Why and how we hide the license plates of cars in Avito ads
Hey. At the end of last year, we began to automatically hide the numbers of cars in the photos in the announcement cards on Avito. About why we did it, and what are the ways to solve such problems, read the article.

In 2018, Avito sold 2.5 million cars. It is almost 7,000 per day. All ads for sale need an illustration - a photo of the car. But according to the state number on it you can find a lot of additional information about the car. And some of our users try to close the state number on their own.
The reasons why users want to hide the license plate may be different. For our part, we want to help them protect their data. And we try to improve the processes of sale and purchase for users. For example, we have an anonymous number service for a long time: when you sell a car, a temporary mobile number is created for you. Well, to protect the data on state numbers, we depersonalize the photos.

')
To automate the process of protecting user photos, you can use convolutional neural networks to detect a polygon with a license plate.
Now for the detection of objects, architectures of two groups are used: two-stage networks, for example, Faster RCNN and Mask RCNN; single-stage (singleshot) - SSD, YOLO, RetinaNet. Object detection is the output of the four coordinates of the rectangle in which the object of interest is inscribed.
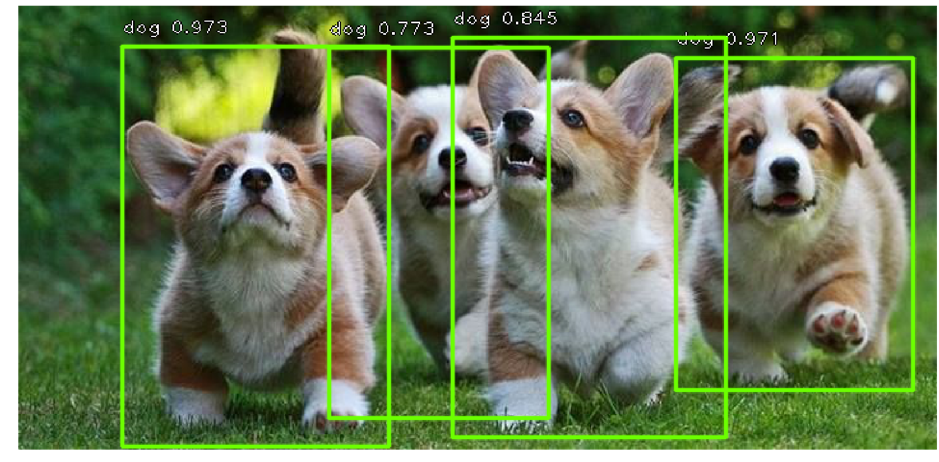
The networks mentioned above are able to find in the pictures a lot of objects of different classes, which is already redundant to solve the problem of finding a license plate, because the car in our pictures is usually only one (there are exceptions when people take pictures of their sold car and its random neighbor , but this happens quite rarely, so this could be neglected).
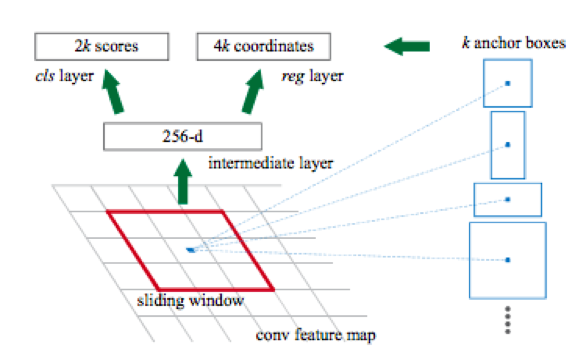
Another feature of these networks is that by default they provide a bounding box with sides parallel to the axes of coordinates. This is because the detection uses a set of pre-defined kinds of rectangular frames called anchor boxes. More specifically, first, using a convolutional network (for example, resnet34), a matrix of features is obtained from the image. Then, for each subset of features obtained using a sliding window, a classification occurs: whether or not there is an object for the k anchor box and a regression is performed in the four coordinates of the frame, which correct its position.
Read more about this here .
