JavaScript engine basics: prototype optimization. Part 1
Hello. Less and less time remains until the launch of the course “Security of Information Systems” , therefore today we continue to share publications dedicated to the launch of this course. By the way, the current publication is a continuation of these two articles: “Basics of JavaScript engines: common forms and inline caching. Part 1 , Basics of JavaScript engines: common forms and inline caching. Part 2 " .
The article describes the key fundamentals. They are common to all JavaScript engines, not just the V8 authors are working on ( Benedict and Matias ). As a JavaScript developer, I can say that a deeper understanding of how the JavaScript engine works will help you figure out how to write effective code.

')
In a previous article, we discussed how JavaScript engines optimize access to objects and arrays using forms and inline caches. In this article, we will look at how to optimize compromise of the pipeline and speed up access to the properties of the prototype.
Optimization levels and tradeoffs when performing
Last time, we found out that all modern JavaScript engines, in fact, have the same pipeline:
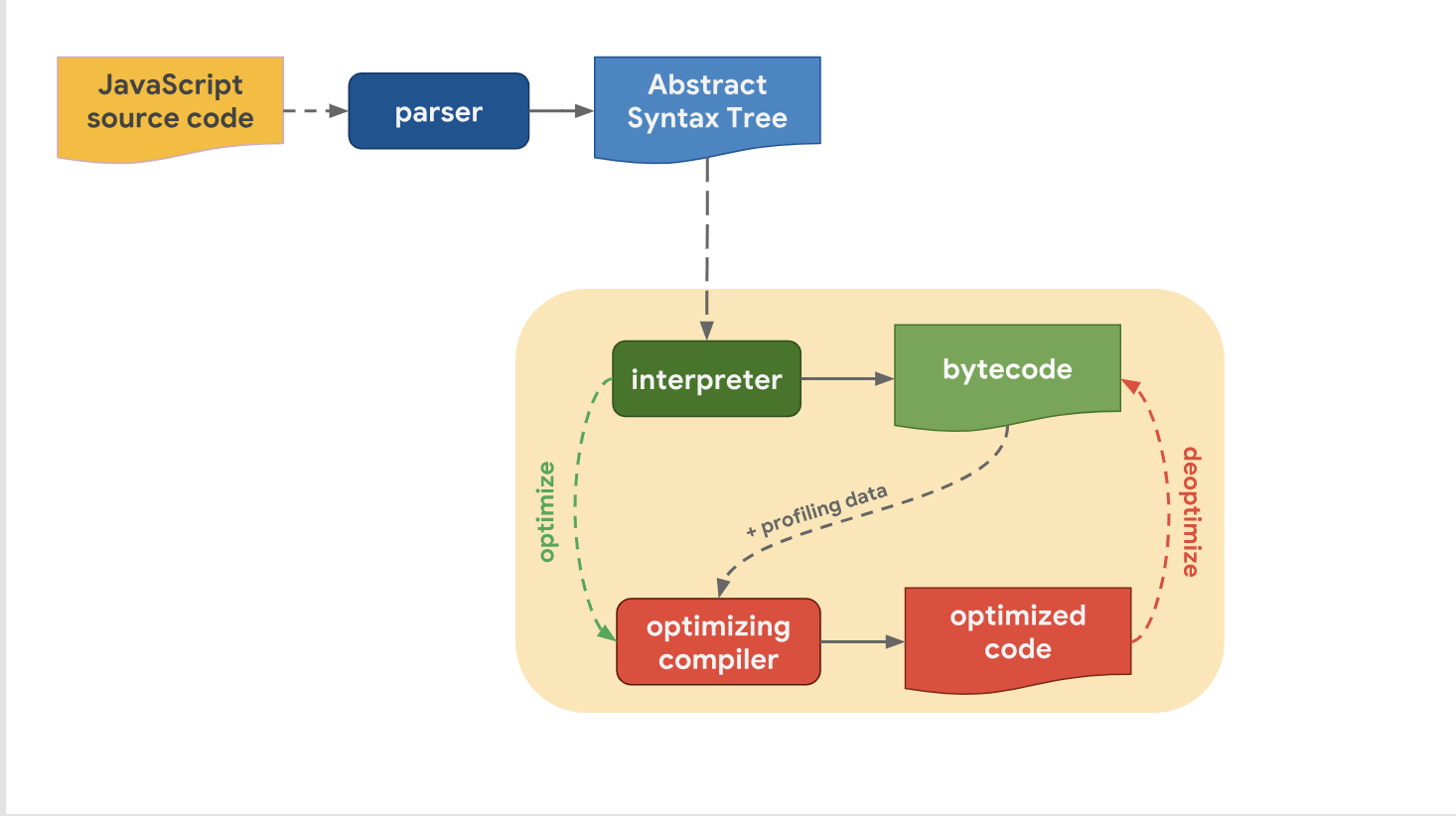
We also realized that despite the fact that the high-level pipelines from engine to engine are similar in structure, there is a difference in the optimization pipeline. Why is this so? Why do some engines have more optimization levels than others? It’s all a matter of making a compromise decision between moving quickly to the stage of code execution or spending a small amount of time on executing code with optimal performance.

