Breaking a simple "quack" with Ghidra - Part 2
In the first part of the article, with the help of Ghidra, we performed an automatic analysis of a simple quack program (which we downloaded from crackmes.one). We figured out how to rename "incomprehensible" functions directly in the listing of the decompiler, and also understood the algorithm of the "top level" program, i.e. which is performed by the main () function.
In this part, we, as I promised, will undertake the analysis of the _construct_key () function, which, as we found out, is responsible for reading the binary file transferred to the program and checking the read data.
Let's immediately look at the full listing of this feature:
With this function we will do the same as before with main () - to begin with, let's go through the “veiled” function calls. As expected, all these functions are from standard C libraries. I will not re-describe the procedure for renaming functions — go back to the first part of the article, if necessary. As a result of the renaming, the following standard functions were found:
')
We renamed the corresponding wrapper functions in our code (the ones that the decompiler brazenly hid behind the word _text ) by adding index 2 (so that there is no confusion with the original C functions). Almost all of these functions are used to work with file streams. It is not surprising - just a quick glance at the code to understand that there is a sequential reading of data from a file (the handle of which is passed to the function as a single parameter) and a comparison of the read data with a certain two-dimensional byte array local_14 .
Let's assume that this array contains key verification data. Let's call it, say, key_array . Since Hydra allows you to rename not only functions, but also variables, use this and rename the incomprehensible local_14 to a more understandable key_array . This is done in the same way as for functions: through the right-click menu ( Rename local ) or the L key from the keyboard.
So, immediately after declaring local variables, a certain _prepare_key () function is called :
We will return to _prepare_key () , this is already the 3rd level of nesting in our call hierarchy: main () -> _construct_key () -> _prepare_key () . In the meantime, let's assume that it creates and somehow initializes this “check” two-dimensional array. And only if this array is not empty, the function continues its work, as evidenced by the else block immediately after the above condition.
Then the program reads the first 4 bytes from the file and compares it with the corresponding section of the key_array array. (The code below is already after the renames made, including the variable local_19 I renamed to first_4bytes .)
Thus, further execution occurs only in case of coincidence of the first 4 bytes (remember this). Then we read 2 2-byte blocks from the file (and the same key_array is used as a buffer for writing data):
And again - then the function only works if the next condition is true:
It is easy to see that the first of the 2-byte blocks read above should be the number 5, and the second the number 4 (the data type short just takes 2 bytes on 32-bit platforms).
Next is this:
Here we see that in the local_30 array (declared as char * local_30 [4]), the offsets of the key_array pointer are entered . That is, local_30 is an array of marker strings into which data from a file will most likely be read. By this assumption, I renamed local_30 to markers . In this part of the code, only the last line seems a bit suspicious, where the assignment of the last offset (at index 0x430, ie 1072) is performed not to the next markers element, but to a separate variable local_20 ( char * ). But with this we will understand, but for now - let's move on!
Next we have a cycle:
Those. Only 5 iterations from 0 to 4 inclusive. The loop immediately begins reading from the file and checking for compliance with our array of markers :
That is, the next byte from the file is read into the variable c_marker (in the original decompiled code is local_35 ) and checked for compliance with the first character of the i-th markers element. If there is a mismatch, the key_array array is reset and an empty double pointer is returned. Further along the code, we see that this happens every time the read data does not match the verification data.
But here, as they say, "the dog is buried." Let's take a closer look at this cycle. It has 5 iterations, as we found out. You can check this if you want by looking at the assembler code:


Indeed, the CMP command compares the value of the variable local_10 (we already have i ) with the number 4 and if the value is less than or equal to 4 (the JLE command), a transition is made to the label LAB_004017eb , i.e. the beginning of the body of the cycle. Those. the condition will be met for i = 0, 1, 2, 3, and 4 — a total of 5 iterations! Everything would be fine, but markers are also indexed by this variable in a loop, and this array is only declared with 4 elements:
So someone is obviously trying to fool someone :) Do you remember, I said that this line makes you doubt?
