The architecture of the network load balancer in Yandeks.Oblak

Hi, I'm Sergey Elantsev, I am developing a network load balancer in Yandex. Cloud. I used to lead the development of the L7-balancer of the Yandex portal - my colleagues joke that whatever I do, it turns out the balancer. I will tell Habr readers how to manage the load in the cloud platform, how we see the ideal tool to achieve this goal and how we are moving towards building this tool.
First, we introduce some terms:
- VIP (Virtual IP) - balancer's IP address
- Server, Backend, Instance — Virtual Machine Running Application
- RIP (Real IP) - server IP address
- Healthcheck - server readiness check
- Availability Zone, Availability Zone, AZ - isolated infrastructure in the data center
- Region - Association of Different AZ
Load balancers solve three main tasks: perform the balancing itself, improve the fault tolerance of the service and simplify its scaling. Fault tolerance is provided by automatic traffic control: the balancer monitors the state of the application and excludes from the balance instances that have not passed the liveliness test. Scaling is ensured by evenly distributing the load across the instances, as well as updating the list of instances on the fly. If balancing is not sufficiently uniform, then some of the instans will receive a load that exceeds their limit of serviceability, and the service will become less reliable.
')
The load balancer is often classified by protocol level from the OSI model on which it runs. Cloud Balancer works at TCP level, which corresponds to the fourth level, L4.
Let us turn to the review of the architecture of the Cloud balancer. We will gradually increase the level of detail. We divide the balancer components into three classes. The class config plane is responsible for user interaction and stores the target state of the system. The Control plane stores the current state of the system and manages the systems from the data plane class, which are directly responsible for delivering traffic from clients to your instances.
Data plane
Traffic hits a costly device called border routers. To increase resiliency in one data center at the same time several such devices work. Further, the traffic gets to the balancers, which for customers announce anycast IP-address to all AZ via BGP.
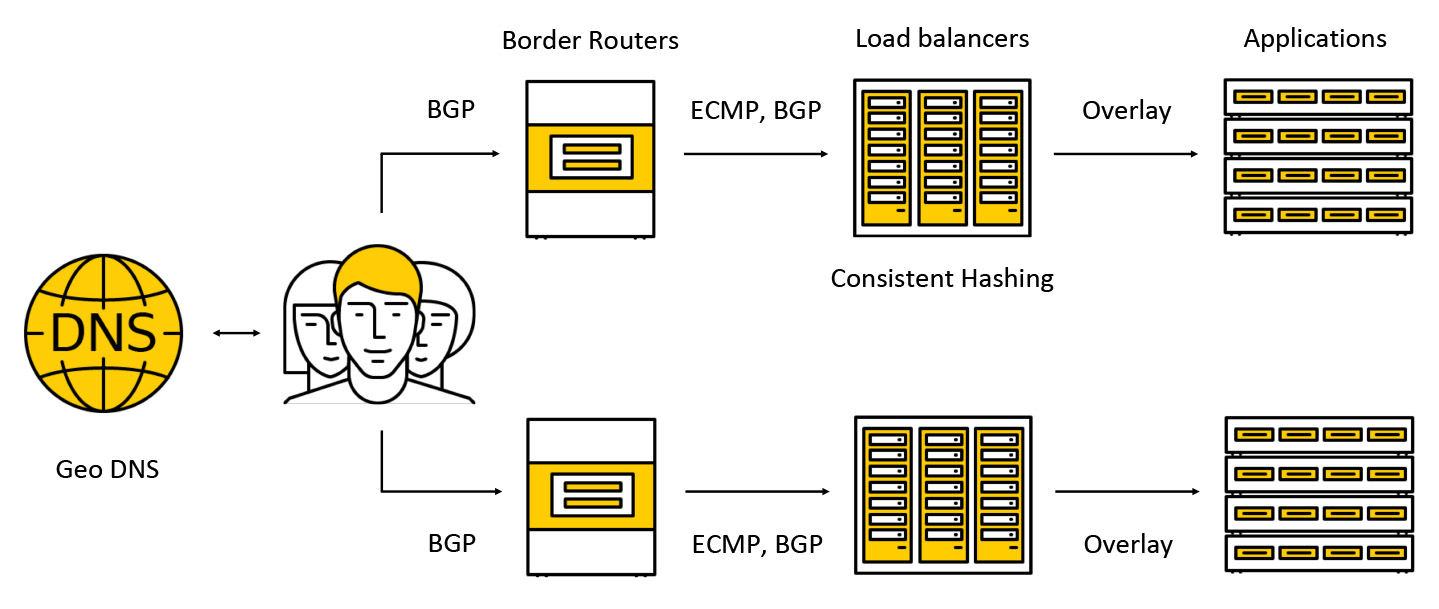
The traffic is transmitted via ECMP - this is a routing strategy, according to which there may be several equally good routes to the target (in our case, the destination will be the IP address) and packets can be sent on any of them. We also support work in several availability zones according to the following scheme: we announce the address in each of the zones, the traffic gets to the closest one and does not go beyond its limits. Further in the post, we will take a closer look at what happens to the traffic.
