SNA Hackathon 2019 - results

On April 1, the final of the SNA Hackathon 2019 ended, the participants of which competed in sorting social network tapes using modern machine learning technologies, computer vision, test processing and recommendation systems. Hard online selection and two days of hard work on 160 gigabytes of data were not in vain :). We talk about what helped the participants to come to success and about other interesting observations.
About data and task
The competition presented data on the mechanisms for preparing the ribbon for users of the social network OK , consisting of three parts:
- logs of content shows in users' tapes with a large number of signs describing the user, content, author and other properties;
- texts related to the shown content;
- body pictures used in the content.
The total amount of data exceeds 160 gigabytes, of which more than 3 are for logs, another 3 for texts and the rest for pictures. A large amount of data did not frighten the participants: according to the ML Bootcamp statistics, almost 200 people took part in the contest, sending more than 3000 submits, and the most active managed to break the 100 decision level. Perhaps, they were motivated by the prize pool of 700,000 rubles + 3 GTX 2080 Ti video cards.

The participants of the competition needed to solve the problem of sorting the tape: for each individual user, sort the displayed objects in such a way that those who received the “Class!” Mark were closer to the head of the list.
ROC-AUC was used as a quality assessment metric. In this case, the metric was not considered for all data as a whole, but separately for each user and then averaged. This version of the calculation is noteworthy because the algorithms that have learned to distinguish users who put many classes do not receive an advantage. On the other hand, there is no such variant of work in standard Python packages, which revealed some interesting points, which are discussed below.
About technology
Traditionally, SNA Hackathon is not only algorithms, but also technologies - the amount of data shipped exceeds 160 gigabytes, which puts participants in front of interesting technical problems.
Parquet vs. CSV
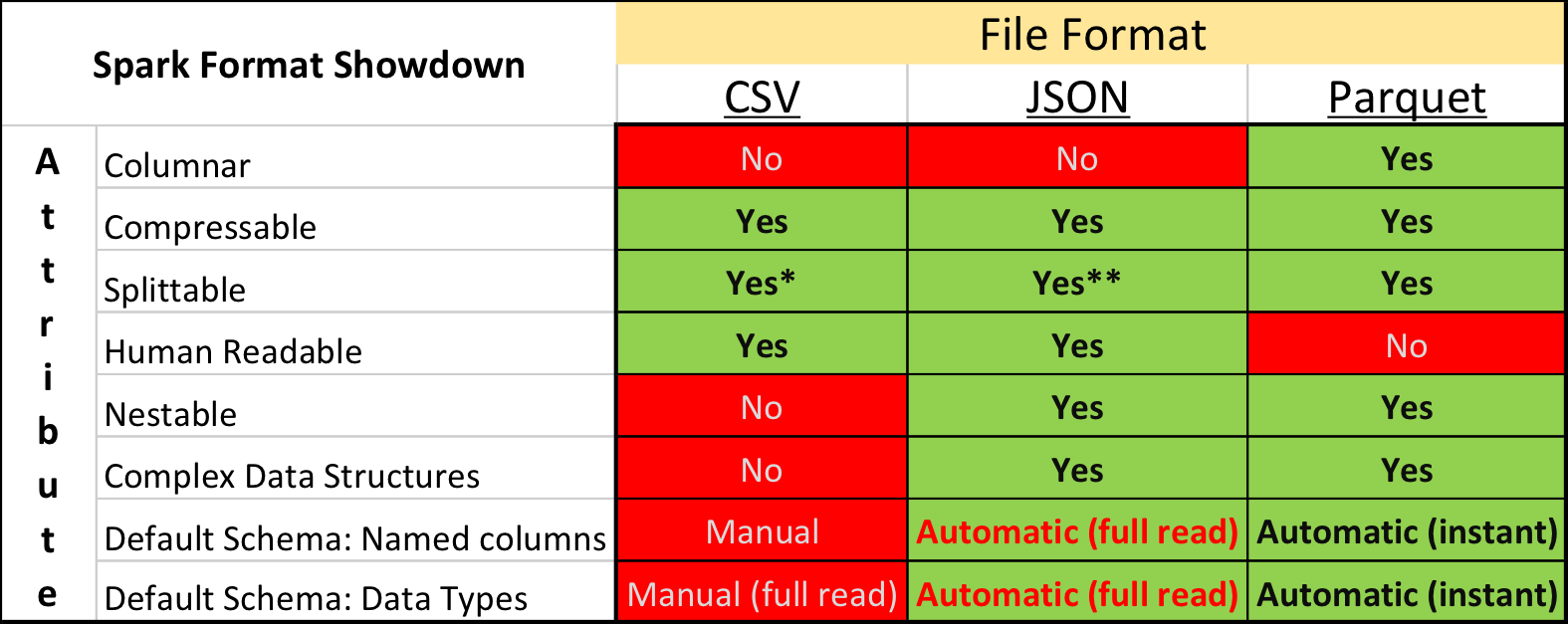
In academic studies and on Kaggle, the dominant data format is CSV , as well as other “plain text” formats. However, in the industry the situation is somewhat different - much greater compactness and processing speed can be achieved using "binary" storage formats.
In particular, in an ecosystem built on the basis of Apache Spark , Apache Parquet is the most popular - column data storage format with support for many features important for exploitation:
- explicitly specified schema with evolution support;
- reading only the necessary speakers from the disk;
- basic support for indexes and filters for reading;
- column compression.
But despite the presence of obvious advantages, the provision of data for the competition in the Apache Parquet format was strongly criticized by some participants. In addition to conservatism and unwillingness to spend time on mastering something new, there were some really unpleasant moments.
First, the format support in the Apache Arrow library, the main tool for working with Parquet from Python, is far from perfect. When preparing data, all structural fields had to be flattened, and still, when reading texts, many participants faced a bug and had to install the old version of the library 0.11.1 instead of the current 0.12 version. Secondly, you will not look into the Parquet file using simple console utilities: cat, less, etc. However, this disadvantage is relatively easy to compensate using the parquet-tools package.
Nevertheless, those who initially tried to convert all the data into CSV, in order to work in a familiar environment, eventually abandoned this idea - after all, Parquet works significantly faster.
Busting and GPU

