Ignite Service Grid - reboot
On February 26, we held the Apache Ignite GreenSource mitap, where the open source distributors of the Apache Ignite project spoke. An important event in the life of this community was the restructuring of the Ignite Service Grid component, which allows you to deploy custom microservices right in the Ignite cluster. Vyacheslav Daradur , a senior Yandex developer and a contributor for Apache Ignite, has been talking about this difficult process at the mitap.
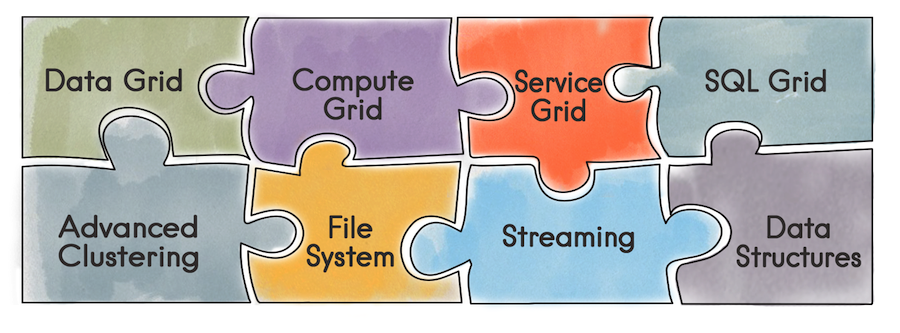
To begin with, what is Apache Ignite in general. This is a database that is a distributed Key / Value repository with support for SQL, transactional and caching. In addition, Ignite allows you to deploy custom services right in the Ignite cluster. All the tools that Ignite provides — distributed data structures, Messaging, Streaming, Compute, and Data Grid — are becoming available to the developer. For example, when using the Data Grid, the problem with the administration of a separate infrastructure for the data storage and, as a result, the overheads arising from this disappears.

')
Using the API Service Grid, you can finish the service by simply specifying the deployment scheme and, accordingly, the service itself in the configuration.
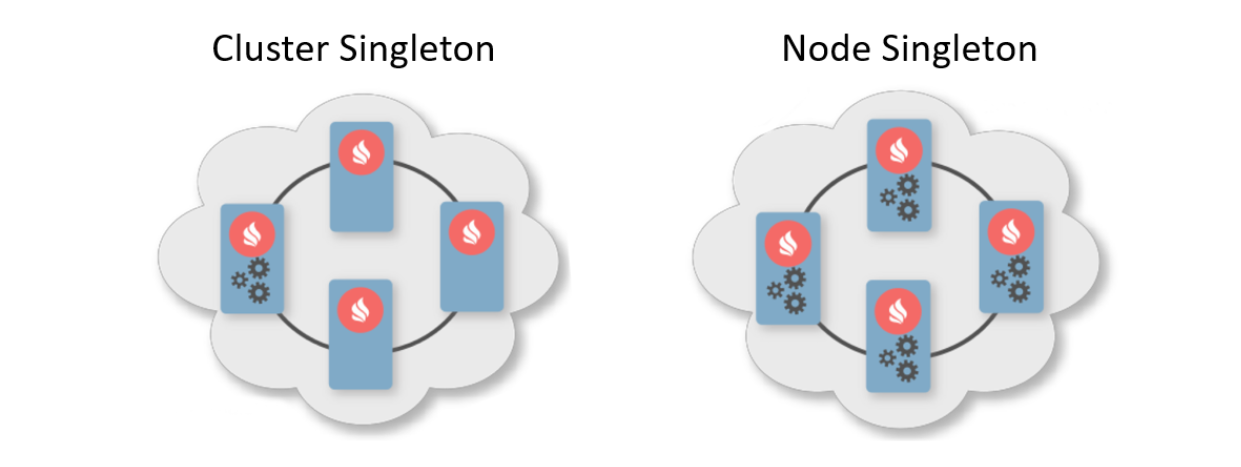
Usually the deployment scheme is an indication of the number of instances that should be deployed on the cluster nodes. There are two typical deployment schemes. The first is Cluster Singleton: at any time in the cluster, one instance of the user service is guaranteed to be available. The second is Node Singleton: on each node of the cluster one service instance is deployed.
