JavaScript engine basics: prototype optimization. Part 2
Good afternoon friends! The course “Security of Information Systems” has been launched; in connection with this, we are sharing with you the final part of the article “Basics of JavaScript engines: prototype optimization”, the first part of which can be found here .
We also remind that the current publication is a continuation of these two articles: “Basics of JavaScript engines: common forms and Inline caching. Part 1 , Basics of JavaScript engines: common forms and inline caching. Part 2 " .

')
Classes and Prototype Programming
Now that we know how to get quick access to the properties of JavaScript objects, we can take a look at the more complex structure of JavaScript classes. This is what the JavaScript class syntax looks like:
Although it seems to be a relatively new concept for JavaScript, it’s just “syntactic sugar” for prototype programming that has always been used in JavaScript:
Here we assign the
Let's take a closer look at what happens when we create a new instance of
The instance created using this code has a form with a single property
This

When you create a new instance of the same class, both instances have the same form, as we already understood earlier. Both instances will point to the same
Access to prototype properties
Well, now we know what happens when we define a class and create a new instance. But what happens if we call a method on an instance, as we did in the following example?
You can view any method call as two separate steps:
The first step is to load the method, which is actually a property of the prototype (whose value is a function). The second step is a function call with an instance, for example, the value of

The engine runs an instance of
JavaScript flexibility allows the links of the prototype chain to change, for example:
In this example, we call
In everyday practice, loading prototype properties is quite a frequent operation: this happens every time you call a method!
