Building a Failover Solution Based on Oracle RAC and AccelStor Shared-Nothing Architecture
A considerable number of Enterprise applications and virtualization systems have their own mechanisms for building fault-tolerant solutions. In particular, Oracle RAC (Oracle Real Application Cluster) is a cluster of two or more Oracle database servers that work together to load balance and provide fault tolerance at the server / application level. To work in this mode, you need a shared storage, which is usually in the role of storage.
As we have already considered in one of our articles , the data storage system itself, despite the presence of duplicate components (including controllers), still has points of failure - mainly as a single data set. Therefore, to build an Oracle solution with increased reliability requirements, the “N servers - one storage system” scheme needs to be complicated.

First, of course, you need to decide on what risks we are trying to insure. In this article, we will not consider protection against threats like “meteorite has flown in”. So the construction of a geographically dispersed disaster recovery solution will remain a topic for one of the following articles. Here we look at the so-called Cross-Rack disaster recovery solution, when protection is built at the level of server cabinets. The cabinets themselves can be located in the same room or in different rooms, but usually within the same building.
These cabinets should contain all the necessary set of equipment and software that will ensure the operation of Oracle databases, regardless of the state of the “neighbor”. In other words, using the Cross-Rack disaster recovery solution, we eliminate the risks of failure:
- Oracle Application Servers
- Storage systems
- Switching systems
- Complete failure of all equipment in the cabinet:
- Failure to eat
- Cooling system failure
- External factors (man, nature, etc.)
The duplication of Oracle servers implies the very principle of operation of Oracle RAC and is implemented through an application. Duplication of switching facilities is also not a problem. But with the duplication of storage, everything is not so simple.
The simplest option is to replicate data from the main storage system to the backup one. Synchronous or asynchronous, depending on the storage capabilities. With asynchronous replication, the question immediately arises of ensuring the consistency of data with respect to Oracle. But even if there is software integration with the application, in any case, in case of a crash on the main storage system, manual intervention of administrators will be required in order to switch the cluster to the backup storage.
A more complex option is software and / or hardware “virtualizers” of storage systems that will eliminate consistency problems and manual intervention. But the complexity of the deployment and subsequent administration, as well as the very indecent cost of such solutions, discourages many.
Just for scenarios like Cross-Rack disaster recovery, the All Flash AccelStor NeoSapphire ™ H710 array solution using Shared-Nothing is a great solution. This model is a two-bin storage system that uses its own FlexiRemap® technology for working with flash drives. Thanks to FlexiRemap® NeoSapphire ™, the H710 is capable of delivering performance up to 600K IOPS @ 4K random write and 1M + IOPS @ 4K random read, which is unattainable when using classic RAID-based storage.
