How to run ML prototype in one day. Report Yandex.Taxi
Machine learning is applied on the entire cycle of ordering a car in Yandex.Taxi, and the number of service components operating thanks to ML is constantly growing. To build them uniformly, we needed a separate process. Roman Khalkechev, head of the machine learning and data analysis service, told about data preprocessing, production models, prototyping services and related tools.
- In my opinion, some new things are much easier perceived when they are told on some simple example. Therefore, so that the report was not dry, I decided to tell you about one of the tasks that we solve. In her example, I will show why we act this way.
Let's formulate the problem. There are Taxi users who need to get from point A to point B, and there are drivers who are ready for a certain amount to deliver these users from point A to point B. The user has several states in which he is located. He calls a taxi, selects point A, point B, fare, and so on, makes a taxi ride, rides, and finally makes a landing. Today I would like to talk about landing in the car and the problems that may arise.
')

As a rule, these problems are connected with the fact that a person needs to choose the place where the taxi should go. And here is a series of difficulties. These difficulties are associated with four things that I listed on the slide.
First of all, the location may be unfamiliar to the user. As an example, you can imagine yourself coming to some large shopping center in which you are not so often. You want to leave and you don’t have much idea where you can call a taxi, where the car can go and where it cannot - for example, because of a barrier. There are problems with the fact that in some places a lot of people, a lot of cars and you find it difficult to find your car. There are places where people usually get into a car, it's easier to sit there. And you may not know, being in some new place, not necessarily in a shopping center, exactly where to land. Difficulties may be related to the fact that the driver cannot drive to the place where you called a taxi: he is forbidden to travel, there is some big exit from the shopping center, in front of which you can not stop, and so on.
On the other hand, you may have problems as a user. The driver arrived, everything is fine, but you are uncomfortable to sit down because everyone dug up. You ask the driver to drive somewhere else. There are other reasons.
The most obvious example, the quintessence of all the above, can serve as an airport, where almost everything is executed. Even if you fly out of Sheremetyevo very often, it is still an unfamiliar location for you, because there often changes a lot. There are a lot of people there, a lot of cars, there are convenient places for landing, there are uncomfortable, but, as a rule, none of us remember.
The solution is read from the title of the slide. Let's recommend to the user some places in which, in our opinion, it is convenient to land. The idea seems obvious, but there are many nuances here.
To begin with, "convenient" is a subjective concept. It seems that before solving a problem, it is necessary to formulate some criteria that the problem will be solved correctly. We have formulated three main ones for ourselves. The first criterion is as in any task of recommendations: probably recommendations are good if they are used. If we show such points from which the user will actually leave - probably these are good points. But this, of course, is not all yet, because one can learn to recommend something, show, encourage the user to use it, but not get some tangible profit (neither we as a system, nor a user, nor a driver). Therefore, it is very important to look at other metrics. We chose two.
If we tell a place where the driver will be easy to drive to, then the time of the car delivery should be reduced. On the other hand, if in this place it will be easier for the user to find the car, it is easier to land, then the driver’s waiting time should decrease. This is some of our hypothesis that we take for granted, and these are some metrics that we look at when we make these recommendations. But of course, these are not the only metrics to look at. They can come up with a dozen more. I think each of you can come up with a hundred of these metrics.
Here are some more examples. This may be a share of cancellations before the trip. In theory, it should be reduced if it is easier for the user to land. Conventionally, these are calls when the user calls the driver, trying to find him, or, conversely, the driver calls the user before the trip begins. This appeal to support, and a dozen others.
We formulated the problem. We roughly understood the criterion that we can solve this problem. Let's now think about how to solve this problem. The first thing that comes to mind: let us recommend some such proven and understandable landing points. Here on the slide is an example of the European shopping center. And we know for sure that you can drive up to the exits from this shopping center, and this is a certain guideline, thanks to which the user can find the driver. It could be any organization. There is an example with the "ABC of taste" in some shopping center. In my opinion, this is “Yerevan Plaza”. This is also a guide for the user and the driver, about which we know that you can drive up there.
These can be landmarks at the airports I mentioned. Conventionally, there are such pillars in Sheremetyevo with numbers. It is convenient to call a taxi and get into the car. Good decision, but it has a minus, that it is not very scalable. We have many countries, hundreds of cities, still a huge number of different shopping centers, airports, difficult junctions, unfamiliar places for which it is rather difficult to make these points manually, and keeping them up to date is even more difficult. It is here that what is loudly called “artificial intelligence” comes to our aid. I prefer to call it data mining or machine learning.
