FAQ on architecture and work VKontakte
The history of creating VKontakte is in Wikipedia, it was told by Pavel himself. It seems that everyone already knows her. Pavel told about interiors, architecture and device of the site at HighLoad ++ back in 2010 . A lot of servers have flowed since then, so we will update the information: dissect, pull out the insides, weigh it - look at the VC device from a technical point of view.

Alexey Akulovich ( AterCattus ) is a backend developer on the VKontakte team. Deciphering this report is a collective answer to frequently asked questions about the operation of the platform, infrastructure, servers, and interaction between them, but not about the development, namely about hardware . Separately - about the databases and what is in their place at the VC, about collecting logs and monitoring the entire project as a whole. Details under the cut.
')
For over four years I have been involved in all sorts of tasks related to the backend.
During this time I had a hand in many components of the site. I want to share this experience.
Everything, as usual, begins with a server or group of servers that accept requests.
The front-server accepts requests via HTTPS, RTMP and WSS.
HTTPS are requests for the main and mobile web versions of the site: vk.com and m.vk.com, and other official and unofficial clients of our API: mobile clients, messengers. We have RTMP traffic for live broadcasts with separate front servers and WSS connections for the Streaming API.
For HTTPS and WSS on servers is nginx . For RTMP broadcasts, we recently switched to our own solution, kive , but it is outside of the report. For fault tolerance, these servers announce public IP addresses and act as groups so that in case of a problem on one of the servers, user requests are not lost. For HTTPS and WSS, the same servers encrypt traffic in order to take some of the CPU load on themselves.
We will not talk further about WSS and RTMP, but only about standard HTTPS requests, which are usually associated with a web project.
Backend servers are usually behind the front. They handle requests that the front-server receives from clients.
These are the kPHP servers on which the HTTP daemon is running, because HTTPS is already decrypted. kPHP is a server that works on the prefork-model : it starts the master process, a bundle of child processes, sends them listening sockets and they process their requests. In this case, the processes are not restarted between each request from the user, but simply reset their state to the initial zero-value state - request by request, instead of restarting.
All our backends are not a huge pool of machines that can handle any request. We divide them into separate groups : general, mobile, api, video, staging ... The problem on a separate group of machines will not affect all the others. In case of problems with the video, the user who listens to music will not even know about the problems. On what backend to send a request, decides nginx on the front by configuration.
To understand how many cars you need to have in each group, we do not rely on QPS . The backends are different, they have different requests, each request has different complexity of calculating QPS. Therefore, we use the concept of server load as a whole - on the CPU and perf .
We have thousands of such servers. The kPHP group is running on each physical server in order to dispose of all cores (because kPHP is single-threaded).
CS or Content Server is a repository . CS is a server that stores files and also handles filled files, all kinds of background synchronous tasks that the main web frontend sets to it.
We have tens of thousands of physical servers that store files. Users love to upload files, and we love to store and distribute them. Some of these servers are closed by special pu / pp servers.
If you opened the network tab in VK, you saw pu / pp.

What is pu / pp? If we close one server after another, then there are two options for uploading and uploading a file to a server that has been closed: directly through
Pu is the historical name for photo upload, and pp is photo proxy . That is, one server to upload photos, and the other - to give. Now not only photos are loaded, but the name is preserved.
These servers terminate HTTPS sessions to remove the CPU load from the storage. Also, since user files are processed on these servers, the less sensitive information is stored on these machines, the better. For example, the keys to encrypt HTTPS.
Since the machines are closed by our other machines, we can afford not to give them “white” external IPs, and give them “gray” ones . So saved on the IP pool and guaranteed to protect the machine from outside access - there is simply no IP to get into it.
Failover through shared IP . In terms of fault tolerance, the scheme works the same way - several physical servers have a common physical IP, and the piece of iron in front of them chooses where to send the request. Later I will talk about other options.
The controversial point is that in this case the client keeps fewer connections . If there is the same IP on several machines - with the same host: pu.vk.com or pp.vk.com, the client’s browser has a limit on the number of simultaneous requests to one host. But during the ubiquitous HTTP / 2, I believe that this is no longer so relevant.
The obvious disadvantage of the scheme is that you have to pump all the traffic that goes to the repository through another server. Since we are pumping traffic through the machines, we cannot yet pump heavy traffic in the same way, for example, video. We give it directly to it - a separate direct connection for separate storage specifically for video. Lighter content we pass through proxy.
Not so long ago, we had an improved proxy version. Now I will tell you how they differ from ordinary ones and why it is needed.
In September 2017, Oracle, which had previously bought Sun, sacked a huge number of Sun employees . We can say that at this moment the company ceased to exist. Choosing a name for the new system, our admins decided to pay homage to the memory of this company, and called the new system Sun. Between ourselves, we call it simply "suns."
Pp had a few problems. One IP per group is an inefficient cache . Several physical servers have a common IP address, and there is no way to control which server the request will come to. Therefore, if different users come for the same file, then if there is a cache on these servers, the file is deposited in the cache of each server. This is a very inefficient scheme, but nothing could be done.
As a result, we cannot shard content , because we cannot select a specific server of this group - they have a common IP. Also, for some internal reasons, we did not have the opportunity to install such servers in the regions . They stood only in St. Petersburg.
With the suns, we changed the system of choice. Now we have anycast routing : dynamic routing, anycast, self-check daemon. Each server has its own individual IP, but a common subnet. Everything is set up so that in the event of a single server falling out, traffic is smeared over the other servers of the same group automatically. Now it is possible to select a specific server, there is no redundant caching , and reliability has not suffered.
Weights support . Now we can afford to put machines of different capacities as needed, as well as in case of temporary problems, to change the weights of the working “suns” to reduce the load on them, so that they “take a rest” and start working again.
Sharding by content id . The funny thing about sharding is that we usually shard content so that different users follow the same file through the same “sun” so that they have a common cache.
We recently launched the application “Clover”. This is an online quiz in live broadcast where the presenter asks questions and users respond in real time by choosing options. The application has a chat, where users can pofludit. More than 100 thousand people can be connected to the broadcast simultaneously. They all write messages that are sent to all participants, along with the message comes another avatar. If 100 thousand people come for one avatar in one "sun", then it can sometimes roll behind a cloud.
In order to withstand the bursts of requests for the same file, it is for some type of content that we turn on a stupid scheme that spreads the files across all the existing “suns” of the region.
Reverse proxy on nginx, cache either in RAM or on fast Optane / NVMe disks. Example:
In our architectural scheme, we add another node - the caching environment.

Below is the layout of the regional caches , there are about 20 of them. These are the places where exactly caches and “suns” stand, which can cache traffic through themselves.

This is caching of multimedia content, user data is not stored here - just music, video, photos.
To determine the region of the user, we collect the BGP prefixes of networks announced in the regions . In the case of a fallback, we still have geoip parsing if we could not find the IP by the prefixes. By user IP define region . In the code, we can look at one or several regions of the user - those points to which it is closest geographically.
We consider the popularity of files by region . There is a regional cache number where the user is located, and the file identifier - take this pair and increment the rating with each download.
In this case, the demons - services in the regions - from time to time come to the API and say: "I am such a cache, give me a list of the most popular files of my region that I don’t have yet." The API gives a bunch of files, sorted by rating, the demon downloads them, takes them to the regions, and from there sends the files. This is the fundamental difference between pu / pp and Sun from caches: they give the file through themselves immediately, even if there is no file in the cache, and the cache first downloads the file to itself, and then starts to give it away.
At the same time, we get the content closer to the users and the spreading of the network load. For example, only from the Moscow cache, we distribute more than 1 Tbit / s during the busy hours.
But there are problems - cache servers are not rubber . For super popular content, sometimes there is not enough network to a separate server. Cache servers are 40-50 Gbit / s, but there is content that clogs such a channel completely. We are moving towards storing more than one copy of popular files in the region. I hope that by the end of the year we will implement it.
We reviewed the overall architecture.
What is missing from this scheme? Of course, the databases in which we store data.
We call them not databases, but engines - Engines, because we have practically no databases in the conventional sense.

