Compiled Distributed System Configuration
I would like to tell one interesting mechanism for working with the configuration of a distributed system. The configuration is represented directly in the compiled language (Scala) using safe types. In this post, an example of such a configuration is examined and various aspects of implementing a compiled configuration into the overall development process are considered.
( english )
Introduction
Building a reliable distributed system implies that all nodes use the correct configuration, synchronized with other nodes. DevOps technology is usually used (terraform, ansible or something like) for automatic generation of configuration files (often its own for each node). We would also like to be sure that on all interacting nodes identical protocols are used (including the same version). Otherwise, incompatibility will be incorporated in our distributed system. In the JVM world, one consequence of this requirement is the need to use the same version of the library containing the protocol messages everywhere.
What about testing a distributed system? Of course, we assume that unit-tests are provided for all components, before we proceed to integration testing. (So that we can extrapolate test results at runtime, we also need to provide an identical set of libraries at the testing stage and in runtime.)
When working with integration tests, it is often easier to use the same classpath everywhere on all nodes. We will only have to ensure that the same classpath is involved in runtime. (Despite the fact that it is quite possible to run different nodes with different classpaths, this leads to complication of the entire configuration and difficulties with deployment and integration tests.) In the framework of this post, we assume that the same classpath will be used on all nodes.
The configuration evolves with the application. We use versions to identify different stages of program evolution. Apparently, it is also logical to identify different versions of configurations. And the configuration itself is placed in the version control system. If there is a single configuration in production, then we can use just the version number. If multiple production instances are used, then we will need several
configuration branches and an additional label in addition to the version (for example, the name of the branch). In this way, we can uniquely identify the exact configuration. Each configuration identifier uniquely corresponds to a certain combination of distributed nodes, ports, external resources, and library versions. In this post, we will assume that there is only one branch, and we can identify the configuration in the usual way using three numbers separated by a dot (1.2.3).
In modern environments, manual configuration files are rarely created. More often, they are generated during deployment and no longer touch them (so as not to break anything ). A legitimate question arises, why do we still use a text format to store the configuration? A completely viable alternative is the ability to use ordinary code for configuration and get benefits from checks during compilation.
In this post, we are exploring the idea of representing the configuration inside a compiled artifact.
Compiled configuration
This section describes an example of a static compiled configuration. Two simple services are implemented - echo service and client echo service. Based on these two services, two system variants are assembled. In one embodiment, both services are located on the same node, in another version - on different nodes.
Typically, a distributed system contains several nodes. You can identify nodes using values of some NodeId type:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId or
case class NodeId(hostName: String) or even
object Singleton type NodeId = Singleton.type Nodes play different roles, services are running on them, and TCP / HTTP communications can be established between them.
To describe TCP communication, we need at least a port number. We would also like to reflect the protocol that is supported on this port to ensure that both the client and the server use the same protocol. We will describe the connection using this class:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol]) where Port is just an integer Int with the range of valid values:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]] See the refined library and my report . In short, the library allows you to add constraints to types that are checked at compile time. In this case, the valid values for the port number are 16-bit integers. For the compiled configuration, the use of the refined library is not mandatory, but it does allow the compiler to improve its configuration checking capabilities.
For HTTP (REST) protocols, in addition to the port number, we may also need the path to the service:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix) To identify the protocol at the compilation stage, we use a type parameter that is not used inside the class. Such a solution is due to the fact that we do not use a protocol instance in runtime, but we would like the compiler to check protocol compatibility. Due to the indication of the protocol, we will not be able to transfer inappropriate service as a dependency.
One common protocol is the REST API with Json serialization:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage] where RequestMessage is the type of request, ResponseMessage is the type of the response.
Of course, you can use other protocol descriptions that provide the accuracy we require.
For the purposes of this post, we will use a simplified version of the protocol:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage] Here, the request is a string added to the url, and the response is the returned string in the body of the HTTP response.
The service configuration is described by the service name, ports, and dependencies. These elements can be represented in Scala in several ways (for example, HList , or algebraic data types). For the purposes of this post, we will use Cake Pattern and represent the modules using trait 's. (Cake Pattern is not a required element of the described approach. It is just one of the possible implementations.)
The dependencies between services can be represented as methods that return EndPoint ports of other nodes:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) } To create an echo service, all that is needed is a port number and an indication that this port supports an echo protocol. We could not specify a specific port, because trait'y allow you to declare methods without implementation (abstract methods). In this case, when creating a specific configuration, the compiler would require us to provide an implementation of the abstract method and provide the port number. Since we have implemented the method, we may not specify a different port when creating a specific configuration. The default value will be used.