After that there are two more heads:
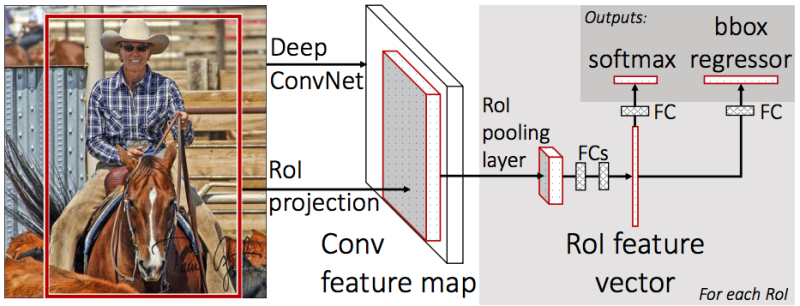
one to classify an object (dog / cat / plant, etc),
the second (bbox regressor) is used to regress the coordinates of the frame obtained in the previous step in order to increase the ratio of the object area to the area of the frame.
In order to predict the rotated frame of the box, you need to change the bbox regressor so that you also get the angle of rotation of the frame. If you do not do this, then it will turn out somehow.

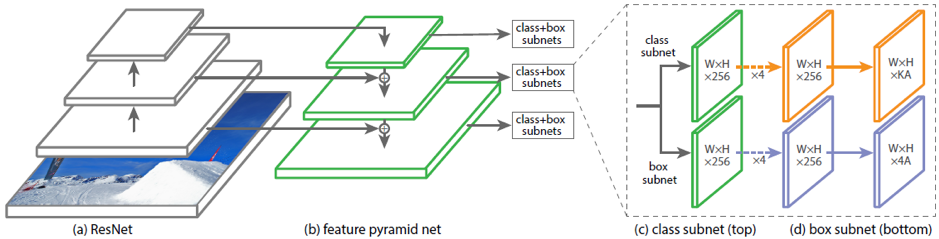
In addition to the two-stage Faster R-CNN, there are one-stage detectors, such as RetinaNet. It differs from the previous architecture in that it immediately predicts the class and the frame, without the preliminary stage of the proposal of sections of the picture, which may contain objects. In order to predict rotated masks, you also need to change the box subnet head.
One example of existing architectures for predicting rotated bounding boxes is DRBOX. This network does not use the preliminary stage of the region proposal, as in Faster RCNN, therefore it is a modification of one-step methods. For training this network, K rotated at certain corners of the bounding box (rbox) is used. The network predicts the probabilities for each of K rbox to contain the target object, coordinates, bbox size and rotation angle.

To modify the architecture and re-train one of the considered networks on data with rotated bounding boxes is a realizable task. But our goal can be achieved more easily, because the area of application of the network is much narrower here - only to hide license plates.
Therefore, we decided to start with a simple network to predict the four points of the number; later it will be possible to complicate the architecture.
The assembly of the dataset is divided into two steps: to collect pictures of cars and to mark on them an area with a license plate. The first task has already been solved in our infrastructure: we keep all ads that have ever been placed on Avito. To solve the second problem, we use Toloka. On toloka.yandex.ru/requester we create the task:

With the help of Toloki, you can create data marking tasks. For example, assess the quality of search results, mark up different classes of objects (texts and pictures), mark up videos, etc. They will be performed by Toloki users, for a fee that you assign. For example, in our case, the pushers should highlight the landfill with the car's license number in the photo. In general, it is very convenient for marking a large dataset, but getting high quality is quite difficult. On a fair lot of bots, whose task is to get money from you, instructing answers randomly or using some strategy. To counteract these bots there is a system of rules and checks. The main test is to add test questions: you manually mark up part of the tasks using the Toloki interface, and then add them to the main task. If the tagging is often mistaken on the control questions, you block it and the markup does not take into account.
For the classification task it is very easy to determine whether the marking is wrong or not, and for the task of selecting an area it is not so easy. The classic way is to count IoU.
