a high place, and as a result I used the pre-trained FastText embeddings for the Russian language. With Elmo, it was not possible to achieve a better ambush, and did not have time to figure it out with Bert.
- < Controversial tip > Do not look for one killer feature. Looking at the data, I noticed that around 1 percent of the texts do not contain, in fact, the text! But then there were links to some resources, and I wrote a simple parser that opened the site and pulled out the name and description. It seems to be a good idea, but then I got carried away, decided to parse all the links for all the texts and again lost a lot of time. All this did not give a significant improvement in the final result (although I figured out the stemming, for example).
- Classic features work. We google, for example, "text features kaggle", read and add everything. TF-IDF gave an improvement, statistical features, like text length, words, punctuation amounts, too.
- If there is a DateTime column, it is worthwhile to disassemble them into several separate features (hours, days of the week, etc.). What features to select, it is necessary to analyze the graphs / some metrics. Here, on a whim, I did everything correctly and selected the necessary features, but a normal analysis would not hurt (for example, as we did at the final).
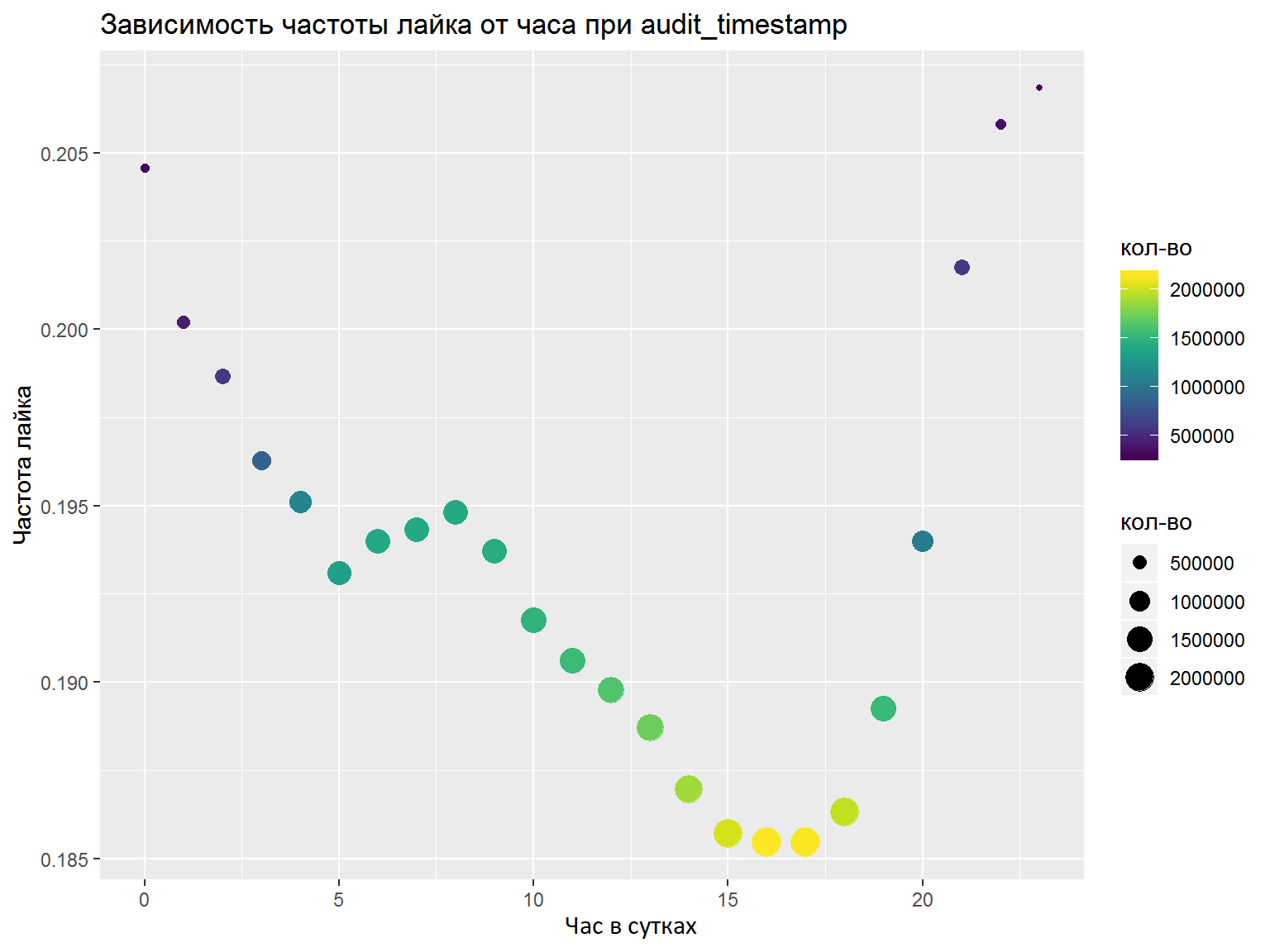
As a result of the competition, I trained one keras model with convolution by words, and another one - based on LSTM and GRU. Both here and there, pre-trained FastText embeddings for the Russian language were used (I tried a number of other embeddings, but these were the ones that worked best). Averaging the predictions, I finished 7th place out of 76 participants.
Already after the first stage, an article by Nikolai Anokhin was published who took second place (he participated out of the competition), and his decision repeated mine until some stage, but he went further due to the query-key-value attention mechanism.
Second stage OK & IDAO
The second stages of the competitions took place almost in a row, so I decided to consider them together.
At first, with the newly acquired team, I got into the impressive office of Mail.ru, where our task was to combine the models of the three tracks from the first stage - the text, the picture and the collage. A little more than 2 days was allotted for this, which turned out to be very little. In fact, we could only repeat our results of the first stage without receiving any gain from the merger. As a result, we took the 5th place, but the text model could not be used. Looking at the decisions of other participants, it seems that it was worth trying to cluster the texts and add them to the collab model. A side effect of this stage was new impressions, acquaintances and communication with cool participants and organizers, as well as a strong lack of sleep, which may have affected the outcome of the final IDAO stage.