Config plane
The key component of the config plane is the API through which basic operations with balancers are performed: creating, deleting, changing the composition of instances, obtaining healthchecks results, etc. On the one hand, this is the REST API, and on the other, we very often use the framework in the Cloud gRPC, so we "translate" REST into gRPC and then use only gRPC. Any query leads to the creation of a series of asynchronous idempotent tasks that are performed on the common pool of Yandex.Oblack workers. Tasks are written in such a way that they can be suspended at any time, and then re-launched. It provides scalability, repeatability and logability of operations.

As a result, the task from the API will make a request to the balance controller service controller, which is written on Go. It can add and remove balancers, change the composition of backends and settings.
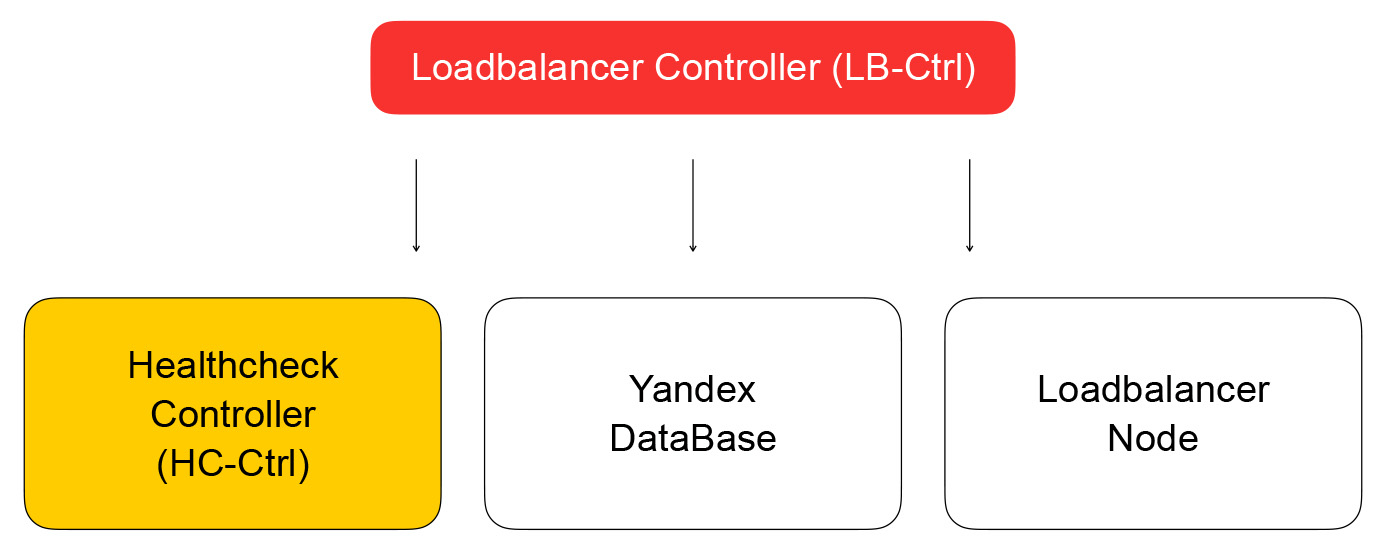
The service stores its status in Yandex Database - a distributed managed database, which you will soon be able to use. In Yandex.Oblak, as we have already said , the dog food concept works: if we ourselves use our services, then our customers will also enjoy using them. Yandex Database is an example of such a concept. We store all our data in YDB, and we don’t have to think about servicing and scaling the base: these problems are solved for us, we use the base as a service.
