Recommendations for configuring AFA AccelStor when working with VMware vSphere
In this article, I would like to talk about the features of the operation of All Flash AccelStor arrays with one of the most popular virtualization platforms - VMware vSphere. In particular, focus on those parameters that will help get the maximum effect from the use of such a powerful tool as All Flash.

All Flash AccelStor NeoSapphire ™ arrays are one or two node devices based on SSDs with a fundamentally different approach to implementing the concept of storing data and accessing it using proprietary FlexiRemap® technology instead of the very popular RAID algorithms. Arrays provide block access for hosts via Fiber Channel or iSCSI interfaces. In fairness, we note that models with an iSCSI interface also have file access as a nice bonus. But within this article we will focus on the use of block protocols as the most productive for All Flash.
The whole process of deployment and subsequent configuration of the joint operation of the AccelStor array and the VMware vSphere virtualization system can be divided into several stages:
- Implementation of the connection topology and SAN network configuration;
- Setting All Flash array;
- Configure ESXi hosts;
- Configure virtual machines.
AccelStor NeoSapphire ™ with Fiber Channel interface and iSCSI interface were used as equipment for the examples. As base software - VMware vSphere 6.7U1.
Before deploying the systems described in this article, it is highly recommended that you read VMware documentation on performance issues ( Performance Best Practices for VMware vSphere 6.7 ) and iSCSI settings ( Best Practices For Running VMware vSphere On iSCSI ).
Connection topology and SAN network configuration
The main components of a SAN network are HBA adapters in ESXi hosts, SAN switches and array nodes. A typical topology of such a network would look like this:
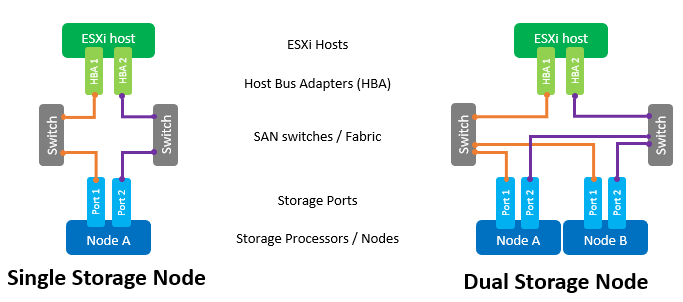
The term Switch means here a separate physical switch or a set of switches (Fabric), as well as a device shared between different services (VSAN in the case of Fiber Channel and VLAN in the case of iSCSI). The use of two independent switches / Fabric will eliminate the possible point of failure.
Direct connection of hosts to the array, although supported, is highly discouraged. The performance of All Flash arrays is quite high. And for maximum speed it is required to use all the ports of the array. Therefore, at least one switch between the hosts and NeoSapphire ™ is required.
Having two ports on a host HBA is also a requirement for maximum performance and fault tolerance.
If you use the Fiber Channel interface, you need to configure zoning to eliminate possible conflicts between initiators and targets. Zones are built on the principle “one port of initiator - one or several ports of the array”.
If an iSCSI connection is used in case of using a switch shared with other services, then it is imperative that you isolate iSCSI traffic within a separate VLAN. It is also highly recommended to include support for Jumbo Frames (MTU = 9000) to increase the size of packets in the network and, thereby, reduce the amount of service information during transmission. However, it is worth remembering that in order to work correctly, it is necessary to change the MTU parameter on all components of the network along the initiator-switch-target chain.
Configuring All Flash Array
The array is delivered to customers with already formed FlexiRemap® groups. Therefore, no action to unite the drives into a single structure is not necessary. It is enough to create volumes of the required size and quantity.