Machine learning needs some data, and we actually have this data. Another way to solve the problem automatically is to use this data. The high-level idea is that we have data about GPS, application logs, and there is a graph of roads. And we can understand where users actually get in the car. Not the points at which they call the car, but where they land. And based on this, do something like that.

These are automatically obtained points for the Aurora business center, in which our Yandex.Taxi team is currently sitting.
I spoke high level about our task. Now let's talk more about what stages the solution to this problem consists of. It is clear that there is a stage of data preparation.

What data do we have? First, we have our users 'GPS data and our drivers' GPS data. When they use our application, we know the approximate location of users. It is clear that GPS has a large error, in the region of 13-15 meters, but nevertheless, there is something. Secondly, we have information that is contained in the application logs, about when the driver moved from the status “I expect the user” to the status “I am carrying the user”. It can be assumed that around this time the driver waited for the user, the user got into the car, and they drove off. Approximately in this place landing was made. And we have a road graph. The road graph is not only a set of edges, streets, but also additional meta-information: barriers, information about parking, etc. On the basis of this data, you can already get some kind of automatic points.
This was the original data. And at the exit, we want two things. These are some so-called candidates for landing points. How are they obtained? It is a pity that it was not possible to show the video. Approximately the following occurs. We have a lot of GPS points where we know that the driver has moved from “I’m waiting for a passenger” status to “Let's go” status. We can, conditionally, pull them to the graph, that is, project them onto the graph of roads, because, as a rule, the car starts moving from some kind of road. On this graph some clustering of these points is performed. And get a large number of candidates - a place in which some users sat in the car, and it was normal, convenient for them. Not where they called, but where they eventually sat down.
After that, when we have a lot of candidates and we have a certain user online, we know its location, so he opened the application and wants to call a taxi, then we can choose the best five from a large number of candidates and show them. The best five are determined by some machine learning model that learns to rank all candidates by the likelihood that the user is right now at this time, given their location and given their travel history, is most convenient to leave. And approximately so we can automatically generate these points. Moreover, if at some point somewhere, conditionally, they dig up, that is, it becomes inconvenient to call a taxi, or somewhere they put a sign prohibiting a stop, and drivers and users will really stop landing at this place, then at some point The moment the algorithm will understand this, and the data will be updated.
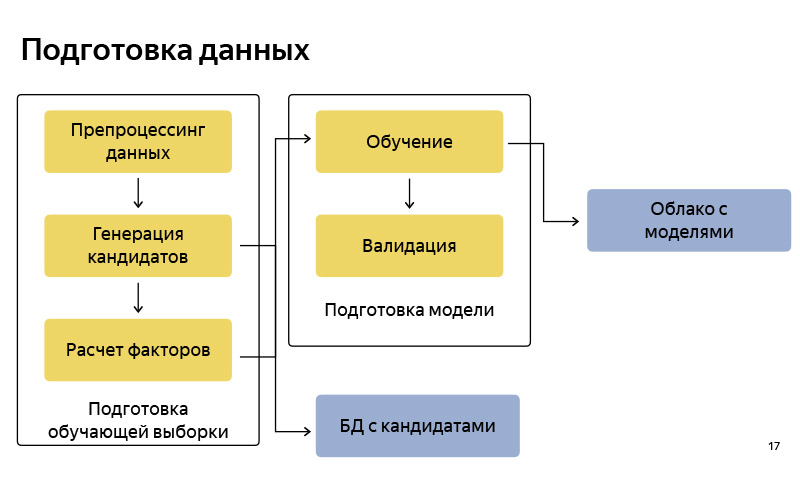
Something like this is a block diagram of how we prepare the data. Accordingly, it is fairly standard, as in any machine learning pipeline. There is data preparation, there is a generation of candidates by the algorithm, I told a simplified version. We keep these candidates in some database. After that we prepare some training pool (training sample), in which there is, conditionally, a user, time, meta information, a set of candidates, and it is known from which point the user eventually left. This is where we teach the classification model. And then according to the predictions of probability we rank the candidates. When the model is ready, we upload it to some cloud, where it is well stored.
