Professional deformation date of scientists

“If you have a hammer in your hands, everything seems to be nails”
As dateologists, we are engaged in data analysis, their collection, cleaning, enrichment, we build and train models of the surrounding world, based on data, we find internal relationships and contradictions between the data, sometimes even where they are not. Of course, such immersion could not but affect our vision and understanding of the world. Professional deformation is present in our profession just as in any other, but what exactly does it bring to us and how does it affect our life?
Disclaimer
This article does not pretend to be scientific, does not express a unified point of view of the ODS community and is the personal opinion of the author.
Preamble

If you are interested in how our brain works, how we perceive the world around us, and in general, what we are doing here, then many of the things described in this article will not be something completely new for you. In one form or another, all this has already been described more than once at completely different angles. My task is to try to look at all this from the perspective of data analytics, and also to draw parallels between the tools and approaches that we use in our work and real life outside the monitor.
Introduction

To begin with, let us imagine such a somewhat simplified setup:
There is the world around us in order to survive and function successfully in it, a person needs to understand what he (the world) is of, how to interact with it, and what results are obtained from various interactions. That is, in other words, a person needs a model of the surrounding world that adequately solves his current tasks . The key is “ current tasks ”. When the task of survival was in the first place, the model of the world was built, first of all, on a quick recognition of the danger and an adequate response to it. That is, who has the worse model - could not pass it on, who better - passed it on to descendants. With the improvement of living conditions, the emphasis in the model began to change from purely survival to something more highly organized, and the safer the environment, the more diverse this “something” becomes. The range of “something” is very wide - from bitcoin and DS to radical feminism and tolerance.
Nature created our brain to solve the problem of survival in conditions of limited resources - there was little food, energy for all garbage was not enough, therefore, in order to survive, it was necessary to solve two mutually exclusive tasks:
- Explore the world, improving the model, increasing the chances of survival (a very energy-intensive task)
- Do not die of lack of energy
Nature solved this dilemma very elegantly by introducing into our brain the possibility of caching data streams and reactions, when energy is practically not wasted to solve basic problems (within the framework of the current model) of interaction with the outside world.
For more information about this caching method and the “resource theory of attention” can be found in D. Kahneman’s excellent works “ Think slowly, solve quickly ” [1] and “ Attention and effort ” [3]
')
According to D. Kahneman:
Psychologists distinguish two modes of thinking, which we will call System 1 and System 2.
System 1 operates automatically and very quickly, without requiring or almost without requiring effort and without giving a feeling of intentional control.
System 2 highlights the attention needed for conscious mental effort, including for complex calculations. The actions of System 2 are often associated with a subjective sense of activity, choice and concentration.
Patterns of behavior, reactions and responses are programmed in our brain (form and change the model of the world) from childhood to death. Two factors depend on what stage the formation of the model is in - the rate at which changes are accepted and the amount of energy needed to change. In childhood, when the model is flexible and malleable, the speed is high and the energy costs are minimal. The denser the model, the more energy is needed to change it. Even more than that, energy is also needed so that a person just wants to change something in the model . And any waste of energy is controlled by the brain, and he sooooo reluctantly allows her to spend.
The command to change the model will be rejected by the brain (still, it’s energy-consuming, but why ?, because we are doing so well) as long as the functioning within the framework of the old model does not threaten survival. Well, or before energy is produced by a spontaneous splash (shock from something, a psychological blow, etc.)
TL / DR:
- For survival, a person builds in his head a model of the surrounding world that solves his current tasks.
- When solving any problem, the brain tries to minimize energy consumption.
- The least energy-consuming functioning within the System-1 (Kaneman), the failure to make decisions on change
- The most energy-consuming - functioning within the System-2, the decision to change the model itself change the model
Metamodel (model model)

So, in order to interact with the outside world, a person builds a model of the world in his brain and acts in accordance with it as long as possible (recall once again about minimizing energy costs). But a person, unfortunately or fortunately, is a social animal - we cannot not interact with other people and, often, this interaction puts us at a dead end.
In order to effectively interact with other people, we build in our heads a behavioral model of these people , that is, a model of how they will behave in certain circumstances if there are certain data. That is, we are building a model model of the surrounding world of this particular person.
Stop and think - the model of the world in a person’s head is imperfect and meets only its own criteria of sufficiency and adequacy , and we build a model of this (strange) model and interact with this person according to our model. Yes, and we also want a person to act as our “model of his model” suggests . Optimistic? Yes, more than ...
