Crash tests SHD AERODISK ENGINE N2, strength test

Hello! This article AERODISK company opens a blog on Habré. Cheers, comrades!
In previous articles on Habré, questions were addressed about the architecture and basic configuration of the storage system. In this article we will consider a question that was not previously covered, but it was often asked about the fault tolerance of AERODISK ENGINE storage systems. Our team will do everything to ensure that the AERODISK storage system stops working, i.e. break it down
It so happened that articles about the history of our company, our products, as well as an example of successful implementation are already hanging on Habré, for which many thanks to our partners, TS Solution and Softline.
Therefore, I will not be here to train the skills of copy-paste management, but just give links to the originals of these articles:
- Article number 1. About the company's history and storage architecture AERODISK ENGINE
- Article number 2. How to quickly set up AERODISK ENGINE
- Article number 3. An interesting project on the implementation of large video surveillance for the 2018 World Cup football in the Safe City project
I also want to share the good news. But I will begin, of course, with the problem. We, as a young vendor, in addition to other costs, are constantly faced with the fact that many engineers and administrators do not know how to properly operate our storage system.
It is clear that the management of most storage systems looks about the same from the point of view of the administrator, but at the same time, each manufacturer has its own characteristics. And we are no exception.
Therefore, in order to simplify the task of training IT professionals, we decided to devote this year to free education. To do this, in many large cities of Russia, we open the network of AERODISK Competence Centers, in which any interested technical specialist will be able to complete the course absolutely free of charge and receive an AERODISK ENGINE storage administration certificate.
In each Competence Center we will install a full-fledged demo stand from the AERODISK storage system and a physical server on which full-time training will be conducted by our teacher. We will publish the schedule of work of the Competence Centers upon their appearance, but now we have already opened a center in Nizhny Novgorod and Krasnodar is next in line. Sign up for training can be on the links below. I cite the currently known information about cities and dates:
- Nizhny Novgorod (ALREADY WORKS - you can sign up here https://aerodisk.promo/nn/ );
until April 16, 2019, you can visit the center at any time, and on April 16, 2019, a large training course will be organized. - Krasnodar (SOON OPENING - you can sign up here https://aerodisk.promo/krsnd/ );
From April 9 to 25, 2019, you can visit the center at any working time, and a large training course will be organized on April 25, 2019. - Ekaterinburg (OPENING SOON, follow the information on our website or on Habré);
May-June 2019. - Novosibirsk (follow the information on our website or on Habré);
October 2019 - Krasnoyarsk (follow the information on our website or on Habré);
November 2019.
And, of course, if Moscow is not far from you, then at any time you can visit our office in Moscow and undergo similar training.
Everything. With marketing tied, go to the technique!
On Habré, we will regularly publish technical articles about our products, load tests, comparisons, usage patterns and interesting introductions.
Crash tests SHD AERODISK ENGINE N2, strength test
ACHTUNG! After reading the article, you can say: well, of course, the vendor will check itself so that everything works “with a bang”, greenhouse conditions, etc. I will answer: nothing of the kind! Unlike our foreign competitors, we are here, close to you, and you can always come to us (to Moscow or any Central Committee) and test our storage system in any way. Thus, it doesn’t make much sense to adjust the results to an ideal picture of the world, We are very easy to check. For those who are too lazy to go who do not have time, we can organize remote testing. We have a special lab for this. Contact us.
ACHTUNG-2! This test is not stressful, because all we care about is fault tolerance. In a couple of weeks we will prepare a more powerful stand and conduct load testing of the storage systems, publishing the results here (by the way, suggestions for tests are accepted).
So, go break.
Test stand
Our booth consists of the following iron:
- 1 x Aerodisk Engine N2 storage system (2 controllers, 64GB cache, 8xFC 8Gb / s ports, 4xEthernet 10Gb / s SFP + port, 4xEthernet 1Gb / s port); The following disks are installed in the storage system:
- 4 x SAS SSD disk 900 GB;
- 12 x SAS 10k 1,2 TB disks;
- 1 x Physical server with Windows Server 2016 (2xXeon E5 2667 v3, 96GB RAM, 2xFC port 8Gb / s, 2xEthernet port 10Gb / s SFP +);
- 2 x SAN 8G switch;
- 2 x 10G LAN switch;
We connected the server to the storage system via switches both on FC and on Ethernet 10G. Stand layout below.