Earlier we talked about how engines optimize the loading of regular (regular), own properties by using forms and inline caches. How can I optimize the loading of prototype properties for objects of the same form? From above, we have seen how properties are loaded.

In order to do this quickly with repeated downloads in this particular case, you need to know the following three things:
In general, this means that you need to make one check of the instance itself and two more checks for each prototype, up to the prototype that contains the desired property. 1 + 2N checks, where N is the number of prototypes used, does not sound so bad in this case, since the prototype chain is relatively shallow. However, engines often have to deal with much longer chains of prototypes, as is the case with regular DOM classes. For example:
We have

The
Total 7 checks obtained. Since this type of code is quite common on the web, the engines use various tricks to reduce the number of checks needed to load prototype properties.
Returning to an earlier example in which we did only three checks when we requested
For each object that occurs before the prototype containing the desired property, it is necessary to check the forms for the absence of this property. It would be nice if we could reduce the number of checks by presenting a prototype check as a check for the absence of a property. In fact, this is exactly what the engines do with simple tricks: instead of storing the prototype link to the instance itself, the engines keep it in shape.
Each form indicates a prototype. This means that each time the
With this approach, we can reduce the number of required checks from 2N + 1 to 1 + N to speed up access. This is still a fairly expensive operation, since it is still a linear function of the number of prototypes in the circuit. The engines use various tricks to further reduce the number of checks to a certain constant value, especially in the case of sequential loading of the same properties.