But the main feature of the NeoSapphire ™ H710 is the execution of two nodes in the form of separate cases, each of which has its own copy of the data. Synchronization of nodes is carried out through the InfiniBand external interface. Thanks to this architecture, it is possible to spread nodes on different locations up to 100m away, thus providing the Cross-Rack disaster recovery solution. Both nodes work completely in synchronous mode. From the side of the H710 hosts looks like an ordinary dual-controller storage system. Therefore, no additional software and hardware options and especially complex settings are required.
If we compare all the above-described Cross-Rack disaster recovery solutions, then the AccelStor variant stands out noticeably from the rest:
| AccelStor NeoSapphire ™ Shared Nothing Architecture | Software or hardware "virtualizer" storage | Replication Based Solution | |
|---|---|---|---|
| Availability | |||
| Server failure | No downtime | No downtime | No downtime |
| Switch failure | No downtime | No downtime | No downtime |
| Storage failure | No downtime | No downtime | Downtime |
| Failure of the entire cabinet | No downtime | No downtime | Downtime |
| Cost and complexity | |||
| Cost of solution | Low * | High | High |
| Deployment complexity | Low | High | High |
* AccelStor NeoSapphire ™ is still the All Flash array, which, by definition, does not cost “3 kopecks,” especially since it has a double reserve of capacity. However, comparing the final cost of the solution based on it with those of other vendors, the cost can be considered low.
The topology of the connection of the application servers and nodes of the All Flash array will be as follows:
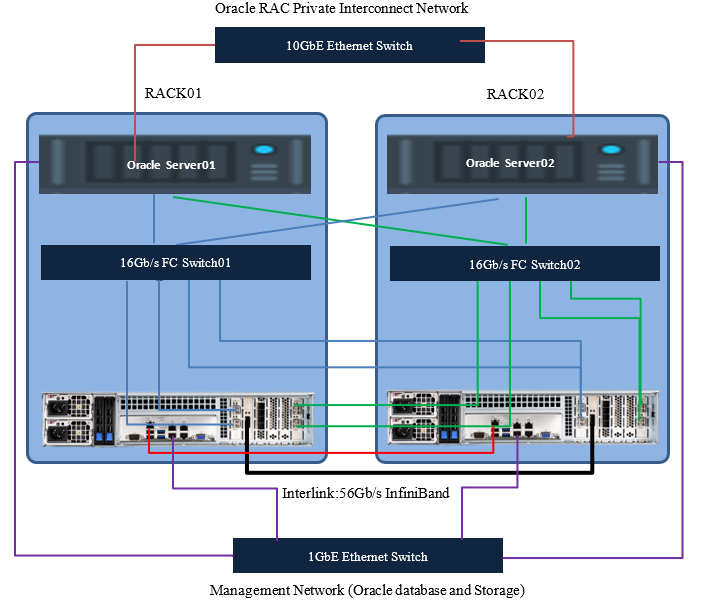
When planning the topology, it is also highly recommended to make duplication of management switches and interconnect servers.
Hereinafter we will talk about connecting through Fiber Channel. If iSCSI is used, everything will be the same, adjusted for the types of switches used and slightly different array settings.
Preparatory work on the array
Server and Switch Specifications
| Components | Description |
|---|---|
| Oracle Database 11g servers | Two |
| Server operating system | Oracle Linux |
| Oracle database version | 11g (RAC) |
| Processors per server | Two 16 cores Intel® Xeon® CPU E5-2667 v2 @ 3.30GHz |
| Physical memory per server | 128GB |
| FC network | 16Gb / s FC with multipathing |
| FC HBA | Emulex Lpe-16002B |
| Dedicated public 1GbE ports for cluster management | Intel ethernet adapter RJ45 |
| 16Gb / s FC switch | Brocade 6505 |
| Dedicated private 10GbE ports for data synchonization | Intel X520 |
AccelStor NeoSapphhire ™ All Flash Array Specification
| Components | Description |
|---|---|
| Storage system | NeoSapphire ™ high availability model: H710 |
| Image version | 4.0.1 |
| Total number of drives | 48 |
| Drive size | 1.92TB |
| Drive type | SSD |
| FC target ports | 16x 16Gb ports (8 per node) |
| Management ports | The 1GbE ethernet cable |
| Heartbeat port | The 1GbE ethernet cable connecting between two storage node |
| Data synchronization port | 56Gb / s InfiniBand cable |
Before you start using an array, you must initialize it. By default, the control address of both nodes is the same (192.168.1.1). You need to connect to them one by one and set up new (already different) management addresses and set up time synchronization, after which Management ports can be connected to a single network. After that, nodes are combined in HA pair by assigning subnets for Interlink connections.