What tools do we use in data preparation? Basically, all the data preparation we have is written in Python, on the Python stack: these are standard NumPy, Pandas, Scikit-learn, etc. We have a lot of data. We have millions of trips per month. There is a lot of data about GPS, about driver tracks, application logs, so we need to process them all the same on a cluster. To do this, we use MapReduce of our intra-Yandex version, called YT, and there is a library written in Python that allows some mappers and reducers to run and do some calculations on a large cluster.
Finally, when the pipeline is ready, we need to automate it so that the data is relevant, and for this we use such a thing as Nirvana and Hitman. This is also intra-development. Nirvana is a computing management framework on a cluster. In fact, it can run just about any program, be fault tolerant, be cross DC (00:14:53). And if something falls, she knows how to restart it, create launches upon the occurrence of any events. etc.

Something like this is the web interface of our MapReduce cluster. Here we see that we have a lot of machines, such nodes, on which calculations are performed.
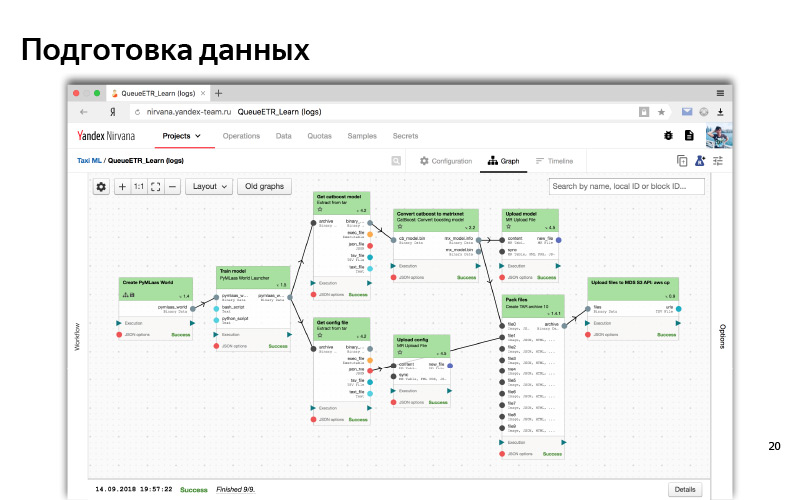
And so in the web interface looks like a typical process of some kind of data preprocessing and model training. This is such a dependency graph. Dependencies are like data, when one part (one cube) is waiting for the data of another cube; and logical dependence (we first prepared all the data, then we started the training). This is some kind of automated system. For all of this, we usually use Python.
The task was formulated, the criteria for success were formulated, they learned how to solve it offline, they even made some model, and for some offline metrics it seems to work - it really does predict the points from which the user leaves, and finds those points which, it would seem, should reduce the waiting time and filing car.

Let's try these models, use this data. To do this, you need to imagine what the Yandex.Taxi service is.
Very superficial scheme looks like. There are users, they have an application, and there are drivers, they also have an application called Taximeter. These applications somehow communicate with the backend, and the backend is a set of microservices that communicate with each other - Ilya told about it. One of the microservices is our service, our team does it, it is called ML as a Service, MLaaS.

All you need to know about it - MLaaS is written in C ++, based on the so-called Fastcgi Daemon. This is an open source library, which is, roughly speaking, a framework for writing a web server that can get and post requests, everything is standard. It was once written in Yandex, laid out in open source. We use the dopilenny version. What can this service? He knows how to work with models: apply them, keep them and sometimes update them, go to this wonderful cloud, where models are regularly updated, saved, and downloaded.
Each functionality, for example, these landing points - inside we call them pickup points - or, for example, the tips of points B, about which Ilya spoke and broke all the time in the previous report, every such functionality where there is some machine learning corresponds to A handler that stores the logic for receiving a request, generating machine learning factors, applying models, and generating a response. Of course, this service is not isolated, able to go to some additional data sources, databases, some other microservices.