Valid cells
V8 handles prototype forms specifically for this purpose. Each prototype has a unique form that is not used in conjunction with other objects (in particular, with other prototypes), and each of these prototype forms has a special
This
To speed up subsequent downloads from prototypes, the V8 places the inline cache in place with four fields:
When the inline cache is heated when the code is first run, V8 remembers the offset by which the property was found in the prototype, this prototype (for example,
The next time the Inline cache is used, the engine needs to check the instance form and
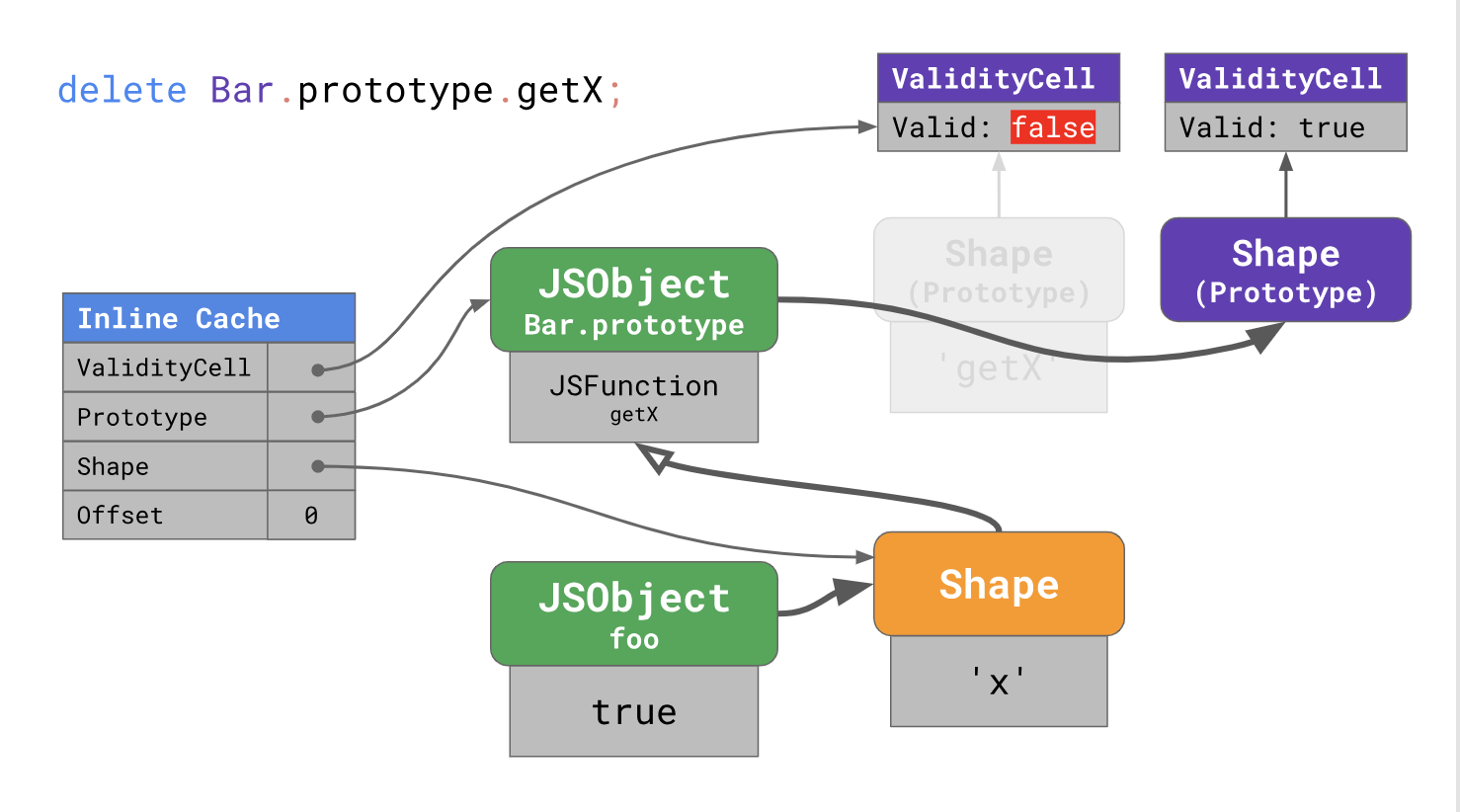
When the prototype changes, a new form is highlighted, and the previous
Let's go back to the DOM example. Every change in
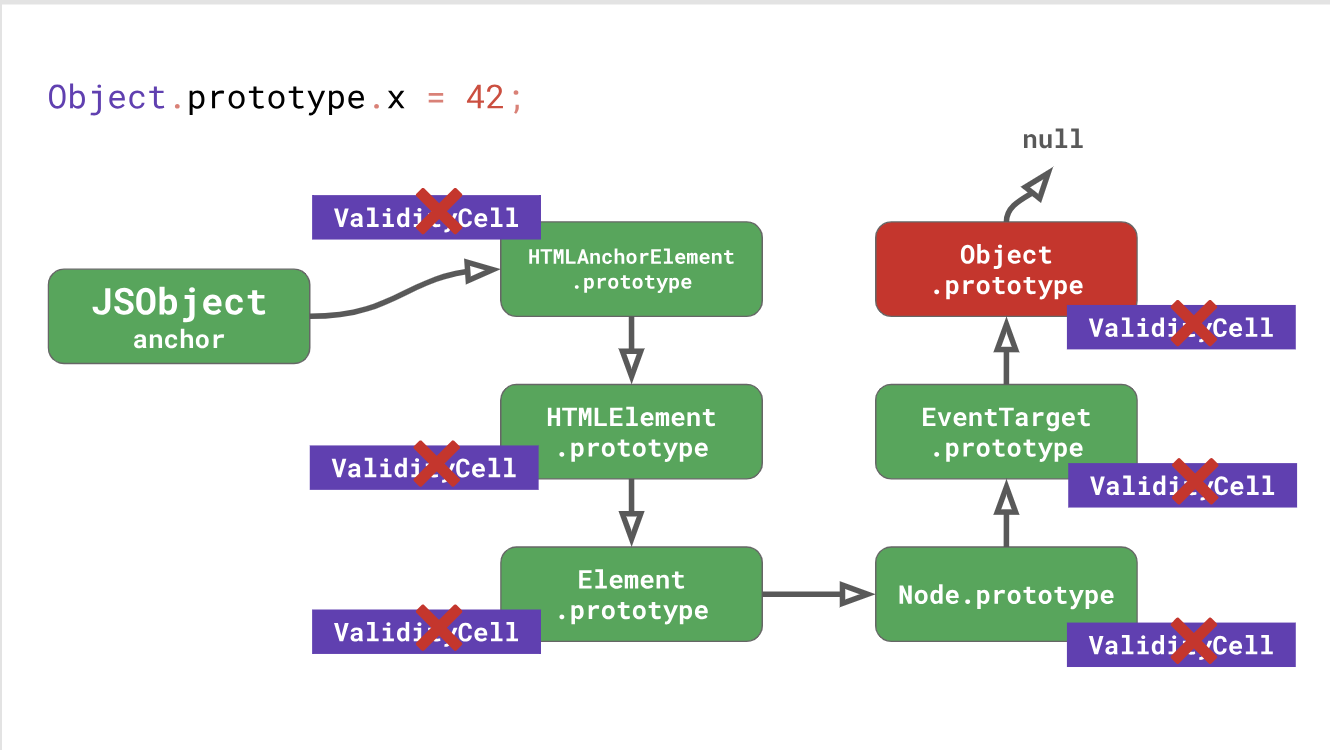
In fact, modifying the
Let's look at a specific example to better understand how this works. Let's say we have a class
The inline cache in
Changing
We are expanding
You think cleaning is a good idea, isn't it? Well, in this case, it will further worsen the situation! Deleting properties changes the
To summarize . Despite the fact that prototypes are just objects, they are specially processed by JavaScript engines in order to optimize the performance of searching methods by prototypes. Leave the prototypes alone! Or, if you really need to deal with them, do it before executing the code, so at least you do not invalidate all attempts to optimize your code in the process of its execution!
← First part
Was this publication series helpful to you? Write in the comments.
We also remind that the current publication is a continuation of these two articles: “Basics of JavaScript engines: common forms and Inline caching. Part 1 , Basics of JavaScript engines: common forms and inline caching. Part 2 " .
