Your bike to sync MariaDB and Sphinx

On February 28, I gave a talk at the SphinxSearch-meetup , which took place in our office. I talked about how we came from regular rebuilding of indexes for full-text search and sending updates “in place” in the code to Railtime indexes and automatic synchronization of the state of the index and the MariaDB database. The link is available video of my report, and for those who prefer reading video viewing, I wrote this article.
To begin with, we had a search, and why we started all this.
Our search was organized in a completely standard way.
From the frontend come user requests to the application server, written in PHP, and he in turn communicates with the database (we have MariaDB). If we need to do a search, the application server refers to the balancer (we have haproxy), which connects it to one of the servers where searchd is running, and that one already performs the search and returns the result.
The data from the database to the index fall in a quite traditional way: according to the schedule, every few minutes we rebuild the index with those documents that were updated relatively recently, and once a day we rebuild the index with the so-called “archival” documents (i.e. for a long time nothing happened). There are a couple of machines selected for indexing, a script is launched there, which first builds the index, then renames the index files in a special way, and then adds it into a separate folder. And on each of the servers with searchd, rsync is run once a minute, which copies files from this folder to the searchd index folder, and then, if something has been copied, executes the RELOAD INDEX request.
However, for some changes in resumes and vacancies it was required that they “reach” the index as soon as possible. For example, if a vacancy that was posted in the public domain is removed from publication, then it is reasonable to expect from the user's point of view that it will disappear from the issue within a few seconds, not more. Therefore, such changes are sent using UPDATE requests directly to searchd. And so that these changes are applied to all copies of the indexes on all of our servers, a distributed index is added to each searchd, which sends attribute updates to all searchd instances. The application server still connects to the balancer and sends one request to update the distributed index; thus, he does not need to know in advance any list of servers with searchd, nor on any particular server with searchd he will get.
It all worked pretty well, but there were problems.
- The average delay between the creation of a document (we have a resume or a job) and its entry into the index was directly proportional to their number in our database.
- Since we used a distributed index to distribute attribute updates, we had no guarantee that these updates were applied to all copies of the index.
- The “urgent” changes that occurred during the index rebuilding were lost when the
RELOAD INDEXcommand was executed (simply because they were not yet in the newly built index), and were only indexed after the next reindexing.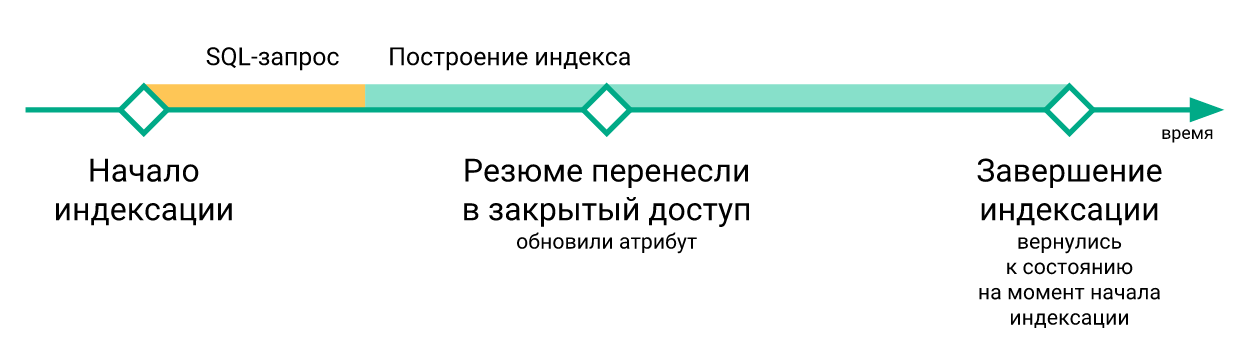
- Index update scripts on servers with searchd were run independently of each other, there was no synchronization between them. Because of this, the delay between updating the index on different servers could reach several minutes.
- If it was necessary to test something related to the search, it was necessary to rebuild the index after each change.
Each of these problems separately did not cost the cardinal processing of the search infrastructure, but together they rather perceptibly ruined life.
We decided to deal with the problems listed above with the help of real-time Sphinx indices. And we had only one transition to RT-indices. In order to finally get rid of any data-races, it was necessary to ensure that all updates from the application to the index went through the same channel. In addition, it was necessary to save somewhere the changes made to the database during the time the index was rebuilt (because, nevertheless, sometimes it has to be rebuilt, and the procedure is not instantaneous).