And how! Just look at the entire function listing and try to find another at least one reference to the local_20 variable. She is not! From here we conclude: this offset should also be stored in the markers array, and the array itself should contain 5 elements. Let's fix it. Go to the declaration of the variable, wait for Ctrl + L (Retype variable) and boldly change the size of the array to 5:
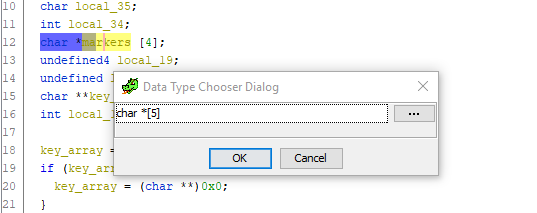
Is done. Scroll below to the code for assigning pointer offsets to the markers , and - lo and behold! - the incomprehensible extra variable disappears and everything falls into place:
We return to our while loop (in the source code it will most likely be for , but we don’t care). Then again the byte from the file is read and its value is checked:
OK, this n_strlen1 should be non-zero. Why? Now you will see, and at the same time you will understand why I assigned the following name to this variable:
I added comments on which everything should be clear. The file reads n_strlen1 bytes and is stored as a sequence of characters (ie, a string) into the array markers [i] —that is, after the corresponding “stop character”, which is already written from key_array . Preserving the value of n_strlen1 in markers [i] at offset 0x104 (260) does not play any role here (see the first line in the code above). In fact, this code can be optimized as follows (and surely this is how it is in the source code):
It also checks that the length of the line read is n_strlen1 . This may seem redundant, given that this parameter was passed to the fread function, but fread reads no more than so many specified bytes and can read less than indicated, for example, in the case of a file end token (EOF). That is, everything is strict: the file specifies the length of the line (in bytes), then the line itself goes - and so exactly 5 times. But we are running ahead.
Further, this code (which I also immediately commented on):
It's still easier here: take the next byte from the file, add 7 and compare the resulting value with the current position of the cursor in the file stream obtained by the ftell () function. The value of n_pos must not be less than the position of the cursor (i.e. the offset in bytes from the beginning of the file).
The final line in the loop:
Those. we move the file cursor (from the beginning) to the position indicated by the function fseek () by n_pos . OK, we perform all these operations in a cycle 5 times. The _construct_key () function ends with the following code:
Thus, the last data block in the file must be a 4-byte integer value and it must be equal to the value in key_array [0] [1340] . In this case, we are waiting for a congratulatory message in the console. And otherwise - the empty array is still returned without praise :)
We have only one unparsed function - __prepare_key () . We have already guessed that it is in it that the verification data is generated in the form of the key_array array, which is then used in the _construct_key () function to verify data from the file. It remains to find out what data is there!
I will not analyze this function in detail and immediately give a full listing with comments after all the necessary variable renames:
The only place worth considering is this line:
How do I understand that here is the string "VOID"? The fact is that 0x404024 is the address in the address space of the program, leading to the .rdata section. Double click on this value allows us to see clearly what is there:

By the way, the same can be understood from the assembler code for this line:
The data corresponding to the “VOID” line is located at the very beginning of the .rdata section (at zero offset from the corresponding address).
So, at the output of this function, a two-dimensional array should be formed with the following data:
Now we can proceed to the synthesis of a binary file. All the initial data in our hands:
1) verification data (“stop symbols”) and their position in the verification array;
2) the sequence of data in the file
Let's restore the structure of the required file using the _construct_key () function algorithm . So, the sequence of data in the file will be as follows:
For clarity, I made in Excel the following label with the data of the required file:

Here in the 7th line - the data itself in the form of characters and numbers, in the 6th line - their hexadecimal representations, in the 8th line - the size of each element (in bytes), in the 9th line - offset relative to the beginning of the file. This presentation is very convenient, because allows you to enter any lines in the future file (marked with a yellow fill), while the values of the lengths of these lines, as well as the offset position of the next stop symbol are calculated by the formulas automatically, as required by the program algorithm. Above (in lines 1-4) the structure of the key_array test array is given .
The very ekselku plus other source materials for the article can be downloaded here .
It remains the case for the small - to generate the desired file in binary format and feed it to our quacks. To generate a file, I wrote a simple Python script:
The script accepts the path to the cracks with a single parameter, then generates a binary file with the key in the same directory and calls the cracks with the corresponding parameter, translating the program output to the console.
To convert text data into binary, use the struct package. The pack () method allows you to write binary data according to the format in which the data type is indicated (“B” = “byte”, “i” = int, etc.), and you can also specify the order of the sequence (“>” = “Big -endian "," <"=" Little-endian "). The default order is Little-endian. Because we have already defined in the first article that this is our case, then we indicate only the type.
The whole code reproduces the program algorithm that we found. As a string, output in case of success, I indicated “I solved this crackme!” (You can modify this script so that you can specify any string).
Check the output:

Hooray, everything works! So, after a bit of sweating and dismantling a couple of functions, we were able to completely restore the algorithm of the program and “hack” it. Of course, this is just a simple quack, a test program, and even then the 2nd level of complexity (out of 5 offered on that site). In reality, we will deal with a complex hierarchy of calls and dozens - hundreds of functions, and in some cases - encrypted data sections, garbage code and other methods of obfuscation, up to the use of internal virtual machines and P-code ... But this, as they say, already completely different story.