At the SmartData conference in St. Petersburg, “widely known in narrow circles,” Alexey Natekin compared the performance of several popular boosting tools when working on a CPU / GPU and came to the conclusion that the tangible gain of the GPU does not give. But even then, this conclusion led to an active controversy, primarily with the developers of the domestic CatBoost tool.
Over the past two years, progress in the development of the GPU and adaptation of the algorithms did not stand still and the SNA Hackathon final can be considered a triumph for the CatBoost + GPU pair - all the winners used it and pulled the metric primarily due to the possibility to grow more trees per unit of time.
The integrated implementation of the mean target encoding implementation contributed to the high result of solutions based on CatBoost, but the number and depth of the trees gave a more significant increase.
Other boosting tools are moving in a similar direction, adding and improving support for the GPU. So grow more trees!
Spark vs. Pyspark

The Apache Spark tool firmly occupies a leading position in industrial Data Science, including due to the presence of the API for Python. However, the use of Python has the additional overhead of integrating between different execution environments and the interpreter’s work.
In itself, this is not a problem, if the user is aware of the extent to which the additional costs result from this or that action. However, it turned out that many people are not aware of the scale of the problem - despite the fact that participants did not use Apache Spark, discussions on Python vs. Scala appeared in the hackathon chat regularly, which led to the appearance of the corresponding post with analysis .
In short, the slowdown in using Spark through Python compared to using Spark through Scala / Java can be divided into the following levels:
- only Spark SQL API without User Defined Functions (UDF) is used - in this case there are practically no overhead costs, since the entire execution plan of the query is calculated within the JVM;
- UDF in Python is used without calling packages with C ++ code - in this case, the performance of the stage at which the UDF is calculated drops 7-10 times ;
- UDF is used in Python with reference to the C ++ package (numpy, sklearn, etc.) - in this case, the performance drops 10-50 times .
Partly, the negative effect can be compensated using PyPy (JIT for Python) and vectorized UDF , however, in these cases, the performance difference is a multiple, and the complexity of implementation and deployment comes as an additional “bonus”.
About algorithms
But the most interesting thing about Data Science-hakatons is, of course, not technologies, but new fashionable and old proven algorithms. This year's SNA Hackathon totally dominated CatBoost, but there were several alternative approaches. Let's talk about them :).
Differentiable graphs