')
Classes and Prototype Programming
Now that we know how to get quick access to the properties of JavaScript objects, we can take a look at the more complex structure of JavaScript classes. This is what the JavaScript class syntax looks like:
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } Although it seems to be a relatively new concept for JavaScript, it’s just “syntactic sugar” for prototype programming that has always been used in JavaScript:
function Bar(x) { this.x = x; } Bar.prototype.getX = function getX() { return this.x; }; Here we assign the
getX property to the getX object. This will work the same as with any other object, since prototypes in JavaScript are the same objects. In prototype programming languages, such as JavaScript, methods are accessed through prototypes, while fields are stored in specific instances.Let's take a closer look at what happens when we create a new instance of
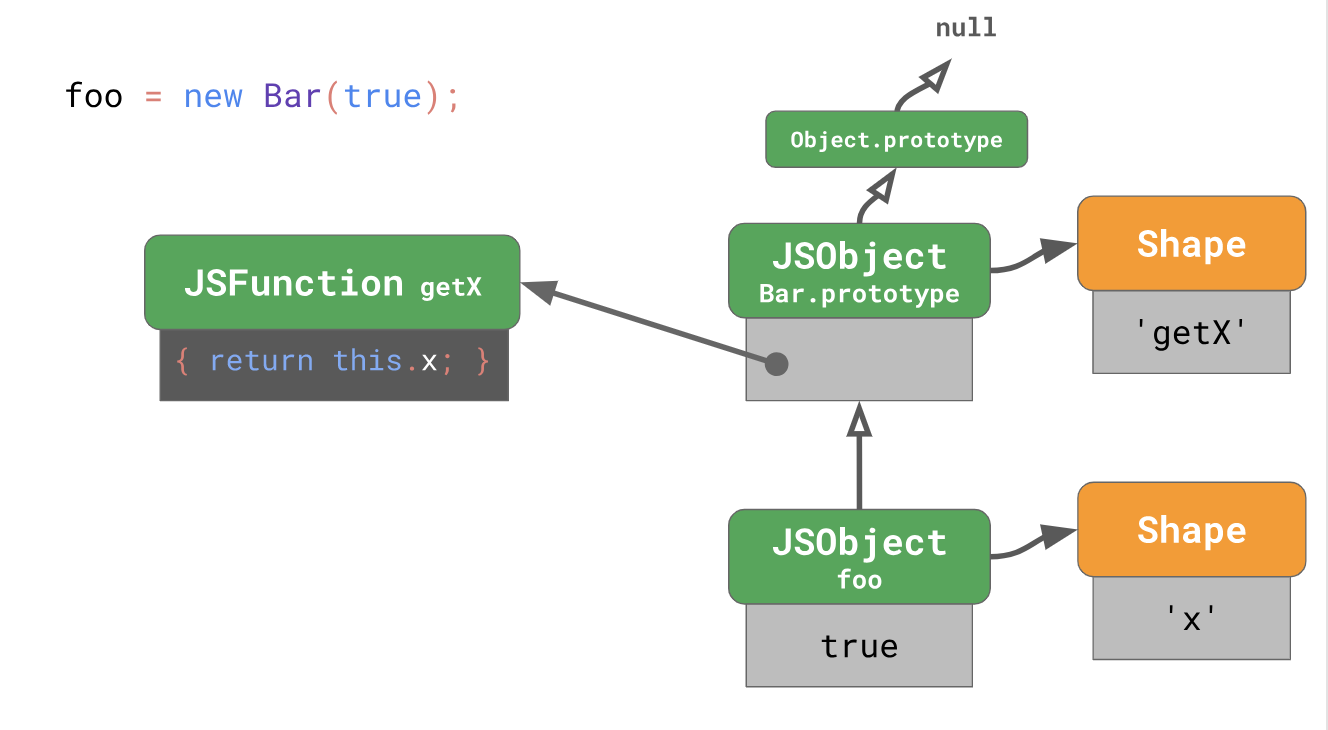
Bar , which we call foo . const foo = new Bar(true); The instance created using this code has a form with a single property
'x' . The prototype of foo is Bar.prototype , which belongs to the class Bar .This
Bar.prototype has the form of itself, containing the only property 'getX' , whose value is determined by the function 'getX' , which when called returns this.x The prototype Bar.prototype is the Object.prototype , which is part of the JavaScript language. Object.prototype is the root of the prototype tree, whereas its prototype is null .When you create a new instance of the same class, both instances have the same form, as we already understood earlier. Both instances will point to the same
Bar.prototype object.Access to prototype properties
Well, now we know what happens when we define a class and create a new instance. But what happens if we call a method on an instance, as we did in the following example?