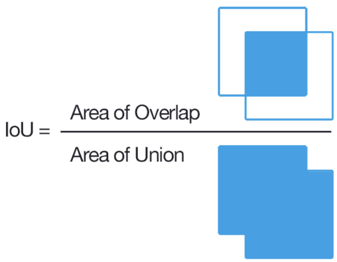
If this ratio is less than a certain threshold for several tasks, then that user is blocked. However, for two arbitrary quadrilaterals, it is not so easy to calculate IoU, especially since Toloka has to implement this in JavaScript. We made a small hack, and we believe that the user was not mistaken if for each point of the source polygon in a small neighborhood there is a point marked by a razmechchik. There is also a rule of quick answers, so that responding users, captcha, disagreement with the majority opinion, etc., are blocked too quickly. Having set up these rules, you can expect pretty good markup, but if you really need high quality and complex markup, you need to hire freelancers-markers specifically. As a result, our dataset was 4k of marked-up pictures, and it all cost $ 28 on Toloka.
Now we will make a network for predicting four points of the area. We will get the signs using resnet18 (11.7M parameters versus 21.8M parameters for resnet34), then we make a head for the regression of four points (eight coordinates) and a head for classifying whether there is a license plate in the picture or not. The second head is needed, because in ads for the sale of cars, not all photos with cars. The photo may be a detail of the car.

Similar to us, of course, it is not necessary to detect.
We are training two goals at the same time by adding a photo without a license plate with a bounding box target (0.0,0,0,0,0,0,0,0) and a value for the “license plate / without picture” classifier - (0, one).
Then you can create a single loss function for both heads as the sum of the next losses. For regression to the coordinates of the polygon license plate using a smooth L1 loss.
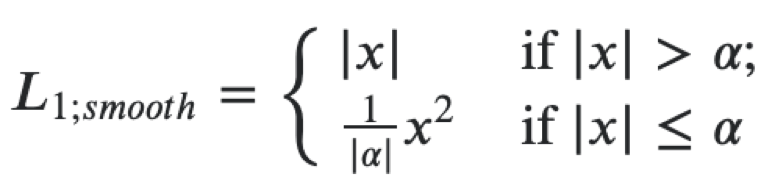
It can be interpreted as a combination of L1 and L2, which behaves like L1 when the absolute value of the argument is large and like L2 when the value of the argument is close to zero. For classification use softmax and crossentropy loss. The tracer extractor is resnet18, we use weights that were pre-trained on ImageNet, then we continue to train the extractor and heads on our dataset. In this task, we used the mxnet framework, since it is the main one for computer vision in Avito. In general, the microservice architecture allows you not to become attached to a specific framework, but when you have a large code base, it is better to use it and not to write the same code again.
Having received acceptable quality on our dataset, we turned to the designers to make us a license plate with the Avito logo. At first, of course, we tried to do it ourselves, but it didn’t look very beautiful. Next you need to change the brightness of the Avito license plate to the brightness of the original area with the license plate and you can impose a logo on the image.

The problem of reproducibility of results, support and development of projects, solved with some error in the world of backend- and frontend-development, still stands open where it is necessary to use machine learning models. You probably had to understand the Legacy code models. Well, if the readme has links to articles or open source repositories on which the solution was based. The script to start retraining may fall with errors, for example, the version of cudnn has changed, and that version of tensorflow no longer works with this version of cudnn, and cudnn does not work with this version of nvidia drivers. Maybe one data iterator was used for training, and another was used for testing and production. So you can continue for quite some time. In general, reproducibility problems exist.
We try to remove them using the nvidia-docker environment for training models, it has all the necessary dependencies for the suda, and we also install dependencies for the python there. A version of the library with an iterator for data, augmentations, model inflection is common for the training / experimentation stage and for production. Thus, in order to train a model on new data, you need to download the repository to the server, run a shell script that will collect the docker-environment, inside which jupyter notebook will rise. Inside you will have all the notebooks for training and testing, which will not fall with an error due to the environment. It’s better, of course, to have one train.py file, but practice shows that you always need to look at what modelka gives and change something in the learning process, so in the end you still run jupyter.
Model weights are stored in git lfs - this is a special technology for storing large files in the gita. Before that, we used the artifactory, but through git lfs it is more convenient because by downloading the repository with the service, you immediately get the current version of the scales, as in production. For the inference of models, autotests are written, so it’s not possible to roll out the service with weights that do not pass them. The service itself is launched at the docker inside the microservice infrastructure on the kubernetes cluster. For performance monitoring, we use grafana. After rolling, we gradually increase the load on the service instances with the new model. When rolling out a new feature, we create a / b tests and make a verdict on the further fate of the feature, based on statistical tests.