This is a necessary measure . This happened because in 2008-2009, when VK had an explosive growth in popularity, the project worked completely on MySQL and Memcache and there were problems. MySQL liked to fall and mess up the files, after which it did not rise, and Memcache gradually degraded in performance, and had to restart it.
It turns out that in the increasingly popular project there was a persistent storage that corrupts data, and a cache that slows down. In such conditions it is difficult to develop a growing project. It was decided to try to rewrite the critical things in which the project rested on their own bikes.
The decision was successful . The ability to do this was, like the extreme necessity, because at that time there were no other ways to scale. There were no heaps of databases, NoSQL did not exist yet, there were only MySQL, Memcache, PostrgreSQL - and that’s all.
Universal operation . The development was led by our team of C-developers and everything was done in a uniform way. Regardless of the engine, everywhere there was approximately the same format of files written to disk, the same launch parameters, the signals were processed the same way and they behaved approximately the same in the case of edge situations and problems. With the growth of engines, it is convenient for admins to exploit the system - there is no zoo to support, and to re-learn to exploit every new third-party base, which made it possible to quickly and conveniently increase their number.
The team wrote quite a lot of engines. Here are just a few of them: friend, hints, image, ipdb, letters, lists, logs, memcached, meowdb, news, nostradamus, photo, playlists, pmemcached, sandbox, search, storage, likes, tasks, ...
For each task that requires a specific data structure or processes atypical requests, the C-team writes a new engine. Why not.
We have a separate memcached engine, which is similar to the usual one, but with a bunch of buns, and which does not slow down. Not ClickHouse, but it works too. There is a separate pmemcached - this is a persistent memcached , which can also store data on the disk, and more than it gets into the RAM so as not to lose data when it is restarted. There are a variety of engines for individual tasks: queues, lists, sets - all that is required by our project.
From the point of view of the code, there is no need to imagine the engines or databases as some processes, entities or instances. The code works with clusters, with groups of engines - one type per cluster . Suppose there is a cluster of memcached - this is just a group of machines.
For this to work, you need to add another entity, which is located between the code and the engines - proxy .
Proxy is a connecting tire on which almost the entire site operates. At the same time, we have no service discovery - instead there is a config for this proxy, which knows the location of all the clusters and all the shards of this cluster. This is done by admins.
Programmers do not care how much, where and what they cost - they just go to the cluster. It allows us a lot. When a request is received, the proxy forwards the request, knowing where it is - it determines this itself.

At the same time proxy is a point of protection against service failure. If any engine slows down or falls, then the proxy understands this and responds accordingly to the client side. This allows you to remove the timeout - the code does not wait for the response of the engine, and understands that it does not work and you need to somehow behave differently. The code must be ready for the fact that databases do not always work.
Sometimes we still really want to have some kind of non-standard solution as an engine. It was decided not to use our ready-made rpc-proxy, created specifically for our engines, but to make a separate proxy for the task.
For MySQL, which we still have in some places we use db-proxy, and for ClickHouse - Kittenhouse .
This works in general. There is a certain server, it runs kPHP, Go, Python - in general, any code that can walk on our RPC protocol. The code runs locally on RPC-proxy - on each server where there is code, its own local proxy is running. Upon request, the proxy understands where to go.
If one engine wants to go to another, even if it is a neighbor, it goes through a proxy, because a neighbor can stand in another data center. The engine should not be tied to the knowledge of the location of anything other than itself - we have this standard solution. But of course there are exceptions :)
An example of a TL scheme, according to which all engines work.
This is a binary protocol, the closest analogue of which is protobuf. The scheme describes in advance optional fields, complex types — extensions of built-in scalars, and queries. Everything works according to this protocol.
We have an RPC protocol for executing queries of the engine that runs on top of a TL scheme. This all works on top of a TCP / UDP connection. TCP is understandable, but why do we often ask UDP.
UDP helps to avoid the problem of a huge number of connections between servers . If on each server there is an RPC-proxy and it, in general, can go to any engine, then tens of thousands of TCP connections to the server are obtained. There is a load, but it is useless. In the case of UDP, this problem does not exist.
No excessive TCP-handshake . This is a typical problem: when a new engine or a new server rises, many TCP connections are established at once. For small lightweight requests, for example, UDP payload, all communication with the engine is two UDP packets: one flies in one direction, the other in the other. One round trip - and the code received a response from the engine without a handshake.
Yes, this all works only with a very small percentage of packet loss . The protocol has support for retransmitters, timeouts, but if we lose a lot, we get almost TCP, which is not profitable. Over the oceans UDP do not drive.
We have thousands of such servers, and there is the same scheme: a pack of engines is put on each physical server. Basically, they are single-threaded in order to work as quickly as possible without locks, and are shaded as single-threaded solutions. At the same time, we have nothing more reliable than these engines, and a lot of attention is paid to persistent data storage.
Engines write binlogs . Binlog is a file at the end of which an event is added to a state or data change. In different solutions it is called differently: binary log, WAL , AOF , but the principle is the same.
So that the engine does not re-read the entire binlog during many years during the restart, the engines write snapshots - the current state . If necessary, they read first from it, and then read it out from binlog. All binlog are written in the same binary format - according to the TL scheme, so that admins can administer them in the same way with their tools. There is no need for snapshots. There is a general header that indicates whose snapshot is an int, the magic of the engine, and which body does not matter to anyone. This is the problem of the engine that recorded the snapshot.
I will briefly describe the principle of work. There is a server running the engine. He opens a new empty binlog post, writes an event of change to it.

At some point, he either decides to take a snapshot, or a signal comes to him. The server creates a new file, writes its entire state to it, appends the current binlog size - offset to the end of the file, and continues to write further. New binlog is not created.
At some point, when the engine has restarted, there will be a binlog and snapshot on the disk. The engine reads completely snapshot, raises its state at a certain point.

Subtracts the position that was at the time of the snapshot creation, and the binlog size.
Reads the end of binlog to get the current state and continues to write further events. This is a simple scheme, all our engines work on it.
As a result, the data is replicated to us from statement-based — we do not write to the binlog any changes to the pages, but requests for changes . Very similar to what comes over the network, only slightly modified.
The same scheme is used not just for replication, but also for creating backups . We have a writing engine that writes to binlog. In any other place where admins are configured, the copy of this binlog is being raised, and that’s all - we have a backup.

If you need a reading replica to reduce the load on reading on the CPU, the reading engine simply rises, which finishes the end of the binlog and executes these commands in itself locally.
The gap here is very small, and there is an opportunity to find out how much the replica is behind the master.
How does sharding work? How does the proxy understand which cluster shard to send to? The code does not say: “Send to shard 15!” - no, this is done by the proxy.
The simplest scheme is firstint - the first number in the query.
This is an example for a simple memcached text protocol, but, of course, requests are complex, structured. In the example, the first number in the request and the remainder of the division by the cluster size is taken.
This is useful when we want to have the locality of data of one entity. Suppose 100 is a user or group ID, and we want all complex data to be on the same shard for complex queries.
If we do not care how requests are spread over a cluster, there is another option - hashing the shard entirely .
We also get a hash, the remainder of the division and the number of the shard.
Both of these options only work if we are prepared for the fact that when we increase the size of a cluster, we will split it up or increase it multiple times. For example, we had 16 shards, we do not have enough, we want more - you can safely get 32 without downtime. If we want to increase more than once - it will be downtime, because it will not be possible to pererobit accurately all without loss. These options are useful, but not always.
If we need to add or remove an arbitrary number of servers, we use consistent hashing on the a la Ketama ring . But at the same time, we completely lose the locality of the data, we have to do a merge request to the cluster, so that each piece will return its small response, and already combine the answers to the proxy.
There are super specific requests. : RPC-proxy , , . , , , . proxy.

. — memcache .
— , , — . 0 1. memcache — . .
, Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
, .

, RPC RPC-proxy, , . ClickHouse, :
— ClickHouse.
ClickHouse, KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
: , , . : .
