RBKmoney Payments under the hood - the logic of the payment platform

Hi, Habr! I continue to publish a cycle about the insides of the RBK.money payment platform, begun in this post . Today we will talk about processing logic, specific microservices and their interrelation with each other, how services that process each piece of business logic are logically separated, why the processing core does not know anything about the numbers of your payment cards and how payments run around the platform. Also, in a little more detail, I’ll cover the topic of how we provide high availability and scaling for high load handling.
Overview logic and general approaches
In general, the scheme of the main elements of the processing part that is responsible for payments looks like this.
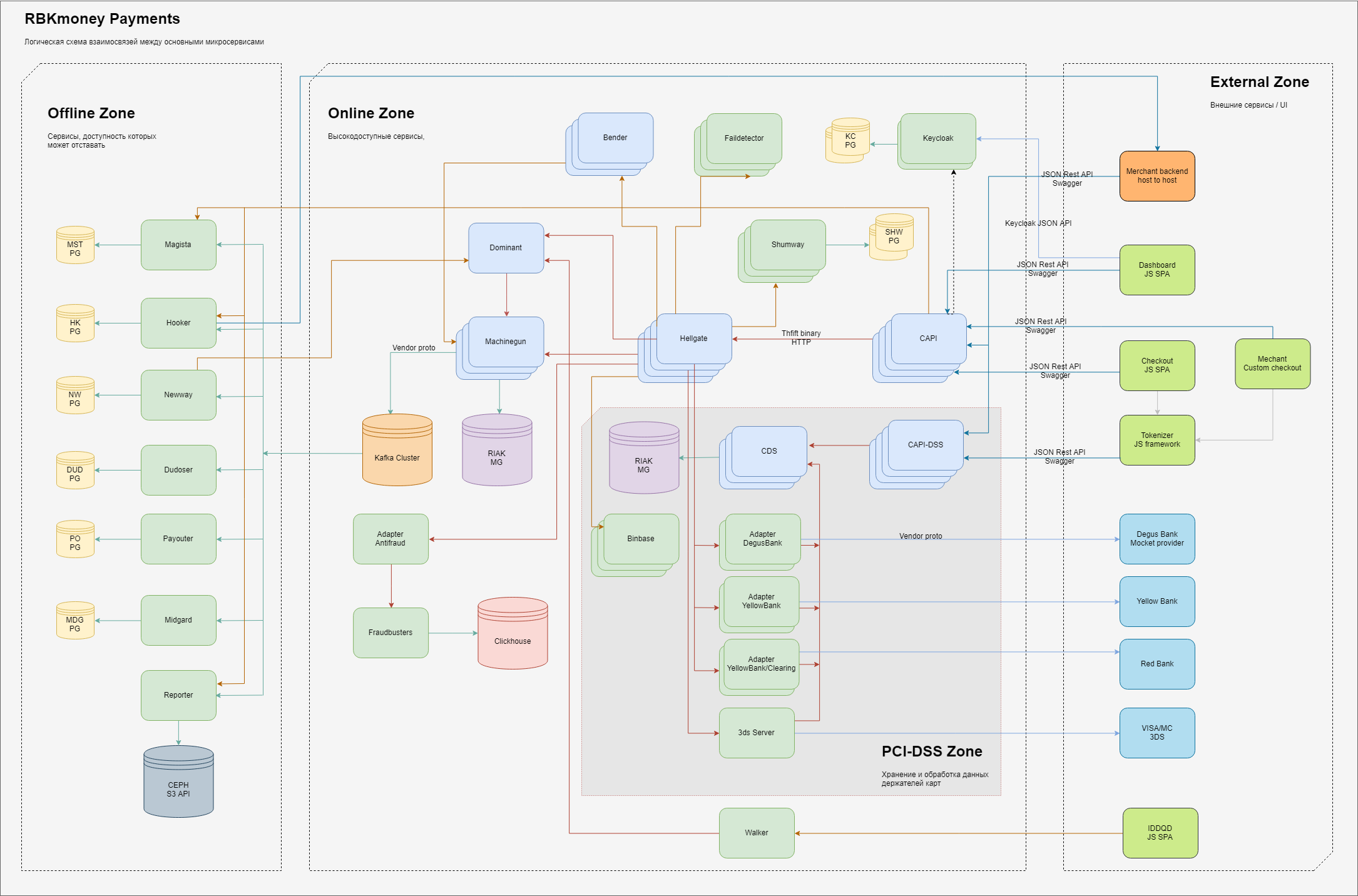
Logically within ourselves, we divide areas of responsibility into 3 domains:
- the external zone, entities that are on the Internet, such as JS applications of our payment form (this is where you enter your card details), backends of our merchant clients, as well as processing gateways of our partner banks and providers of other payment methods;
- internal high-access zone, microservices live there, which provide work directly for the payment gateway and manage the debiting of money, taking them into account within our system and other online services that are characterized by the requirement “must always be available, despite any failures within our business centers”;
- here, the zone of services that work directly with complete cardholder data is separately distinguished; these services have separate requirements put forward by the IPS and subject to mandatory certification within the framework of the PCI-DSS standards. In more detail, why exactly such a division will be described below;
- The internal zone, where lower demands are placed on the availability of the services provided or the time of their response, in the classical sense is the back office. Although, of course, here we are also trying to ensure the principle of "always available", we just spend less effort on it;
Within each of the zones there are microservices that perform their parts of the processing of business logic. At the entrance, they accept RPC calls, at the output they generate data processed by the algorithms laid down, also arranged in the form of calls to other microservices along the chain.
To ensure scalability, we try to store states in as few places as possible. The stateless services on the diagram do not have connections to persistent storages, stateful, respectively, are connected to them. In general, we use several limited services for persistent state storage — for the main part of the processing, these are Riak KV clusters, for related services — PostgreSQL, for asynchronous queue processing we use Kafka.
To ensure high availability, we deploy services in several instances, usually from 3 to 5.
It is easy to scale stateless services, just raise the number of instances we need on different virtual machines, they register with the Consul, become available for resolving the consul DNS and start receiving calls from other services, processing the received data and sending them further.