We return to the controller balancer. His task is to save information about the balancer, send the task of checking the readiness of the virtual machine to the healthcheck controller.
Healthcheck controller
It receives requests to change the inspection rules, stores them in YDB, distributes tasks to healtcheck nodes and aggregates the results, which are then saved to the database and sent to the loadbalancer controller. He, in turn, sends a request to change the composition of the cluster in the data plane to a loadbalancer-node, which I will discuss below.

Let's talk more about healthchecks. They can be divided into several classes. Checks have different criteria for success. TCP checks need to successfully establish a connection in a fixed time. HTTP checks require both a successful connection and a response with a status code of 200.
Also, checks differ in the class of action - they are active and passive. Passive checks simply monitor what happens to the traffic, without taking any special action. This does not work very well on L4, because it depends on the logic of the higher level protocols: on L4, there is no information about how long the operation took, and whether the connection was good or bad. Active checks require the balancer to send requests to each server instance.
Most load balancers perform liveliness checks themselves. We in the Cloud decided to separate these parts of the system to increase scalability. This approach will allow us to increase the number of balancers, while maintaining the number of healthcheck requests to the service. Checks are performed by individual healthcheck nodes, which are shaded and replicated audit targets. You can not do checks from one host, as it can refuse. Then we will not get the state of the instances checked by him. We perform checks on any of the instances from at least three healthcheck nodes. We shuffle audit targets between nodes using consistent hashing algorithms.

Separation of balancing and healthcheck can lead to problems. If healthcheck node makes requests to an instance, bypassing the balancer (which currently does not serve traffic), then a strange situation arises: the resource seems to be alive, but traffic will not reach it. We solve this problem like this: guaranteed to get healthcheck traffic through balancers. In other words, the scheme for moving packets with traffic from clients and healthchecks differs minimally: in both cases, the packets will go to balancers, who will deliver them to the target resources.
The difference is that customers make VIP requests, and healthchecks access each individual RIP. Here an interesting problem arises: we give our users the ability to create resources in gray IP networks. Imagine that there are two different cloud owners who hid their services behind balancers. Each of them has resources in the subnet 10.0.0.1/24, and with the same addresses. You need to be able to somehow distinguish them, and here you have to dive into the device of the Yandex.Oblak virtual network. It is better to find out more details in the video from the event about: cloud , now it is important for us that the network is multi-layered and has tunnels in itself that can be distinguished by the subnet id.
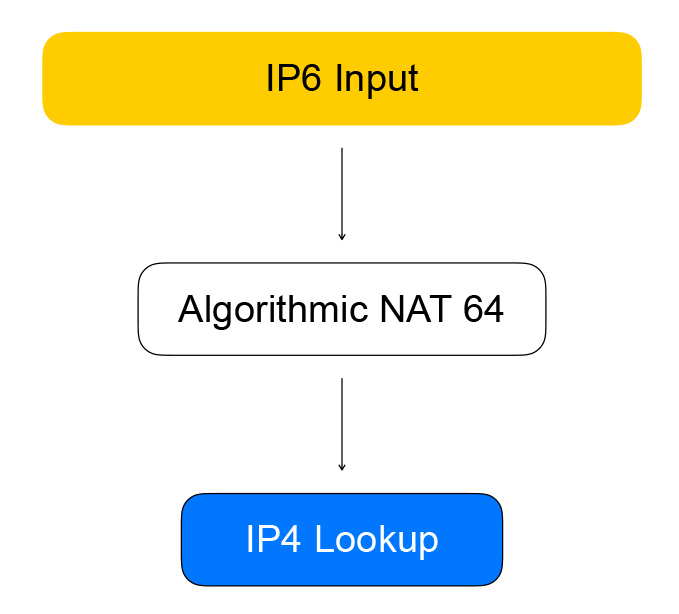
Healthcheck nodes access balancers using so-called quasi-IPv6 addresses. A quasi-address is an IPv6 address within which the IPv4 address and id of the user's subnet are stitched. The traffic hits the balancer, it extracts the IPv4 address of the resource from it, replaces IPv6 with IPv4 and sends the packet to the user's network.