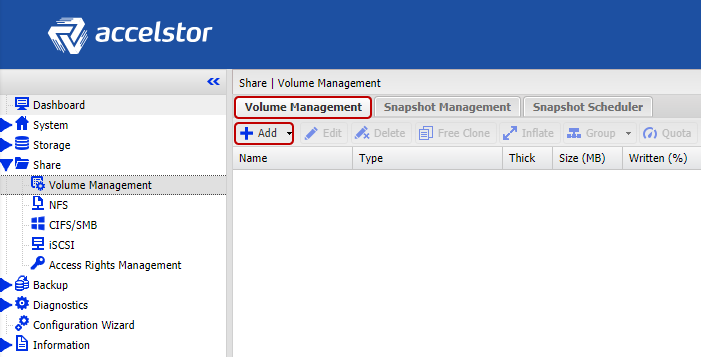
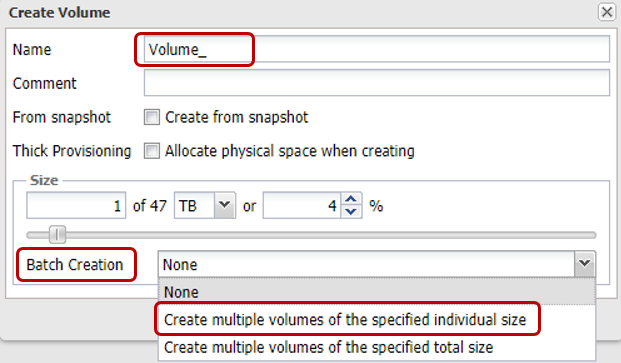
For convenience, there is the functionality of batch creation of several volumes of a given volume at once. By default, thin volumes are created, since this allows for more efficient use of available storage space (including through the support of Space Reclamation). In terms of performance, the difference between “thin” and “thick” volumes does not exceed 1%. However, if you want to "squeeze all the juice" from the array, you can always convert any "thin" volume to "thick." But it should be remembered that such an operation is irreversible.
Next, it remains to “publish” the created volumes and set access rights to them by the hosts using ACLs (IP addresses for iSCSI and WWPN for FC) and physical separation across the ports of the array. For iSCSI models, this is done through the creation of Target.
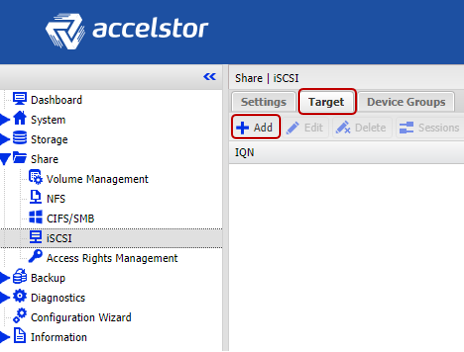

For FC models, publication occurs through the creation of a LUN for each port in the array.
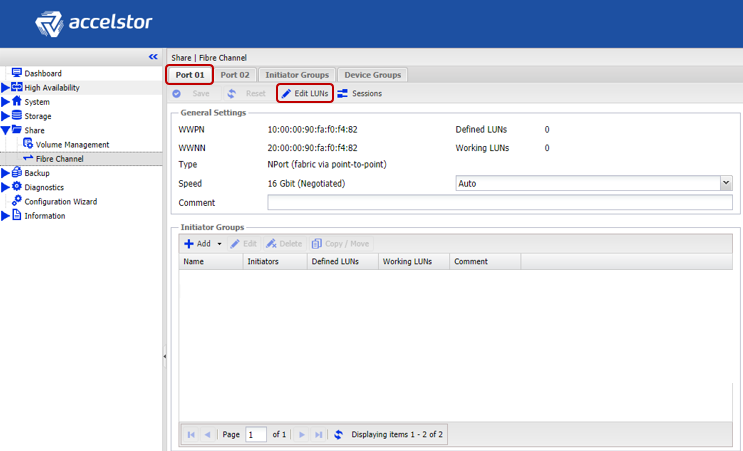
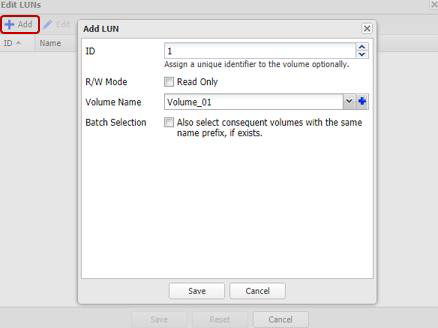
To speed up the configuration process, hosts can be grouped together. Moreover, if a multi-port FC HBA is used on the host (which in practice most often happens), the system automatically determines that the ports of such an HBA are assigned to a single host due to the WWPN, which differs by one. Batch Target / LUN creation is also supported for both interfaces.
An important note in the case of using the iSCSI interface is the creation of several targets for volumes at once to increase performance, since the queue on the target cannot be changed, and it will actually be a bottleneck.
Configuring ESXi hosts
On the ESXi side of the hosts, the basic configuration is performed according to the expected scenario. Procedure for iSCSI connection:
- Add Software iSCSI Adapter (not required if it has already been added, or if you are using the Hardware iSCSI Adapter);
- Creating a vSwitch through which iSCSI traffic will pass, and adding physical uplink and VMkernal to it;
- Adding array addresses to Dynamic Discovery;
- Creating a datastore
Some important notes:
- In the general case, of course, you can use an existing vSwitch, but in the case of a separate vSwitch, managing host settings will be much easier.