The interpreter can quickly generate bytecode, but bytecode itself is not efficient enough in terms of speed. Involving an optimizing compiler in this process spends a certain amount of time, but allows you to get more efficient machine code.
Let's take a look at how the V8 does it. Recall that in V8 the interpreter is called Ignition and it is considered the fastest interpreter among existing engines (in terms of the speed of performing raw bytecode). The optimizing compiler in V8 is called the Turbofan (TurboFan) and it generates highly optimized machine code.

The tradeoff between launch delay and execution speed is the reason why some JavaScript engines prefer to add additional levels of optimization between stages. For example, SpiderMonkey adds a baseline tier between its interpreter and the full IonMonkey optimizing compiler:
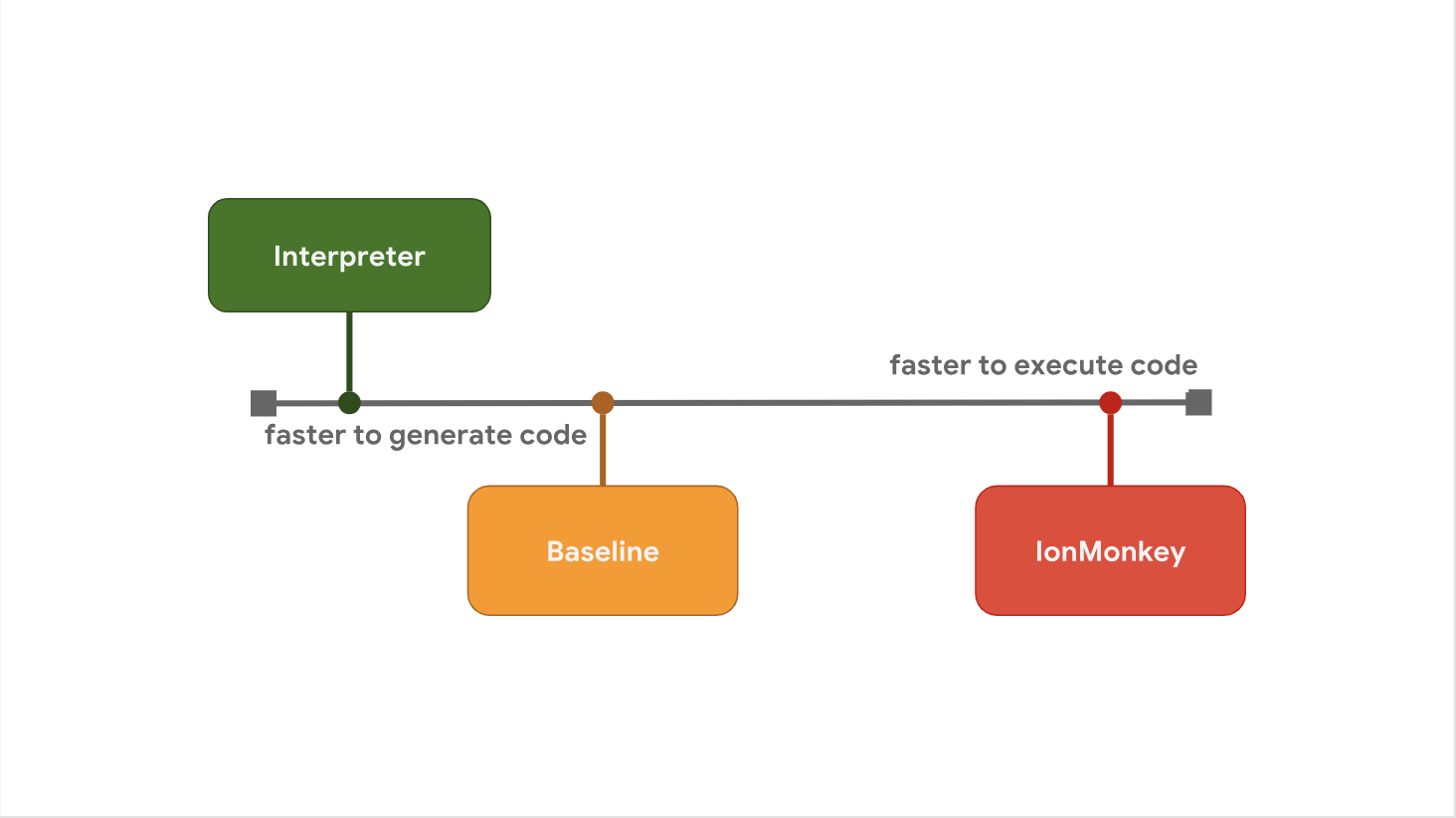
The interpreter quickly generates bytecode, but bytecode itself is relatively slow. Baseline generates code a little longer, but provides performance improvements at runtime. Finally, the IonMonkey optimizing compiler spends the most time on generating machine code, but this code is extremely efficient.
Let's look at a specific example and see how the various pipelines deal with this issue. Here in the hot loop often the same code repeats.
V8 starts by launching the bytecode in the Ignition interpreter. At some point, the engine determines that the code is hot and launches the TurboFan interface, which integrates the profiling data and builds the basic machine code representation. It is then sent to the TurboFan optimizer in another thread for further improvement.

While optimization is going on, V8 continues to execute code in Ignition. At some point, when the optimizer finished and we got the executable machine code, it immediately goes into the execution phase.