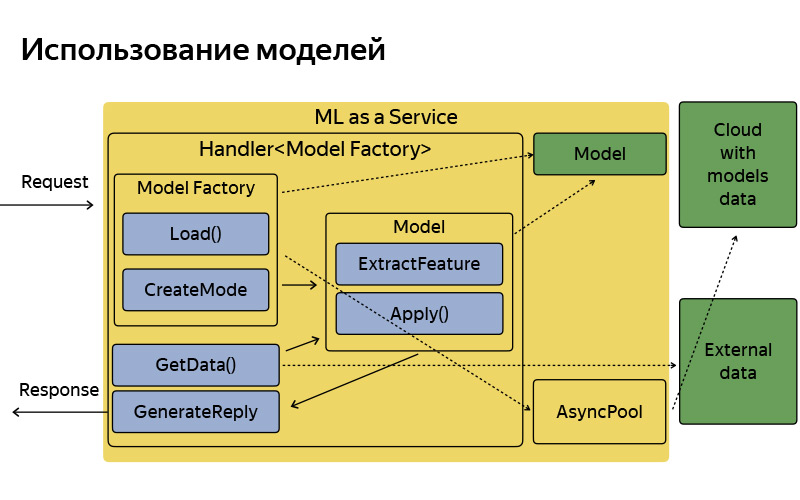
Approximately the way it is, it has a fairly simple architecture. I did not want to dwell on this slide in detail, I just wanted to say that, conditionally, the architecture is very simple. A request arrives, there is some factory of models that sometimes downloads these models from the cloud. In memory, they are stored in a single copy. For each request, a rather lightweight model object is created that extracts features, applies and generates a response.

But what do we have at the moment? I have already told you that we have data preparation, training, various studies, experiments, and all this is written on the Python Stack, and there is some production that is written in C ++, simply because we have great requirements for efficiency and productivity. When you live in such an ecosystem, two problems arise.
First of all, this is the problem of experiments. For example, the data scientist who works in our team got an idea. If you run any clustering or classification algorithm with slightly different parameters, you can achieve better quality. He tried to test his hypothesis offline, built into our Python process, figured out, and it really works. And now he wants an AB-experiment, that is, parts of users show a new algorithm and measure some metrics already online: whether the delivery time is really falling, waiting, whether usage is growing. For this, he has, conditionally, five versions of his algorithm, in which he believes, which offline give good quality: implement in C ++ and conduct an AB-experiment. And after this AB-experiment, perhaps all five will go to junk, that is, the quality of them online will be worse than it was offline, that is, worse than in production. That is, the process of experimentation takes a lot of time due to the fact that, conditionally, two different languages, two different technologies.
This is for existing features. And then there are new ones. Once these pickup points were also ideas that I wanted to quickly check. Do not spend on it two months of development - it is desirable to get something in three weeks. To create such a prototype is quite difficult. First write the extraction of features in Python, simply because it is convenient - move fast, as they say. In Python, you can build any prototype, there are many libraries for data analysis. You experimented in your laptop, and now you want to check on users. And it was pretty hard to make a prototype. We have come to the conclusion that we need some kind of additional service in order to assemble such prototypes rather quickly - conditionally, in a week or even a day - and also conduct AB-experiments.
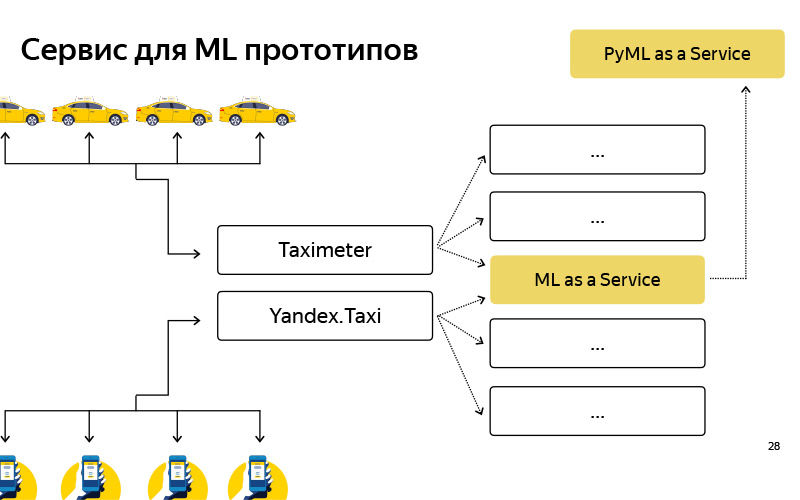
We created such a service, called it PyMLaaS. What he really is? In fact, this is a complete analogue of MLaaS, about which I spoke before, but written in Python based on Flask, nginx and Gunicorn. The architecture is quite simple, the same as in MLaaS, but it is possible to quickly hook into it some prototype of its offline experiments. In addition, we arranged such proxying at the nginx level, so that, conditionally, we had the opportunity to transfer part of the load from MLaaS to PyMLaaS and thereby experiment.