As a result: we launched a smearing of numbers on ads in the category of cars for private traders, 95 percentile of the processing time of one image to hide the number is 250 ms.
Task
In 2018, Avito sold 2.5 million cars. It is almost 7,000 per day. All ads for sale need an illustration - a photo of the car. But according to the state number on it you can find a lot of additional information about the car. And some of our users try to close the state number on their own.
 |  |
 |  |
 | |
The reasons why users want to hide the license plate may be different. For our part, we want to help them protect their data. And we try to improve the processes of sale and purchase for users. For example, we have an anonymous number service for a long time: when you sell a car, a temporary mobile number is created for you. Well, to protect the data on state numbers, we depersonalize the photos.
')
Review of solutions
To automate the process of protecting user photos, you can use convolutional neural networks to detect a polygon with a license plate.
Now for the detection of objects, architectures of two groups are used: two-stage networks, for example, Faster RCNN and Mask RCNN; single-stage (singleshot) - SSD, YOLO, RetinaNet. Object detection is the output of the four coordinates of the rectangle in which the object of interest is inscribed.
The networks mentioned above are able to find in the pictures a lot of objects of different classes, which is already redundant to solve the problem of finding a license plate, because the car in our pictures is usually only one (there are exceptions when people take pictures of their sold car and its random neighbor , but this happens quite rarely, so this could be neglected).
Another feature of these networks is that by default they provide a bounding box with sides parallel to the axes of coordinates. This is because the detection uses a set of pre-defined kinds of rectangular frames called anchor boxes. More specifically, first, using a convolutional network (for example, resnet34), a matrix of features is obtained from the image. Then, for each subset of features obtained using a sliding window, a classification occurs: whether or not there is an object for the k anchor box and a regression is performed in the four coordinates of the frame, which correct its position.
Read more about this here .
After that there are two more heads:
one to classify an object (dog / cat / plant, etc),
the second (bbox regressor) is used to regress the coordinates of the frame obtained in the previous step in order to increase the ratio of the object area to the area of the frame.
In order to predict the rotated frame of the box, you need to change the bbox regressor so that you also get the angle of rotation of the frame. If you do not do this, then it will turn out somehow.
In addition to the two-stage Faster R-CNN, there are one-stage detectors, such as RetinaNet. It differs from the previous architecture in that it immediately predicts the class and the frame, without the preliminary stage of the proposal of sections of the picture, which may contain objects. In order to predict rotated masks, you also need to change the box subnet head.
One example of existing architectures for predicting rotated bounding boxes is DRBOX. This network does not use the preliminary stage of the region proposal, as in Faster RCNN, therefore it is a modification of one-step methods. For training this network, K rotated at certain corners of the bounding box (rbox) is used. The network predicts the probabilities for each of K rbox to contain the target object, coordinates, bbox size and rotation angle.
To modify the architecture and re-train one of the considered networks on data with rotated bounding boxes is a realizable task. But our goal can be achieved more easily, because the area of application of the network is much narrower here - only to hide license plates.
Therefore, we decided to start with a simple network to predict the four points of the number; later it will be possible to complicate the architecture.
Data
The assembly of the dataset is divided into two steps: to collect pictures of cars and to mark on them an area with a license plate. The first task has already been solved in our infrastructure: we keep all ads that have ever been placed on Avito. To solve the second problem, we use Toloka. On toloka.yandex.ru/requester we create the task:
In the task given photo of the car. It is necessary to highlight the license plate of the car, using a quadrilateral. In this case, the state number should be allocated as accurately as possible.
With the help of Toloki, you can create data marking tasks. For example, assess the quality of search results, mark up different classes of objects (texts and pictures), mark up videos, etc. They will be performed by Toloki users, for a fee that you assign. For example, in our case, the pushers should highlight the landfill with the car's license number in the photo. In general, it is very convenient for marking a large dataset, but getting high quality is quite difficult. On a fair lot of bots, whose task is to get money from you, instructing answers randomly or using some strategy. To counteract these bots there is a system of rules and checks. The main test is to add test questions: you manually mark up part of the tasks using the Toloki interface, and then add them to the main task. If the tagging is often mistaken on the control questions, you block it and the markup does not take into account.