SpyderMonkey also starts executing bytecode in the interpreter. But it has an additional Baseline level, which means that the hot code is first sent there. The Baseline compiler generates the Baseline code in the main thread and continues execution at the end of its generation.

If the Baseline code is executed for some time, SpiderMonkey eventually launches the IonMonkey interface (IonMonkey frontend) and starts the optimizer, the process is very similar to V8. All this continues to work simultaneously in Baseline, while IonMonkey is engaged in optimization. Finally, when the optimizer finishes its work, the optimized code is executed instead of the Baseline code.
The Chakra architecture is very similar to SpiderMonkey, but Chakra tries to run more processes at the same time to avoid blocking the main thread. Instead of running any part of the compiler in the main thread, Chakra copies the bytecode and profiling data that the compiler will need and sends it to the dedicated compiler process.

When the generated code is ready, the engine executes this SimpleJIT code instead of bytecode. The same thing happens with FullJIT. The advantage of this approach is that the pause that occurs when copying is usually much shorter compared to running a full-fledged compiler (frontend). On the other hand, this approach has a flaw. It lies in the fact that copy heuristic may miss some information that will be needed for optimization, so we can say that to some extent the quality of the code is sacrificed to speed up the work.
In JavaScriptCore, all optimizing compilers work completely in parallel with the main implementation of JavaScript. There is no copying phase. Instead, the main stream simply starts the compilation in another thread. Compilers then use a sophisticated blocking scheme to access profiling data from the main thread.