In the client configuration, we declare a dependency on the echo service:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] } The dependency is of the same type as the echoService exported service. In particular, in the echo client, we require the same protocol. Therefore, when connecting two services, we can be sure that everything will work correctly.
A function is required to start and stop the service. (The ability to stop the service is critical for testing.) Again, there are several options for implementing such a function (for example, we could use type classes based on the configuration type). For the purposes of this post, we will use the Cake Pattern. We will represent the service using the cats.Resource class, since this class already provides safe means of guaranteed release of resources in case of problems. To get the resource we need to provide the configuration and ready runtime context. The service launch function can be as follows:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] } Where
Config- the configuration type for this service.AddressResolveris a runtime object that allows you to find the addresses of other nodes (see below)
and other types from the cats library:
F[_]is the effect type (in the simplest case,F[A]may be just a function() => AIn this post we will usecats.IO)Reader[A,B]- more or less synonymous withA => Bcats.Resource- a resource that can becats.Resourceand releasedTimer- timer (allows you to fall asleep for a while and measure time intervals)ContextShift- analogue ofExecutionContextApplicativeis an effect type class that allows you to combine individual effects (almost a monad). In more complex applications, it seems better to useMonad/ConcurrentEffect.
Using this function signature, we can implement several services. For example, a service that does nothing:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) } (See the source code , which implements other services - echo service , echo client
and time-of-life controllers .)
A node is an object that can start several services (the launch of the resource chain is provided by the Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig } Note that we specify the exact type of configuration that is required for this node. If we forget to specify one of the types of configuration required by a separate service, there will be a compilation error. Also, we will not be able to start a node unless we provide an object of the appropriate type with all the necessary data.
To connect to a remote host, we need a real IP address. It is possible that the address will be known later than the rest of the configuration. Therefore, we need a function that displays the node ID to the address:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] } You can offer several ways to implement this function:
- If the addresses become known to us before deployment, then we can generate the Scala code with
addresses and then run the build. This will compile and run the tests.
In this case, the function will be known statically and can be represented in the code as aMap[NodeId, NodeAddress]. - In some cases, the actual address becomes known only after the node has started.
In this case, we can implement a "discovery service" (discovery) that runs up to the other nodes and all nodes will register with this service and request the addresses of other nodes. - If we can modify
/etc/hosts, we can use predefined host names (likemy-project-main-nodeandecho-backend) and simply link these names
with IP addresses during deployment.
As part of this post, we will not consider these cases in more detail. For our
of the toy example, all nodes will have the same IP address - 127.0.0.1 .
Next, we consider two variants of a distributed system:
- Placement of all services on one site.
- And the placement of the echo service and the echo client on different nodes.
Single node configuration:
object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton /** Type safe service port specification. */ override def portNumber: PortNumber = 8088 // configuration of client /** We'll use the service provided by the same host. */ def echoServiceDependency = echoService override def testMessage: UrlPathElement = "hello" def pollInterval: FiniteDuration = 1.second // lifecycle controller configuration def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9. } The object implements the configuration of both the client and the server. The lifetime configuration is also used to terminate the program after the lifetime interval. (Ctrl-C also works and correctly frees all resources.)
The same set of configuration traits and implementations can be used to create a system consisting of two separate nodes :
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig { // NB! dependency specification def echoServiceDependency = NodeServerConfig.echoService def pollInterval: FiniteDuration = 1.second def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9. def testMessage: String = "dolly" } Important! Notice how the services are bound. We specify a service implemented by one node as an implementation of the method of the dependency of another node. The type of dependency is checked by the compiler, since contains the type of protocol. At startup, the dependency will contain the correct target node identifier. With this scheme, we specify the port number exactly once and always guaranteed to refer to the correct port.
For this configuration, we use the same service implementation unchanged. The only difference is that now we have two objects that implement different sets of services:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig } The first node implements the server and needs only server configuration. The second node implements the client and uses a different part of the configuration. Both nodes also need lifetime control. The server node runs indefinitely until SIGTERM is stopped, and the client node ends some time later. See the launch application .
General development process
Let's see how this configuration approach affects the overall development process.
The configuration will be compiled along with the rest of the code and an artifact (.jar) will be generated. It seems to make sense to put the configuration into a separate artifact. This is due to the fact that we can have many configurations based on the same code. Again, you can generate artifacts that correspond to different configuration branches. Along with the configuration, dependencies on specific versions of libraries are saved and these versions are saved forever, whenever we decide to deploy this version of configuration.