The user can also specify the number of service instances in the entire cluster and define a predicate for filtering suitable nodes. In this scenario, the Service Grid itself calculates the optimal distribution for service deployment.
In addition, there is such a feature as Affinity Service. Affinity is a function that determines the connection of keys with partitions and the connection of batches with nodes in a topology. The key can be used to determine the primary node where data is stored. In this way, you can associate your own service with the key and affinity function cache. In the case of a change in the affinity function, an automatic redeploy will occur. So the service will always be placed next to the data that it has to manipulate, and, accordingly, reduce the overhead of access to information. Such a scheme can be called a kind of collocated computations.
Now that we’ve seen what the beauty of the Service Grid is, let's talk about its development history.
The previous implementation of the Service Grid was based on the Ignite transactional replicated system cache. The term "cache" in Ignite means storage. That is, it is not something temporary, as you might think. Despite the fact that the cache is replicable and each node contains the entire data set, the cache has a partitioned view inside. This is due to the optimization of storage.

What happened when the user wanted to close the service?
At some point we came to the conclusion: it is impossible to work with services in this way. There were several reasons.
If some kind of error occurred during deployment, then it was possible to learn about it only from the logs of the node where everything happened. There was only asynchronous deployment, so after returning the control from the deployment method to the user, some additional time was needed to start the service — and at that time the user could not control anything. To develop the Service Grid further, cut new features, attract new users and make life easier for everyone, you need to change something.
When designing a new Service Grid, we first of all wanted to provide a guarantee of synchronous deployment: as soon as the user returned control from the API, he could immediately use the services. I also wanted to give the initiator the ability to handle deployment errors.
In addition, I wanted to facilitate the implementation, namely to get away from transactions and rebalancing. Despite the fact that the cache is replicable and there is no balancing, there were problems during a large deployment with many nodes. When the topology changes, the nodes need to exchange information, and with large deployments, this data can weigh a lot.
When the topology was unstable, the coordinator needed to recalculate the distribution of services. And in general, when you have to work with transactions on an unstable topology, this can lead to difficult-to-predictable errors.
What are the global changes without related problems? The first of these was a topology change. You need to understand that at any time, even at the time of deployment of the service, a node can enter into a cluster or leave it. Moreover, if the node enters the cluster at the time of deployment, you will need to consistently transfer all the information about the services to the new node. And we are talking not only about what has already been deployed, but also about current and future deployments.
This is just one of the problems that can be put together in a separate list:
And that's not all.
As a target, we chose the Event Driven approach with the implementation of process communication using messages. Ignite has already implemented two components that allow nodes to send messages between each other, communication-spi and discovery-spi.
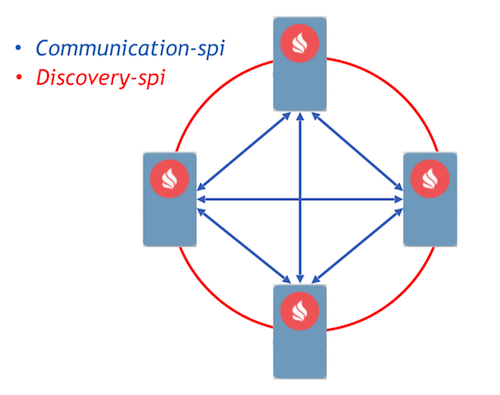
Communication-spi allows nodes to communicate and forward messages directly. It is well suited for sending large amounts of data. Discovery-spi allows you to send a message to all nodes in the cluster. In the standard implementation, this is done using a ring topology. There is also integration with Zookeeper, in this case the “star” topology is used. Another important point to note is that discovery-spi guarantees that the message will be delivered exactly in the correct order to all nodes.
Consider the deployment protocol. All user requests for deploy and razdeloma sent by discovery-spi. This gives the following guarantees :
When a request is received, the nodes in the cluster validate it and form tasks for processing. These tasks are added to a queue and then processed in another thread by a separate worker. This is implemented in this way, because the deployment can take considerable time and delay expensive discovery-flow is unacceptable.