Stateful services, or rather our main one, is shown on the diagram as Machinegun, they implement a highly accessible interface (the distributed architecture is based on Erlang Distribution), and to provide guarantees of priority and distributed locking, synchronization via Consul KV. In short, a detailed description will be in a separate post.
Riak out of the box provides high-available persistent masterless storage, we don’t prepare it for anything, the config is almost default. With the current load profile, we have 5 nodes in the cluster, deployed on separate hosts. Important note - we practically do not use indexes and large data samples, we work with specific keys.
Where it is too expensive to implement a KV scheme, we use PostgeSQL databases with replication, or even single-solution solutions, because we can always pour the necessary events from the online part through Machinegun.
The color separation of microservices in the diagram indicates the languages in which they are written — light green — these are Java applications, light blue — Erlang.
All services operate in Docker containers, which are build artifacts on CI and are located in the local Docker Registry. Deploys services in SaltStack production, the configuration of which is in a private Github repository.
Developers independently make change requests to this repository, where they describe the requirements for the service - indicate the version and parameters you need, such as the size of the memory allocated for the container, transferred to environment variables and so on. Further, after manually confirming the change request by authorized employees (we have this devops, support and information security), the CD automatically rolls out the copies of the containers with the new versions to the hosts of the product environment.
Also, each service writes logs in a format understandable for Elasticsearch. Log files are picked up by Filebeat, which writes them to the Elasticsearch cluster. Thus, despite the fact that developers do not have access to the product environment, they always have the opportunity to debug and see what happens to their services.
Interaction with the outside world

Any change in the state of the platform takes place exclusively through calls to the corresponding public API methods. We do not use classic web applications and server-side content generation; in fact, everything you see as a UI is a JS view above our public APIs. In principle, any action in the platform can be performed by a chain of curl calls from the console, which is what we use. In particular, for writing integration tests (they are written in JS in the form of a library), which at CI with every assembly checks all public methods.
Also, this approach solves all the problems of external integration with our platform, allowing you to get a single protocol both for the end user in the form of a beautiful form of entering payment information, and host-to-host for direct integration with third-party processing using only inter-server interaction.