We decided to make this connection through the MySQL replication protocol, and binlog MySQL as the place where changes are saved for the time the index is rebuilt. This solution allowed us to get rid of writing to Sphinx from the application code. And since by that time we had already used row-based replication with a global transaction id, switching between database replicas could be made quite simple.
The idea of connecting directly to the database in order to receive changes from there to be sent to the index is, of course, not new: in 2016, colleagues from Avito gave a report where they described in detail how they solved the problem of synchronizing data in Sphinx with the main database. We decided to use their experience and make a similar system, with the difference that we do not have PostgreSQL, but MariaDB, and the old Sphinx branch (namely, version 2.3.2).
We made a service that subscribes to changes in MariaDB and updates the index in Sphinx. His duties are as follows:
- connection to the MariaDB server via the replication protocol and receiving events from the binlog;
- tracking the current binlog position and the number of the last completed transaction;
- binlog filtering;
- finding out which documents need to be added, deleted or updated in the index, and for updatable documents - which fields need to be updated;
- request missing data from MariaDB;
- creating and executing index update requests;
- rebuild the index if necessary.
We made the replication protocol connection using go-mysql library. She is responsible for establishing a connection with MariaDB, reading replication events and passing them to a handler. This handler is started in the mountain, which is controlled by the library, but we write the handler code ourselves. In the handler code, events are reconciled with a list of tables that interest us and are sent for processing changes to these tables. Our handler also stores the status of the transaction. This is due to the fact that in the replication protocol the events go in the following order: GTID (start of transaction) -> ROW (change of data) -> XID (completion of transaction), and information about the transaction number is only in the first of them. It is more convenient for us to transfer the transaction number along with its completion in order to save information about the position to which the changes were made in the binlog, and for this you need to remember the number of the current transaction between its beginning and completion.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+ We save the number of the last completed transaction to a special index from one document on each server with searchd. At the start of the service, we check that the indexes are initialized and have the expected structure, as well as that the saved position on all servers is present and the same on all servers. Then, if these checks were completed successfully and we managed to start reading the binlog from a saved position, we begin the synchronization procedure. If the checks did not pass, or it was not possible to start reading the binlog from the saved position, then reset the saved position to the current position of the MariaDB server and rebuild the index.
Replication event handling begins by determining which documents are affected by a change in the database. To do this, in the configuration of our service, we did something like routing for row change events in the tables of interest, that is, a set of rules to determine how changes in the database should be indexed.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"] For example, for such a set of rules, changes in the vacancy , vacancy_language and vacancy_metro_station should fall in the vacancy index. The document number can be taken in the id field for the vacancy table, and in the vacancy_id field for the other two tables. The column_map field is a table of the dependence of the index fields on the fields of different database tables.
Further, when we received a list of documents affected by changes, we need to update them in the index, but we are not doing this right away. First, we accumulate changes for each document, and send the changes to the index as soon as a short time passes (we have 100 milliseconds) since the last change to this document.
We decided to do this to avoid a lot of unnecessary updates to the index, because in many cases one logical change of a document occurs with the help of several SQL queries that affect different tables, and sometimes they are executed in different transactions.
I will give a simple example. Suppose a user edited a job. The code responsible for saving changes is often written for simplicity in the following way:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT; In other words, all old records are deleted from the linked tables first, and then new ones are inserted. At the same time there will still be entries in the binlog about these deletions and inserts, even if nothing has changed in fact in the document.
To update only what we need, we did the following: sort the modified lines so that for each pair of the index document you can get all the changes in chronological order. Then we can then apply them in turn to determine which fields in which tables eventually changed and which did not, and then use the column_map table column_map get a list of fields and index attributes that need to be updated for each affected document. Moreover, events related to one document may not come one after the other, but, as it were, “out of joint”, if they are executed in different transactions. But, our ability to determine what has changed in which documents will not affect it.
At the same time, this approach allowed us to update only the attributes of the index, if there were no changes in the text fields, and also to merge the submission of changes to Sphinx.
So now we can figure out which documents need to be updated in the index.
In many cases, the data from the binlog is not enough to build a request to update the index, so we get the missing data from the same server from which we are reading the binlog. To do this, in the configuration of our service there is a request template for receiving data.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """ In this template, all fields are marked with special aliases: [___]:___ .