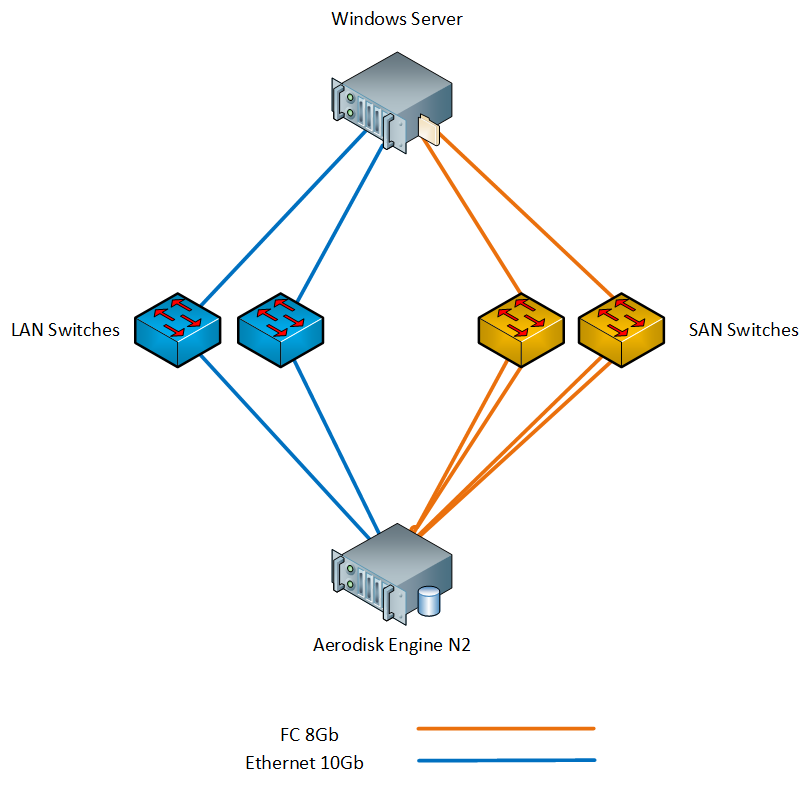
Windows Server has the necessary components installed, such as MPIO and iSCSI initiator.
On FC switches, zones are configured, corresponding VLANs are configured on LAN switches and MTU 9000 is installed on the storage ports, switches and host (as described in our documentation, this is why we will not write this process here).
Testing method
The crash test plan is:
- Check for FC and Ethernet port failure.
- Check power failure.
- Check controller failure.
- Check disk failure in the group / pool.
All tests will be performed under synthetic load conditions, which we will generate with the IOMETER program. In parallel, we will perform the same tests, but in the conditions of copying large files to the storage system.
Config IOmeter following:
- Read / Write - 70/30
- Block - 128k (we decided to wet the storage of large blocks)
- The number of threads - 128 (which is very similar to the productive load)
- Full random
- Number of Workers - 4 (2 for FC, 2 for iSCSI)
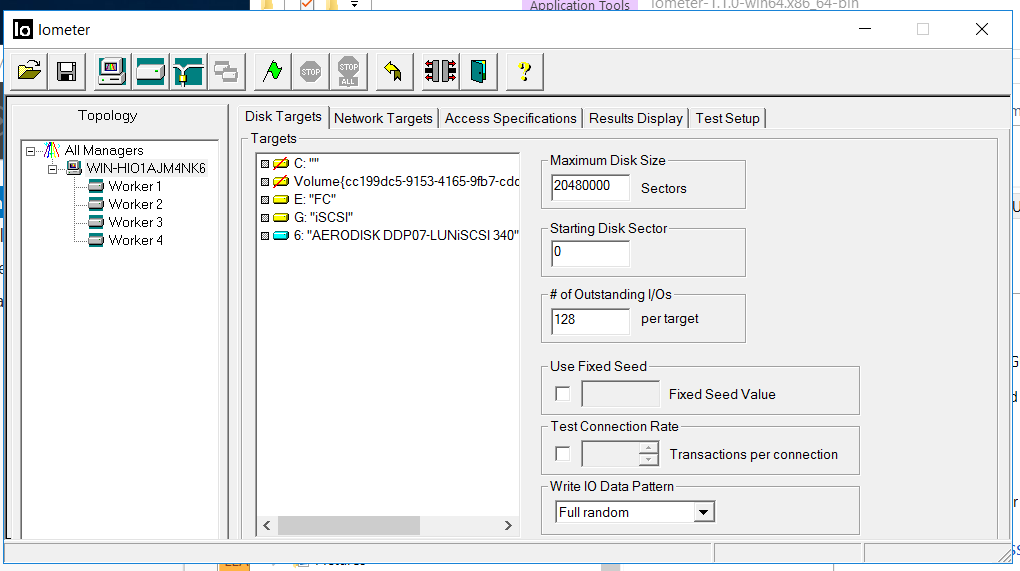
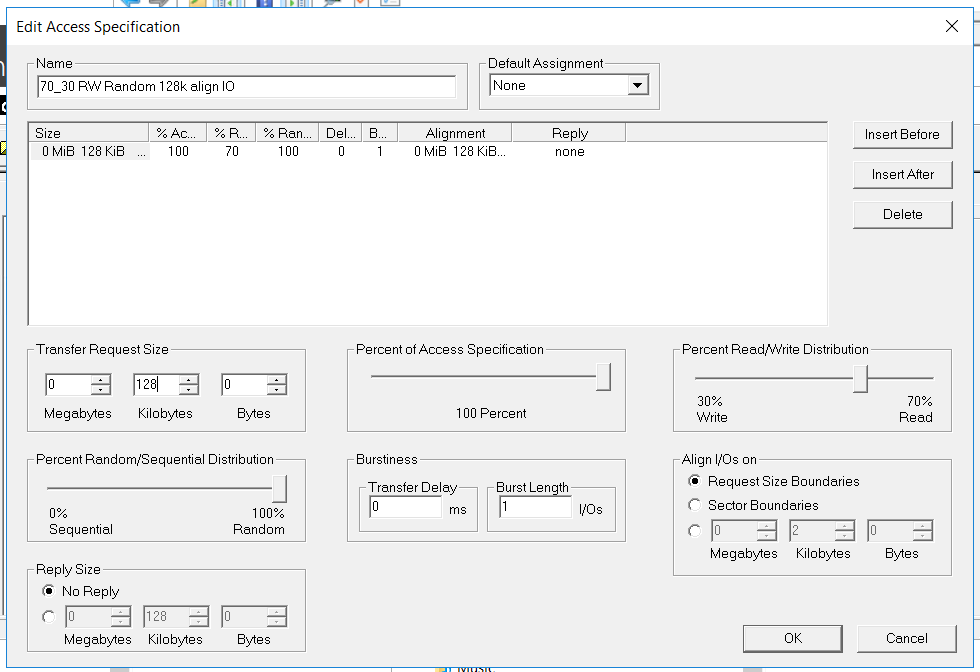
The test has the following objectives:
- Make sure that the synthetic load and the copying process will not be interrupted and will not cause errors in various failure modes.
- To make sure that the process of switching ports, controllers, etc., is sufficiently automated and does not require administrator actions in case of failures (that is, with failover, it’s not about failback, ah).
- Make sure that the information in the logs is correct.
Host and Storage Preparation
On the storage system, we configured block access using FC and Ethernet ports (FC and iSCSI, respectively). How to do this, the guys from TS Solution described in detail in a previous article ( https://habr.com/ru/company/tssolution/blog/432876/ ). And, of course, nobody canceled manuals and courses.
We set up a hybrid group using all the disks we have. 2 SSD disks are added to the cache, 2 SSD disks are added as an additional storage level (Online-tier). We grouped 12 SAS10k disks in RAID-60P (triple parity), in order to check the failure of three disks in the group at once. One disk left for autochange.