In addition to full coverage of integration tests, we use staging update approaches, in a distributed architecture, this is fairly easy to do, for example, rolling out only one service from each group in one pass, followed by a pause and analysis of logs and graphs.
This allows us to deploy almost around the clock, including Friday evenings, without much fear to roll out something unworkable or quickly roll back, making a simple revert commit with the change, while no one noticed.
Registration in the platform and public API

Before any call to the public method, we need to authorize and authenticate the client. In order for a client to appear on the platform, you need a service that will take over all the interaction with the end user, provide interfaces for registering, entering and resetting passwords, security controls, and other binding.
Here we did not reinvent the wheel, but simply integrated the open source solution from Redhat - Keycloak . Before starting any interaction with us, you will need to register in the platform, which is actually happening through Keycloak.
After successful authentication in the service, the client receives JWT. We use it later for authorization - on the Keycloak side, you can specify arbitrary fields that describe the roles that will be embedded as a simple json structure in JWT and signed by the private key of the service.
One of the features of JWT is that this structure is signed by the server's private key; accordingly, to authorize the list of roles and its other objects, we do not need to contact the authorization service, the process is completely untied. CAPI services at startup read the Keycloak public key and use it to authorize calls to public API methods.
As we came up with a key recall scheme - the story is separate and deserves its own post.
So, we have received JWT, we can use it for authentication. This is where the Common API microservice group comes into play, on the schema indicated as CAPI and CAPI-DSS, implementing the following functions:
- authorization of received messages. Each public API call is preceded by an Authorizaion: Bearer {JWT} HTTP header. The services of the Common API group use it to verify the signed data with the available public key of the authorization service;
- validation of received data. Since the schema is described as an OpenAPI specification, also known as Swagger, it is very easy to validate the data and with a small amount of probability to get control commands in the data stream. This has a positive effect on the security of the service as a whole;
- translation of data formats from public REST JSON to internal binary Thrift;
- framing the transport binding with data such as a unique trace_id and sending the event further into the platform to the service that manages business logic and knows what payment is, for example.
We have a lot of such services, they are quite simple and oak, they do not store any states, respectively, for linear scaling of performance, we simply deploy them on available capacity in the quantities we need.
PCI-DSS and open card data

As you can see in the diagram, we have two such service groups - the main one, the Common API, is responsible for processing all data streams that do not have open cardholder data, and the second, the Common PCI-DSS API, which works directly with these cards. Inside, they are absolutely identical, but we physically divided them and placed them on different glands.
This is done in order to minimize the number of places for storing and processing card data, to reduce the risks of leakage of this data and the scope of PCI-DSS certification. And this, believe me, is a rather laborious and costly process - as a payment company, we are required to undergo paid certification for compliance with IPU standards every year, and the fewer servers and services it takes, the faster and easier it is to go through this process. Well, this is reflected in safety in the most positive way.