After the initialization is complete, you can manage the array from any node.
Next, create the necessary volumes and publish them for application servers.

It is highly recommended to create multiple volumes for Oracle ASM, as this will increase the number of target servers, which ultimately improves overall performance (for more information, see the queues in another article ).
| Storage Volume Name | Volume Size |
|---|---|
| Data01 | 200GB |
| Data02 | 200GB |
| Data03 | 200GB |
| Data04 | 200GB |
| Data05 | 200GB |
| Data06 | 200GB |
| Data07 | 200GB |
| Data08 | 200GB |
| Data09 | 200GB |
| Data10 | 200GB |
| Gridd01 | 1GB |
| Grid02 | 1GB |
| Grid03 | 1GB |
| Grid4d04 | 1GB |
| Gridrid05 | 1GB |
| Grid06 | 1GB |
| Redo01 | 100GB |
| Redo02 | 100GB |
| Redo03 | 100GB |
| Redo04 | 100GB |
| Redo05 | 100GB |
| Redo06 | 100GB |
| Redo07 | 100GB |
| Redo08 | 100GB |
| Redo09 | 100GB |
| Redo10 | 100GB |
Some explanations about the modes of the array and the ongoing processes in emergency situations

The data set of each node has a “version number” parameter. After the initial initialization, it is the same and equal to 1. If for some reason the version number is different, then data is always synchronized from the older version to the younger version, after which the younger version is aligned, i.e. This means that the copies are identical. The reasons for which versions may be different:
- Scheduled restart of one of the nodes
- An accident at one of the nodes due to a sudden shutdown (power, overheating, etc.).
- Open InfiniBand connection with inability to synchronize
- An accident on one of the nodes due to data corruption. Here you will need to create a new HA group and complete synchronization of the data set.
In any case, the node that remains online increases its version number by one in order to synchronize its data set after restoring communication with the pair.
If there is a broken connection via an Ethernet link, the Heartbeat temporarily switches to InfiniBand and returns back within 10s when it is restored.
Host configuration
To ensure fault tolerance and increase performance, you must enable MPIO support for the array. To do this, add lines to the /etc/multipath.conf file, then restart the multipath service
device {
vendor "AStor"
path_grouping_policy "group_by_prio"
path_selector "queue-length 0"
path_checker "tur"
features "0"
hardware_handler "0"
prio "const"
failback immediate
fast_io_fail_tmo 5
dev_loss_tmo 60
user_friendly_names yes
detect_prio yes
rr_min_io_rq 1
no_path_retry 0
}
}
Next, in order for ASM to work with MPIO via ASMLib, you must change the file / etc / sysconfig / oracleasm and then run /etc/init.d/oracleasm scandisks
# ORACLEASM_SCANORDER: Matching patterns to order disk scanning
ORACLEASM_SCANORDER = "dm"
# ORACLEASM_SCANEXCLUDE: Matching patterns to exclude disks from scan
ORACLEASM_SCANEXCLUDE = "sd"
Note
If you do not want to use ASMLib, you can use UDEV rules, which are the basis for ASMLib.
Starting with version 12.1.0.2 of Oracle Database, the option is available for installation as part of ASMFD software.
Be sure to ensure that the disks created for Oracle ASM are aligned with the block size that the array (4K) physically works with. Otherwise, there may be performance problems. Therefore, it is necessary to create volumes with the appropriate parameters:
parted / dev / mapper / device-name mklabel gpt mkpart primary 2048s 100% align-check optimal 1
Distributing databases to created volumes for our test configuration
| Storage Volume Name | Volume Size | Volume LUNs mapping | ASM Volume Device Detail | Allocation Unit Size |
|---|---|---|---|---|
| Data01 | 200GB | Map All Data Ports | Redundancy: Normal Name: DGDATA Purpose: Data files | 4MB |
| Data02 | 200GB | |||
| Data03 | 200GB | |||
| Data04 | 200GB | |||
| Data05 | 200GB | |||
| Data06 | 200GB | |||
| Data07 | 200GB | |||
| Data08 | 200GB | |||
| Data09 | 200GB | |||
| Data10 | 200GB | |||
| Gridd01 | 1GB | Redundancy: Normal Name: DGGRID1 Purpose: Grid: CRS and Voting | 4MB | |
| Grid02 | 1GB | |||
| Grid03 | 1GB | |||
| Grid4d04 | 1GB | Redundancy: Normal Name: DGGRID2 Purpose: Grid: CRS and Voting | 4MB | |
| Gridrid05 | 1GB | |||
| Grid06 | 1GB | |||
| Redo01 | 100GB | Redundancy: Normal Name: DGREDO1 Purpose: Redo log of thread 1 | 4MB | |
| Redo02 | 100GB | |||
| Redo03 | 100GB | |||
| Redo04 | 100GB | |||
| Redo05 | 100GB | |||
| Redo06 | 100GB | Redundancy: Normal Name: DGREDO2 Purpose: Redo log of thread 2 ') | 4MB | |
| Redo07 | 100GB | |||
| Redo08 | 100GB | |||
| Redo09 | 100GB | |||
| Redo10 | 100GB |
- Block size = 8K
- Swap space = 16GB
- Disable AMM (Automatic Memory Management)
- Disable Transparent Huge Pages
# vi /etc/sysctl.conf
✓ fs.aio-max-nr = 1048576
✓ fs.file-max = 6815744
✓ kernel.shmmax 103079215104
✓ kernel.shmall 31457280
✓ kernel.shmmn 4096
✓ kernel.sem = 250 32000 100 128
✓ net.ipv4.ip_local_port_range = 9000 65500
✓ net.core.rmem_default = 262144
✓ net.core.rmem_max = 4194304
✓ net.core.wmem_default = 262144
✓ net.core.wmem_max = 1048586
✓ vm.swappiness = 10
✓ vm.min_free_kbytes = 524288 # don't set this if you are using Linux x86
✓ vm.vfs_cache_pressure = 200
✓ vm.nr_hugepages = 57000
# vi /etc/security/limits.conf
✓ grid soft nproc 2047
✓ grid hard nproc 16384
✓ grid soft nofile 1024
✓ grid hard nofile 65536
✓ grid soft stack 10240
✓ grid hard stack 32768
✓ oracle soft nproc 2047
✓ oracle hard nproc 16384
✓ oracle soft nofile 1024
✓ oracle hard nofile 65536
✓ oracle soft stack 10240
✓ oracle hard stack 32768
✓ soft memlock 120795954
✓ hard memlock 120795954
sqlplus “/ as sysdba”
alter system set processes = 2000 scope = spfile;
alter system set open_cursors = 2000 scope = spfile;
alter system set session_cached_cursors = 300 scope = spfile;
alter system set db_files = 8192 scope = spfile;
Failover test
For demonstration purposes, HammerDB was used to emulate the OLTP load. HammerDB configuration:
| Number of Warehouses | 256 |
| Total Transactions per User | 1000000000000 |
| Virtual Users | 256 |
As a result, the indicator 2.1M TPM was obtained, which is far from the H710 array performance limit, but is the “ceiling” for the current hardware configuration of servers (primarily due to processors) and their number. The goal of this test is to demonstrate the resiliency of the solution as a whole, and not to achieve maximum performance. Therefore, we will simply build on this figure.