Materials to the article.
In this part, we, as I promised, will undertake the analysis of the _construct_key () function, which, as we found out, is responsible for reading the binary file transferred to the program and checking the read data.
Step 5 - Overview of the _construct_key () function
Let's immediately look at the full listing of this feature:
Function listing _construct_key ()
char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; } With this function we will do the same as before with main () - to begin with, let's go through the “veiled” function calls. As expected, all these functions are from standard C libraries. I will not re-describe the procedure for renaming functions — go back to the first part of the article, if necessary. As a result of the renaming, the following standard functions were found:
')
- fread ()
- strncmp ()
- strlen ()
- ftell ()
- fseek ()
- puts ()
We renamed the corresponding wrapper functions in our code (the ones that the decompiler brazenly hid behind the word _text ) by adding index 2 (so that there is no confusion with the original C functions). Almost all of these functions are used to work with file streams. It is not surprising - just a quick glance at the code to understand that there is a sequential reading of data from a file (the handle of which is passed to the function as a single parameter) and a comparison of the read data with a certain two-dimensional byte array local_14 .
Let's assume that this array contains key verification data. Let's call it, say, key_array . Since Hydra allows you to rename not only functions, but also variables, use this and rename the incomprehensible local_14 to a more understandable key_array . This is done in the same way as for functions: through the right-click menu ( Rename local ) or the L key from the keyboard.
So, immediately after declaring local variables, a certain _prepare_key () function is called :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; } We will return to _prepare_key () , this is already the 3rd level of nesting in our call hierarchy: main () -> _construct_key () -> _prepare_key () . In the meantime, let's assume that it creates and somehow initializes this “check” two-dimensional array. And only if this array is not empty, the function continues its work, as evidenced by the else block immediately after the above condition.
Then the program reads the first 4 bytes from the file and compares it with the corresponding section of the key_array array. (The code below is already after the renames made, including the variable local_19 I renamed to first_4bytes .)
first_4bytes = 0; /* 4 */ fread2(&first_4bytes,1,4,param_1); /* key_array[1][0...3] */ iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... } Thus, further execution occurs only in case of coincidence of the first 4 bytes (remember this). Then we read 2 2-byte blocks from the file (and the same key_array is used as a buffer for writing data):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1); And again - then the function only works if the next condition is true:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) { // ... } It is easy to see that the first of the 2-byte blocks read above should be the number 5, and the second the number 4 (the data type short just takes 2 bytes on 32-bit platforms).
Next is this:
local_30[0] = *key_array; // .. key_array[0] local_30[1] = *key_array + 0x10c; local_30[2] = *key_array + 0x218; local_30[3] = *key_array + 0x324; local_20 = *key_array + 0x430; Here we see that in the local_30 array (declared as char * local_30 [4]), the offsets of the key_array pointer are entered . That is, local_30 is an array of marker strings into which data from a file will most likely be read. By this assumption, I renamed local_30 to markers . In this part of the code, only the last line seems a bit suspicious, where the assignment of the last offset (at index 0x430, ie 1072) is performed not to the next markers element, but to a separate variable local_20 ( char * ). But with this we will understand, but for now - let's move on!
Next we have a cycle:
i = 0; // local_10 i while (i < 5) { // ... i = i + 1; } Those. Only 5 iterations from 0 to 4 inclusive. The loop immediately begins reading from the file and checking for compliance with our array of markers :
char c_marker = 0; // local_35 /* . */ fread2(&c_marker, 1, 1, param_1); if (*markers[i] != c_marker) { /* - */ _free_key(key_array); return (char **)0x0; } That is, the next byte from the file is read into the variable c_marker (in the original decompiled code is local_35 ) and checked for compliance with the first character of the i-th markers element. If there is a mismatch, the key_array array is reset and an empty double pointer is returned. Further along the code, we see that this happens every time the read data does not match the verification data.