Reverse traffic goes the same way: the balancer sees that the destination is a gray network of healthcheckers, and converts IPv4 to IPv6.
VPP - the heart of the data plane
The balancer is implemented on the Vector Packet Processing (VPP) technology - a framework from Cisco for packet network traffic processing. In our case, the framework runs on top of the user-space-management network device library, the Data Plane Development Kit (DPDK). This provides high packet processing performance: much less interrupts occur in the kernel, there are no context switches between kernel space and user space.
VPP goes even further and squeezes even more performance out of the system by combining packages into batchy. Increased performance is due to the aggressive use of modern processor caches. Both data caches are used (packets are processed by “vectors”, data lie close to each other) and instruction caches: in VPP, packet processing follows a graph, in the nodes of which there are functions that perform the same task.
For example, IP packets are processed in VPP in the following order: first, the parsing of packet headers occurs in the parse node, and then they are sent to the node, which forwards packets further according to the routing tables.
A little hardcore. The VPP authors do not tolerate compromises on the use of processor caches, so the typical code for processing the packet vector contains a manual vectorization: there is a processing cycle in which the situation is “we have four packets in a queue”, then the same for two, then for one. Often, prefetch instructions are used that load data into caches to speed up access to them at subsequent iterations.
n_left_from = frame->n_vectors; while (n_left_from > 0) { vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next); // ... while (n_left_from >= 4 && n_left_to_next >= 2) { // processing multiple packets at once u32 next0 = SAMPLE_NEXT_INTERFACE_OUTPUT; u32 next1 = SAMPLE_NEXT_INTERFACE_OUTPUT; // ... /* Prefetch next iteration. */ { vlib_buffer_t *p2, *p3; p2 = vlib_get_buffer (vm, from[2]); p3 = vlib_get_buffer (vm, from[3]); vlib_prefetch_buffer_header (p2, LOAD); vlib_prefetch_buffer_header (p3, LOAD); CLIB_PREFETCH (p2->data, CLIB_CACHE_LINE_BYTES, STORE); CLIB_PREFETCH (p3->data, CLIB_CACHE_LINE_BYTES, STORE); } // actually process data /* verify speculative enqueues, maybe switch current next frame */ vlib_validate_buffer_enqueue_x2 (vm, node, next_index, to_next, n_left_to_next, bi0, bi1, next0, next1); } while (n_left_from > 0 && n_left_to_next > 0) { // processing packets by one } // processed batch vlib_put_next_frame (vm, node, next_index, n_left_to_next); } So, Healthchecks are turning to VPP over IPv6, which turns them into IPv4. This is done by the node graph, which we call algorithmic NAT. For reverse traffic (and conversion from IPv6 to IPv4) there is the same node of algorithmic NAT.
Direct traffic from clients of the balancer goes through the nodes of the graph, which perform the balancing itself.

The first node is sticky sessions. It stores a hash from 5-tuple for established sessions. 5-tuple includes the address and port of the client from which information is transmitted, the address and ports of resources available for receiving traffic, as well as the network protocol.