That is, we have set some parameters and want to check how this affects the users. We have allowed 5% of the load on PyMLaaS, and we see what happens in the experiment. Finally, it is convenient to create prototypes. I created a prototype of some new feature, made it into PyMLaaS and you can immediately check it in production.
We liked it so much that the idea arose - why not use it all the time? Because, conditionally, there are features that require a large load, 1000 RPS, large memory requirements. I want to have a fairly flexible parallelism. But for some features, for some products or services that do not have such large requirements for load, performance, RPS and so on, we use this service quite successfully.

Let's sum up. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .
- In my opinion, some new things are much easier perceived when they are told on some simple example. Therefore, so that the report was not dry, I decided to tell you about one of the tasks that we solve. In her example, I will show why we act this way.
Let's formulate the problem. There are Taxi users who need to get from point A to point B, and there are drivers who are ready for a certain amount to deliver these users from point A to point B. The user has several states in which he is located. He calls a taxi, selects point A, point B, fare, and so on, makes a taxi ride, rides, and finally makes a landing. Today I would like to talk about landing in the car and the problems that may arise.
')
As a rule, these problems are connected with the fact that a person needs to choose the place where the taxi should go. And here is a series of difficulties. These difficulties are associated with four things that I listed on the slide.
First of all, the location may be unfamiliar to the user. As an example, you can imagine yourself coming to some large shopping center in which you are not so often. You want to leave and you don’t have much idea where you can call a taxi, where the car can go and where it cannot - for example, because of a barrier. There are problems with the fact that in some places a lot of people, a lot of cars and you find it difficult to find your car. There are places where people usually get into a car, it's easier to sit there. And you may not know, being in some new place, not necessarily in a shopping center, exactly where to land. Difficulties may be related to the fact that the driver cannot drive to the place where you called a taxi: he is forbidden to travel, there is some big exit from the shopping center, in front of which you can not stop, and so on.
On the other hand, you may have problems as a user. The driver arrived, everything is fine, but you are uncomfortable to sit down because everyone dug up. You ask the driver to drive somewhere else. There are other reasons.
The most obvious example, the quintessence of all the above, can serve as an airport, where almost everything is executed. Even if you fly out of Sheremetyevo very often, it is still an unfamiliar location for you, because there often changes a lot. There are a lot of people there, a lot of cars, there are convenient places for landing, there are uncomfortable, but, as a rule, none of us remember.
The solution is read from the title of the slide. Let's recommend to the user some places in which, in our opinion, it is convenient to land. The idea seems obvious, but there are many nuances here.
To begin with, "convenient" is a subjective concept. It seems that before solving a problem, it is necessary to formulate some criteria that the problem will be solved correctly. We have formulated three main ones for ourselves. The first criterion is as in any task of recommendations: probably recommendations are good if they are used. If we show such points from which the user will actually leave - probably these are good points. But this, of course, is not all yet, because one can learn to recommend something, show, encourage the user to use it, but not get some tangible profit (neither we as a system, nor a user, nor a driver). Therefore, it is very important to look at other metrics. We chose two.
If we tell a place where the driver will be easy to drive to, then the time of the car delivery should be reduced. On the other hand, if in this place it will be easier for the user to find the car, it is easier to land, then the driver’s waiting time should decrease. This is some of our hypothesis that we take for granted, and these are some metrics that we look at when we make these recommendations. But of course, these are not the only metrics to look at. They can come up with a dozen more. I think each of you can come up with a hundred of these metrics.
Here are some more examples. This may be a share of cancellations before the trip. In theory, it should be reduced if it is easier for the user to land. Conventionally, these are calls when the user calls the driver, trying to find him, or, conversely, the driver calls the user before the trip begins. This appeal to support, and a dozen others.
We formulated the problem. We roughly understood the criterion that we can solve this problem. Let's now think about how to solve this problem. The first thing that comes to mind: let us recommend some such proven and understandable landing points. Here on the slide is an example of the European shopping center. And we know for sure that you can drive up to the exits from this shopping center, and this is a certain guideline, thanks to which the user can find the driver. It could be any organization. There is an example with the "ABC of taste" in some shopping center. In my opinion, this is “Yerevan Plaza”. This is also a guide for the user and the driver, about which we know that you can drive up there.
