We expand and supplement Kubernetes (review and video of the report)

On April 8, at the Saint HighLoad ++ 2019 conference, within the DevOps and Operation section, the report “Expand and supplement Kubernetes” was heard, in the creation of which three Fleet employees took part. In it, we talk about the many situations in which we wanted to expand and complement the capabilities of Kubernetes, but for which we did not find a ready and simple solution. The necessary solutions appeared in the form of Open Source-projects, and this presentation is also devoted to them.
By tradition, we are glad to present a video with the report (50 minutes, much more informative than the article) and the main squeeze in text form. Go!
')
Kernel and add-ons in K8s
Kubernetes is changing the industry and administrative approaches that have long been established:
- Thanks to his abstractions , we no longer operate with such concepts as configuring a config or launching a command (Chef, Ansible ...), but using grouping of containers, services, etc.
- We can prepare applications without thinking about the nuances of the specific site on which it will be launched: bare metal, the cloud of one of the providers, etc.
- With K8s, best practices in the organization of infrastructure have become more available than ever: scaling, self-healing, fault tolerance, etc.
However, of course, everything is not so smooth: with Kubernetes came their own - new - challenges.
Kubernetes is not a combine that solves all the problems of all users. The Kubernetes kernel is responsible only for the set of minimally necessary functions that are present in each cluster:
The core set of primitives is defined in the Kubernetes core - for grouping containers, traffic control, and so on. We talked about them in more detail in a 2-year-old report .
On the other hand, the K8s offers remarkable opportunities to expand the available features, which help to close and other - specific - user needs. For additions to Kubernetes, cluster administrators are responsible, who must install and configure everything they need to ensure that their cluster “takes on the necessary form” [to solve their specific tasks]. What are these additions? Consider some examples.
Examples of additions
Having established Kubernetes, we may be surprised that the network, so necessary for the interaction of the pods both within the node and between the nodes, does not work by itself. The Kubernetes kernel does not guarantee the necessary connections — instead, it defines the network interface ( CNI ) for third-party add-ons. We must install one of these add-ons, which will be responsible for the network configuration.

A close example is storage solutions (local disk, network block device, Ceph ...). Initially, they were in the kernel, but with the advent of CSI, the situation changes to a similar one already described: in Kubernetes interface, and its implementation - in third-party modules.
Among other examples:
- Ingress controllers (for a review, see our recent article ) .
- cert-manager :

- Operators are a whole class of add-ons (to which the cert-manager mentioned also applies), they define the primitive (s) and controller (s). The logic of their work is limited only by our imagination and allows you to turn ready-made infrastructure components (for example, a DBMS) into primitives, which are much easier to work with (than with a set of containers and their settings). There are a lot of operators written - even if many of them are not yet ready for production, it’s just a matter of time:
- Metrics are another illustration of how Kubernetes separated the interface (Metrics API) from implementation (third-party add-ons such as the Prometheus adapter, Datadog cluster agent ...).
- For monitoring and statistics , where in practice you need not only Prometheus and Grafana , but also kube-state-metrics, node-exporter, etc.
And this is far from a complete list of add-ons ... For example, we at the company "Flant" currently install 29 add-ons for each Kubernetes-cluster (all of them create a total of 249 Kubernetes objects). Simply put, we do not see the life of a cluster without additions.
Automation
Operators are designed to automate routine operations that we face every day. Here are examples from life, an excellent solution for which is to write an operator:
- There is a private (i.e. requiring login) registry with images for the application. It is assumed that each pod has a special secret associated with it, allowing it to be authenticated in the registry. Our task is to ensure that this secret is found in the namespace, so that pods can download images. There can be a lot of applications (each of which needs a secret), and it is useful to regularly update the secrets themselves, so the option of unfolding secrets with your hands disappears. This is where the operator comes to the rescue: we create a controller that will wait for the namespace to appear and add a secret to the namespace for this event.
- Let the default access from pods to the Internet is prohibited. But sometimes it may be required: it is logical that the access resolution mechanism works simply, without requiring specific skills, for example, by the presence of a certain label in the namespace. How can the operator help us here? A controller is created that waits for a label to appear in the namespace and adds the appropriate policy for Internet access.