The 5-tuple hash helps us perform fewer computations in a subsequent consistent hash node, and also better handle the change in the list of resources behind the balancer. When a packet arrives at the balancer, for which there is no session, it is sent to the consistent hashing node. Here balancing occurs with the help of consistent hashing: we select a resource from the list of available “living” resources. Next, the packets are sent to the NAT node, which actually replaces the destination address and recalculates the checksums. As you can see, we follow the rules of VPP - similar to similar, grouping similar calculations to increase the efficiency of processor caches.
Consistent hashing
Why did we choose it and what is it all about? To begin, consider the previous task - selecting a resource from the list.
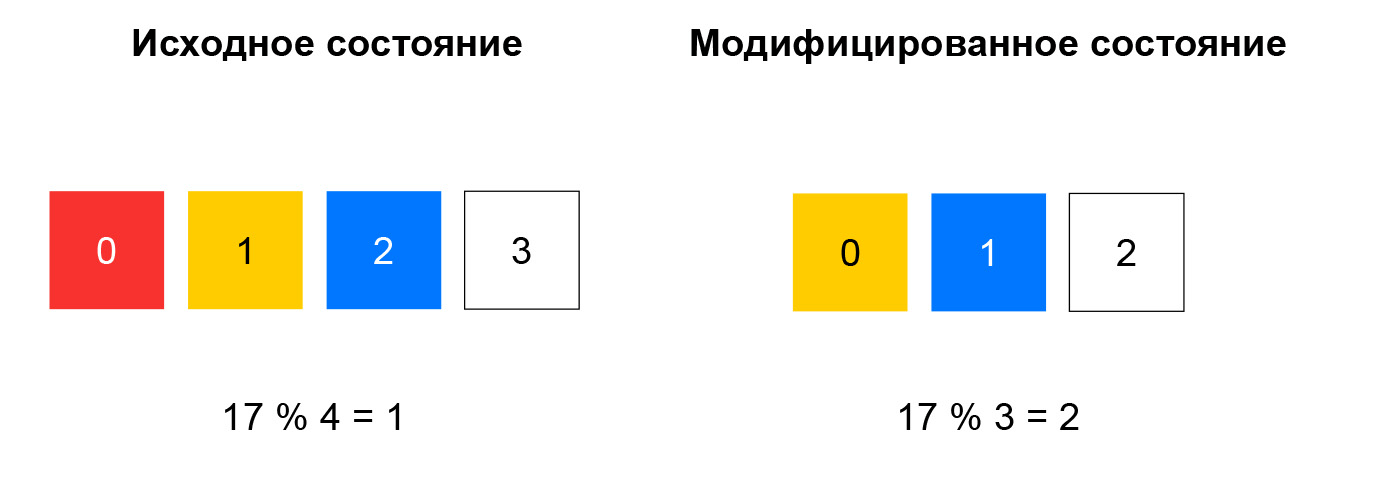
In case of inconsistent hashing, the hash from the incoming packet is calculated, and the resource is selected from the list based on the remainder of dividing this hash by the amount of resources. While the list remains unchanged, such a scheme works well: we always send packets with the same 5-tuple to the same instance. If, for example, a resource stopped responding to healthchecks, then for a significant portion of the hashes, the choice will change. The client will break TCP connections: a packet that previously got to instance A may start to get to instance B, which is not familiar with the session for this packet.
Consistent hashing solves the problem described. The easiest way to explain this concept is this: imagine that you have a ring for which you allocate resources by hash (for example, by IP: port). The choice of resource is the rotation of the wheel at an angle, which is determined by the hash of the package.