Billing Processing and Tokenization
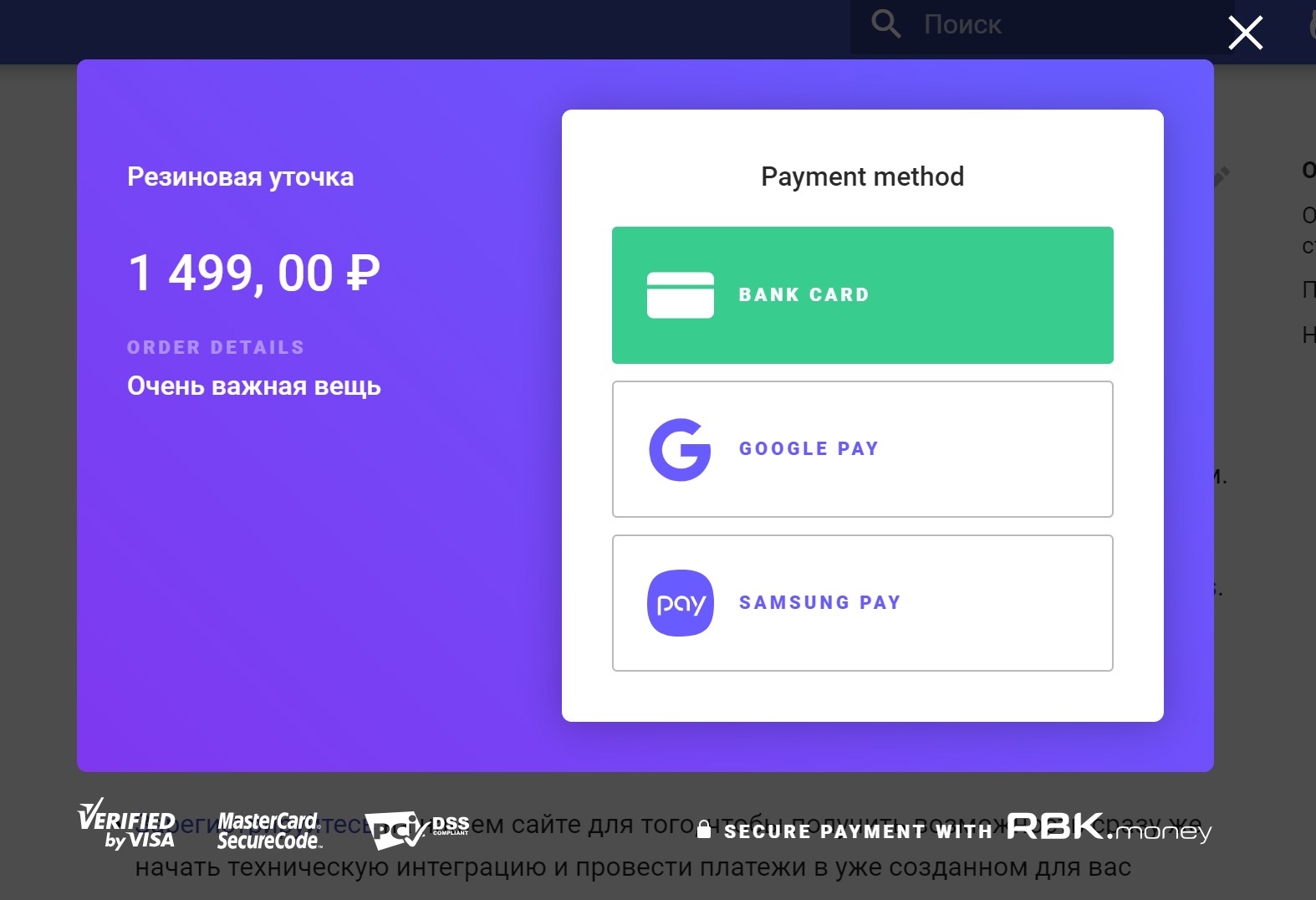
So, we want to start the payment and write off the money from the payer's card.
Imagine that a request for this came in the form of a chain of calls to the methods of our public API, which was initiated by you as a payer after you went to the online store, collected a basket of goods, clicked "Buy", entered your card details into our billing form and clicked "Pay".
We provide different business processes for writing off money, but the process with the use of invoices seems to be the most interesting. In our platform, you can create an invoice for payment, or an invoice, which will be a container for payments.
Inside one invoice, you can alternately make attempts to pay for it, i.e., create payments until the next payment is successful. For example, you can try to pay an invoice with different cards, wallets and any other payment methods. If there is no money on one of the cards, you can try another one and so on.
This has a positive effect on conversion and user experience.
Invoice machine

Inside the platform, this chain turns into interaction along the following route:
- Before delivering content to your browser, our merchant client integrated with our platform, registered with us and received JWT for authorization;
- the merchant called the createInvoice () method from his backend, that is, he created an invoice for payment in our platform. In fact, the merchant backend sent an HTTP POST request of the following content to our endpoint:
curl -X POST \ https://api.rbk.money/v2/processing/invoices \ -H 'Authorization: Bearer {JWT}' \ -H 'Content-Type: application/json; charset=utf-8' \ -H 'X-Request-ID: 1554417367' \ -H 'cache-control: no-cache' \ -d '{ "shopID": "TEST", "dueDate": "2019-03-28T17:41:32.569Z", "amount": 6000, "currency": "RUB", "product": "Order num 12345", "description": "Delicious meals", "cart": [ { "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "metadata": { "order_id": "Internal order num 13123298761" } }' The request was balanced on one of the erlang applications of the Common API group, which checked its validity, went to the Bender service, where it received an idempotency key, translated it into a trift and sent a request to the Hellgate service group. The Hellgate instance did business checks, for example, made sure that the owner of this JWT is not blocked in principle, can create invoices and interact with the platform in general, and started creating an invoice.