Netdata , Graphite Carbon . ClickHouse, Whisper, . ClickHouse, Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
, , — , Wathdogs.
, 600 1 . , . — , . , .
, memcache , . stats-daemon . logs-collectors , , .

logs-collectors.
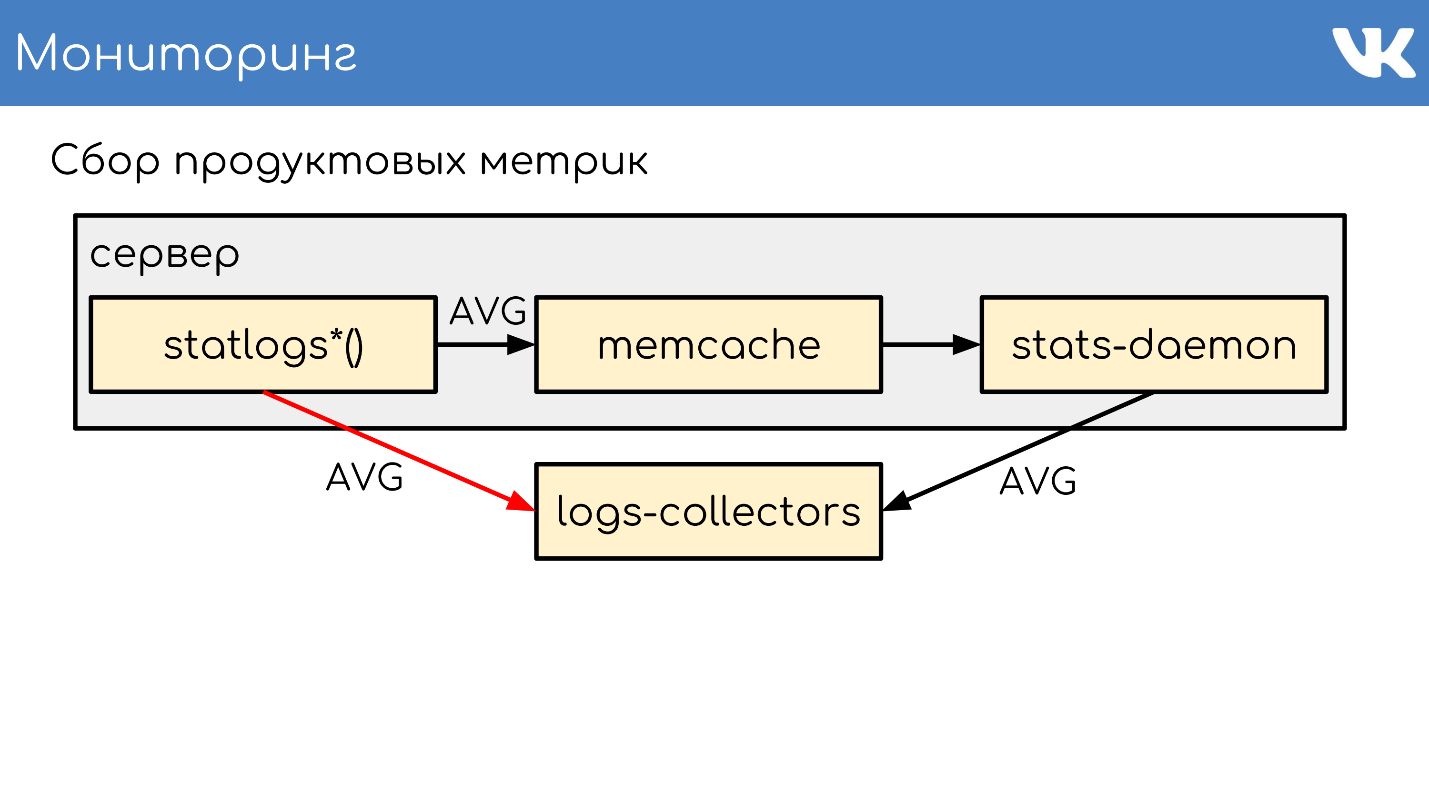
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors meowDB — , .
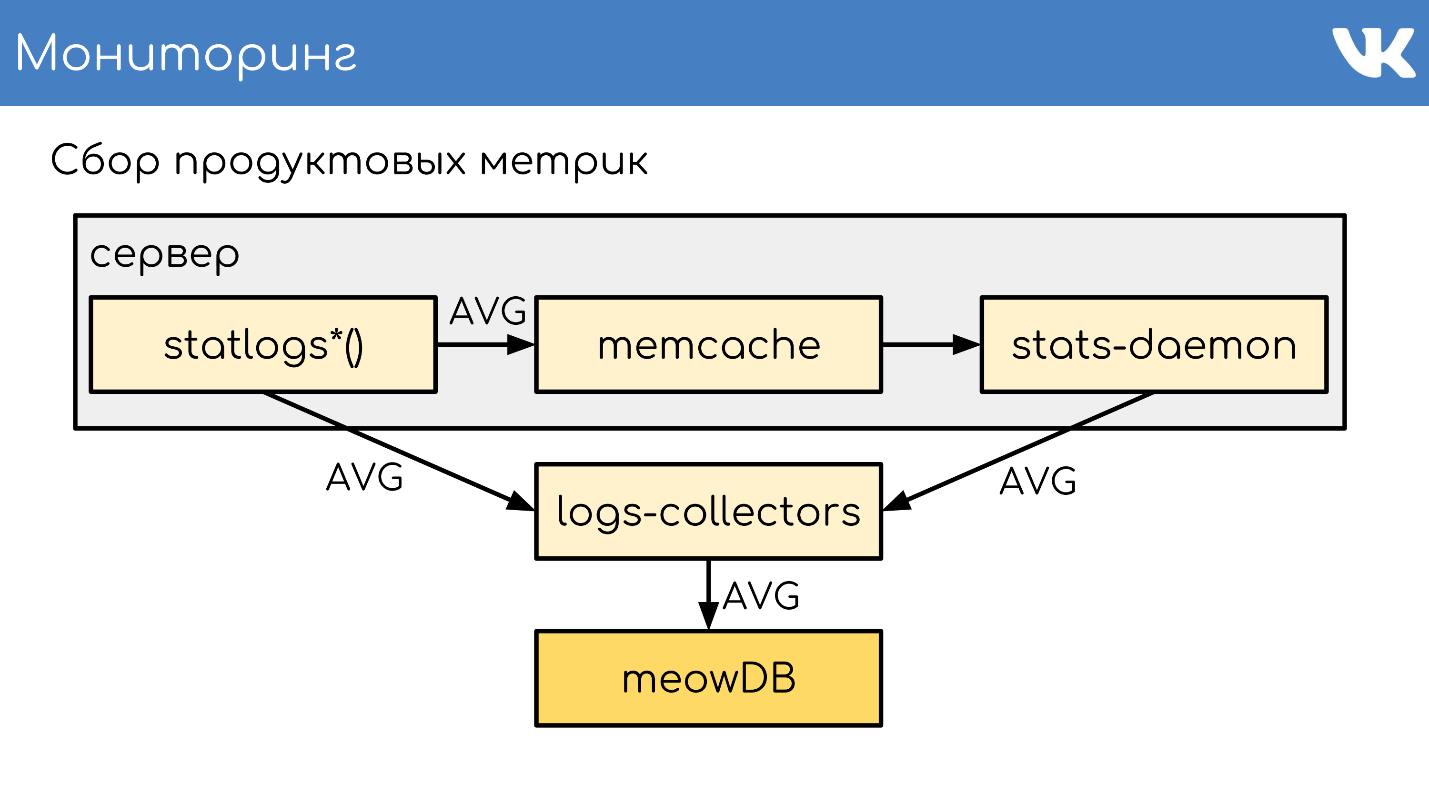
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
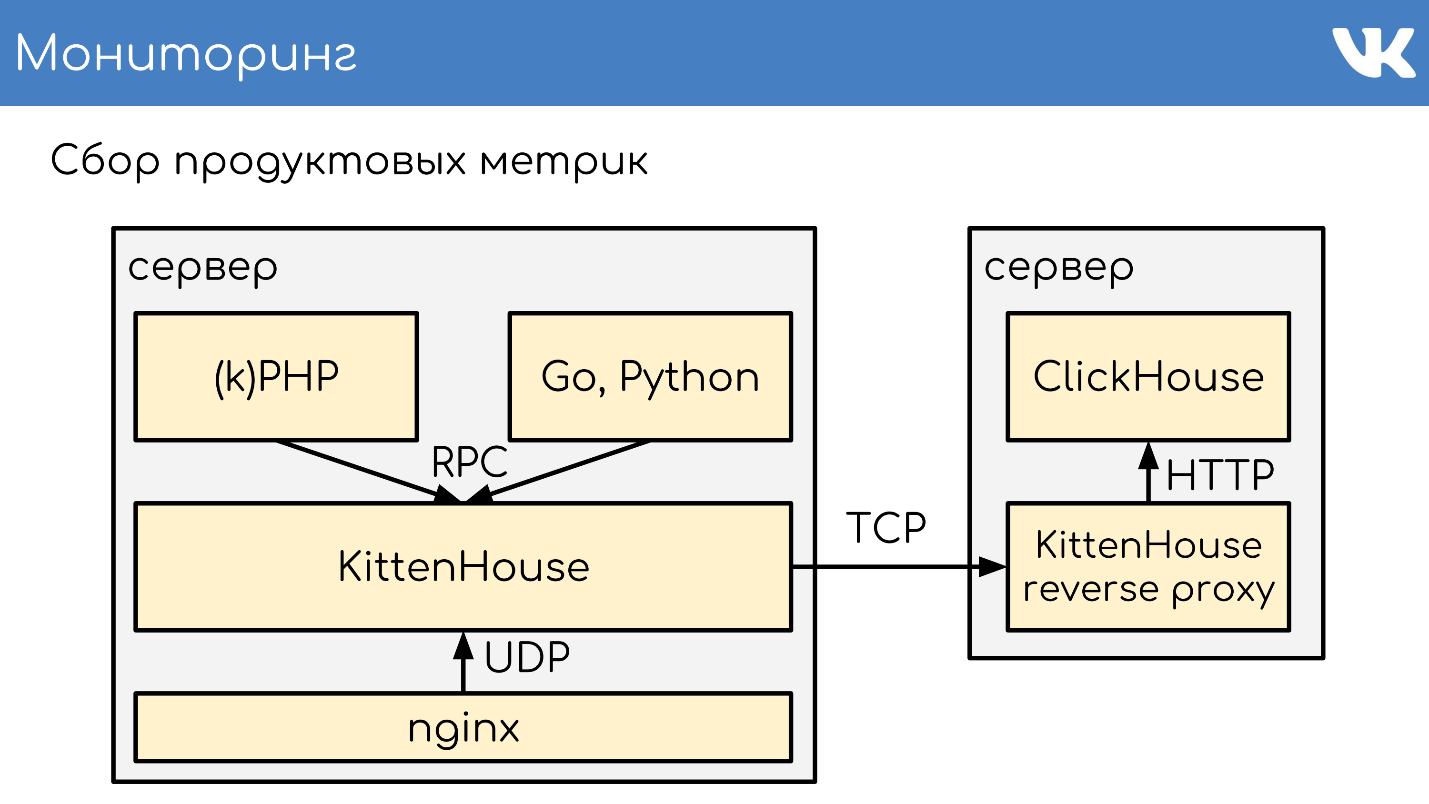
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , . , .
PHP. git : GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . , gossip replication , , — , . . , . .
kPHP git . HTTP- , diff — . — binlog copyfast . , . . copyfast' , binlog , gossip replication , -, . graceful .
, , :
, .deb , dpkg -i . kPHP , — dpkg? . — .
:
Alexey Akulovich ( AterCattus ) is a backend developer on the VKontakte team. Deciphering this report is a collective answer to frequently asked questions about the operation of the platform, infrastructure, servers, and interaction between them, but not about the development, namely about hardware . Separately - about the databases and what is in their place at the VC, about collecting logs and monitoring the entire project as a whole. Details under the cut.
')
For over four years I have been involved in all sorts of tasks related to the backend.
- Loading, storage, processing, distribution of media: video, live streaming, audio, photos, documents.
- Infrastructure, platform, monitoring by the developer, logs, regional caches, CDN, own RPC protocol.
- Integration with external services: push emails, external links parsing, RSS feed.
- Helping colleagues on various issues, for the answers to which you have to dive into an unknown code.
During this time I had a hand in many components of the site. I want to share this experience.
General architecture
Everything, as usual, begins with a server or group of servers that accept requests.
Front server
The front-server accepts requests via HTTPS, RTMP and WSS.
HTTPS are requests for the main and mobile web versions of the site: vk.com and m.vk.com, and other official and unofficial clients of our API: mobile clients, messengers. We have RTMP traffic for live broadcasts with separate front servers and WSS connections for the Streaming API.
For HTTPS and WSS on servers is nginx . For RTMP broadcasts, we recently switched to our own solution, kive , but it is outside of the report. For fault tolerance, these servers announce public IP addresses and act as groups so that in case of a problem on one of the servers, user requests are not lost. For HTTPS and WSS, the same servers encrypt traffic in order to take some of the CPU load on themselves.
We will not talk further about WSS and RTMP, but only about standard HTTPS requests, which are usually associated with a web project.
Backend
Backend servers are usually behind the front. They handle requests that the front-server receives from clients.