These can be landmarks at the airports I mentioned. Conventionally, there are such pillars in Sheremetyevo with numbers. It is convenient to call a taxi and get into the car. Good decision, but it has a minus, that it is not very scalable. We have many countries, hundreds of cities, still a huge number of different shopping centers, airports, difficult junctions, unfamiliar places for which it is rather difficult to make these points manually, and keeping them up to date is even more difficult. It is here that what is loudly called “artificial intelligence” comes to our aid. I prefer to call it data mining or machine learning.
Machine learning needs some data, and we actually have this data. Another way to solve the problem automatically is to use this data. The high-level idea is that we have data about GPS, application logs, and there is a graph of roads. And we can understand where users actually get in the car. Not the points at which they call the car, but where they land. And based on this, do something like that.
These are automatically obtained points for the Aurora business center, in which our Yandex.Taxi team is currently sitting.
I spoke high level about our task. Now let's talk more about what stages the solution to this problem consists of. It is clear that there is a stage of data preparation.
What data do we have? First, we have our users 'GPS data and our drivers' GPS data. When they use our application, we know the approximate location of users. It is clear that GPS has a large error, in the region of 13-15 meters, but nevertheless, there is something. Secondly, we have information that is contained in the application logs, about when the driver moved from the status “I expect the user” to the status “I am carrying the user”. It can be assumed that around this time the driver waited for the user, the user got into the car, and they drove off. Approximately in this place landing was made. And we have a road graph. The road graph is not only a set of edges, streets, but also additional meta-information: barriers, information about parking, etc. On the basis of this data, you can already get some kind of automatic points.
This was the original data. And at the exit, we want two things. These are some so-called candidates for landing points. How are they obtained? It is a pity that it was not possible to show the video. Approximately the following occurs. We have a lot of GPS points where we know that the driver has moved from “I’m waiting for a passenger” status to “Let's go” status. We can, conditionally, pull them to the graph, that is, project them onto the graph of roads, because, as a rule, the car starts moving from some kind of road. On this graph some clustering of these points is performed. And get a large number of candidates - a place in which some users sat in the car, and it was normal, convenient for them. Not where they called, but where they eventually sat down.
After that, when we have a lot of candidates and we have a certain user online, we know its location, so he opened the application and wants to call a taxi, then we can choose the best five from a large number of candidates and show them. The best five are determined by some machine learning model that learns to rank all candidates by the likelihood that the user is right now at this time, given their location and given their travel history, is most convenient to leave. And approximately so we can automatically generate these points. Moreover, if at some point somewhere, conditionally, they dig up, that is, it becomes inconvenient to call a taxi, or somewhere they put a sign prohibiting a stop, and drivers and users will really stop landing at this place, then at some point The moment the algorithm will understand this, and the data will be updated.
Something like this is a block diagram of how we prepare the data. Accordingly, it is fairly standard, as in any machine learning pipeline. There is data preparation, there is a generation of candidates by the algorithm, I told a simplified version. We keep these candidates in some database. After that we prepare some training pool (training sample), in which there is, conditionally, a user, time, meta information, a set of candidates, and it is known from which point the user eventually left. This is where we teach the classification model. And then according to the predictions of probability we rank the candidates. When the model is ready, we upload it to some cloud, where it is well stored.
What tools do we use in data preparation? Basically, all the data preparation we have is written in Python, on the Python stack: these are standard NumPy, Pandas, Scikit-learn, etc. We have a lot of data. We have millions of trips per month. There is a lot of data about GPS, about driver tracks, application logs, so we need to process them all the same on a cluster. To do this, we use MapReduce of our intra-Yandex version, called YT, and there is a library written in Python that allows some mappers and reducers to run and do some calculations on a large cluster.
Finally, when the pipeline is ready, we need to automate it so that the data is relevant, and for this we use such a thing as Nirvana and Hitman. This is also intra-development. Nirvana is a computing management framework on a cluster. In fact, it can run just about any program, be fault tolerant, be cross DC (00:14:53). And if something falls, she knows how to restart it, create launches upon the occurrence of any events. etc.
Something like this is the web interface of our MapReduce cluster. Here we see that we have a lot of machines, such nodes, on which calculations are performed.
And so in the web interface looks like a typical process of some kind of data preprocessing and model training. This is such a dependency graph. Dependencies are like data, when one part (one cube) is waiting for the data of another cube; and logical dependence (we first prepared all the data, then we started the training). This is some kind of automated system. For all of this, we usually use Python.