We can say that Hellgate is the core of our processing, since it is he who operates business entities, knows how to start a payment, who needs to be kicked, so that this payment can turn into a real write-off, how to calculate the route of this payment, who can say to make this write-off reflected on the balances, calculate the commission and other strapping.
Which is typical, also does not store any state and also easily scaled. But we would not like to lose the invoice, or receive a double debit from the card in the event of network split or Hellgate failure for any reason. It is necessary to save this data persistently.
Here the third microservice comes into play, namely Machinegun. Hellgate sends a “create automaton” call to Machinegun with a payload in the form of request parameters. Machinegun orders the parallel queries and uses Hellgate from the parameters to create the first event, InvoiceCreated. Which then he himself writes to the Riak and the queue. After that, a successful response is returned to the original request through the chain in the reverse order.
In short, Machinegun is such a DBMS with timers over any other DBMS, in the current version of the platform - over Riak. It provides an interface that allows you to manage independent machines, and provides guarantees of idempotency and order of recording. That MG will not allow to record the event in the machine out of turn, if several HGs suddenly come to him with such a request.
An automaton is a unique entity within the platform consisting of an identifier, a data set in the form of a list of events and a timer. The final state of the automaton is calculated from the processing of all its events, which initiate its transition to the corresponding state. We use this approach to work with business entities, describing them as finite state machines. In fact, all invoices created by our merchants, as well as payments in them, are finite automata with their own logic of transition between states.
The interface for working with timers in Machinegun allows you to receive a request like “I want to continue processing this machine after 15 years” from another service along with events for recording. Such pending tasks are implemented on built-in timers. In practice, they are used very often - periodic calls to the bank, automatic actions with payments due to long inactivity, etc.
By the way, the source code for Machinegun is open under the Apache 2.0 license in our public repository . We hope that this service can be useful to the community.
A detailed description of the work of Machinegun, and in general how we prepare the distribution, pulls into a separate big post, so I will not dwell here in more detail.
Nuances of authorization of external clients

After successful saving, Hellgate returns the data to the CAPI, which converts the binary trift structure into beautifully designed JSON, ready to be sent to the merchant's backend:
{ "invoice": { "amount": 6000, "cart": [ { "cost": 5000, "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "cost": 1000, "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "createdAt": "2019-04-04T23:00:31.565518Z", "currency": "RUB", "description": "Delicious meals", "dueDate": "2019-04-05T00:00:30.889000Z", "id": "18xtygvzFaa", "metadata": { "order_id": "Internal order num 13123298761" }, "product": "Order num 12345", "shopID": "TEST", "status": "unpaid" }, "invoiceAccessToken": { "payload": "{JWT}" } } It would seem that you can give content to the browser to the payer and start the payment process, but then we thought that not all merchants would be ready to independently implement authorization on the client side, therefore, they implemented it themselves. The approach is that CAPI generates another JWT that allows you to start the process of tokenization of cards and manage a specific invoice and adds it to the returned invoice structure.
An example of the roles described inside a similar JWT:
"resource_access": { "common-api": { "roles": [ "invoices.18xtygvzFaa.payments:read", "invoices.18xtygvzFaa.payments:write", "invoices.18xtygvzFaa:read", "payment_resources:write" ] } } This JWT has a limited number of usage attempts and a life span that we can customize, which allows you to publish it in the payer's browser. Even if he is intercepted, the maximum that an attacker can do is pay for someone else's invoice or read his data. Moreover, since the payment machine does not operate with open card data, the maximum that an attacker can see is the masked card number of the form 4242 42** **** 4242 , the amount of payment and, optionally, the basket of goods.