These are the kPHP servers on which the HTTP daemon is running, because HTTPS is already decrypted. kPHP is a server that works on the prefork-model : it starts the master process, a bundle of child processes, sends them listening sockets and they process their requests. In this case, the processes are not restarted between each request from the user, but simply reset their state to the initial zero-value state - request by request, instead of restarting.
Load distribution
All our backends are not a huge pool of machines that can handle any request. We divide them into separate groups : general, mobile, api, video, staging ... The problem on a separate group of machines will not affect all the others. In case of problems with the video, the user who listens to music will not even know about the problems. On what backend to send a request, decides nginx on the front by configuration.
Metrics collection and rebalancing
To understand how many cars you need to have in each group, we do not rely on QPS . The backends are different, they have different requests, each request has different complexity of calculating QPS. Therefore, we use the concept of server load as a whole - on the CPU and perf .
We have thousands of such servers. The kPHP group is running on each physical server in order to dispose of all cores (because kPHP is single-threaded).
Content Server
CS or Content Server is a repository . CS is a server that stores files and also handles filled files, all kinds of background synchronous tasks that the main web frontend sets to it.
We have tens of thousands of physical servers that store files. Users love to upload files, and we love to store and distribute them. Some of these servers are closed by special pu / pp servers.
pu / pp
If you opened the network tab in VK, you saw pu / pp.
What is pu / pp? If we close one server after another, then there are two options for uploading and uploading a file to a server that has been closed: directly through
http://cs100500.userapi.com/path or via an intermediate server - http://pu.vk.com/c100500/path .Pu is the historical name for photo upload, and pp is photo proxy . That is, one server to upload photos, and the other - to give. Now not only photos are loaded, but the name is preserved.
These servers terminate HTTPS sessions to remove the CPU load from the storage. Also, since user files are processed on these servers, the less sensitive information is stored on these machines, the better. For example, the keys to encrypt HTTPS.
Since the machines are closed by our other machines, we can afford not to give them “white” external IPs, and give them “gray” ones . So saved on the IP pool and guaranteed to protect the machine from outside access - there is simply no IP to get into it.
Failover through shared IP . In terms of fault tolerance, the scheme works the same way - several physical servers have a common physical IP, and the piece of iron in front of them chooses where to send the request. Later I will talk about other options.
The controversial point is that in this case the client keeps fewer connections . If there is the same IP on several machines - with the same host: pu.vk.com or pp.vk.com, the client’s browser has a limit on the number of simultaneous requests to one host. But during the ubiquitous HTTP / 2, I believe that this is no longer so relevant.