- A similar situation: even if we needed to add a certain taint to the node, if it has a similar label (with some kind of prefix). Operator actions are obvious ...
In any cluster, it is necessary to solve routine tasks, and to do it correctly - with the help of operators.
Summing up all the described stories, we came to the conclusion that for comfortable work in Kubernetes it is required : a) to install add-ons , b) to develop operators (to solve everyday admin tasks).
How to write an operator for Kubernetes?
In general, the scheme is simple:
... but it turns out that:
- Kubernetes API is a fairly non-trivial thing that takes a lot of time to master;
- programming is not for everyone either (Go is selected as preferred because there is a special framework for it - Operator SDK );
- with the framework itself, a similar situation.
Bottom line: to write a controller (operator) you have to spend significant resources to study the materiel. This would be justified for “large” operators - say, for MySQL DBMS. But if we recall the examples described above (unfolding secrets, accessing pods to the Internet ...), which we also want to do right, we will understand that the effort expended will outweigh the result we need now:

In general, a dilemma arises: spend a lot of resources and find the right tool for writing operators or act in the old way (but quickly). To solve it - finding a compromise between these extremes - we created our own project: a shell-operator (see also its recent announcement on Habré) .
Shell-operator
How does he work? In the cluster there is a pod in which the Go-binary with a shell-operator lies. A set of hooks is stored next to it (for more details, see below) . The shell-operator itself subscribes to certain events in the Kubernetes API, upon the occurrence of which it launches the corresponding hooks.
How does a shell-operator understand what hooks to trigger on what events? This information is passed to the shell-operator by the hooks themselves and they make it very simple.
A hook is a script in Bash or any other executable file that supports the single argument
--config and returns JSON in response. The latter determines which objects it is interested in and which events (for these objects) should be responded to:
I will illustrate the implementation on a shell-operator of one of our examples - unfolding secrets for accessing a private registry with application images. It consists of two stages.
Practice: 1. We write a hook
First of all, in the hook, we will process
--config , indicating that we are interested in namespaces, and specifically - the moment of their creation: [[ $1 == "--config" ]] ; then cat << EOF { "onKubernetesEvent": [ { "kind": "namespace", "event": ["add"] } ] } EOF … What would logic look like? Pretty simple too:
… else createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH) kubectl create -n ${createdNamespace} -f - << EOF Kind: Secret ... EOF fi The first step is to find out which namespace was created, and the second is to create a secret for this namespace through
kubectl .Practice: 2. Putting an image
It remains to pass the shell-operator created hook - how to do it? The shell-operator itself comes in the form of a Docker image, so our task is to add a hook to a special directory in this image:
FROM flant/shell-operator:v1.0.0-beta.1 ADD my-handler.sh /hooks It remains to collect it and push it:
$ docker build -t registry.example.com/my-operator:v1 . $ docker push registry.example.com/my-operator:v1 The final touch is to enclose the image in a cluster. To do this, write Deployment :
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: my-operator spec: template: spec: containers: - name: my-operator image: registry.example.com/my-operator:v1 # 1 serviceAccountName: my-operator # 2 It is necessary to pay attention to two points:
- an indication of the newly created image;
- This is a system component, which (at a minimum) needs rights to subscribe to events in Kubernetes and to lay out secrets by namespaces, so we create a ServiceAccount (and a set of rules) for the hook.
Result - we solved our problem in the Kubernetes way, creating an operator for unfolding secrets.
Other shell-operator features
To restrict the objects of the type you choose with which the hook will work, you can filter them by selecting them by specific labels (or using
matchExpressions ): "onKubernetesEvent": [ { "selector": { "matchLabels": { "foo": "bar", }, "matchExpressions": [ { "key": "allow", "operation": "In", "values": ["wan", "warehouse"], }, ], } … } ] There is a deduplication mechanism , which - using the jq-filter - allows you to convert large JSON's of objects into small ones, where only those parameters remain that we want to monitor for changes.
When calling a hook, a shell-operator sends it data about the object that can be used for any needs.