One of the first publications of decisions on the basis of the selection round was devoted not to trees, but to differentiable graphs (also called artificial neural networks). The author is an employee of the OC, so he can afford not to chase after the prizes, but to enjoy building a promising solution based on a solid mathematical foundation.
The main idea of the proposed solution was to build a single computational differentiable graph that translates the existing features into a forecast, taking into account various aspects of the input data:
- embedings of objects and users allow you to add an element of classic collaborative recommendations;
- the transition from the scalar product of embeddings to aggregation via MLP allows you to add arbitrary features;
- query-key-value attention allowed the model to dynamically adapt to the behavior of even an unfamiliar user looking at his recent history.
This model performed very well on the online selection in solving the problem of recommending text content, so several teams tried to reproduce it at the final at once, however, they did not come to success. This was partly due to the fact that this requires time and experience, and partly due to the fact that the number of signs in the final was much larger and methods based on trees gained a significant advantage due to them.
Collaborative dominant

Of course, when organizing the competition, we knew that the logs have a fairly strong signal, because the signs collected there reflect a significant part of the ranking work done in the OK. Nevertheless, they hoped to the very end that the participants would cope with the “curse of the third character” - situations where the enormous human and machine resources invested in the development of the model for extracting features from content (texts and photos) result in extremely modest quality gains compared to prepared, mainly collaborative, signs.
Knowing about this problem, we initially divided the task into three tracks in the qualifying round and formed a combined data set only in the final, but in the fixed metric hackathon format, the teams that invested in the development of content models turned out to be in a losing situation compared to the teams that developed the collaborative part.
To compensate for this injustice helped the prize of the jury ...
Deep cluster

Which was almost unanimously awarded for his work on reproducing and testing the Deep Cluster algorithm from facebook. A simple method of building clusters and embeddings that does not require initial markup was captivating with new ideas and promising results.
The essence of the method is very simple:
- calculate embeding vectors for images of any meaningful neural network;
- clustering vectors in the resulting space with k-means;
- train a neural network classifier to predict a cluster of a picture;
- repeat paragraphs 2-3 to convergence (if you have 800 hcp) or while there is enough time.
With a minimum of effort, we managed to get high-quality clustering of OK pictures, good embeddings and metric growth in the third digit.
A look into the future

In any data you can find "loopholes" to improve the forecast. In itself, this is not so bad, much worse if the “loopholes” are found themselves and for a long time manifest themselves only in the form of incomprehensible discrepancies between the results of validation on historical data and A / B tests.
One of the most common "loopholes" of this kind is the use of information from the future. Such information is often a very strong signal and the machine learning algorithm, if allowed to it, will start using it with confidence. When you make a model for your product, you are trying in every way to avoid infiltrating information from the future, but on the hackathon this is a good chance to raise the metric, which the participants took advantage of.
The most obvious loophole was the presence of data fields with reaction counters on the object at the time of the show - numLikes and numDislikes. By comparing the two nearest events related to the same object, it was possible to determine with high precision what the reaction was to the object in the first of them. There were several such counters in the data, and their use gave a noticeable advantage. Naturally, in real operation such information will not be available.
In life, you can stumble upon a similar problem without realizing it, as a rule, with negative results. For example, counting statistics on the number of marks "Class!" for the object for all data and taking as a separate sign. Or, as was done in one of the participating teams, adding an object identifier to the model as a categorical attribute. On a training set, a model with such a sign works well, but cannot generalize to a test set.
Instead of conclusion

All contest materials, including data and presentations of the participants' decisions are available in the Mail.ru Cloud . Data is available for use by research projects without restrictions, except for the presence of a link. For the story, let's leave here the final table with the metrics of the finalist teams:
- Scala crouching, Python undercover - 0.7422, solution analysis is available here , and the code here and here .
- Magic City - 0.7256
- Kefir - 0.7226
- Team 6 - 0.7205
- Three in the boat - 0.7188
- Hall # 14 - 0.7167 and the jury prize
- BezSNA - 0.7147
- PONGA - 0.7117
- Team 5 - 0.7112
SNA Hackathon 2019, like the previous events of the series, was a success in every sense. We managed to gather under one roof cool specialists in different areas and have a fruitful time, for which many thanks to both the participants themselves and all those who helped with the organization.
Could you do something even better? Of course yes! Each competition held enriches us with new experience, which we take into account when preparing the next one and are not going to stop there. So, see you soon at SNA Hackathon events!
')
Source: https://habr.com/ru/post/448140/
All Articles