The obvious disadvantage of the scheme is that you have to pump all the traffic that goes to the repository through another server. Since we are pumping traffic through the machines, we cannot yet pump heavy traffic in the same way, for example, video. We give it directly to it - a separate direct connection for separate storage specifically for video. Lighter content we pass through proxy.
Not so long ago, we had an improved proxy version. Now I will tell you how they differ from ordinary ones and why it is needed.
Sun
In September 2017, Oracle, which had previously bought Sun, sacked a huge number of Sun employees . We can say that at this moment the company ceased to exist. Choosing a name for the new system, our admins decided to pay homage to the memory of this company, and called the new system Sun. Between ourselves, we call it simply "suns."
Pp had a few problems. One IP per group is an inefficient cache . Several physical servers have a common IP address, and there is no way to control which server the request will come to. Therefore, if different users come for the same file, then if there is a cache on these servers, the file is deposited in the cache of each server. This is a very inefficient scheme, but nothing could be done.
As a result, we cannot shard content , because we cannot select a specific server of this group - they have a common IP. Also, for some internal reasons, we did not have the opportunity to install such servers in the regions . They stood only in St. Petersburg.
With the suns, we changed the system of choice. Now we have anycast routing : dynamic routing, anycast, self-check daemon. Each server has its own individual IP, but a common subnet. Everything is set up so that in the event of a single server falling out, traffic is smeared over the other servers of the same group automatically. Now it is possible to select a specific server, there is no redundant caching , and reliability has not suffered.
Weights support . Now we can afford to put machines of different capacities as needed, as well as in case of temporary problems, to change the weights of the working “suns” to reduce the load on them, so that they “take a rest” and start working again.
Sharding by content id . The funny thing about sharding is that we usually shard content so that different users follow the same file through the same “sun” so that they have a common cache.
We recently launched the application “Clover”. This is an online quiz in live broadcast where the presenter asks questions and users respond in real time by choosing options. The application has a chat, where users can pofludit. More than 100 thousand people can be connected to the broadcast simultaneously. They all write messages that are sent to all participants, along with the message comes another avatar. If 100 thousand people come for one avatar in one "sun", then it can sometimes roll behind a cloud.
In order to withstand the bursts of requests for the same file, it is for some type of content that we turn on a stupid scheme that spreads the files across all the existing “suns” of the region.
Sun inside
Reverse proxy on nginx, cache either in RAM or on fast Optane / NVMe disks. Example:
http://sun4-2.userapi.com/c100500/path - a link to the "sun", which stands in the fourth region, the second server group. It closes the path file, which physically lies on the server 100500.Cache
In our architectural scheme, we add another node - the caching environment.
Below is the layout of the regional caches , there are about 20 of them. These are the places where exactly caches and “suns” stand, which can cache traffic through themselves.
This is caching of multimedia content, user data is not stored here - just music, video, photos.
To determine the region of the user, we collect the BGP prefixes of networks announced in the regions . In the case of a fallback, we still have geoip parsing if we could not find the IP by the prefixes. By user IP define region . In the code, we can look at one or several regions of the user - those points to which it is closest geographically.
How it works?
We consider the popularity of files by region . There is a regional cache number where the user is located, and the file identifier - take this pair and increment the rating with each download.
In this case, the demons - services in the regions - from time to time come to the API and say: "I am such a cache, give me a list of the most popular files of my region that I don’t have yet." The API gives a bunch of files, sorted by rating, the demon downloads them, takes them to the regions, and from there sends the files. This is the fundamental difference between pu / pp and Sun from caches: they give the file through themselves immediately, even if there is no file in the cache, and the cache first downloads the file to itself, and then starts to give it away.
At the same time, we get the content closer to the users and the spreading of the network load. For example, only from the Moscow cache, we distribute more than 1 Tbit / s during the busy hours.
But there are problems - cache servers are not rubber . For super popular content, sometimes there is not enough network to a separate server. Cache servers are 40-50 Gbit / s, but there is content that clogs such a channel completely. We are moving towards storing more than one copy of popular files in the region. I hope that by the end of the year we will implement it.
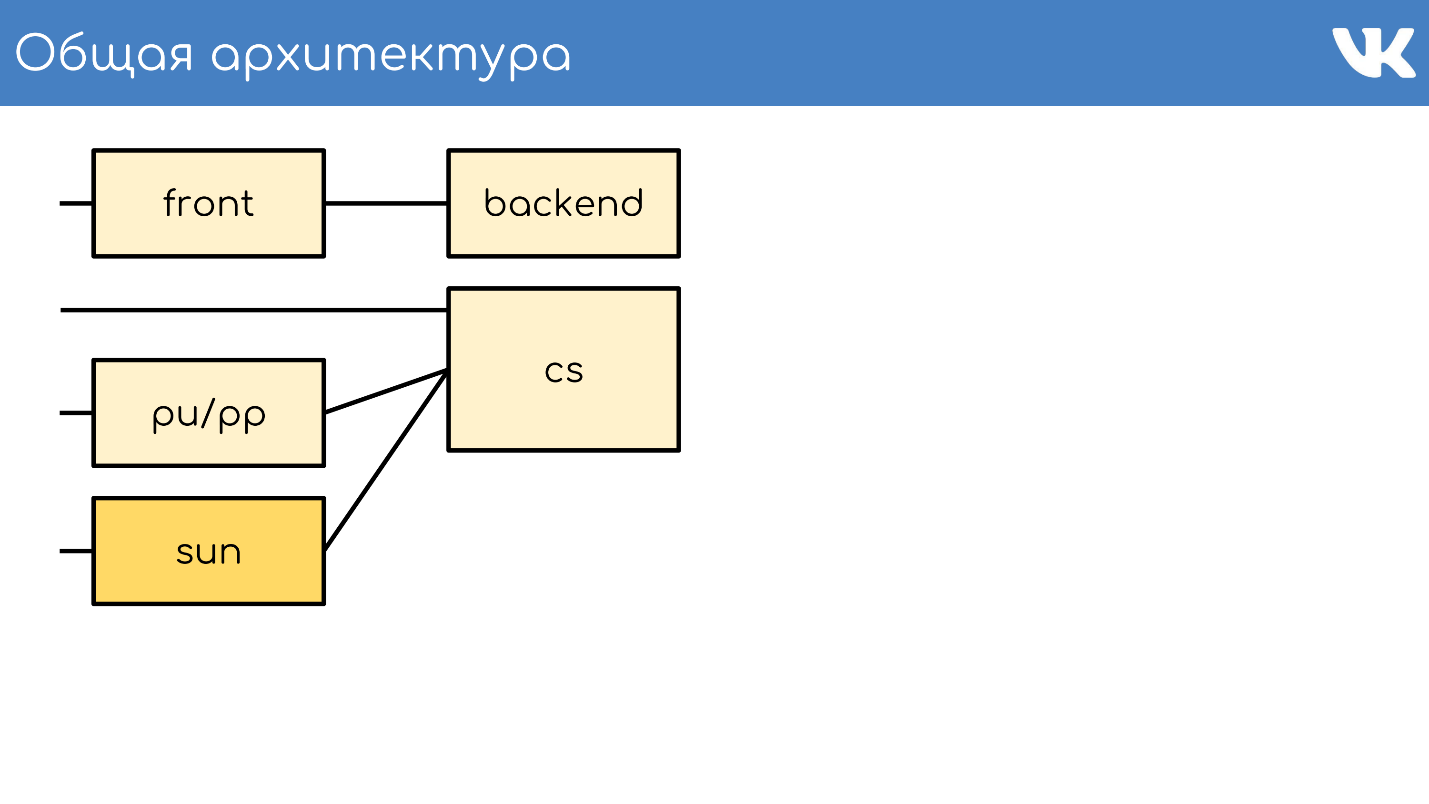
We reviewed the overall architecture.
- Front servers that accept requests.
- Backends that process requests.
- Stores that are closed by two types of proxy.
- Regional caches.
What is missing from this scheme? Of course, the databases in which we store data.
Databases or engines
We call them not databases, but engines - Engines, because we have practically no databases in the conventional sense.