Events that occur when hooks are triggered are not limited to Kubernetes events: the shell operator has support for calling hooks by time (similar to crontab in the traditional scheduler), as well as the special onStartup event. All these events can be combined and assigned to the same hook.
And two more features of a shell-operator:
- It works asynchronously . From the moment the Kubernetes event was received (for example, the creation of an object) other events could have occurred in the cluster (for example, the deletion of the same object), and this should be taken into account in hooks. If the hook was executed with an error, then by default it will be recalled until successful completion (this behavior can be changed).
- It exports metrics for Prometheus, with the help of which you can understand whether a shell-operator works, find out the number of errors for each hook and the current queue size.
Summing up this part of the report:

Install Add-ons
For comfortable work with Kubernetes, the need to install add-ons was also mentioned. I will tell about it on the example of the way of our company to how we do it now.
We started working with Kubernetes with several clusters, the only addition in which was Ingress. It was required to install it in each cluster differently, and we made several YAML configurations for different environments: bare metal, AWS ...
Clusters became more - more became and configurations. In addition, we improved these configurations themselves, as a result of which they became quite heterogeneous:
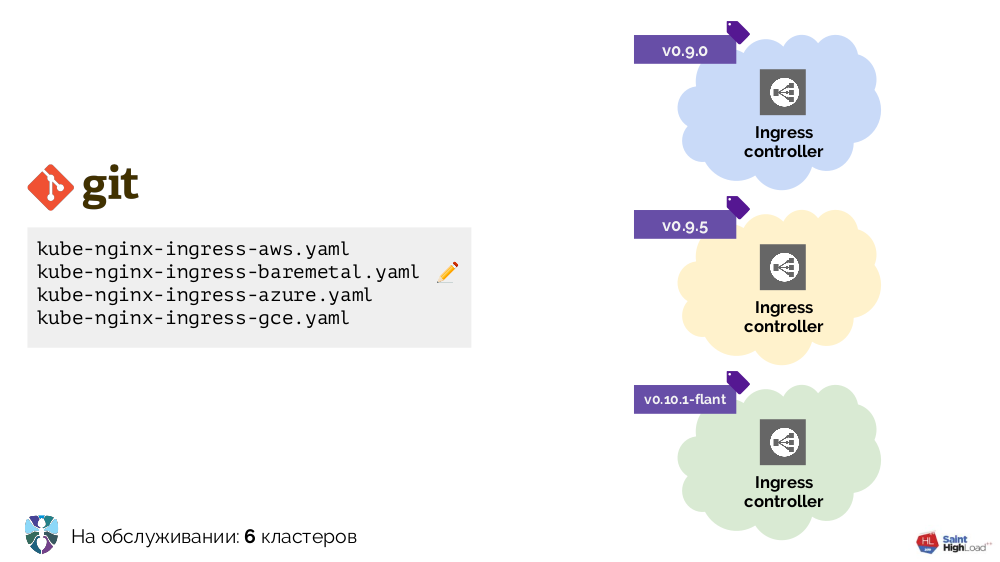
To put everything in order, we started with a script (
install-ingress.sh ), which took as an argument the type of cluster into which we deploy, generated the necessary YAML configuration and rolled it into Kubernetes.In short, our further path and reasoning related to it were as follows:
- To work with YAML configurations, a template engine is required (in the first stages, this is a simple sed);
- as the number of clusters grows, the need for an automatic update came (the earliest solution was to put the script in Git, we update and run it using cron);
- A similar script was needed for Prometheus (
install-prometheus.sh), however, it is remarkable that it requires much more input data, as well as their storage (in a good way - centralized and in a cluster), and some data (passwords) could be automatically generated :
- the risk of rolling out something wrong on a growing number of clusters was constantly growing, so we realized that the installers (i.e. two scripts: for Ingress and Prometheus) needed staging (several branches in Git, several cron'ov to update them in the corresponding: stable or test clusters);
- it became difficult to work with
kubectl apply, because it is not declarative and can only create objects, but not make decisions on their status / delete them; - some functions that we didn’t realize at all at that time were missing:
- full control of the result of the cluster update,
- automatic detection of certain parameters (input for installation scripts) based on data that can be obtained from the cluster (discovery),
- its logical development in the form of continuous discovery.