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const x = foo.getX(); // ^^^^^^^^^^ You can view any method call as two separate steps:
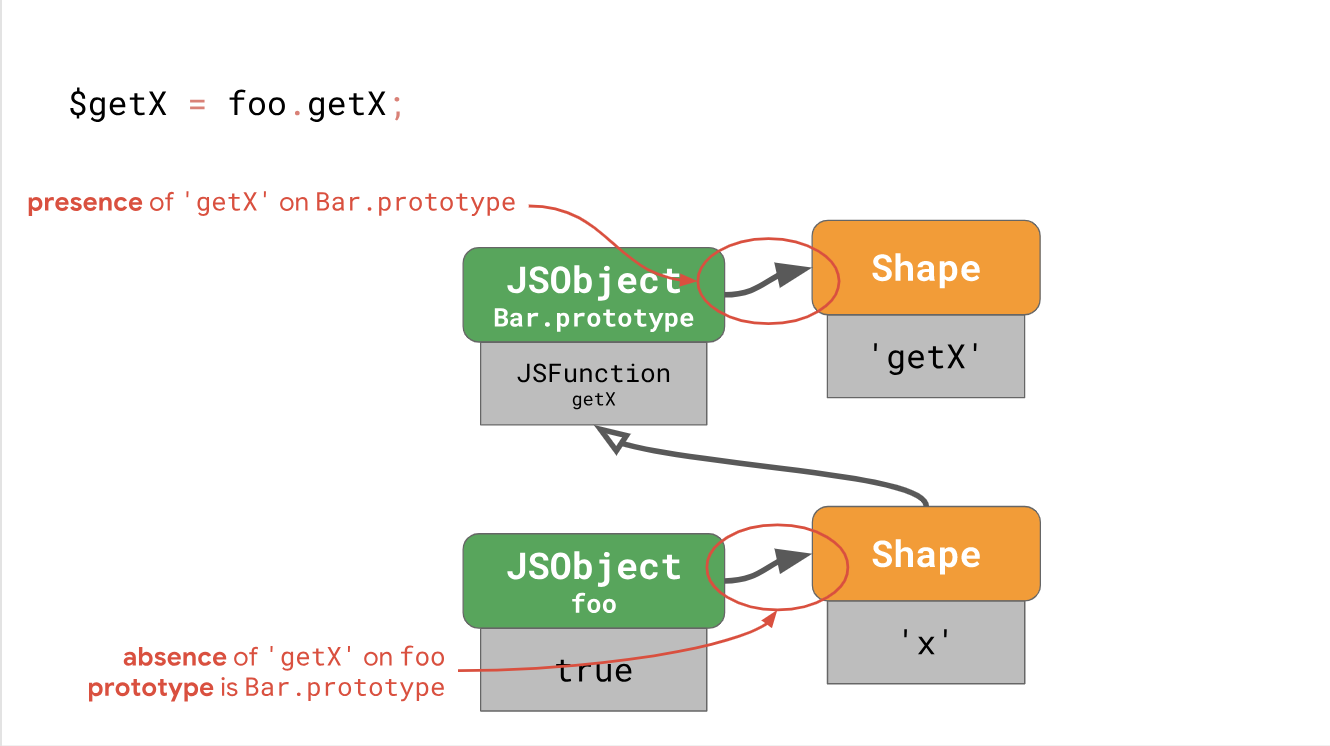
const x = foo.getX(); // is actually two steps: const $getX = foo.getX; const x = $getX.call(foo); The first step is to load the method, which is actually a property of the prototype (whose value is a function). The second step is a function call with an instance, for example, the value of
this . Let's take a closer look at the first step, in which the getX method is getX from the foo instance.The engine runs an instance of
foo and understands that the form foo does not have any property 'getX' , so it has to go through a prototype chain to find it. We get to Bar.prototype , we look at the prototype form, we see that it has the property 'getX' at zero offset. We look for the value at this offset in Bar.prototype and find the JSFunction getX we were looking for.JavaScript flexibility allows the links of the prototype chain to change, for example:
const foo = new Bar(true); foo.getX(); // → true Object.setPrototypeOf(foo, null); foo.getX(); // → Uncaught TypeError: foo.getX is not a function In this example, we call
foo.getX() twice, but each time it has completely different meanings and results. That is why, despite the fact that prototypes are just objects in JavaScript, speeding up access to prototype properties is even more important task for JavaScript engines than speeding up access to properties for regular objects.In everyday practice, loading prototype properties is quite a frequent operation: this happens every time you call a method!
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const x = foo.getX(); // ^^^^^^^^^^ Earlier we talked about how engines optimize the loading of regular (regular), own properties by using forms and inline caches. How can I optimize the loading of prototype properties for objects of the same form? From above, we have seen how properties are loaded.