All requests from the queue are processed by the deployment manager. He has a special worker who pulls the task out of this queue and initializes it to start the deployment. After this, the following actions occur:

New event-driven design: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
If an error occurred at the time of deployment, the node immediately includes this error in a message that sends to the coordinator. After aggregation of messages, the coordinator will have information about all errors during deployment and send this message via discovery-spi. Error information will be available on any node in the cluster.
According to this algorithm, all important events in the Service Grid are processed. For example, a topology change is also a message on discovery-spi. And in general, if compared with what was, the protocol turned out to be quite lightweight and reliable. Just enough to handle any situation during deployment.
Now about the plans. Any major refinement in the Ignite project is carried out as an initiative to improve Ignite, the so-called IEP. The Service Grid redesign also has an IEP - IEP No. 17 with the stem name “Oil Change in Service Grid”. But in fact, we have changed not the engine oil, but the engine entirely.
We divided the tasks in the IEP into 2 phases. The first is a major phase, which consists in reworking the deployment protocol. It is already injected into the master, you can try the new Service Grid, which will appear in version 2.8. The second phase includes many other tasks:
Finally, we can advise you of the Service Grid for building fault-tolerant high-availability systems. We also invite you to our dev-list and user-list to share your experience. Your experience is really important for the community, it will help you understand where to go next, how to develop the component in the future.
To begin with, what is Apache Ignite in general. This is a database that is a distributed Key / Value repository with support for SQL, transactional and caching. In addition, Ignite allows you to deploy custom services right in the Ignite cluster. All the tools that Ignite provides — distributed data structures, Messaging, Streaming, Compute, and Data Grid — are becoming available to the developer. For example, when using the Data Grid, the problem with the administration of a separate infrastructure for the data storage and, as a result, the overheads arising from this disappears.
')
Using the API Service Grid, you can finish the service by simply specifying the deployment scheme and, accordingly, the service itself in the configuration.
Usually the deployment scheme is an indication of the number of instances that should be deployed on the cluster nodes. There are two typical deployment schemes. The first is Cluster Singleton: at any time in the cluster, one instance of the user service is guaranteed to be available. The second is Node Singleton: on each node of the cluster one service instance is deployed.
The user can also specify the number of service instances in the entire cluster and define a predicate for filtering suitable nodes. In this scenario, the Service Grid itself calculates the optimal distribution for service deployment.
In addition, there is such a feature as Affinity Service. Affinity is a function that determines the connection of keys with partitions and the connection of batches with nodes in a topology. The key can be used to determine the primary node where data is stored. In this way, you can associate your own service with the key and affinity function cache. In the case of a change in the affinity function, an automatic redeploy will occur. So the service will always be placed next to the data that it has to manipulate, and, accordingly, reduce the overhead of access to information. Such a scheme can be called a kind of collocated computations.
Now that we’ve seen what the beauty of the Service Grid is, let's talk about its development history.
What was before
The previous implementation of the Service Grid was based on the Ignite transactional replicated system cache. The term "cache" in Ignite means storage. That is, it is not something temporary, as you might think. Despite the fact that the cache is replicable and each node contains the entire data set, the cache has a partitioned view inside. This is due to the optimization of storage.
What happened when the user wanted to close the service?
- All nodes in the cluster subscribed to update data in the repository using the built-in Continuous Query mechanism.
- The initiating node under the read-committed transaction made a record in the database that contained the configuration of the service, including the serialized instance.
- When receiving notification of a new record, the coordinator calculated the distribution based on the configuration. The resulting object was recorded back into the database.
- Nodes read information about the new distribution and deployment services in
if necessary.
What did not suit us
At some point we came to the conclusion: it is impossible to work with services in this way. There were several reasons.
If some kind of error occurred during deployment, then it was possible to learn about it only from the logs of the node where everything happened. There was only asynchronous deployment, so after returning the control from the deployment method to the user, some additional time was needed to start the service — and at that time the user could not control anything. To develop the Service Grid further, cut new features, attract new users and make life easier for everyone, you need to change something.
When designing a new Service Grid, we first of all wanted to provide a guarantee of synchronous deployment: as soon as the user returned control from the API, he could immediately use the services. I also wanted to give the initiator the ability to handle deployment errors.