It is used both when forming a request for obtaining missing data, and when building an index (more on that later).
We form a request of this type:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id Then for each document we check if it is as a result of this query. If not, it means that it was deleted from the main table, and therefore it can also be deleted from the index (execute a DELETE query for this document). If it is, then we are looking at whether it is necessary to update the text fields for this document. If the text fields do not need to be updated, then we make an UPDATE request for this document, otherwise - REPLACE .
It is worth noting here that the logic of maintaining the position from which one can begin reading binlog in case of failures had to be complicated, because now it is possible that we do not apply all changes read from binlog.
In order for the resumption of binlog reading to work correctly, we did the following: for each event of changing rows in the database, we remember the id of the last completed transaction at the time this event occurred. After sending changes to Sphinx, we update the transaction number from which it is safe to start reading, as follows. If we have not processed all the accumulated changes (because some documents are not “lying down” in the queue), then we take the number of the earliest transaction among those that relate to changes that we have not yet had time to apply. And if it so happened that we applied all the accumulated changes, then we simply take the number of the last completed transaction.
What we got as a result suited us, but there was still one rather important point: in order for the realtime index performance to remain at an acceptable level over time, it was necessary that the size and number of chunks of this index remained small. To do this, Sphinx has a FLUSH RAMCHUNK request, which makes a new disk chunk, and an OPTIMIZE INDEX request, which merges all disk chunks into one. Initially, we thought that we would just periodically carry it out and that’s it. But, unfortunately, it turned out that in version 2.3.2 OPTIMIZE INDEX does not work (namely, with a rather high probability leads to a drop of searchd). Therefore, we decided to just completely rebuild the index once a day, especially since from time to time you still have to do it (for example, if the index scheme or the tokenizer settings are changed).
The procedure for rebuilding the index takes place in several stages.
We generate config for indexer
As mentioned above, there is a SQL query template in the service config. It is also used to form the indexer config.
Also in the config there are other settings needed to build the index (tokenizer settings, dictionaries, various restrictions on resource consumption).Save current position MariaDB
From this position, we will start reading binlog after the new index is available on all servers with searchd.
Run indexer
indexer --config tmp.vacancy.indexer.0.conf --allcommands likeindexer --config tmp.vacancy.indexer.0.conf --alland wait for them to complete. Moreover, if the index is divided into parts, then run the construction of all parts in parallel.Load index files by servers
Uploading to each server also happens in parallel, but we naturally wait until all files are uploaded to all servers. To download files in the service configuration there is a section with a command template for downloading files.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]For each server, we simply substitute its name in the Host variable and execute the resulting command. We use rsync for downloading, but in principle any program or script that accepts a list of files in stdin and uploads these files to the folder where searchd expects to see the index files will do.
Stop sync
We stop reading binlog, stop the gorutin responsible for the accumulation of changes.
Replace the old index with a new one.
For each server with searchd, make successive queries
RELOAD INDEX vacancy_plain,TRUNCATE INDEX vacancy_plain,ATTACH INDEX vacancy_plain TO vacancy. If the index is divided into parts, then we perform these requests for each part sequentially. At the same time, if we are in a production environment, before performing these queries on any server, we remove the load from the balancer (so that no one makes SELECT queries to the indexes betweenTRUNCATEandATTACH), and as soon as the lastATTACHrequest is executed, we return the load to this server.Resume sync from saved position
As soon as we replace all realtime indices with newly built ones, we resume reading from the binlog and synchronization of events from the binlog, starting from the position we saved before starting the indexing.
Here is an example of the index lag graph from the MariaDB server.

Here you can see that although the state of the index after rebuilding and comes back in time, this happens quite a bit.
Now that everything is more or less ready, it's time to release. We did it gradually. First, we poured a realtime index on a couple of servers, and the rest at that time worked as before. At the same time, the structure of the indexes on the “new” servers did not differ from the old ones, so our PHP application could still connect to the balancer, without worrying about whether the request would be processed on a realtime index or on a plain index.