This is a necessary measure . This happened because in 2008-2009, when VK had an explosive growth in popularity, the project worked completely on MySQL and Memcache and there were problems. MySQL liked to fall and mess up the files, after which it did not rise, and Memcache gradually degraded in performance, and had to restart it.
It turns out that in the increasingly popular project there was a persistent storage that corrupts data, and a cache that slows down. In such conditions it is difficult to develop a growing project. It was decided to try to rewrite the critical things in which the project rested on their own bikes.
The decision was successful . The ability to do this was, like the extreme necessity, because at that time there were no other ways to scale. There were no heaps of databases, NoSQL did not exist yet, there were only MySQL, Memcache, PostrgreSQL - and that’s all.
Universal operation . The development was led by our team of C-developers and everything was done in a uniform way. Regardless of the engine, everywhere there was approximately the same format of files written to disk, the same launch parameters, the signals were processed the same way and they behaved approximately the same in the case of edge situations and problems. With the growth of engines, it is convenient for admins to exploit the system - there is no zoo to support, and to re-learn to exploit every new third-party base, which made it possible to quickly and conveniently increase their number.
Types of engines
The team wrote quite a lot of engines. Here are just a few of them: friend, hints, image, ipdb, letters, lists, logs, memcached, meowdb, news, nostradamus, photo, playlists, pmemcached, sandbox, search, storage, likes, tasks, ...
For each task that requires a specific data structure or processes atypical requests, the C-team writes a new engine. Why not.
We have a separate memcached engine, which is similar to the usual one, but with a bunch of buns, and which does not slow down. Not ClickHouse, but it works too. There is a separate pmemcached - this is a persistent memcached , which can also store data on the disk, and more than it gets into the RAM so as not to lose data when it is restarted. There are a variety of engines for individual tasks: queues, lists, sets - all that is required by our project.
Clusters
From the point of view of the code, there is no need to imagine the engines or databases as some processes, entities or instances. The code works with clusters, with groups of engines - one type per cluster . Suppose there is a cluster of memcached - this is just a group of machines.
The code does not need to know the physical location, size and number of servers. He goes to the cluster by some kind of identifier.
For this to work, you need to add another entity, which is located between the code and the engines - proxy .
RPC-proxy
Proxy is a connecting tire on which almost the entire site operates. At the same time, we have no service discovery - instead there is a config for this proxy, which knows the location of all the clusters and all the shards of this cluster. This is done by admins.
Programmers do not care how much, where and what they cost - they just go to the cluster. It allows us a lot. When a request is received, the proxy forwards the request, knowing where it is - it determines this itself.
At the same time proxy is a point of protection against service failure. If any engine slows down or falls, then the proxy understands this and responds accordingly to the client side. This allows you to remove the timeout - the code does not wait for the response of the engine, and understands that it does not work and you need to somehow behave differently. The code must be ready for the fact that databases do not always work.
Specific implementations
Sometimes we still really want to have some kind of non-standard solution as an engine. It was decided not to use our ready-made rpc-proxy, created specifically for our engines, but to make a separate proxy for the task.
For MySQL, which we still have in some places we use db-proxy, and for ClickHouse - Kittenhouse .
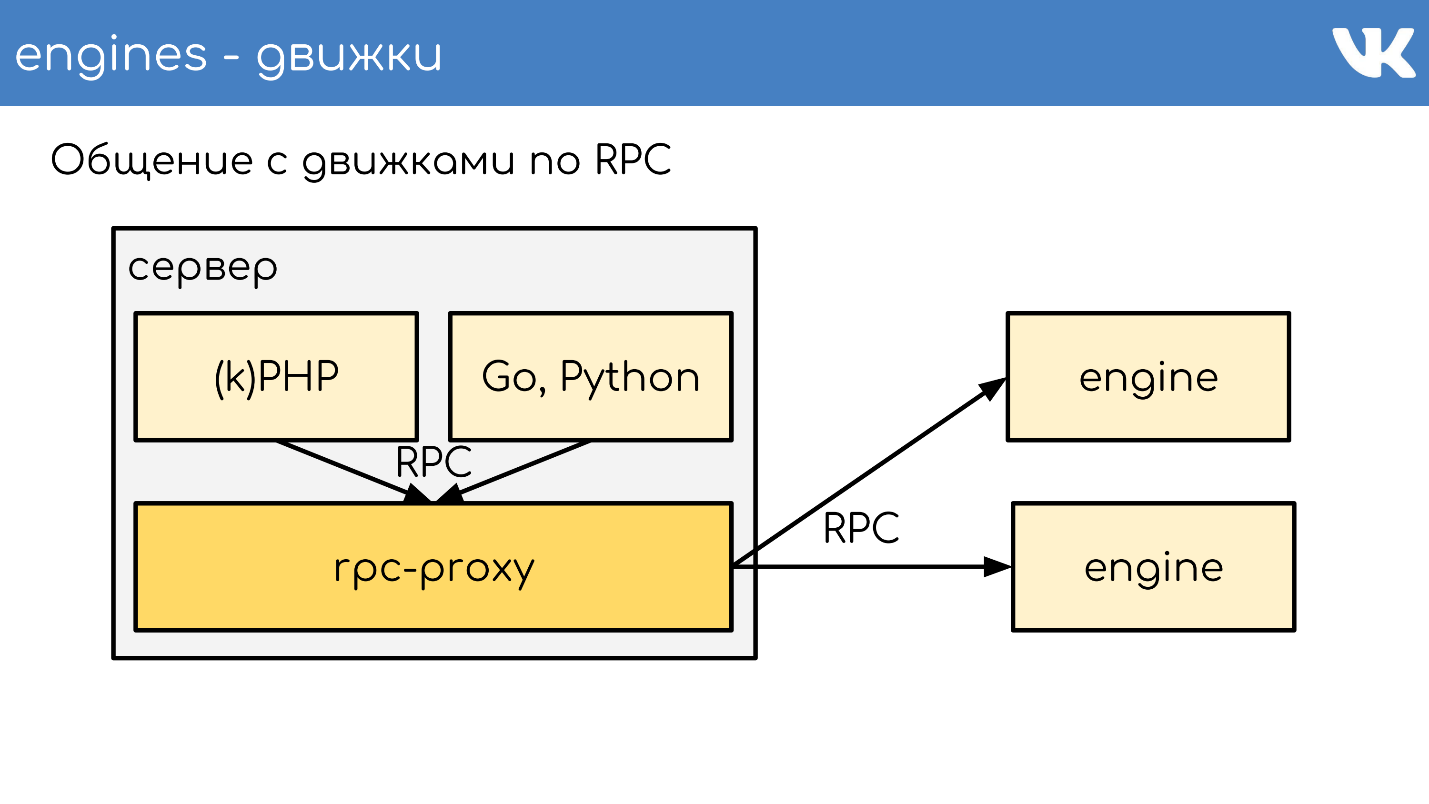
This works in general. There is a certain server, it runs kPHP, Go, Python - in general, any code that can walk on our RPC protocol. The code runs locally on RPC-proxy - on each server where there is code, its own local proxy is running. Upon request, the proxy understands where to go.
If one engine wants to go to another, even if it is a neighbor, it goes through a proxy, because a neighbor can stand in another data center. The engine should not be tied to the knowledge of the location of anything other than itself - we have this standard solution. But of course there are exceptions :)
An example of a TL scheme, according to which all engines work.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long; This is a binary protocol, the closest analogue of which is protobuf. The scheme describes in advance optional fields, complex types — extensions of built-in scalars, and queries. Everything works according to this protocol.
RPC over TL over TCP / UDP ... UDP?
We have an RPC protocol for executing queries of the engine that runs on top of a TL scheme. This all works on top of a TCP / UDP connection. TCP is understandable, but why do we often ask UDP.
UDP helps to avoid the problem of a huge number of connections between servers . If on each server there is an RPC-proxy and it, in general, can go to any engine, then tens of thousands of TCP connections to the server are obtained. There is a load, but it is useless. In the case of UDP, this problem does not exist.