The advantage of this approach is that it reduces the amount of garbage that has appeared after optimization in the main stream. The disadvantage of this approach is that it requires solving complex problems of multithreading and some blocking costs for various operations.
We talked about the trade-offs between the rapid generation of code when the interpreter works and the generation of fast-running code using an optimizing compiler. But there is another compromise, and it concerns the use of memory. To show it visually, I wrote a simple JavaScript program that adds two numbers.
Look at the bytecode that is generated for the add function by the Ignition interpreter in V8.
Don't worry about bytecode, you don't need to be able to read it. Here you need to pay attention to the fact that there are only 4 instructions .
When the code gets hot, TurboFan generates highly optimized machine code, which is presented below:
There are really a lot of teams, especially in comparison with the four that we saw in baytkode. In general, bytecode is much more capacious than machine code, and especially optimized machine code. On the other hand, the bytecode is executed by the interpreter, while the optimized code can be executed directly by the processor.
This is one of the reasons why JavaScript engines are not just “optimize everything”. As we have seen before, the generation of optimized machine code takes a lot of time and, therefore, it requires more memory.

To summarize: The reason why JavaScript engines have different levels of optimization is to find a compromise solution between fast code generation using an interpreter and fast code generation using an optimizing compiler. Adding more levels of optimization allows you to make more informed decisions based on the cost of additional complexity and overhead during execution. In addition, there is a trade-off between optimization and memory usage. That is why JavaScript engines try to optimize only hot functions.
Optimize access to prototype properties
Last time, we talked about how JavaScript engines optimize the loading of object properties using forms and inline caches. Recall that the engines keep the shapes of objects separately from the values of the object.
Forms allow you to use optimization with inline caches or ICs for short. When working together, forms and ICs can speed up repeated access to properties from the same place in your code.
The first part of the publication has come to an end, and it will be possible to learn about classes and prototype programming in the second part, which we will publish in the coming days. Traditionally, we are waiting for your comments and vigorous reasoning, and we also invite you to the open door on the course “Security of Information Systems”.
The article describes the key fundamentals. They are common to all JavaScript engines, not just the V8 authors are working on ( Benedict and Matias ). As a JavaScript developer, I can say that a deeper understanding of how the JavaScript engine works will help you figure out how to write effective code.
')
In a previous article, we discussed how JavaScript engines optimize access to objects and arrays using forms and inline caches. In this article, we will look at how to optimize compromise of the pipeline and speed up access to the properties of the prototype.
Attention: if you like watching presentations more than reading articles, then watch this video . If not, then skip it and read on.
Optimization levels and tradeoffs when performing
Last time, we found out that all modern JavaScript engines, in fact, have the same pipeline:
We also realized that despite the fact that the high-level pipelines from engine to engine are similar in structure, there is a difference in the optimization pipeline. Why is this so? Why do some engines have more optimization levels than others? It’s all a matter of making a compromise decision between moving quickly to the stage of code execution or spending a small amount of time on executing code with optimal performance.
The interpreter can quickly generate bytecode, but bytecode itself is not efficient enough in terms of speed. Involving an optimizing compiler in this process spends a certain amount of time, but allows you to get more efficient machine code.
Let's take a look at how the V8 does it. Recall that in V8 the interpreter is called Ignition and it is considered the fastest interpreter among existing engines (in terms of the speed of performing raw bytecode). The optimizing compiler in V8 is called the Turbofan (TurboFan) and it generates highly optimized machine code.
The tradeoff between launch delay and execution speed is the reason why some JavaScript engines prefer to add additional levels of optimization between stages. For example, SpiderMonkey adds a baseline tier between its interpreter and the full IonMonkey optimizing compiler:
The interpreter quickly generates bytecode, but bytecode itself is relatively slow. Baseline generates code a little longer, but provides performance improvements at runtime. Finally, the IonMonkey optimizing compiler spends the most time on generating machine code, but this code is extremely efficient.
Let's look at a specific example and see how the various pipelines deal with this issue. Here in the hot loop often the same code repeats.