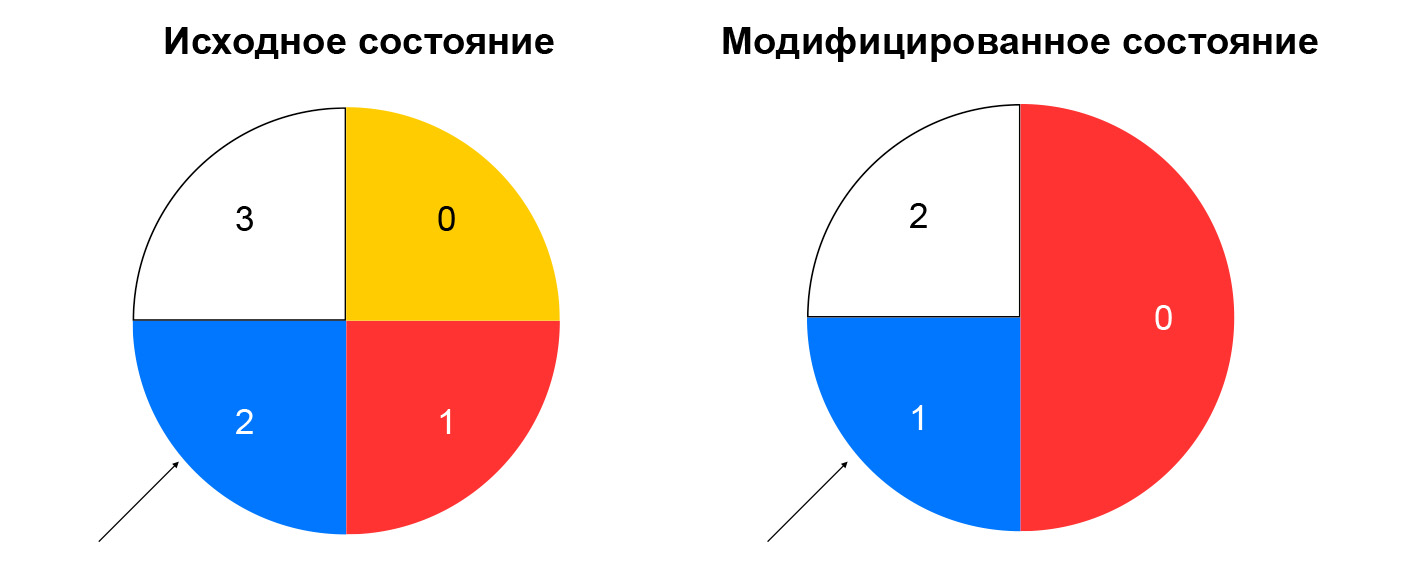
This minimizes the redistribution of traffic when the composition of resources changes. Deleting a resource will only affect the part of the consistent hashing ring where the resource was located. Adding a resource also changes the distribution, but we have a sticky sessions node that allows us not to switch already established sessions to new resources.
We looked at what happens with direct traffic between the balancer and resources. Now let's deal with the return traffic. It follows the same pattern as verification traffic — through algorithmic NAT, that is, through reverse NAT 44 for client traffic and through NAT 46 for healthchecks traffic. We follow our own scheme: we unify healthchecks traffic and real users traffic.
Loadbalancer-node and component assembly
The composition of the balancers and resources in the VPP is reported by the local service loadbalancer-node. It subscribes to the stream of events from loadbalancer-controller, and is able to build the difference between the current state of the VPP and the target state received from the controller. We get a closed system: events from the API come to the balancer controller, which sets the healthcheck controller tasks to check the "liveliness" of resources. That, in turn, sets the tasks in the healthcheck-node and aggregates the results, after which it gives them back to the balancer controller. Loadbalancer-node subscribes to events from the controller and changes the state of the VPP. In such a system, each service knows only what is necessary about neighboring services. The number of links is limited, and we have the ability to independently exploit and scale different segments.