- It is necessary to separate Management traffic and iSCSI on separate physical links and / or VLAN in order to avoid performance problems.
- The IP addresses of the VMkernal and the corresponding ports of the All Flash array must be located within the same subnet, again due to performance issues.
- To ensure fault tolerance by VMware rules, a vSwitch must have at least two physical uplink
- If Jumbo Frames are used, you need to change the MTU of both the vSwitch and VMkernal
- It would not be superfluous to recall that, according to the recommendations of VMware, for physical adapters that will be used to work with iSCSI traffic, it is imperative that you configure Teaming and Failover. In particular, each VMkernal should work only through one uplink, the second uplink must be switched to unused mode. For fault tolerance, you need to add two VMkernal, each of which will work through its uplink.
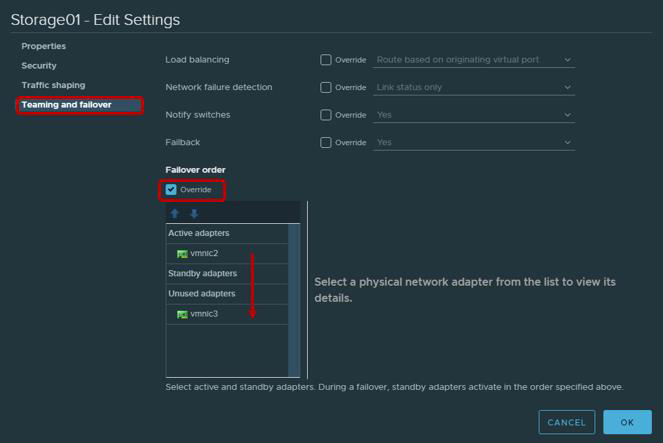
| VMkernel Adapter (vmk #) | Physical Network Adapter (vmnic #) |
|---|---|
| vmk1 (Storage01) | Active adapters vmnic2 Unused adapters vmnic3 |
| vmk2 (Storage02) | Active adapters vmnic3 Unused adapters vmnic2 |
No preliminary action is required to connect via Fiber Channel. You can immediately create a datastore.
After creating the Datastore, you need to make sure that the Round Robin policy is used for the Target / LUN paths as the most efficient.
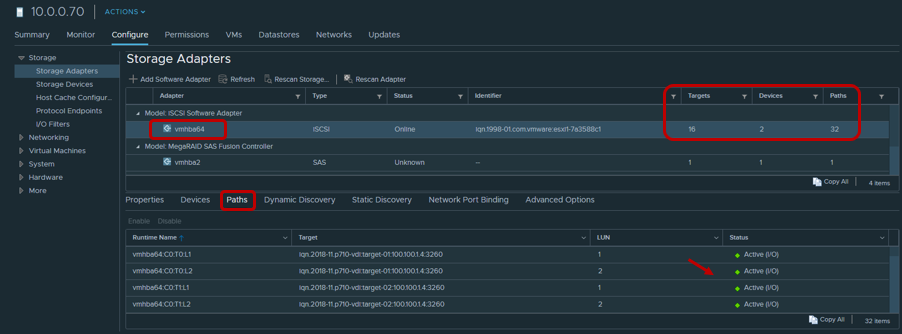
By default, VMware settings use this policy according to the following scheme: 1000 requests through the first path, the next 1000 requests through the second path, etc. Such a host interaction with a dual-controller array will be unbalanced. Therefore, we recommend setting the Round Robin parameter = 1 through Esxcli / PowerCLI.
For Esxcli:
- Print available LUNs
esxcli storage nmp device list
- Copy Device Name
- Modify Round Robin Policy
esxcli storage nmp psp roundrobin deviceconfig set - type = iops - iops = 1 - device = "Device_ID"
Most modern applications are designed to exchange large data packets in order to maximize bandwidth utilization and reduce the load on the CPU. Therefore, by default, ESXi transmits I / O requests to the storage device in batches up to 32767KB. However, for a number of scenarios, the exchange of smaller portions will be more productive. For AccelStor arrays, these are the following scenarios:
- Virtual machine uses UEFI instead of Legacy BIOS
- Used by vSphere Replication
For such scenarios, it is recommended to change the value of the Disk.DiskMaxIOSize parameter to 4096.