We have implemented all this accumulated experience as part of our other project, the addon-operator .
Addon-operator
It is based on the shell-operator already mentioned. The whole system looks like this:
The shell-operator hooks are added:
- repository values ,
- Helm chart
- the component that keeps track of the values' storage and, in case of any changes, asks Helm to re-roll the chart.

Thus, we can react to the event in Kubernetes, run the hook, and from this hook make changes to the repository, after which the chart will be redrawn. In the resulting scheme, we select a set of hooks and a chart into one component, which we call a module :
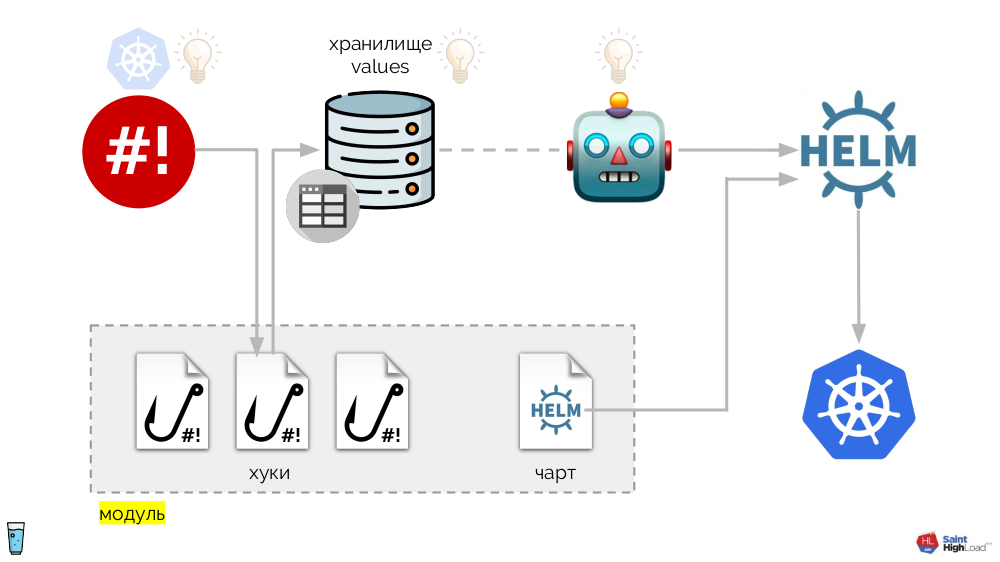
There can be many modules, and to them we add global hooks, global values store and component that monitors this global store.
Now that something is happening in Kubernetes, we can react to it with a global hook and change something in the global repository. This change will be noticed and will cause all modules in the cluster to roll out:
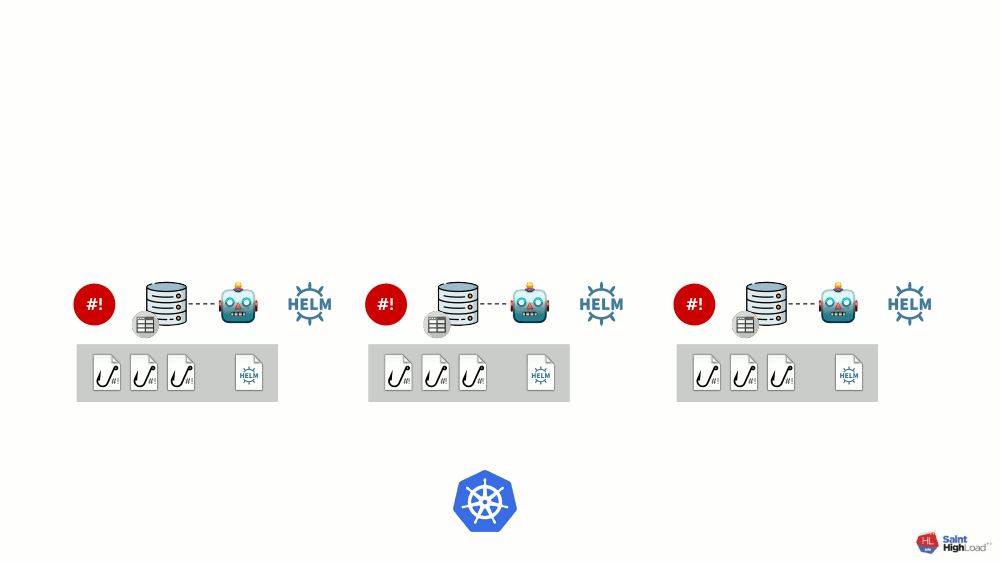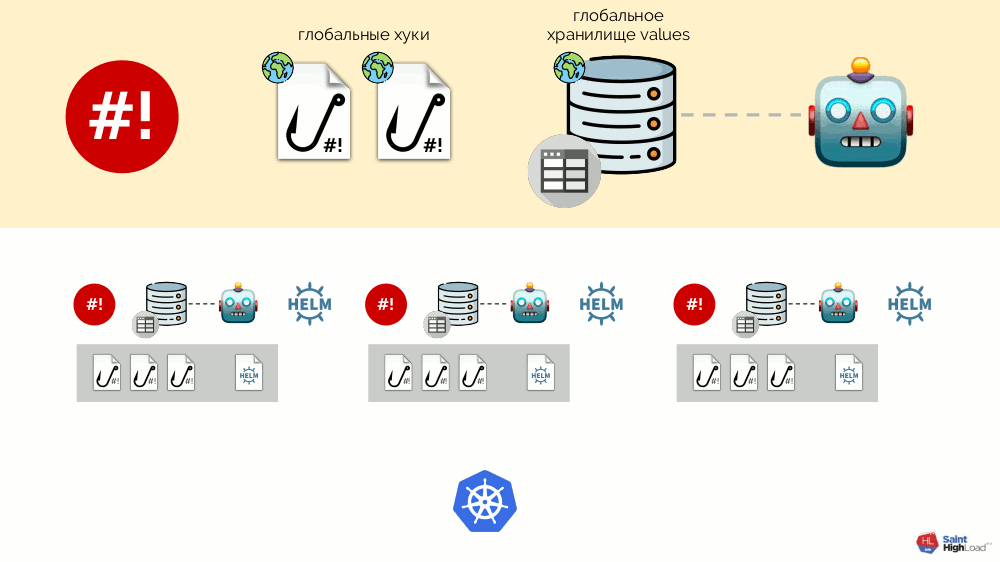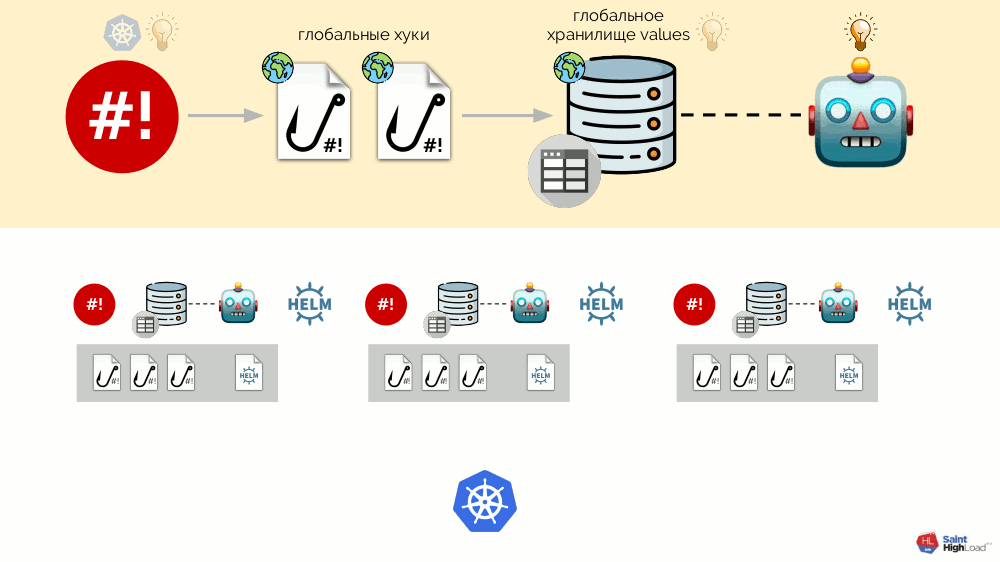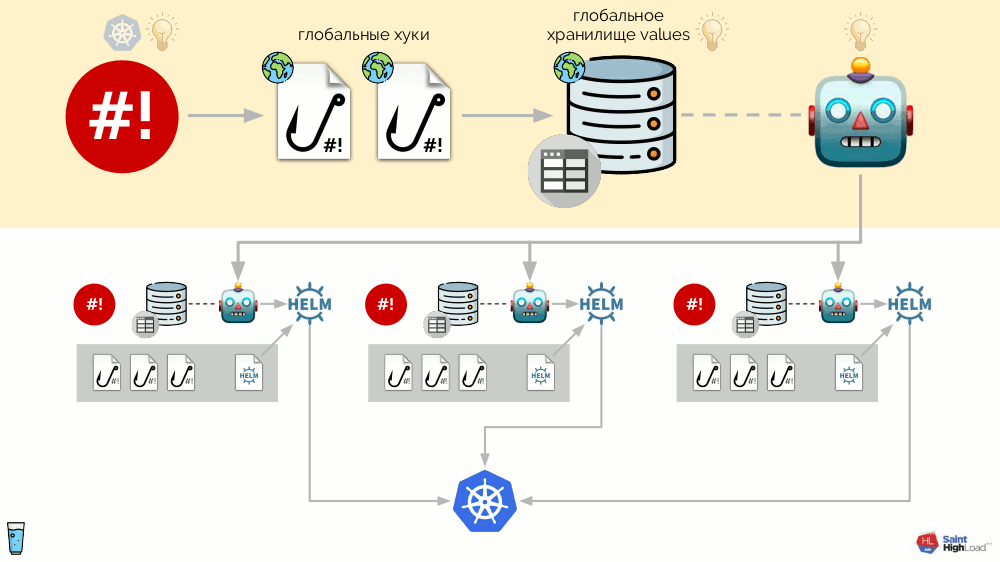