No excessive TCP-handshake . This is a typical problem: when a new engine or a new server rises, many TCP connections are established at once. For small lightweight requests, for example, UDP payload, all communication with the engine is two UDP packets: one flies in one direction, the other in the other. One round trip - and the code received a response from the engine without a handshake.
Yes, this all works only with a very small percentage of packet loss . The protocol has support for retransmitters, timeouts, but if we lose a lot, we get almost TCP, which is not profitable. Over the oceans UDP do not drive.
We have thousands of such servers, and there is the same scheme: a pack of engines is put on each physical server. Basically, they are single-threaded in order to work as quickly as possible without locks, and are shaded as single-threaded solutions. At the same time, we have nothing more reliable than these engines, and a lot of attention is paid to persistent data storage.
Persistent storage
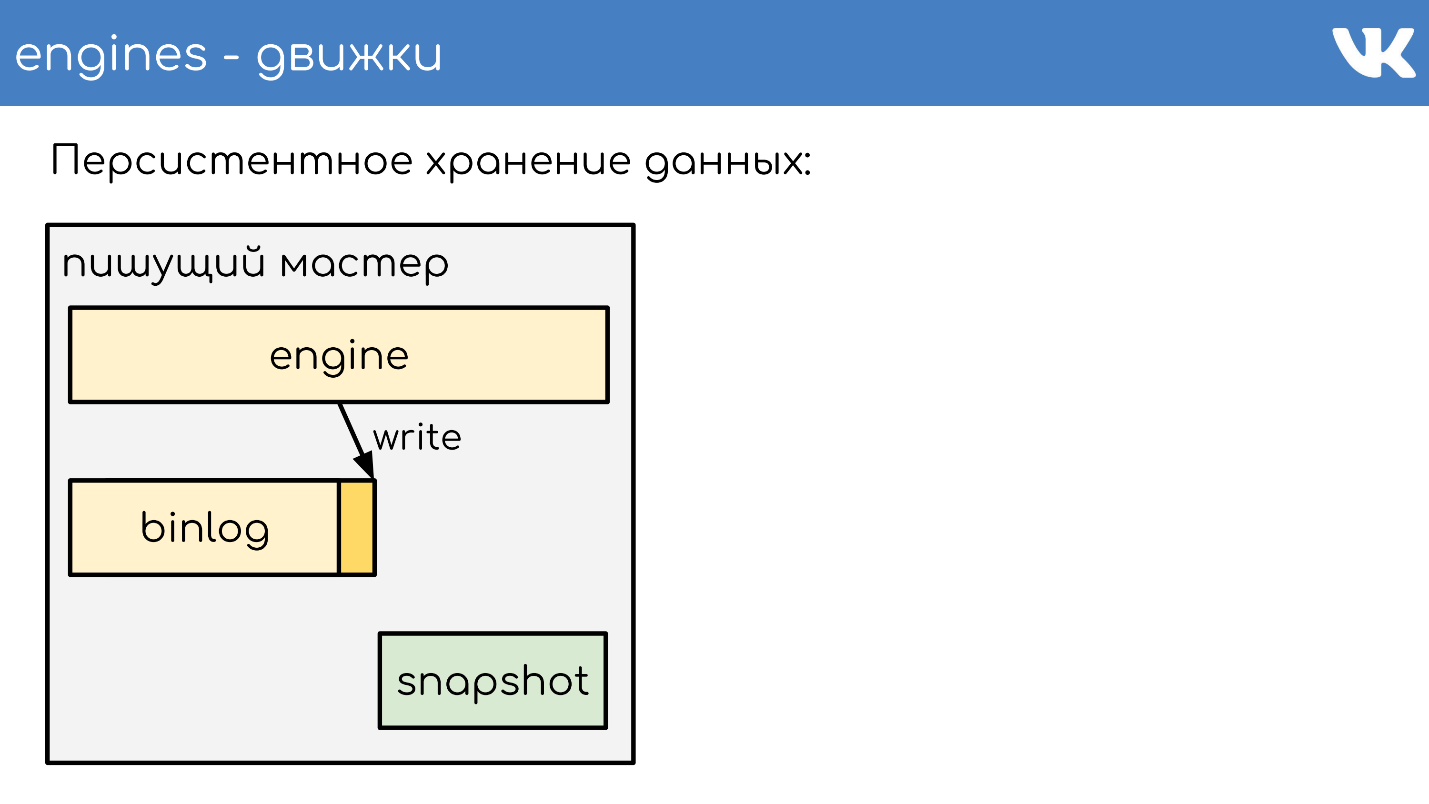
Engines write binlogs . Binlog is a file at the end of which an event is added to a state or data change. In different solutions it is called differently: binary log, WAL , AOF , but the principle is the same.
So that the engine does not re-read the entire binlog during many years during the restart, the engines write snapshots - the current state . If necessary, they read first from it, and then read it out from binlog. All binlog are written in the same binary format - according to the TL scheme, so that admins can administer them in the same way with their tools. There is no need for snapshots. There is a general header that indicates whose snapshot is an int, the magic of the engine, and which body does not matter to anyone. This is the problem of the engine that recorded the snapshot.
I will briefly describe the principle of work. There is a server running the engine. He opens a new empty binlog post, writes an event of change to it.
At some point, he either decides to take a snapshot, or a signal comes to him. The server creates a new file, writes its entire state to it, appends the current binlog size - offset to the end of the file, and continues to write further. New binlog is not created.
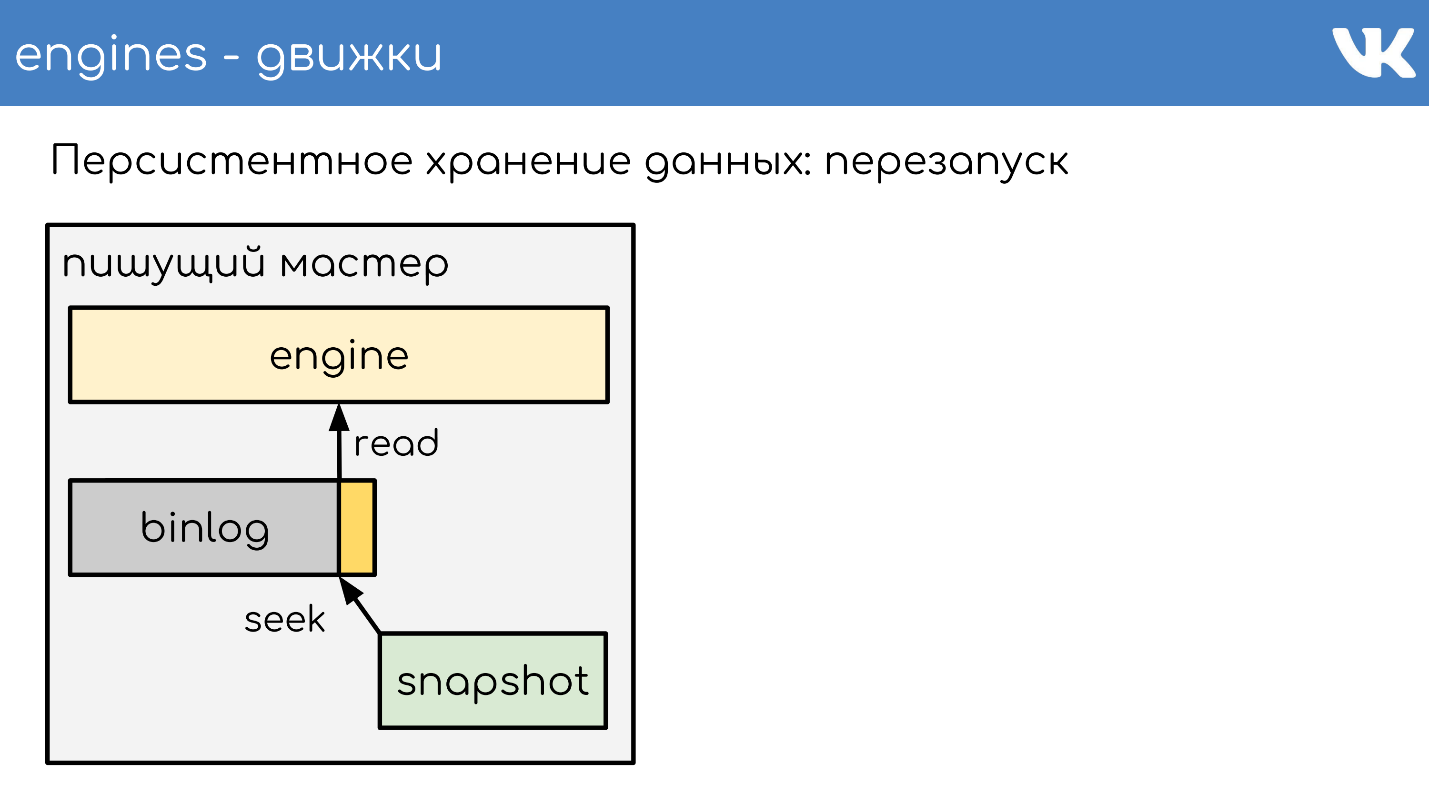
At some point, when the engine has restarted, there will be a binlog and snapshot on the disk. The engine reads completely snapshot, raises its state at a certain point.