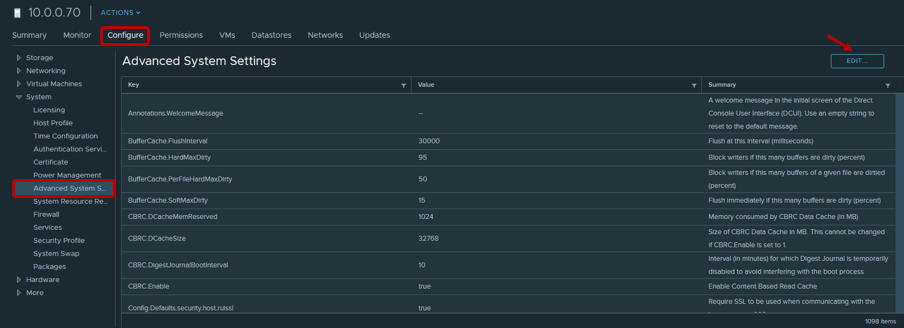
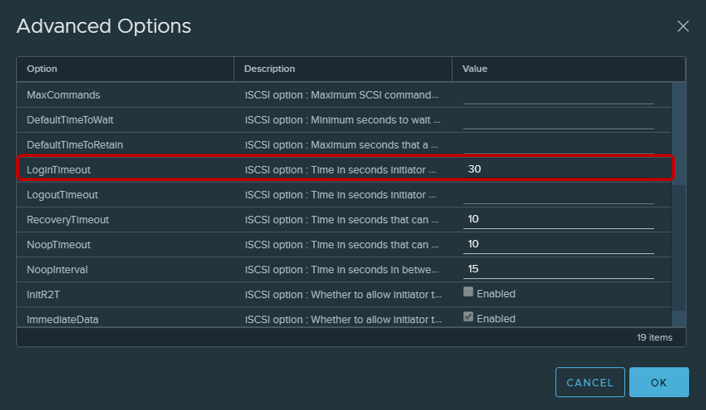
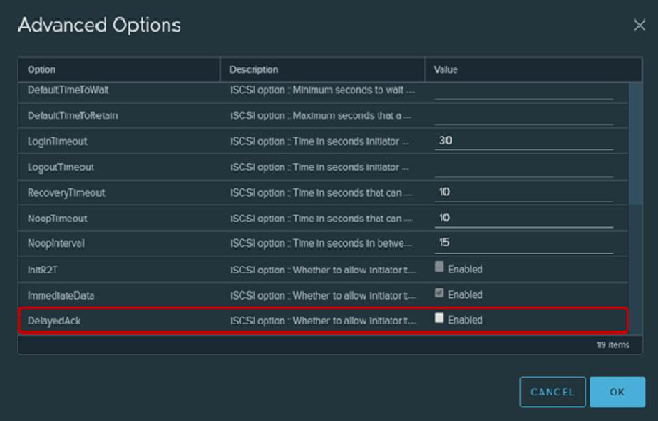
For iSCSI connections, it is recommended to change the Login Timeout parameter to 30 (default 5) to increase the stability of the connection and turn off the delay of confirmations of sent packets DelayedAck. Both options are located in vSphere Client: Host → Configure → Storage → Storage Adapters → Advanced Options for iSCSI adapter
A rather subtle point is the number of volumes used for the datastore. It is clear that for ease of management there is a desire to create one large volume for the entire volume of the array. However, the presence of several volumes and, accordingly, the datastore has a beneficial effect on the overall performance (more about the queues in the text below). Therefore, we recommend creating at least two volumes.
More recently, VMware advised to limit the number of virtual machines on one datastore, again in order to get the highest possible performance. However, now, especially with the spread of VDI, this problem is no longer so acute. But this does not negate the old rule - to distribute virtual machines that require intensive IO, according to different datastore. To determine the optimal number of virtual machines for one volume, there is nothing better than to conduct load testing of All Flash AccelStor array within its infrastructure.
Configure Virtual Machines
When configuring virtual machines there are no special requirements, or rather, they are quite ordinary:
- Using the highest possible version of VM (compatibility)
- It is more accurate to set the size of the RAM when the virtual machines are densely located, for example, in VDI (because by default, when starting, a paging file of a size comparable to the RAM is created, which consumes the useful capacity and has an effect on the final performance)
- Use the most productive for IO versions of adapters: network type VMXNET 3 and SCSI type PVSCSI
- Use Thick Provision Eager Zeroed Disk Type for Maximum Performance and Thin Provisioning for the most efficient use of storage space.