This scheme satisfies all the requirements for installing add-ons that have been voiced above:
- Helm is responsible for standardization and declarativeness.
- The issue of auto-update has been resolved with the help of a global hook, which, according to the schedule, goes to the registry and, if it sees a new image of the system there, re-rolls it (ie, “itself”).
- The storage of settings in the cluster is implemented using ConfigMap , in which the primary data for the storages are recorded (at startup they are loaded into the storages).
- Problems of password generation, discovery and continuous discovery are solved with the help of hooks.
- Staging is achieved thanks to tags that Docker supports out of the box.
- The control of the result is made with the help of metrics by which we can understand the status.
This entire system is implemented as a single binary on Go, which is called the addon-operator. Thanks to this scheme looks simpler:

The main component on this diagram is a set of modules (highlighted in gray below) . Now we can, with little effort, write a module for the desired add-on and be sure that it will be installed in each cluster, updated and respond to the events it needs in the cluster.
"Flant" uses addon-operator on 70+ Kubernetes-clusters. The current status is alpha version . Now we are preparing documentation to release a beta, but for now examples are available in the repository, on the basis of which you can create your addon.
Where can I get the modules for addon-operator? Publishing our library is the next stage for us, we plan to do it in the summer.
Video and slides
Video from the performance (~ 50 minutes):
Presentation of the report:
PS
Other reports on our blog:
- " Databases and Kubernetes "; (Dmitry Stolyarov; November 8, 2018 on HighLoad ++) ;
- “ Monitoring and Kubernetes ”; (Dmitry Stolyarov; May 28, 2018 on RootConf) ;
- " Best Practices CI / CD with Kubernetes and GitLab "; (Dmitry Stolyarov; November 7, 2017 on HighLoad ++) ;
- “ Our experience with Kubernetes in small projects ”; (Dmitry Stolyarov; June 6, 2017 at RootConf) .
You may also be interested in the following publications:
Source: https://habr.com/ru/post/449096/
All Articles