In order to do this quickly with repeated downloads in this particular case, you need to know the following three things:
- The form
foodoes not contain'getX'and it has not changed. This means that no one has changed the foo object by adding or removing a property or changing one of the attributes of a property. - The prototype of foo is still the original
Bar.prototype. So no one changed the prototype offoousingObject.setPrototypeOf()or assigning it to a special_proto_property. - The form
Bar.prototypecontains'getX'and has not changed. This means that no one has changedBar.prototypeby adding or removing a property or changing one of the attributes of a property.
In general, this means that you need to make one check of the instance itself and two more checks for each prototype, up to the prototype that contains the desired property. 1 + 2N checks, where N is the number of prototypes used, does not sound so bad in this case, since the prototype chain is relatively shallow. However, engines often have to deal with much longer chains of prototypes, as is the case with regular DOM classes. For example:
const anchor = document.createElement('a'); // → HTMLAnchorElement const title = anchor.getAttribute('title'); We have
HTMLAnchorElement and we call the getAttribute() method. The chain for this element already includes 6 prototypes! Most of the interesting DOM methods are not in the prototype of HTMLAnchorElement , but somewhere upstream.The
getAttribute() method is in the Element.prototype . This means that every time we call anchor.getAttribute() , the JavaScript engine needs to:- Check that
'getAttribute'not ananchorobject itself; - Check that the final prototype is
HTMLAnchorElement.prototype; - Confirm the absence of
'getAttribute'there; - Check that the next prototype is
HTMLElement.prototype; - Confirm the absence of
'getAttribute'; - Check that the next prototype is
Element.prototype; - Check that
'getAttribute'present.
Total 7 checks obtained. Since this type of code is quite common on the web, the engines use various tricks to reduce the number of checks needed to load prototype properties.
Returning to an earlier example in which we did only three checks when we requested
'getX' for foo : class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const $getX = foo.getX; For each object that occurs before the prototype containing the desired property, it is necessary to check the forms for the absence of this property. It would be nice if we could reduce the number of checks by presenting a prototype check as a check for the absence of a property. In fact, this is exactly what the engines do with simple tricks: instead of storing the prototype link to the instance itself, the engines keep it in shape.