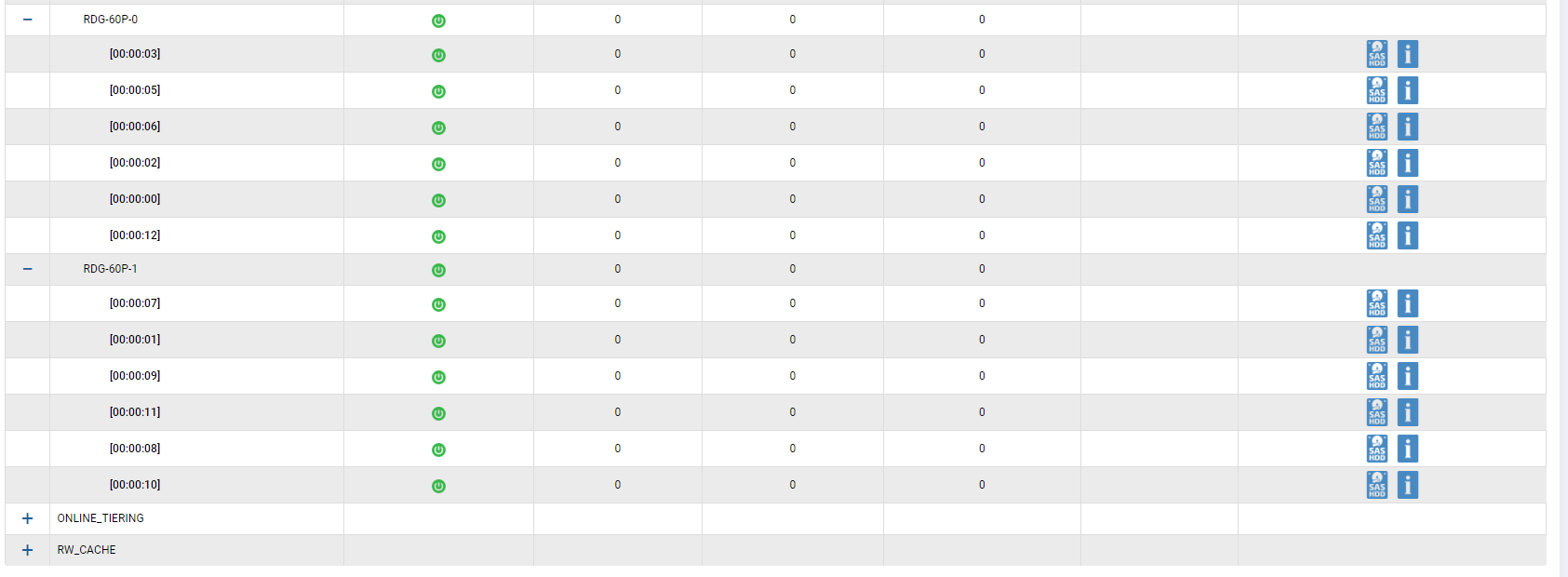
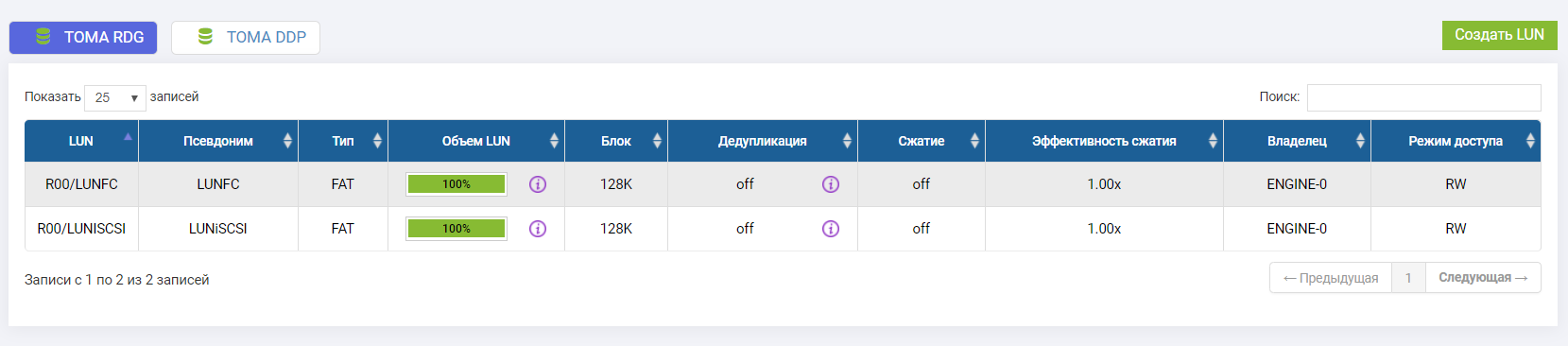
We connected two LUNs (one for FC, one for iSCSI).