The created invoice and its access key allow you to start the payment business process. We give the invoice identifier and its JWT to the browser to the payer and transfer control to our JS applications.
Our Checkout JS application implements the interface of interaction with you as a payer - draws a form for entering payment information, starts a payment, gets its final status, shows a funny or sad Point.
Tokenization and card data

But Checkout does not work with card data. As mentioned above, we want to store sensitive data in the form of cardholder data in as few places as possible. For this, we implement tokenization.
This is where the Tokenizer JS library comes into play. When you enter your card in the input fields and click "Pay", it intercepts this data and asynchronously sends it to us in processing, calling the createPaymentResource () method.
This request is balanced by individual CAPI-DSS applications, which also authorize the request, only by checking the invoice JWT, validating the data and sending it to the card data storage service. In the diagram, it is listed as CDS - Card Data Storage.
The main objectives of this service:
- receive sensitive data as input, in our case - your card data;
- Encrypt this data with a data encryption key
- generate some random value used as a key;
- save encrypted data with this key in your Riak cluster;
- return the key in the form of a billing token to the CAPI-DSS service.
Along the way, the service solves a bunch of important tasks, such as generating keys for encrypting keys, securely entering these keys, re-encrypting data, controlling the CVV overwriting after making a payment, and so on, but this is beyond the scope of this post.
It was not without protection from the possibility to shoot yourself in the foot. There is a non-zero probability that the private JWT, which is designed to authorize requests from the backend, will be published on the web to the client’s browser. To prevent this from happening, we have built in protection — you can only call the createPaymentResource () method with the invoice authorization key. If you try to use a private JWT platform, it returns an HTTP / 401 error.
After the tokenization request is completed, Tokenizer returns the received token to Checkout and finishes its work with this.
Business process of the payment machine

Checkout starts the payment process, namely, it calls the createPayment () method, passing as an argument the card data token received earlier and starts the polling process of the events, actually, once per second, calling the getInvoiceEvents () API method.
These requests through CAPI fall into Hellgate, which begins to implement the payment business process, while not using card data:
- first of all, Hellgate goes to the configuration management service - Dominant and receives the current revision of the domain configuration. It contains all the rules by which this payment will be made, then which bank it will go to for authorization, which transaction entries will be recorded and so on;
- from the member management service, now it is part of HG, it finds out the data on the internal numbers of the merchant’s accounts for the benefit of which the payment is made, applies the amount of commissions, prepares the plan of transactions and stuffs it into the Shumway service. This service is responsible for managing information about the movement of money in the accounts of participants in the transaction during the payment. The posting plan contains the instruction “to freeze the possible movement of funds in the transaction participants’ accounts specified in the plan ”;
- enriches payment data by accessing additional services, for example, in Binbase, in order to find out the country of the issuing bank that issued the card and its type, for example, "gold, credit";
- calls the inspector service, as a rule, this is Antifraud in order to get the payment scoring and decide on the choice of the terminal covering the risk level issued by the scoring. For example, a terminal without 3D-Secure can be used for low-risk payments, and a payment that has received a fatal risk level will end its life there;
- calls the error detection service, the Faultdetector, and, based on the data received from it, chooses a payment transaction - the bank protocol adapter, which currently has the least amount of errors and the highest probability of a successful payment;
- sends a request to the selected bank protocol adapter, even if in this case it will be the YellowBank Adapter, “authorize the specified amount from this token”.
The protocol adapter for the received token calls the CDS, receives the decrypted card data, translates it into a bank-specific protocol, and generally receives authorization — confirmation from the acquiring bank that the specified amount is frozen in the payer's account.
It is at this moment that you receive an SMS with a message about withdrawing funds from your card from your bank, although in fact the funds are in fact only frozen in your account.
The adapter notifies HG of successful authorization, your CVV code is deleted from the CDS service and the interaction phase ends here. Management returns to HG.