Each form indicates a prototype. This means that each time the
foo prototype changes, the engine moves to a new form. Now we need to check only the shape of the object to confirm the absence of certain properties, as well as to protect the prototype link (guard the prototype link).With this approach, we can reduce the number of required checks from 2N + 1 to 1 + N to speed up access. This is still a fairly expensive operation, since it is still a linear function of the number of prototypes in the circuit. The engines use various tricks to further reduce the number of checks to a certain constant value, especially in the case of sequential loading of the same properties.
Valid cells
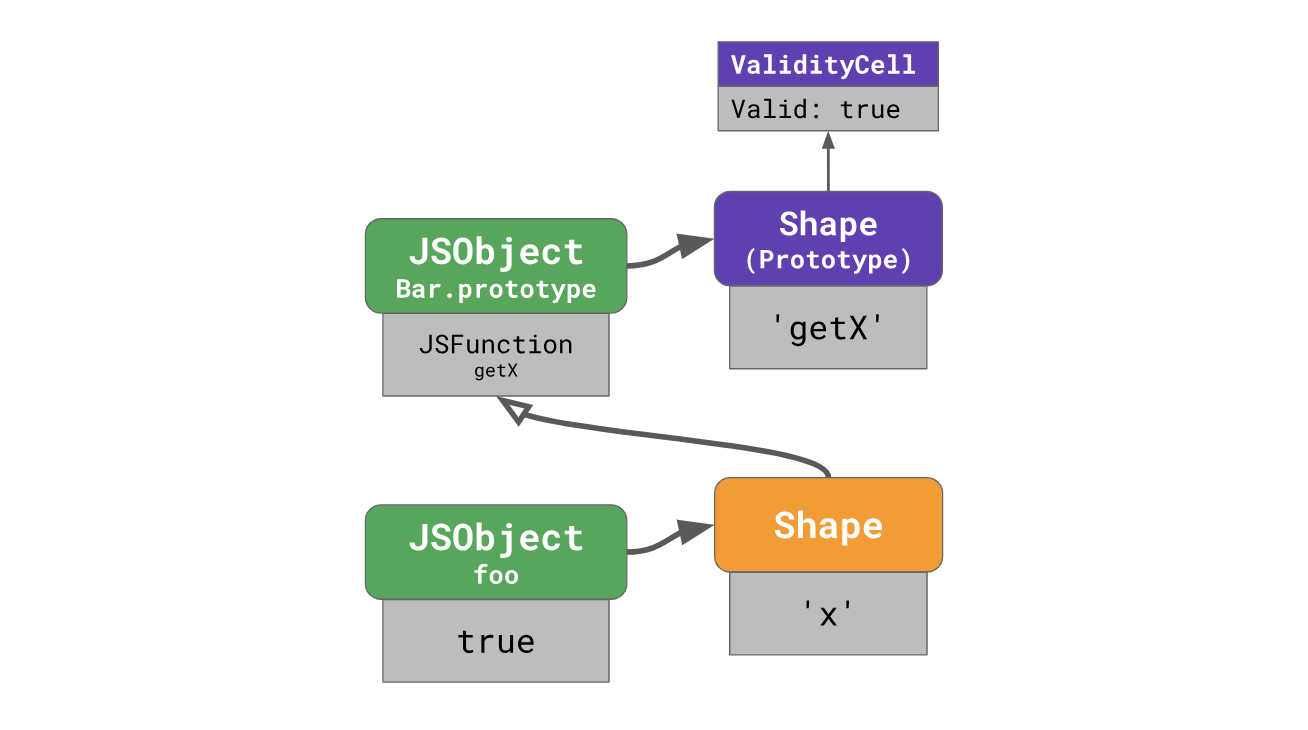
V8 handles prototype forms specifically for this purpose. Each prototype has a unique form that is not used in conjunction with other objects (in particular, with other prototypes), and each of these prototype forms has a special
ValidityCell , which is associated with it.This
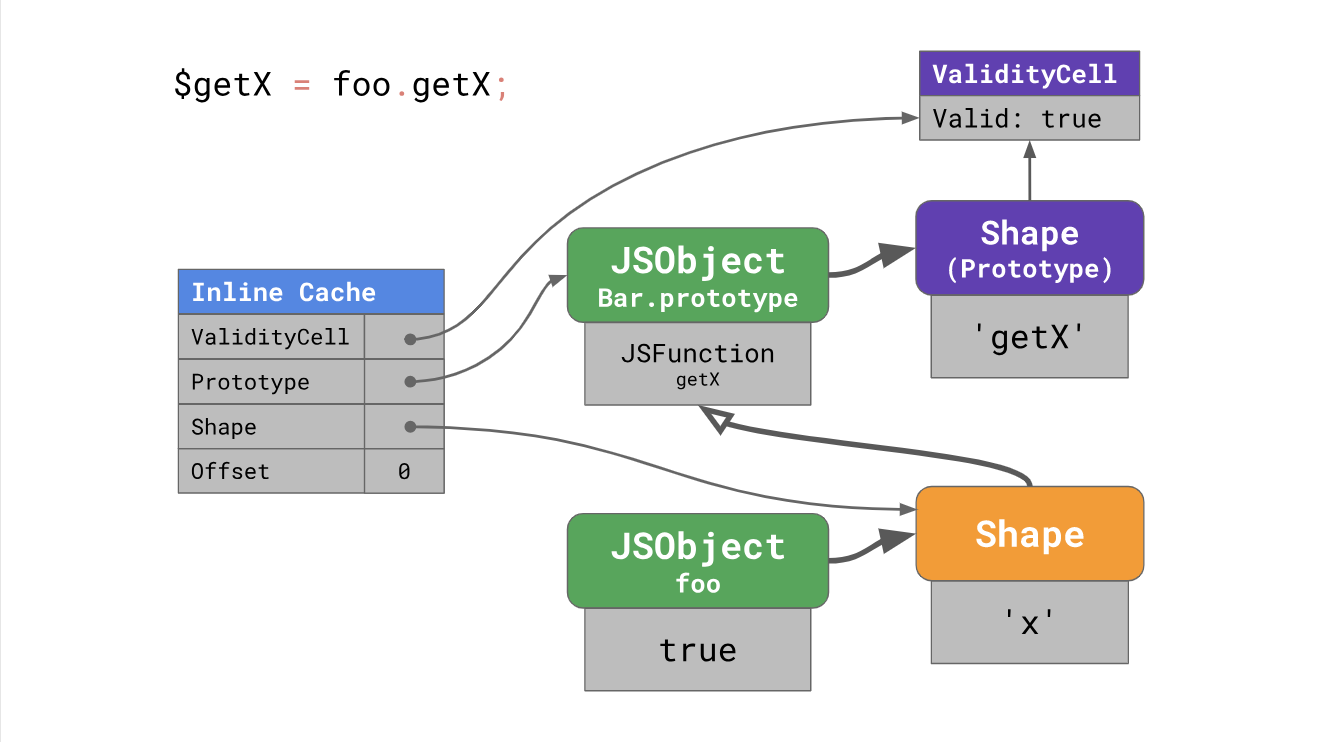
ValidityCell invalidated every time when someone changes the prototype associated with it or any other prototype above it. Let's see how it works.To speed up subsequent downloads from prototypes, the V8 places the inline cache in place with four fields:
When the inline cache is heated when the code is first run, V8 remembers the offset by which the property was found in the prototype, this prototype (for example,
Bar.prototype ), the instance form (in our case, the form foo ), and also binds the current ValidityCell to the prototype obtained from the form instance (in our case Bar.prototype is taken).The next time the Inline cache is used, the engine needs to check the instance form and
ValidityCell . If it is still valid, the engine directly uses the offset on the prototype, skipping the extra search steps.When the prototype changes, a new form is highlighted, and the previous
ValidityCell cell is disabled. Because of this, the inline cache is skipped the next time it starts up, resulting in poor performance.Let's go back to the DOM example. Every change in
Object.prototype not only invalidates Inline caches for Object.prototype , but also for any prototype in the chain under it, including EventTarget.prototype , Node.prototype , Element.prototype , etc., to the HTMLAnchorElement.prototype itself.In fact, modifying the
Object.prototype for as long as the code runs is a terrible loss of performance. Do not do this!Let's look at a specific example to better understand how this works. Let's say we have a class