Subtracts the position that was at the time of the snapshot creation, and the binlog size.
Reads the end of binlog to get the current state and continues to write further events. This is a simple scheme, all our engines work on it.
Data replication
As a result, the data is replicated to us from statement-based — we do not write to the binlog any changes to the pages, but requests for changes . Very similar to what comes over the network, only slightly modified.
The same scheme is used not just for replication, but also for creating backups . We have a writing engine that writes to binlog. In any other place where admins are configured, the copy of this binlog is being raised, and that’s all - we have a backup.
If you need a reading replica to reduce the load on reading on the CPU, the reading engine simply rises, which finishes the end of the binlog and executes these commands in itself locally.
The gap here is very small, and there is an opportunity to find out how much the replica is behind the master.
Sharding data in RPC-proxy
How does sharding work? How does the proxy understand which cluster shard to send to? The code does not say: “Send to shard 15!” - no, this is done by the proxy.
The simplest scheme is firstint - the first number in the query.
get(photo100_500) => 100 % N.This is an example for a simple memcached text protocol, but, of course, requests are complex, structured. In the example, the first number in the request and the remainder of the division by the cluster size is taken.
This is useful when we want to have the locality of data of one entity. Suppose 100 is a user or group ID, and we want all complex data to be on the same shard for complex queries.
If we do not care how requests are spread over a cluster, there is another option - hashing the shard entirely .
hash(photo100_500) => 3539886280 % NWe also get a hash, the remainder of the division and the number of the shard.
Both of these options only work if we are prepared for the fact that when we increase the size of a cluster, we will split it up or increase it multiple times. For example, we had 16 shards, we do not have enough, we want more - you can safely get 32 without downtime. If we want to increase more than once - it will be downtime, because it will not be possible to pererobit accurately all without loss. These options are useful, but not always.
If we need to add or remove an arbitrary number of servers, we use consistent hashing on the a la Ketama ring . But at the same time, we completely lose the locality of the data, we have to do a merge request to the cluster, so that each piece will return its small response, and already combine the answers to the proxy.
There are super specific requests. : RPC-proxy , , . , , , . proxy.
. — memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
, Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .
, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse, KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse reverse proxy , , . .
RPC- , , nginx. KittenHouse UDP.
, UDP- . RPC , UDP. .
Monitoring
: , , . : .
Netdata , Graphite Carbon . ClickHouse, Whisper, . ClickHouse, Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params) , , — , Wathdogs.
, 600 1 . , . — , . , .
, memcache , . stats-daemon . logs-collectors , , .
logs-collectors.
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors meowDB — , .
«-SQL» .
Experiment
2018 , -, ClickHouse. ClickHouse — ?
, KittenHouse.
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
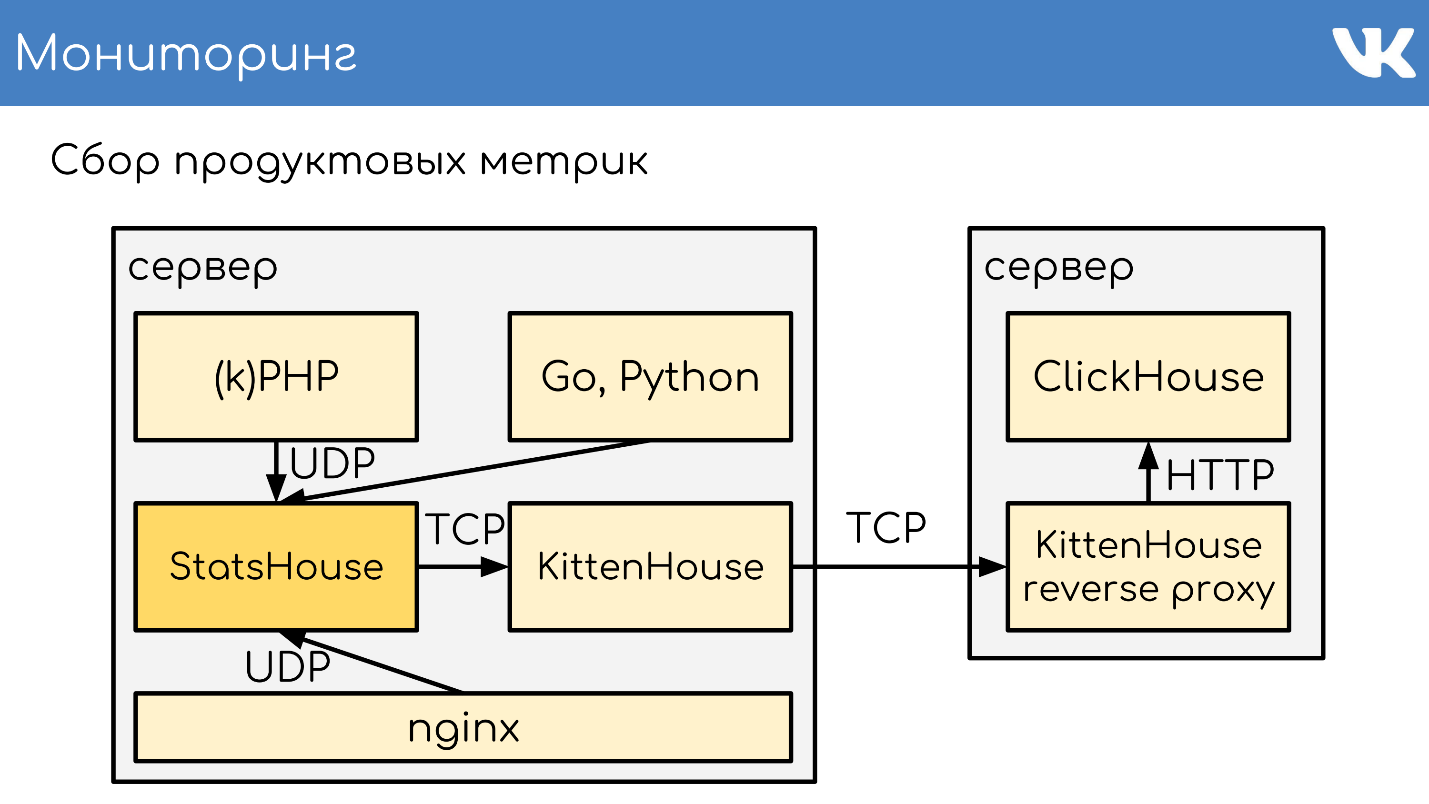
memcache, stats-daemon logs-collectors .
memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , . , .
PHP. git : GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . , gossip replication , , — , . . , . .
kPHP git . HTTP- , diff — . — binlog copyfast . , . . copyfast' , binlog , gossip replication , -, . graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
, .deb , dpkg -i . kPHP , — dpkg? . — .
:
- « Vkontakte. ?» copyfast gossip.
- « VK CLickHouse » .
- « » , , .
, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .
Source: https://habr.com/ru/post/449254/
All Articles