The task at the IDAO 2019 Final internal stage was to predict the waiting time for Yandex taxi drivers at the airport. At stage 2, 3 tasks = 3 airports were allocated. For each airport, given per minute data on the number of taxi orders for six months. And as the test data was given the next month and per-minute data on orders over the past 2 weeks. There was little time (1.5 days), the task was quite specific, only one person came from the team to the competition - and as a result, a sad place near the end. Of the interesting ideas were attempts to use external data: about weather, traffic jams and statistics of orders Yandex-taxi. Although the organizers did not say what the airports were, many participants suggested that they were Sheremetyevo, Domodedovo and Vnukovo. Although this suggestion was disproved after the competition, features, for example, with Moscow weather data, improved the result both on validation and on the leaderboard.
Conclusion
- ML contests are cool and interesting! Here there is an application of skills and data analysis, and tricky models and techniques, and just common sense is welcome.
- ML is already a huge layer of knowledge that seems to grow exponentially. I set myself a goal to get acquainted with different areas (signals, pictures, tables, text) and I already understood how much to learn. For example, after these contests I decided to study: clustering algorithms, advanced techniques for working with gradient boost libraries (in particular, working with CatBoost on the GPU), capsule networks, the query-key-value attention mechanism.
- Do not kaggle'om one! There are many other contests where at least it is easier to get a t-shirt, and there are more chances for other prizes.
- Communicate! In the field of machine learning and data analysis, there is already a large community, there are subject groups in telegram, slack, and serious people from Mail.ru, Yandex and other companies answer questions and help beginners and continue their way in this area of knowledge.
- I advise everyone visiting the previous paragraph to visit the datafest - a large free conference in Moscow, which will be held on May 10-11.
')
Source: https://habr.com/ru/post/449430/
All Articles