But here, as they say, "the dog is buried." Let's take a closer look at this cycle. It has 5 iterations, as we found out. You can check this if you want by looking at the assembler code:
Indeed, the CMP command compares the value of the variable local_10 (we already have i ) with the number 4 and if the value is less than or equal to 4 (the JLE command), a transition is made to the label LAB_004017eb , i.e. the beginning of the body of the cycle. Those. the condition will be met for i = 0, 1, 2, 3, and 4 — a total of 5 iterations! Everything would be fine, but markers are also indexed by this variable in a loop, and this array is only declared with 4 elements:
char *markers [4]; So someone is obviously trying to fool someone :) Do you remember, I said that this line makes you doubt?
local_20 = *key_array + 0x430; And how! Just look at the entire function listing and try to find another at least one reference to the local_20 variable. She is not! From here we conclude: this offset should also be stored in the markers array, and the array itself should contain 5 elements. Let's fix it. Go to the declaration of the variable, wait for Ctrl + L (Retype variable) and boldly change the size of the array to 5:
Is done. Scroll below to the code for assigning pointer offsets to the markers , and - lo and behold! - the incomprehensible extra variable disappears and everything falls into place:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430; // ... ! We return to our while loop (in the source code it will most likely be for , but we don’t care). Then again the byte from the file is read and its value is checked:
byte n_strlen1 = 0; // local_36 /* . */ fread2(&n_strlen1,1,1,param_1); if (n_strlen1 == 0) { /* */ _free_key(key_array); return (char **)0x0; } OK, this n_strlen1 should be non-zero. Why? Now you will see, and at the same time you will understand why I assigned the following name to this variable:
/* n_strlen1) (markers[i] + 0x104) */ *(uint *)(markers[i] + 0x104) = (uint)n_strlen1; /* (n_strlen1) (--> ?) */ fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1); // sVar2 if (n_strlen2 != *(size_t *)(markers[i] + 0x104)) { /* (n_strlen2) == n_strlen1 */ _free_key(key_array); return (char **)0x0; } I added comments on which everything should be clear. The file reads n_strlen1 bytes and is stored as a sequence of characters (ie, a string) into the array markers [i] —that is, after the corresponding “stop character”, which is already written from key_array . Preserving the value of n_strlen1 in markers [i] at offset 0x104 (260) does not play any role here (see the first line in the code above). In fact, this code can be optimized as follows (and surely this is how it is in the source code):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... } It also checks that the length of the line read is n_strlen1 . This may seem redundant, given that this parameter was passed to the fread function, but fread reads no more than so many specified bytes and can read less than indicated, for example, in the case of a file end token (EOF). That is, everything is strict: the file specifies the length of the line (in bytes), then the line itself goes - and so exactly 5 times. But we are running ahead.
Further, this code (which I also immediately commented on):
uint n_pos = 0; // local_3c /* . */ fread2(&n_pos,1,1,param_1); /* 7 */ n_pos = n_pos + 7; /* */ uint n_filepos = ftell2(param_1); // uVar3 if (n_pos < n_filepos) { /* n_pos >= n_filepos */ _free_key(key_array); return (char **)0x0; } It's still easier here: take the next byte from the file, add 7 and compare the resulting value with the current position of the cursor in the file stream obtained by the ftell () function. The value of n_pos must not be less than the position of the cursor (i.e. the offset in bytes from the beginning of the file).
The final line in the loop:
fseek2(param_1,n_pos,0); Those. we move the file cursor (from the beginning) to the position indicated by the function fseek () by n_pos . OK, we perform all these operations in a cycle 5 times. The _construct_key () function ends with the following code:
int i_lastmarker = 0; // local_34 /* 4 (int32) */ fread2(&i_lastmarker,4,1,param_1); if (*(int *)(*key_array + 0x53c) == i_lastmarker) { /* == key_array[0][1340] ... :) */ puts2("Markers seem to still exist"); } else { _free_key(key_array); key_array = (char **)0x0; } Thus, the last data block in the file must be a 4-byte integer value and it must be equal to the value in key_array [0] [1340] . In this case, we are waiting for a congratulatory message in the console. And otherwise - the empty array is still returned without praise :)
Step 6 - Overview of the __prepare_key () function
We have only one unparsed function - __prepare_key () . We have already guessed that it is in it that the verification data is generated in the form of the key_array array, which is then used in the _construct_key () function to verify data from the file. It remains to find out what data is there!