Test for failure of one of the nodes
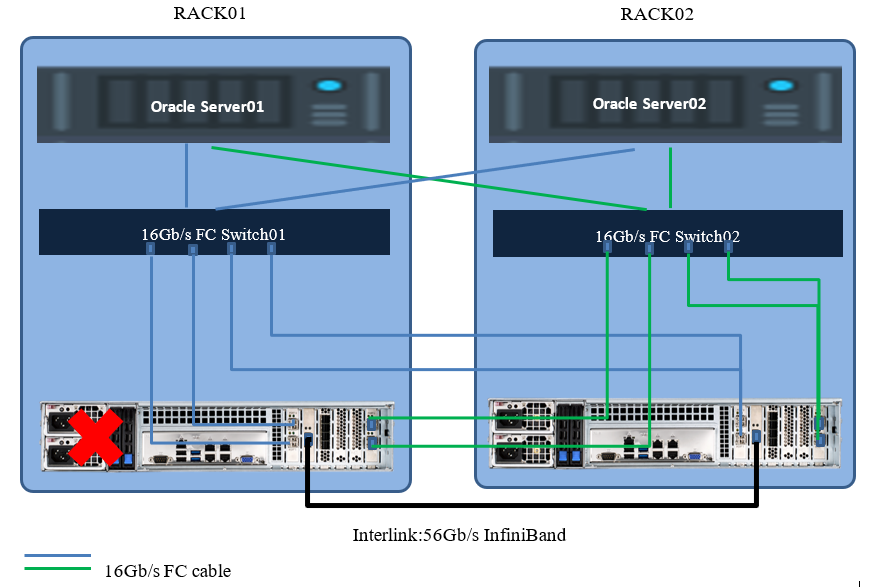

Hosts have lost some of the paths to the repository, continuing to work through the rest of the second node. Productivity slipped for a few seconds due to the restructuring of the paths, and then returned to normal. There was no interruption in service.
Test for cabinet failure with all equipment

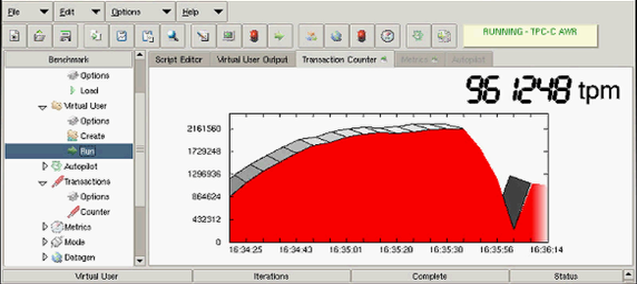
In this case, the performance also slipped for a few seconds due to the restructuring of the paths, and then returned to half the value of the original indicator. The result was halved from the initial due to the exclusion of one application server. There was no interruption in service either.
If there are needs for implementing a Cross-Rack disaster recovery solution for Oracle at a reasonable cost and with little deployment / administration efforts, then working together with Oracle RAC and AccelStor Shared-Nothing architecture will be one of the best options. Instead of Oracle RAC there can be any other software providing clustering, the same DBMS or virtualization systems, for example. The principle of building a solution will remain the same. And the total is a zero value for the RTO and RPO.
Source: https://habr.com/ru/post/448538/
All Articles