In addition, I wanted to facilitate the implementation, namely to get away from transactions and rebalancing. Despite the fact that the cache is replicable and there is no balancing, there were problems during a large deployment with many nodes. When the topology changes, the nodes need to exchange information, and with large deployments, this data can weigh a lot.
When the topology was unstable, the coordinator needed to recalculate the distribution of services. And in general, when you have to work with transactions on an unstable topology, this can lead to difficult-to-predictable errors.
Problems
What are the global changes without related problems? The first of these was a topology change. You need to understand that at any time, even at the time of deployment of the service, a node can enter into a cluster or leave it. Moreover, if the node enters the cluster at the time of deployment, you will need to consistently transfer all the information about the services to the new node. And we are talking not only about what has already been deployed, but also about current and future deployments.
This is just one of the problems that can be put together in a separate list:
- How to shut down statically configured services when starting a node?
- Exiting a node from a cluster - what to do if a host is a hostel services?
- What to do if the coordinator changed?
- What should I do if the client reconnects to the cluster?
- Do I need to process activation / deactivation requests and how?
- But what if they caused a crash cache, and we have affinity services tied to it?
And that's not all.
Decision
As a target, we chose the Event Driven approach with the implementation of process communication using messages. Ignite has already implemented two components that allow nodes to send messages between each other, communication-spi and discovery-spi.
Communication-spi allows nodes to communicate and forward messages directly. It is well suited for sending large amounts of data. Discovery-spi allows you to send a message to all nodes in the cluster. In the standard implementation, this is done using a ring topology. There is also integration with Zookeeper, in this case the “star” topology is used. Another important point to note is that discovery-spi guarantees that the message will be delivered exactly in the correct order to all nodes.
Consider the deployment protocol. All user requests for deploy and razdeloma sent by discovery-spi. This gives the following guarantees :
- The request will be received by all nodes in the cluster. This will allow the request to continue processing when the coordinator changes. It also means that in one message, each node will have all the necessary metadata, such as the configuration of the service and its serialized instance.
- Strict message delivery allows you to resolve configuration conflicts and competing requests.
- Since the input of the node to the topology is also processed by discovery-spi, the new node will get all the data necessary for working with services.
When a request is received, the nodes in the cluster validate it and form tasks for processing. These tasks are added to a queue and then processed in another thread by a separate worker. This is implemented in this way, because the deployment can take considerable time and delay expensive discovery-flow is unacceptable.
All requests from the queue are processed by the deployment manager. He has a special worker who pulls the task out of this queue and initializes it to start the deployment. After this, the following actions occur:
- Each node independently calculates the distribution due to the new deterministic assignment-function.
- The nodes form a message with the results of the deployment and send it to the coordinator.
- The coordinator aggregates all messages and generates the result of the entire deployment process, which is sent via discovery-spi to all nodes in the cluster.
- When the result is received, the deployment process is completed, after which the task is removed from the queue.
New event-driven design: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
If an error occurred at the time of deployment, the node immediately includes this error in a message that sends to the coordinator. After aggregation of messages, the coordinator will have information about all errors during deployment and send this message via discovery-spi. Error information will be available on any node in the cluster.
According to this algorithm, all important events in the Service Grid are processed. For example, a topology change is also a message on discovery-spi. And in general, if compared with what was, the protocol turned out to be quite lightweight and reliable. Just enough to handle any situation during deployment.
What will happen next
Now about the plans. Any major refinement in the Ignite project is carried out as an initiative to improve Ignite, the so-called IEP. The Service Grid redesign also has an IEP - IEP No. 17 with the stem name “Oil Change in Service Grid”. But in fact, we have changed not the engine oil, but the engine entirely.
We divided the tasks in the IEP into 2 phases. The first is a major phase, which consists in reworking the deployment protocol. It is already injected into the master, you can try the new Service Grid, which will appear in version 2.8. The second phase includes many other tasks:
- Hot thin
- Service Versioning
- Increased resiliency
- Thin client
- Tools for monitoring and counting various metrics
Finally, we can advise you of the Service Grid for building fault-tolerant high-availability systems. We also invite you to our dev-list and user-list to share your experience. Your experience is really important for the community, it will help you understand where to go next, how to develop the component in the future.
Source: https://habr.com/ru/post/447264/
All Articles