I will not analyze this function in detail and immediately give a full listing with comments after all the necessary variable renames:
Listing function __prepare_key ()
void ** __prepare_key(void) { void **key_array; void *pvVar1; /* key_array = new char*[2]; // 2 4- (char*) */ key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); /* key_array[0] = new char[1340] */ *key_array = pvVar1; pvVar1 = calloc2(1,8); /* key_array[1] = new char[8] */ key_array[1] = pvVar1; /* "VOID" */ *(undefined4 *)key_array[1] = 0x404024; /* 5 4 (2- ) */ *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; /* key_array[0][0] = 'b' */ *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; /* 'W' */ *(undefined *)((int)*key_array + 0x218) = 0x57; /* 'p' */ *(undefined *)((int)*key_array + 0x324) = 0x70; /* 'l' */ *(undefined *)((int)*key_array + 0x10c) = 0x6c; /* 152 ( ASCII) */ *(undefined *)((int)*key_array + 0x430) = 0x98; /* = 1122 (int32) */ *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; } The only place worth considering is this line:
*(undefined4 *)key_array[1] = 0x404024; How do I understand that here is the string "VOID"? The fact is that 0x404024 is the address in the address space of the program, leading to the .rdata section. Double click on this value allows us to see clearly what is there:
By the way, the same can be understood from the assembler code for this line:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
The data corresponding to the “VOID” line is located at the very beginning of the .rdata section (at zero offset from the corresponding address).
So, at the output of this function, a two-dimensional array should be formed with the following data:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Step 7 - Preparing a binary file for cracks
Now we can proceed to the synthesis of a binary file. All the initial data in our hands:
1) verification data (“stop symbols”) and their position in the verification array;
2) the sequence of data in the file
Let's restore the structure of the required file using the _construct_key () function algorithm . So, the sequence of data in the file will be as follows:
File structure
- 4 bytes == key_array [1] [0 ... 3] == "VOID"
- 2 bytes == key_array [1] [4] == 5
- 2 bytes == key_array [1] [6] == 4
- 1 byte == key_array [0] [0] == 'b' (marker)
- 1 byte == (length of the next line) == n_strlen1
- n_strlen1 bytes == (any string) == n_strlen1
- 1 byte == (+7 == next marker) == n_pos
- 1 byte == key_array [0] [0] == 'l' (marker)
- 1 byte == (length of the next line) == n_strlen1
- n_strlen1 bytes == (any string) == n_strlen1
- 1 byte == (+7 == next marker) == n_pos
- 1 byte == key_array [0] [0] == 'W' (marker)
- 1 byte == (length of the next line) == n_strlen1
- n_strlen1 bytes == (any string) == n_strlen1
- 1 byte == (+7 == next marker) == n_pos
- 1 byte == key_array [0] [0] == 'p' (marker)
- 1 byte == (length of the next line) == n_strlen1
- n_strlen1 bytes == (any string) == n_strlen1
- 1 byte == (+7 == next marker) == n_pos
- 1 byte == key_array [0] [0] == 152 (marker)
- 1 byte == (length of the next line) == n_strlen1
- n_strlen1 bytes == (any string) == n_strlen1
- 1 byte == (+7 == next marker) == n_pos
- 4 bytes == (key_array [1340]) == 1122
For clarity, I made in Excel the following label with the data of the required file:
Here in the 7th line - the data itself in the form of characters and numbers, in the 6th line - their hexadecimal representations, in the 8th line - the size of each element (in bytes), in the 9th line - offset relative to the beginning of the file. This presentation is very convenient, because allows you to enter any lines in the future file (marked with a yellow fill), while the values of the lengths of these lines, as well as the offset position of the next stop symbol are calculated by the formulas automatically, as required by the program algorithm. Above (in lines 1-4) the structure of the key_array test array is given .
The very ekselku plus other source materials for the article can be downloaded here .
Binary file generation and verification
It remains the case for the small - to generate the desired file in binary format and feed it to our quacks. To generate a file, I wrote a simple Python script:
Script to generate a file
import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main() The script accepts the path to the cracks with a single parameter, then generates a binary file with the key in the same directory and calls the cracks with the corresponding parameter, translating the program output to the console.
To convert text data into binary, use the struct package. The pack () method allows you to write binary data according to the format in which the data type is indicated (“B” = “byte”, “i” = int, etc.), and you can also specify the order of the sequence (“>” = “Big -endian "," <"=" Little-endian "). The default order is Little-endian. Because we have already defined in the first article that this is our case, then we indicate only the type.
The whole code reproduces the program algorithm that we found. As a string, output in case of success, I indicated “I solved this crackme!” (You can modify this script so that you can specify any string).
Check the output:
Hooray, everything works! So, after a bit of sweating and dismantling a couple of functions, we were able to completely restore the algorithm of the program and “hack” it. Of course, this is just a simple quack, a test program, and even then the 2nd level of complexity (out of 5 offered on that site). In reality, we will deal with a complex hierarchy of calls and dozens - hundreds of functions, and in some cases - encrypted data sections, garbage code and other methods of obfuscation, up to the use of internal virtual machines and P-code ... But this, as they say, already completely different story.
Materials to the article.
Source: https://habr.com/ru/post/447488/
All Articles