The task was formulated, the criteria for success were formulated, they learned how to solve it offline, they even made some model, and for some offline metrics it seems to work - it really does predict the points from which the user leaves, and finds those points which, it would seem, should reduce the waiting time and filing car.
Let's try these models, use this data. To do this, you need to imagine what the Yandex.Taxi service is.
Very superficial scheme looks like. There are users, they have an application, and there are drivers, they also have an application called Taximeter. These applications somehow communicate with the backend, and the backend is a set of microservices that communicate with each other - Ilya told about it. One of the microservices is our service, our team does it, it is called ML as a Service, MLaaS.
All you need to know about it - MLaaS is written in C ++, based on the so-called Fastcgi Daemon. This is an open source library, which is, roughly speaking, a framework for writing a web server that can get and post requests, everything is standard. It was once written in Yandex, laid out in open source. We use the dopilenny version. What can this service? He knows how to work with models: apply them, keep them and sometimes update them, go to this wonderful cloud, where models are regularly updated, saved, and downloaded.
Each functionality, for example, these landing points - inside we call them pickup points - or, for example, the tips of points B, about which Ilya spoke and broke all the time in the previous report, every such functionality where there is some machine learning corresponds to A handler that stores the logic for receiving a request, generating machine learning factors, applying models, and generating a response. Of course, this service is not isolated, able to go to some additional data sources, databases, some other microservices.
Approximately the way it is, it has a fairly simple architecture. I did not want to dwell on this slide in detail, I just wanted to say that, conditionally, the architecture is very simple. A request arrives, there is some factory of models that sometimes downloads these models from the cloud. In memory, they are stored in a single copy. For each request, a rather lightweight model object is created that extracts features, applies and generates a response.
But what do we have at the moment? I have already told you that we have data preparation, training, various studies, experiments, and all this is written on the Python Stack, and there is some production that is written in C ++, simply because we have great requirements for efficiency and productivity. When you live in such an ecosystem, two problems arise.
First of all, this is the problem of experiments. For example, the data scientist who works in our team got an idea. If you run any clustering or classification algorithm with slightly different parameters, you can achieve better quality. He tried to test his hypothesis offline, built into our Python process, figured out, and it really works. And now he wants an AB-experiment, that is, parts of users show a new algorithm and measure some metrics already online: whether the delivery time is really falling, waiting, whether usage is growing. For this, he has, conditionally, five versions of his algorithm, in which he believes, which offline give good quality: implement in C ++ and conduct an AB-experiment. And after this AB-experiment, perhaps all five will go to junk, that is, the quality of them online will be worse than it was offline, that is, worse than in production. That is, the process of experimentation takes a lot of time due to the fact that, conditionally, two different languages, two different technologies.
This is for existing features. And then there are new ones. Once these pickup points were also ideas that I wanted to quickly check. Do not spend on it two months of development - it is desirable to get something in three weeks. To create such a prototype is quite difficult. First write the extraction of features in Python, simply because it is convenient - move fast, as they say. In Python, you can build any prototype, there are many libraries for data analysis. You experimented in your laptop, and now you want to check on users. And it was pretty hard to make a prototype. We have come to the conclusion that we need some kind of additional service in order to assemble such prototypes rather quickly - conditionally, in a week or even a day - and also conduct AB-experiments.
We created such a service, called it PyMLaaS. What he really is? In fact, this is a complete analogue of MLaaS, about which I spoke before, but written in Python based on Flask, nginx and Gunicorn. The architecture is quite simple, the same as in MLaaS, but it is possible to quickly hook into it some prototype of its offline experiments. In addition, we arranged such proxying at the nginx level, so that, conditionally, we had the opportunity to transfer part of the load from MLaaS to PyMLaaS and thereby experiment.
That is, we have set some parameters and want to check how this affects the users. We have allowed 5% of the load on PyMLaaS, and we see what happens in the experiment. Finally, it is convenient to create prototypes. I created a prototype of some new feature, made it into PyMLaaS and you can immediately check it in production.
We liked it so much that the idea arose - why not use it all the time? Because, conditionally, there are features that require a large load, 1000 RPS, large memory requirements. I want to have a fairly flexible parallelism. But for some features, for some products or services that do not have such large requirements for load, performance, RPS and so on, we use this service quite successfully.
Let's sum up. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .
Source: https://habr.com/ru/post/447186/
All Articles