- If possible, limit the work of non-I / O machines using Virtual Disk Limit
- Be sure to install VMware Tools
Queue Notes
A queue (or Outstanding I / Os) is the number of I / O requests (SCSI commands) that are waiting to be processed at a time by a specific device / application. In the event of a queue overflow, an QFULL error is issued, which ultimately results in an increase in the latency parameter. When using disk (spindle) storage systems, theoretically, the higher the queue, the higher their performance. However, you should not abuse it because it is easy to run into QFULL. In the case of All Flash systems, on the one hand, everything is somewhat simpler: after all, the array has a delay of orders of magnitude lower, and therefore, more often than not, the size of the queues is not required to be separately controlled. But on the other hand, in some usage scenarios (a strong imbalance in the IO requirements for specific virtual machines, tests for maximum performance, etc.) is required if you do not change the queue parameters, then at least understand what indicators can be achieved, and, most importantly, in what ways.
There is no limit on the All Flash array AccelStor in relation to the volumes or I / O ports. If necessary, even a single volume can get all the resources of the array. The only limit on queues is at iSCSI targets. It is for this reason that the above indicated the need to create several (ideally up to 8 pcs.) Targets for each volume in order to overcome this limit. We also repeat that AccelStor arrays are very productive solutions. Therefore, all system interface ports should be used to achieve maximum speed.
On the ESXi host side, the situation is completely different. The host itself applies the practice of equal access to resources for all participants. Therefore, there are separate IO queues for the guest OS and HBA. Queues to the guest OS are combined from the queues to the virtual SCSI adapter and virtual disk:
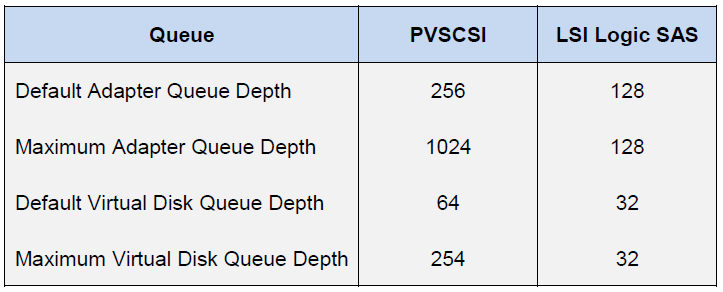
Queue to HBA depends on the specific type / vendor:
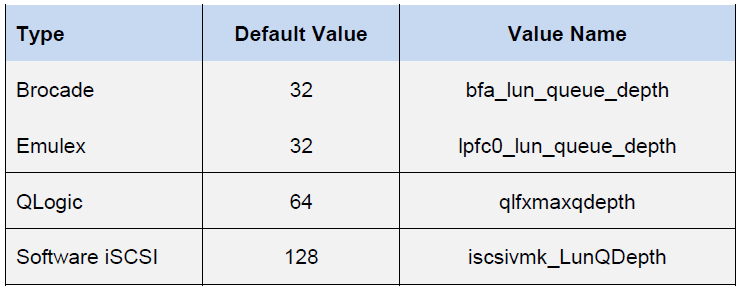
The final performance of the virtual machine will be determined by the lowest Queue Depth limit value among the host components.
Thanks to these values, you can estimate the performance indicators that we can get in one configuration or another. For example, we want to know the theoretical performance of the virtual machine (without blocking) with latency 0.5ms. Then its IOPS = (1,000 / latency) * Outstanding I / Os (Queue Depth limit)
Example 1
- FC Emulex HBA Adapter
- One VM on datastore
- VMware Paravirtual SCSI Adapter
Here the Queue Depth limit is defined by the Emulex HBA. Therefore, IOPS = (1000 / 0.5) * 32 = 64K
Example 2
- VMware iSCSI Software Adapter
- One VM on datastore
- VMware Paravirtual SCSI Adapter
Here, the Queue Depth limit is already defined by the Paravirtual SCSI Adapter. Therefore, IOPS = (1000 / 0.5) * 64 = 128K
The top All Flash models of AccelStor arrays (for example, P710 ) are capable of providing 700K IOPS per write performance with a 4K block. With this block size, it is clear that a single virtual machine is not able to load such an array. To do this, we need 11 (for example 1) or 6 (for example 2) virtual machines.
As a result, if all the components of the virtual data center are correctly configured, you can get very impressive results in terms of performance.

4K Random, 70% Read / 30% Write
In fact, the real world is much more difficult to describe with a simple formula. Multiple virtual machines with different configurations and IO requirements are always located on the same host. And the I / O processing is handled by a host processor, whose power is not infinite. So, to unlock the full potential of the same model P710 in reality, you will need from three hosts. Plus, applications running inside virtual machines make their own adjustments. Therefore, for accurate sizing, we suggest using the test in the case of All Flash test models of AccelStor arrays inside the customer's infrastructure for real-life tasks.
')
Source: https://habr.com/ru/post/447390/
All Articles