Depending on what was called when creatingPayment () was called by the merchant of the payment business process, HG expects an external API to call the authorization capture method, i.e., confirm the debit of money from your card, or does it immediately on its own, if the merchant chose the scheme single payment.
As a rule, most merchants use a single-stage payment, however there are business categories that, at the time of receiving authorization, do not yet know the total amount of the write-off. This often happens in the tourism industry, when you book a tour for one amount, and after confirming your reservation, the amount is clarified and may differ from the one that was authorized at the beginning.
Despite the fact that the amount of confirmation can only be equal to or less than the amount of authorization, there are pitfalls. Imagine that you are paying with a card product or service in a currency other than the currency of your bank account to which the card is linked.
At the time of authorization, your account blocks the amount based on the exchange rate on the day of authorization. Since the payment may be in the status of "authorized" (despite the fact that the IPU has recommendations for the maximum period and now is 3 days) for several days, the authorization will be seized at the rate of the day on which it was made.
Thus, you bear currency risks that can be both in your favor and against you, especially in a situation of high volatility in the currency market.
To capture the authorization, the same process of communication with the protocol adapter occurs as for its receipt, and if successful, HG applies the plan of posting to the accounts within Shumway, and transfers the payment to the "Paid" status. It is at this moment that we, as a payment system, have financial obligations to the parties to the transaction.
It is also worth noting that any changes in the status of the invoice machine, to which the payment process relates, are recorded by Hellgate in Machinegun, ensuring data persistence and enriching the invoice with new events.
Synchronization of payment machine states and UI
While the payment process takes place inside the platform, Checkout lightens processing by requesting events. When receiving certain events, it draws the current status of the payment in a form understandable to the person — draws a preloader, shows the screen “Your payment was successfully processed” or “Payment failed” or redirects the browser to the page of your issuing bank to enter the 3D-Secure password;
In case of failure, Checkout will offer to choose another payment method or try again, thus launching a new payment within the invoice.
Such a scheme with event polling allows you to restore the state even after the browser tab is closed - if you restart Checkout, it will receive the current list of events and draw up the current scenario of user interaction, for example, it will offer to enter the 3D-Secure code or show that the payment has already been successfully completed.
Offline Zone Event Replication
Simultaneously with the machine control interfaces, Machinegun implements a service responsible for transferring the flow of events to services that are responsible for other, less online platform tasks.
As a queuing broker in the finals, we settled on Kafka, although we previously implemented this functionality through the use of Machinegun itself. In the general case, this service is the preservation of a guaranteed ordered stream of events, or the issuance of a specific list of events on request to other consumers.
We also initially implemented the event deduplication scheme, providing guarantees that the same event will not be replicated twice, however, the load on Riak that generated such an approach made it refuse - after all, searching by indices is not the best that KV storage. Now each service consumer is responsible for event deduplication.
In the general case, the replication of events from Machinegun ends on the confirmation of saving data in Kafka, and consumers are already connecting to the Kafka topics and pumping out those lists of events that interest them.
Typical Offline Zone Application Template
For example, the Dudoser service is responsible for sending you an email notification of a successful payment. When it starts, it downloads a list of events of successfully completed payments, takes the address and amount information from there, saves it to the local PostgreSQL instance and uses it for further processing of business logic.
All other similar services operate according to the same logic as, for example, the Magista service, which is responsible for finding invoices and payments in the merchant’s personal account or the Hooker service, which sends asynchronous callbacks to the backend merchants, who for one reason or another cannot organize polling events, turning directly to the processing API.
This approach allows us to unleash the processing load, allocating maximum resources and ensuring high speed and availability of payment processing, providing high conversion. Heavy requests like "business customers want to see statistics on payments for the last year" are processed by services that do not affect the current load of the online part of the processing, and accordingly do not affect you, as payers and merchants, as our customers.
Perhaps we’ll stop on this in order not to turn the post into a too long longrid. In future articles I will definitely tell you about the nuances of ensuring the atomicity of changes, guarantees and priority in a loaded distributed system using the example of Machinegun, Bender, CAPI and Hellgate.
Well, about the Salt Stack next time already ¯\_(ツ)_/¯
')
Source: https://habr.com/ru/post/447440/
All Articles