To build and train an adequate model, not for me to tell you, you need a lot of time, energy and data. And we often have neither one nor the other, and the more degrees of freedom (parameters) a model has, the more data is needed - a curse of dimension, remember?
And life flies, but time is short, therefore (System 1 works), meeting a person, and even communicating with him in some conditions, we select to him one of our pre-compiled model templates that we already have in head (“bitch”, “normal kid”, “rohlja”, “just“ №; ak ”, etc.), maybe a little bit of it for a specific case.
Yes, of course, there are exceptions, there are people for whom we don’t feel sorry for neither time nor energy, and whom we have known all our life. But in this case, we know about a person only what is in our model of this person.
What follows from this? Some obvious things:
Well, first of all , the date of the scientist does not feel resentment towards other people .
Completely from the word completely. In his vocabulary, the term “offense” is absent. Why? It's simple - at the heart of any insult is our misunderstanding:
- How could he (she) do that (say, do, do)?
- Or NOT (say, do, do)?
That is, in our model of this person, he in specific circumstances with a specific input packet of information had to do so, and he did not do so. That bastard, huh? Yeah, he is not a reptile, and our model of this person is wrong. We missed something in it, or we were not fanatically altogether for specific circumstances, but took just a template, or the input data in the current situation is different from those on which we trained the model.
What to do in this case? Same as usual - we look at what is wrong in the data and overtrain the model taking into account the new information.
Secondly , the date of the scientist is missing a reflex “ someone is wrong on the Internet .”
It works not only on the Internet, but also at work, in society, etc. If a person does not understand something (as you think), or understands it, but not in the way you do - perhaps he is just a completely different model for this part of the world . And to convince this, that is, Making him change his model, (especially if he does not want to) is very difficult and very energy-consuming. Do you need it?
A completely different option is when a person is ready to change his model, wants to expand it or podtyunit, and he has the strength and energy for this. Can you help - help, can not - direct to who can. You can neither help nor direct - do not interfere .
Next time, do not aggretize a person if, in your opinion, he is “wrong” or “does not understand” something. In his model of the world, everything is different. The harder and “simpler” the model, the more energy is needed to at least take it out of the equilibrium point , not to mention changing something.
And thirdly , the date of the scientist remembers the principle “ Things are always not what they seem .”
Understanding how this system works, it is possible to mix, tune out to some basic pattern that is familiar to the society in which you are currently located, and until you get out of it, everything will be fine. It works both ways, so don't forget - “ Owl is not what it seems .”
“The perception of a rope as a snake is as false as the perception of a rope as a rope” (C)
Model building and training

As a date for Scientists, we are well aware of how difficult it is to build, train and constantly pre-train a more or less adequate model. And so the date of the scientist calmly and patiently refers to the imperfection of models in the heads of other people and is constantly improving his own . And since he is still a professional, he perfectly remembers the basic principles of successful modeling:
You reap what you sow (Garbage in - garbage out.)
The accuracy and adequacy of the model depends on the purity of the data more than anything else. We all know this, we spend an enormous amount of time on data cleaning, preprocessing, normalization, and so on and so forth. Feed the model with garbage - and the result is predictable. Feed it with cleared normalized data - and insights in your pocket. Models in our heads work the same way. Understanding this, we try to use the most accurate and clean data for processing and training, we constantly use a critical eye to analyze the adequacy of the data and strive to prevent dirty and noisy information in our model . In short - read Habr and do not watch the first channel.
Difference between Train and Test (our headache)
Date scientist understands that the applicability of the model is directly dependent on the similarity of distributions on which the model was studied and for which it is applied . The rules of behavior in one society do not work in another, the principles of success in one area are inapplicable to another, the “typical model of behavior” of the opposite sex based on my mother's stories suddenly turns out to be not quite right, and so on.
We always take into account the possible dissimilarity of the training dataset, on which we trained our model of the world, and the real dataset, on which we apply our model.
In short, we understand the cause of the discrepancy and are willing to spend energy on the pre-training model to more accurately match the real world.
Choice of objective function and multidomain-learning
Virtually any task can be transferred to another domain by changing the objective function. Do not solve the problem as regression? Redo target classes and solve as a classification task. And even better - make two heads at the grid, one is to solve one problem, the second is reformulated. Two different models can be trained on completely different things on the same data set. Remember this, the best option, as in life, multidomain-learning, when your final objective function covers several domains at once . At work, for example, you can simply earn money, while still having a chance to download professional skills, you can still improve your social interaction skills. As is the case with conventional models, this approach allows us, in the end, to enrich and improve all multi-domain targets, as if we were downloading them separately. And do not forget about time - three models for individual goals require three times more time, but in real life it is not that much , and parallelize training for a dozen or so TPU-nis, unfortunately, will not work.