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result); V8 starts by launching the bytecode in the Ignition interpreter. At some point, the engine determines that the code is hot and launches the TurboFan interface, which integrates the profiling data and builds the basic machine code representation. It is then sent to the TurboFan optimizer in another thread for further improvement.
While optimization is going on, V8 continues to execute code in Ignition. At some point, when the optimizer finished and we got the executable machine code, it immediately goes into the execution phase.
SpyderMonkey also starts executing bytecode in the interpreter. But it has an additional Baseline level, which means that the hot code is first sent there. The Baseline compiler generates the Baseline code in the main thread and continues execution at the end of its generation.
If the Baseline code is executed for some time, SpiderMonkey eventually launches the IonMonkey interface (IonMonkey frontend) and starts the optimizer, the process is very similar to V8. All this continues to work simultaneously in Baseline, while IonMonkey is engaged in optimization. Finally, when the optimizer finishes its work, the optimized code is executed instead of the Baseline code.
The Chakra architecture is very similar to SpiderMonkey, but Chakra tries to run more processes at the same time to avoid blocking the main thread. Instead of running any part of the compiler in the main thread, Chakra copies the bytecode and profiling data that the compiler will need and sends it to the dedicated compiler process.
When the generated code is ready, the engine executes this SimpleJIT code instead of bytecode. The same thing happens with FullJIT. The advantage of this approach is that the pause that occurs when copying is usually much shorter compared to running a full-fledged compiler (frontend). On the other hand, this approach has a flaw. It lies in the fact that copy heuristic may miss some information that will be needed for optimization, so we can say that to some extent the quality of the code is sacrificed to speed up the work.
In JavaScriptCore, all optimizing compilers work completely in parallel with the main implementation of JavaScript. There is no copying phase. Instead, the main stream simply starts the compilation in another thread. Compilers then use a sophisticated blocking scheme to access profiling data from the main thread.
The advantage of this approach is that it reduces the amount of garbage that has appeared after optimization in the main stream. The disadvantage of this approach is that it requires solving complex problems of multithreading and some blocking costs for various operations.
We talked about the trade-offs between the rapid generation of code when the interpreter works and the generation of fast-running code using an optimizing compiler. But there is another compromise, and it concerns the use of memory. To show it visually, I wrote a simple JavaScript program that adds two numbers.
function add(x, y) { return x + y; } add(1, 2); Look at the bytecode that is generated for the add function by the Ignition interpreter in V8.
StackCheck Ldar a1 Add a0, [0] Return Don't worry about bytecode, you don't need to be able to read it. Here you need to pay attention to the fact that there are only 4 instructions .
When the code gets hot, TurboFan generates highly optimized machine code, which is presented below:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18 There are really a lot of teams, especially in comparison with the four that we saw in baytkode. In general, bytecode is much more capacious than machine code, and especially optimized machine code. On the other hand, the bytecode is executed by the interpreter, while the optimized code can be executed directly by the processor.
This is one of the reasons why JavaScript engines are not just “optimize everything”. As we have seen before, the generation of optimized machine code takes a lot of time and, therefore, it requires more memory.
To summarize: The reason why JavaScript engines have different levels of optimization is to find a compromise solution between fast code generation using an interpreter and fast code generation using an optimizing compiler. Adding more levels of optimization allows you to make more informed decisions based on the cost of additional complexity and overhead during execution. In addition, there is a trade-off between optimization and memory usage. That is why JavaScript engines try to optimize only hot functions.
Optimize access to prototype properties
Last time, we talked about how JavaScript engines optimize the loading of object properties using forms and inline caches. Recall that the engines keep the shapes of objects separately from the values of the object.
Forms allow you to use optimization with inline caches or ICs for short. When working together, forms and ICs can speed up repeated access to properties from the same place in your code.
The first part of the publication has come to an end, and it will be possible to learn about classes and prototype programming in the second part, which we will publish in the coming days. Traditionally, we are waiting for your comments and vigorous reasoning, and we also invite you to the open door on the course “Security of Information Systems”.
Source: https://habr.com/ru/post/447870/
All Articles