Bar and a function loadX , which calls a method on objects of type Bar . We call the loadX function several times with instances of the same class. class Bar { /* … */ } function loadX(bar) { return bar.getX(); // IC for 'getX' on `Bar` instances. } loadX(new Bar(true)); loadX(new Bar(false)); // IC in `loadX` now links the `ValidityCell` for // `Bar.prototype`. Object.prototype.newMethod = y => y; // The `ValidityCell` in the `loadX` IC is invalid // now, because `Object.prototype` changed. The inline cache in
loadX now pointing to ValidityCell for Bar.prototype . If you then change (mutate) Object.prototype , which is the root of all the prototypes in JavaScript, ValidityCell becomes invalid and existing Inline caches will not be used next time, which leads to poor performance.Changing
Object.prototype is always a bad idea, as it invalidates any inline caches for loaded prototypes at the time of the change. Here is an example of how NOT to do: Object.prototype.foo = function() { /* … */ }; // Run critical code: someObject.foo(); // End of critical code. delete Object.prototype.foo; We are expanding
Object.prototype , which invalidates all Inline prototype caches loaded by the engine at this point. Then we run some code that uses the method we described. The engine will have to start from the very beginning and configure inline caches for any access to the prototype property. And then, finally, “tidying up after ourselves” and removing the method of the prototype, which we added earlier.You think cleaning is a good idea, isn't it? Well, in this case, it will further worsen the situation! Deleting properties changes the
Object.prototype , so that all Inline caches are again invalidated, and the engine has to start work from the very beginning again.To summarize . Despite the fact that prototypes are just objects, they are specially processed by JavaScript engines in order to optimize the performance of searching methods by prototypes. Leave the prototypes alone! Or, if you really need to deal with them, do it before executing the code, so at least you do not invalidate all attempts to optimize your code in the process of its execution!
Summarize
We learned how JavaScript stores objects and classes, and how forms, inline caches, and validity cells help optimize operations with prototypes. Based on this knowledge, we realized how to improve performance from a practical point of view: do not touch the prototypes! (or if you really need it, do it before executing the code).
← First part
Was this publication series helpful to you? Write in the comments.
Source: https://habr.com/ru/post/449144/
All Articles