Batch-learning
Training the model in batches proved its effectiveness long ago. If you do not take into account the specific areas that require online training, then it makes no sense to update the weight only after the passage of the entire era. Yes, batch training gives high-frequency noise, but this is leveled by a higher convergence rate with almost the same accuracy.
What does this give us? Understanding that it makes no sense to wait long before slightly changing your model of the world on the basis of new data. You do not have to wait for the whole epoch, well, I don’t know, a year at a new job, a year of relations with a new person, change more often - get a faster movement to your final goal , well, exploration will provide more opportunities. It also makes no sense to shout that “everything is gone” after some single incident , perhaps it’s just an outburst, it’s possible that the stars were like that, wait until the end of the batch, accumulate errors, and then change the model.
Hyperparameters search methods (Grid search VS random search)
There are many articles ( example ) on the fact that when searching for the best hyperparameters, iteration is randomly better than the search on the grid. So in our case, the choice of “random” action is better to do “pseudo random”, and not strictly in accordance with any predetermined grid . Fans and adherents of strict approaches will now trample me, but seriously, the world is ruled by chance , and the use of such a method, oddly enough, may be even more rational.
Better yet, of course, use Bayesian optimization . But here I have no idea how it can be applied to real life. Not the Bayesian approach to comprehending information, but Bayesian optimization when choosing hyper parameters.
Ensemble
We all know about the power of ensembles, in which each model looks at the data in its own way, pulling some signal out of them, and the best result is achieved by using the metamodel on top of the first level models. In life, everything is exactly the same; you can build your own model of the world not only on the basis of your own experience, but also by absorbing all the best (or vice versa, understanding and cutting off all the worst) from other people's models of the world. These models are described in books, films, and just by watching the behavior of other people, you can understand what kind of model they have, take the best and embed yourself.
Let us recall “Many things are incomprehensible to us not because our concepts are weak, but because these things are not included in the circle of our concepts.” Kozma Petrovich understood the problem of limited models, even without being a date scientist. :)
Different people, different environments, different data - different models, even for seemingly obvious things. If you worked in large companies, you probably remember all these endless trainings about behavior, rules of communication, harassment, and so on. What the fuck, you thought. But no, not bullshit. In large international companies (due to differences in culture, mentality and values) it is simply necessary to introduce a layer of basic principles into the model of each employee to ensure normal interaction and work.
Tl / dr
- Only you and your model of the world are to blame for what happens to you in this world.
- Other people's models of the world are not at all obliged to correlate with your own
- Your meta-models of other people's models of the world most likely do not correspond to reality at all.
- It is difficult to create an open model of the world in my head, ready to change on the Bayesian principle. It is even more difficult to maintain it in this open state throughout life. It’s quite difficult to remain a person.
What's left overs
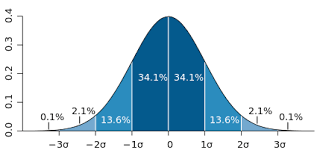
Central limit theorem
As the CPT says, the sum of random events sampled from any type of weakly dependent distributions is itself a random variable and is normally distributed in the limit.
Our whole life consists of random events : the waiting time of the elevator or bus at the bus stop, missed you at the turn or not, etc. You can conditionally evaluate the day as successful or unsuccessful (another random variable), depending on whether we hit the final distribution - in the center or in the tail. On a fairly large sample (for example, year) it is clear that this random variable of ours is distributed normally, with the center at “ well, well, more or less everything is OK ”
Date scientist understands all of the above and does not soar, if it falls into the so-called. “Black bar” , when everything is bad - and the bus went out from under your nose, and spilled coffee, and did not save the code, etc. He understands that today we have the tail of the distribution, we just have to go through this day , and tomorrow, perhaps, the world will see us a little differently.
By the way, the transition to a new reference point of events (a new set of samples) is a dream . Not a calendar day, not midnight, but a subjective new day after you woke up. Our ancestors understood this intuitively (although they didn’t know about xgboost and keras), it was from here that the sayings “ wiser than morning ” and “ if you want to work, go sleep and everything will go ” went .
And the logical conclusion is that if the “black bar” lasts too long (you can even try to calculate the p-value of this “too”), then this means that some values in our life equation are shifted (the bus was removed from the route, you there was a morning hand shake), or an external influence on the system is carried out.