Any configuration change turns into a code change. And therefore, every such
The change will be covered by the usual quality assurance process:
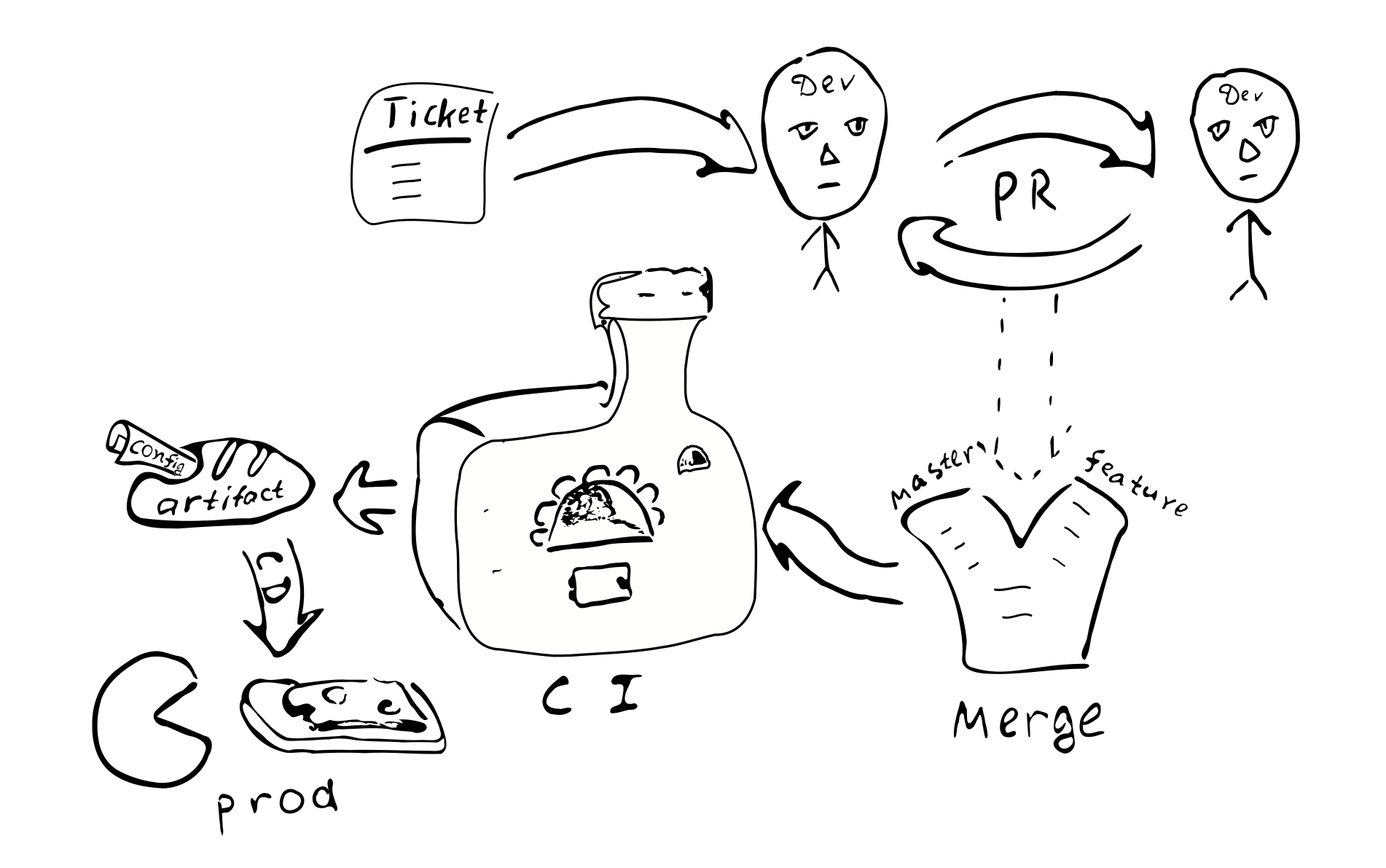
Ticket in the bugtracker -> PR -> review -> merging with the corresponding branches ->
integration -> deployment
The main consequences of implementing a compiled configuration:
The configuration will be coordinated on all nodes of the distributed system. By virtue of the fact that all nodes receive the same configuration from a single source.