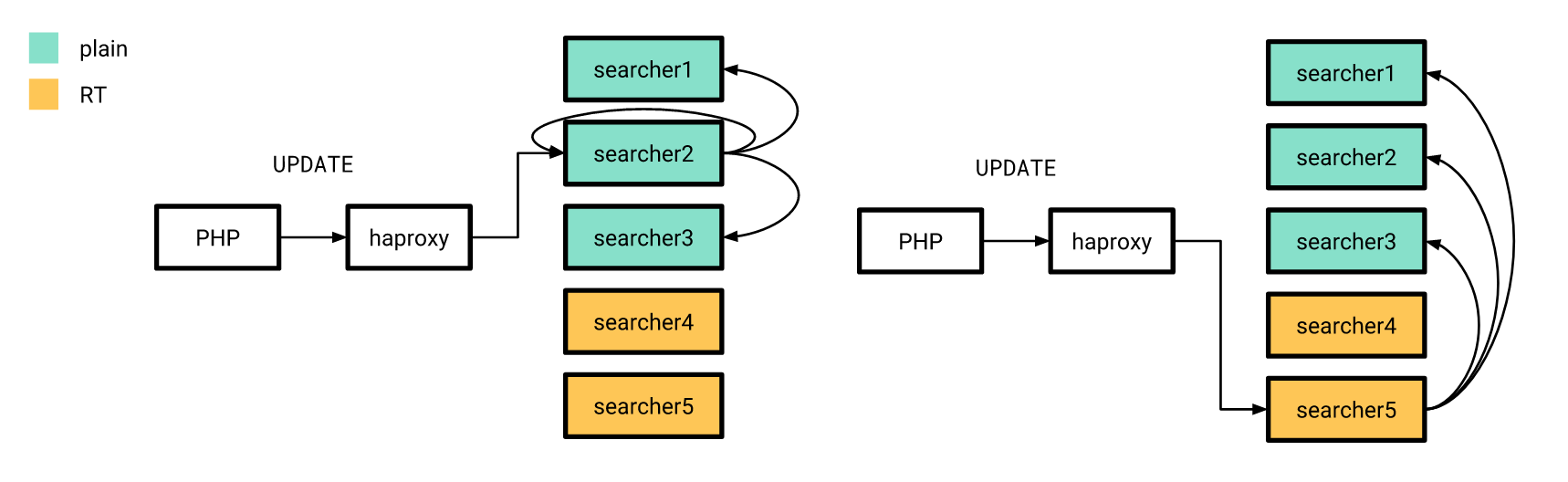
Attribute updates, which I mentioned earlier, were also sent out using the old scheme, with the difference that the distributed index on all servers was configured to send UPDATE requests only to servers with plain indexes. Moreover, if an UPDATE request from an application is sent to a server with realtime indexes, then it does not execute the request itself, but sends it to servers configured in the old way.
After the release, as we had hoped, it turned out to significantly reduce the delay between how a resume or vacancy changes in the database and how relevant changes fall into the index.
After switching to the realtime index, there is no need to rebuild the index after each change on the test servers. And therefore it became possible to write end-to-end auto-tests with relatively low cost with the participation of search. However, since we process the changes from binlog asynchronously (from the point of view of the clients who write to the database), we had to make it possible to wait until the changes concerning the document participating in the autotest will be processed by our service and sent to searchd .
To do this, we made an endpoint in our service, which is exactly what it does, that is, it waits until all changes are applied to the specified transaction number. To do this, immediately after we have made the necessary changes in the database, we request MariaDB @@gtid_current_pos and transfer it to the endpoint of our service. If we have already applied all transactions to this position by this time, the service immediately responds that it can be continued. If not, then in the gorutine, which is responsible for applying the changes, we create a subscription to this GTID, and as soon as he (or any one following him) is applied, we also allow the client to continue with the autotest.
In PHP code, it looks something like this:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } } results
As a result, we were able to significantly reduce the delay between updating MariaDB and Sphinx.


We also became much more confident that all updates reach all our Sphinx servers on time.
In addition, search testing (both manual and automatic) has become much more enjoyable.
Unfortunately, this was not free for us: the realtime index performance was slightly worse compared to the plain index.
The following shows the distribution of the processing time of search queries depending on the time for a plain index.

But the same schedule for the realtime index.

It can be seen that the share of “fast” requests has slightly decreased, while the share of “slow” requests has increased.
Instead of conclusion
It remains to say that the code of the service described in this article, we have laid out in the public domain . Unfortunately, there is no detailed documentation yet, but if you wish, you can run an example of using this service through docker-compose .
Links
')
Source: https://habr.com/ru/post/447526/
All Articles