For the classification task it is very easy to determine whether the marking is wrong or not, and for the task of selecting an area it is not so easy. The classic way is to count IoU.
If this ratio is less than a certain threshold for several tasks, then that user is blocked. However, for two arbitrary quadrilaterals, it is not so easy to calculate IoU, especially since Toloka has to implement this in JavaScript. We made a small hack, and we believe that the user was not mistaken if for each point of the source polygon in a small neighborhood there is a point marked by a razmechchik. There is also a rule of quick answers, so that responding users, captcha, disagreement with the majority opinion, etc., are blocked too quickly. Having set up these rules, you can expect pretty good markup, but if you really need high quality and complex markup, you need to hire freelancers-markers specifically. As a result, our dataset was 4k of marked-up pictures, and it all cost $ 28 on Toloka.
Model
Now we will make a network for predicting four points of the area. We will get the signs using resnet18 (11.7M parameters versus 21.8M parameters for resnet34), then we make a head for the regression of four points (eight coordinates) and a head for classifying whether there is a license plate in the picture or not. The second head is needed, because in ads for the sale of cars, not all photos with cars. The photo may be a detail of the car.
Similar to us, of course, it is not necessary to detect.
We are training two goals at the same time by adding a photo without a license plate with a bounding box target (0.0,0,0,0,0,0,0,0) and a value for the “license plate / without picture” classifier - (0, one).
Then you can create a single loss function for both heads as the sum of the next losses. For regression to the coordinates of the polygon license plate using a smooth L1 loss.
It can be interpreted as a combination of L1 and L2, which behaves like L1 when the absolute value of the argument is large and like L2 when the value of the argument is close to zero. For classification use softmax and crossentropy loss. The tracer extractor is resnet18, we use weights that were pre-trained on ImageNet, then we continue to train the extractor and heads on our dataset. In this task, we used the mxnet framework, since it is the main one for computer vision in Avito. In general, the microservice architecture allows you not to become attached to a specific framework, but when you have a large code base, it is better to use it and not to write the same code again.
Having received acceptable quality on our dataset, we turned to the designers to make us a license plate with the Avito logo. At first, of course, we tried to do it ourselves, but it didn’t look very beautiful. Next you need to change the brightness of the Avito license plate to the brightness of the original area with the license plate and you can impose a logo on the image.
Run in the prod
The problem of reproducibility of results, support and development of projects, solved with some error in the world of backend- and frontend-development, still stands open where it is necessary to use machine learning models. You probably had to understand the Legacy code models. Well, if the readme has links to articles or open source repositories on which the solution was based. The script to start retraining may fall with errors, for example, the version of cudnn has changed, and that version of tensorflow no longer works with this version of cudnn, and cudnn does not work with this version of nvidia drivers. Maybe one data iterator was used for training, and another was used for testing and production. So you can continue for quite some time. In general, reproducibility problems exist.
We try to remove them using the nvidia-docker environment for training models, it has all the necessary dependencies for the suda, and we also install dependencies for the python there. A version of the library with an iterator for data, augmentations, model inflection is common for the training / experimentation stage and for production. Thus, in order to train a model on new data, you need to download the repository to the server, run a shell script that will collect the docker-environment, inside which jupyter notebook will rise. Inside you will have all the notebooks for training and testing, which will not fall with an error due to the environment. It’s better, of course, to have one train.py file, but practice shows that you always need to look at what modelka gives and change something in the learning process, so in the end you still run jupyter.
Model weights are stored in git lfs - this is a special technology for storing large files in the gita. Before that, we used the artifactory, but through git lfs it is more convenient because by downloading the repository with the service, you immediately get the current version of the scales, as in production. For the inference of models, autotests are written, so it’s not possible to roll out the service with weights that do not pass them. The service itself is launched at the docker inside the microservice infrastructure on the kubernetes cluster. For performance monitoring, we use grafana. After rolling, we gradually increase the load on the service instances with the new model. When rolling out a new feature, we create a / b tests and make a verdict on the further fate of the feature, based on statistical tests.
As a result: we launched a smearing of numbers on ads in the category of cars for private traders, 95 percentile of the processing time of one image to hide the number is 250 ms.
Source: https://habr.com/ru/post/447286/
All Articles