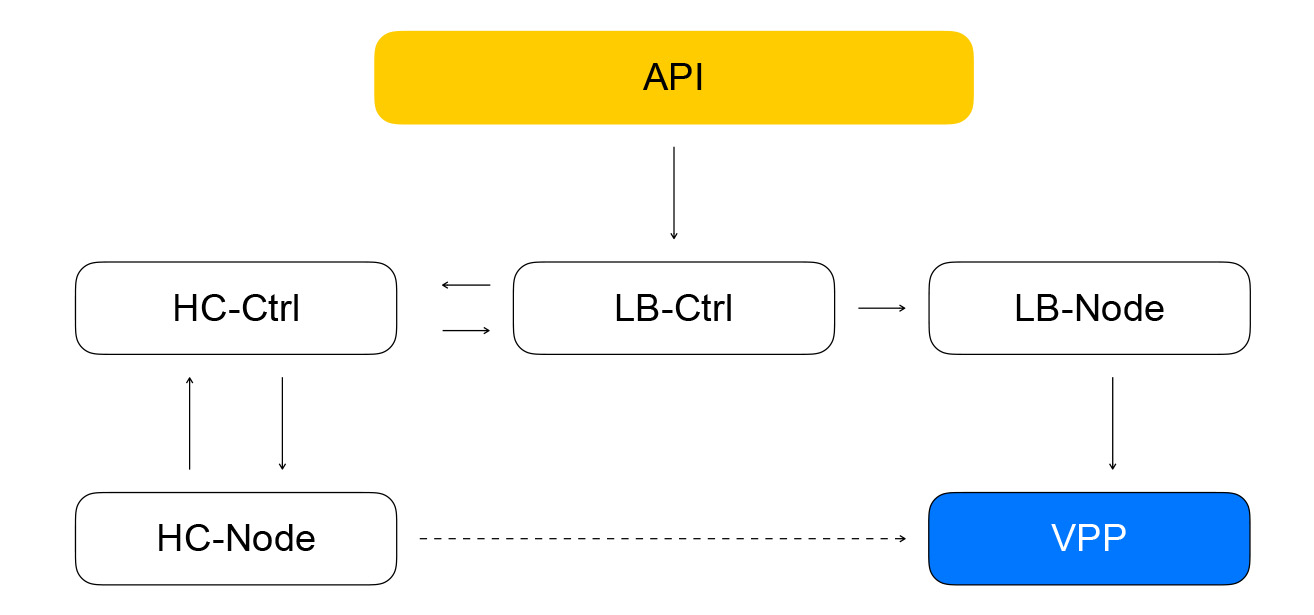
What questions have been avoided
All our services in control plane are written in Go and have good performance in terms of scaling and reliability. Go has many open source libraries for building distributed systems. We actively use GRPC, all components contain an open-source implementation of service discovery - our services monitor the performance of each other, can change their composition dynamically, and we tied it with GRPC balancing. For metrics, we also use an open source solution. In the data plane we got decent performance and a large supply of resources: it turned out to be very difficult to assemble a stand on which to rest against the performance of the VPP, and not the iron network card.
Problems and Solutions
What didn't work very well? In Go, memory management is automatic, but there are still memory leaks. The easiest way to deal with them is to run the gorutin and not forget to complete them. Conclusion: monitor the memory consumption of Go-programs. Often a good indicator is the amount of gorutin. There is a plus in this story: in Go it is easy to get data on the runtime - on memory consumption, on the number of running gorutins and on many other parameters.
In addition, Go is probably not the best choice for functional tests. They are rather verbose, and the standard “run everything in CI pack” approach is not very suitable for them. The fact is that functional tests are more demanding of resources, with them there are real timeouts. Because of this, tests may fail unsuccessfully, since the CPU is busy with unit tests. Conclusion: if possible, perform "heavy" tests separately from unit tests.
Microservice event architecture is more complicated than a monolith: logging on dozens of different machines is not very convenient. Conclusion: if you are doing microservices, immediately think about tracing.
Our plans
We will launch an internal balancer, an IPv6 balancer, add support for Kubernetes scripts, continue to shuffle our services (now only healthcheck-node and healthcheck-ctrl are shaded), add new healthchecks, and also implement smart aggregation of checks. We are considering the possibility of making our services even more independent - so that they communicate not directly with each other, but with the help of a message queue. SQS-compatible Yandex Message Queue service has recently appeared in the Cloud.
Recently, a public release of Yandex Load Balancer took place. Study the service documentation , manage balancers in the way that is convenient for you, and increase the fault tolerance of your projects!
Source: https://habr.com/ru/post/448588/
All Articles