Regression to average
Let us recall the kind word of Sir Francis Galton , who first drew attention to this phenomenon in his work “ Regression to the average in inheritance ”. Also this topic is well covered in the already mentioned beautiful book by D. Kahneman [1].
As a date for Scientists, we do not pay attention if today something is worse than yesterday . We remember the regression to the average and relate to today's failure philosophically, especially since today's failure increases the likelihood of our success tomorrow , again in accordance with the same law)
Well, and again, this law has long been reformulated in a more familiar form, “ if things are going well, then soon they will go even worse .”
Use and exploration (Exploitation vs Exploration)
As already mentioned, our brain seeks to minimize energy costs, this is due to the priority of survival and procreation. Initially, the energy was not enough to survive, it had to be saved, and the brain for such a long evolution impressed the principle of Uncle Occam on his basic firmware - “it works — don't touch! ". You do not need to spend energy on building a new model of the world, if everything that happens around is quite explicable within the framework of the current, and you do not need to look for something new, if, in principle, everything is more or less good.
But we are programs ... date Scientists. We well know what a jam is at a local minimum. The complexity of the surface of the optimization function of our life does not lend itself to understanding and description (although many consciously simplify it to facilitate existence), and the new best local minimum can be right around the corner, side by side, in one or two simple actions. But we continue to sit in a non-optimum, saying, “ Well, I know that nothing will change .” We cannot know anything like this due to, as already mentioned, the complexity of the landscape of the objective function. You just need to stop thinking and start jumping . You won’t believe how differently your life can go if you periodically go out of your local minimum and try to twitch in different directions.
As an illustration, the problem of getting stuck in the “local minimum” for RL ( Reinforcement learning ) can be given. Using the greedy algorithm for selecting actions in each state, we, of course, ultimately optimize our reward, but leave behind other, possibly more interesting, areas of the surrounding space. Therefore, we bring to the algorithm the possibility of choosing not the best, but the random action from this particular situation, just to see if this will lead us to something new and, possibly, better . For the RL task with an infinite number of launches, sooner or later we will consider all possible states and rewards and choose the maximum one. Unfortunately, in real life we have a limited number of attempts (and the time of the experiment is also of course) , but the more interesting the task is, it means that instead of just a random choice of action, you can come up with some more sophisticated algorithms.
The bubble of interests , by the way, as well as personalized tapes, search results and other things are also harmful because they cut off the possibilities for exploration , closing the information flow into the sphere of already studied content.
Sample from the general population
We understand that all our evaluative judgments about people, events, things are not built on the entire population , but only on a certain sample available to us for observation. Giving ourselves this report, we very neatly hang labels like “ all men are artiodactyls ” or “ all women are blondes ”.
We also remember that even with a normal sample, the probability of falling into the “tail” of the distribution is far from zero . And, if this happens, we do not get upset, do not reflect on the topic “why am I again”, but learn a lesson and calmly move on.
As already mentioned, if suddenly your sample of something (people, events, ..) suddenly began to consist of one “tails”, then this is an occasion to reflect on the fact that in your own model of the world it suddenly changed, that the world began to react in a similar way. .
Cognitive distortion
We are all in some way still people, and our brain is subject to all possible cognitive distortions caused by the work of System-1. Fundamental attribution error , retrospective distortion , framing , survivor systematic error , etc., etc. These and many other veils all affect us. But as a date scientists, we always remember about these traps and constantly try to separate ourselves from them, straining System-2. Understanding the nature of distortions and methods of detuning from them helps us in our work and in real life. Yes, it's hard, there is little energy on System-2, but the muscle grows only when you strain it.
“After this does not mean as a consequence of this” and other logical errors
Again, as in the case of cognitive distortions , we are aware of these logical errors , remember them and try to develop our System-1 so that bypassing such traps occurs automatically.
Map is not equal to the territory
We all remember that “All models are wrong, but some are useful” (C). This also applies to our models of the world. As a date for Scientists, we are aware of their imperfections , realizing that they are only a faded reflection of the real world, but, nevertheless, a very useful reflection. , , , , , , , .
TL/DR
- ,
- . ,
- (exploration)
- , . , - , 1
Conclusion

, - , , , , , .
Bibliography
- . … . — .: , 2013. — 625 .
- ., ., . : ., : , 2005. — 632 . — [ISBN 966-8324-14-5]
- . / . . . . . — .: , 2006. — 288 .
- . , “ : "
Source: https://habr.com/ru/post/447362/
All Articles