It is problematic to change the configuration in only one of the nodes. Therefore, configuration drift is unlikely.
It becomes more difficult to make small changes to the configuration.
Most of the configuration changes will occur as part of the overall development process and will be reviewed.
Do I need a separate repository to store the production-configuration? This configuration may contain passwords and other secret information, access to which we would like to restrict. Based on this, it seems to make sense to store the final configuration in a separate repository. You can divide the configuration into two parts — one containing the publicly available configuration settings and the other containing the restricted access parameters. This will allow most developers to have access to common parameters. This separation is easy to achieve using intermediate traits containing default values.
Possible variations
Let's try to compare the compiled configuration with some common alternatives:
- Text file on the target machine.
- Centralized key-value storage (
etcd/zookeeper). - Process components that can be reconfigured / restarted without restarting the process.
- Storage configuration is out of artifact and version control.
Text files provide considerable flexibility in terms of small changes. The system administrator can go to the remote site, make changes to the appropriate files and restart the service. For large systems, however, this flexibility may be undesirable. From the changes made there are no traces in other systems. Nobody reviews the changes. It is difficult to establish exactly who made the changes and for what reason. Changes are not tested. If the system is distributed, the administrator may forget to make a corresponding change on other nodes.
(It should also be noted that the use of the compiled configuration does not close the possibility of using text files in the future. It is enough to add a parser and validator giving the same type of Config output, and you can use text files. From this it follows that the complexity of the system with the compiled configuration is somewhat less than the complexity of a system that uses text files, because additional code is required for text files.)
Centralized key-value storage is a good mechanism for distributing the meta-parameters of a distributed application. We need to decide what the configuration parameters are, and what is just data. Suppose we have a function C => A => B , and the parameters C rarely change, and the data A - often. In this case, we can say that C is the configuration parameters, and A is the data. It seems that the configuration parameters differ from the data in that they generally change less frequently than the data. Also, data usually comes from one source (from the user), and configuration parameters from another (from the system administrator).
If rarely changing parameters need to be updated without restarting the program, then this can often lead to a complication of the program, because we need to somehow deliver the parameters, store, parse and check, handle incorrect values. Therefore, from the point of view of reducing the complexity of the program, it makes sense to reduce the number of parameters that may change during the course of the program (or not to support such parameters at all).
From the point of view of this post, we will distinguish between static and dynamic parameters. If the logic of the service requires changing the parameters during the program, then we will call these parameters dynamic. Otherwise, the parameters are static and can be configured using a compiled configuration. For dynamic reconfiguration, we may need a mechanism for restarting parts of the program with new parameters in the same way as restarting operating system processes. (In our opinion, it is desirable to avoid real-time reconfiguration, as the complexity of the system increases. If possible, it is better to use the standard OS capabilities for restarting processes.)
One important aspect of using static configuration that makes people consider dynamic reconfiguration is the time it takes for the system to reboot after the configuration has been updated (downtime). In fact, if we need to make changes to the static configuration, we will have to restart the system for the new values to take effect. The downtime problem has a different urgency for different systems. In some cases, you can schedule a reboot at a time when the load is minimal. In case continuous service is required, it is possible to implement "drain connections" (AWS ELB connection draining) . At the same time, when we need to reboot the system, we start a parallel instance of this system, switch the balancer to it, and wait until the old connections are completed. After all the old connections have ended, we turn off the old instance of the system.
Consider now the issue of storing the configuration inside or outside the artifact. If we store the configuration inside the artifact, then, at a minimum, we had the opportunity to verify the correctness of the configuration during the assembly of the artifact. If the configuration is outside a controlled artifact, it is difficult to track who made the changes to this file and why. How important is it? In our opinion, for many production-systems it is important to have a stable and high-quality configuration.
The artifact version allows you to determine when it was created, which values it contains, which functions are enabled / disabled, who is responsible for any change in the configuration. Of course, storing the configuration inside the artifact requires some effort, so you need to make an informed decision.
Pros and cons
I would like to highlight the pros and cons of the proposed technology.
Benefits
Below is a list of the main features of the compiled configuration of a distributed system:
- Static configuration check. Lets you be sure that
configuration is correct. - . . Scala , . ,
trait' , , val', (DRY) . (Seq,Map, ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- Modularity. , . , , — . production- .
- Testing. mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList(case class') . - , : (
package,import, ;override def' , ). , DSL. , (, XML), . - .
Conclusion
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
Acknowledgments
, .
')
Source: https://habr.com/ru/post/447694/
All Articles