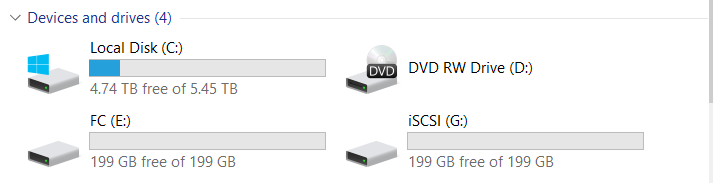
The owner of both LUNs is the Engine-0 controller
We start the test
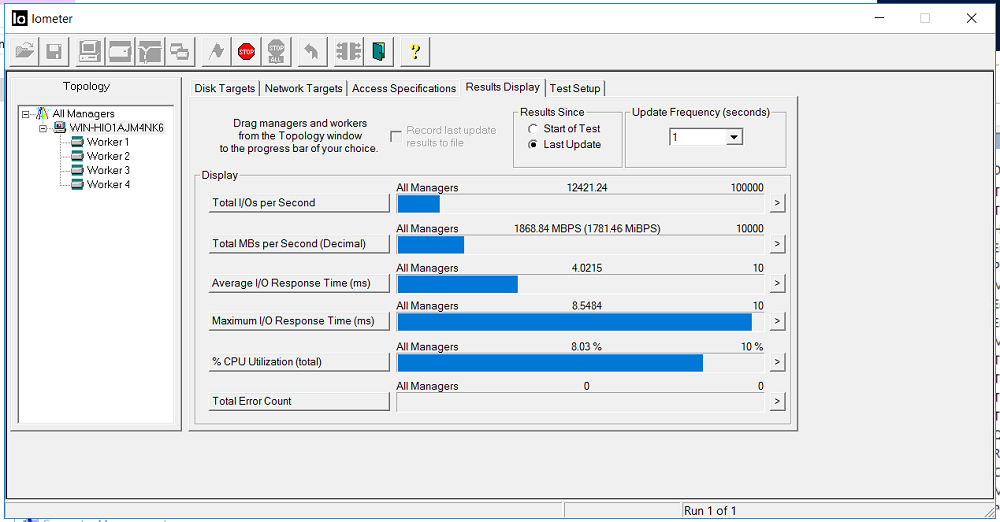
Turn on IOMETER with the config above.
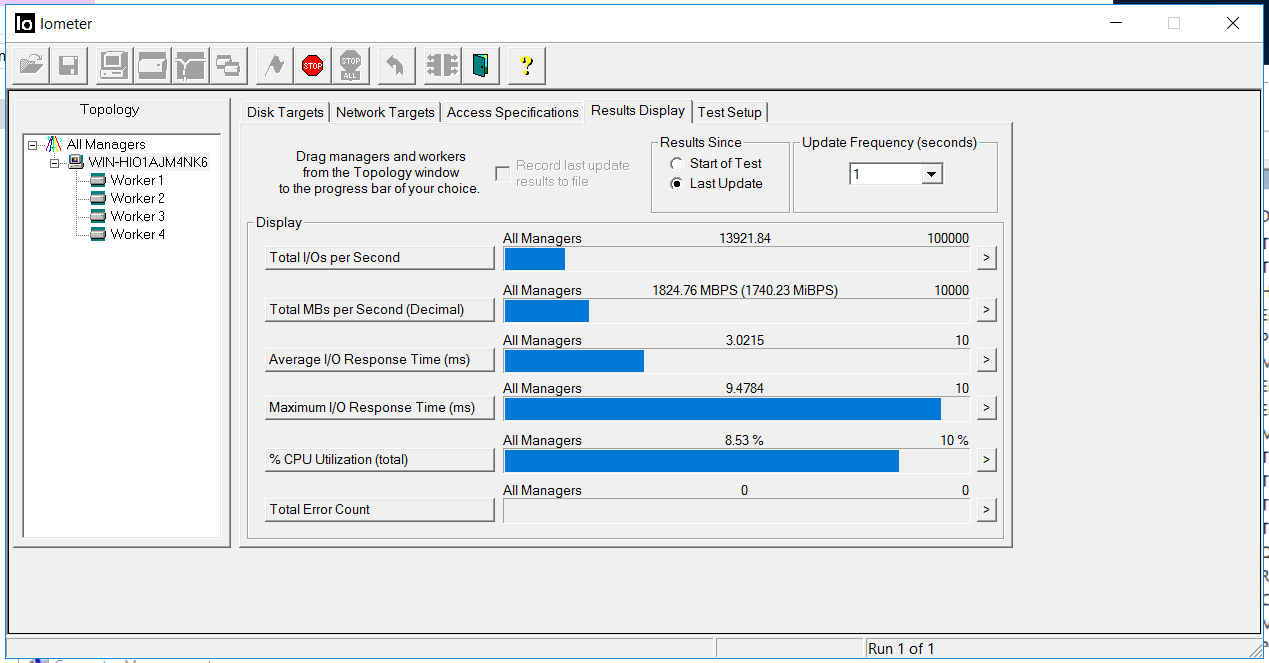
We fix the bandwidth of 1.8 GB / s and the delay of 3 milliseconds. There are no errors (Total Error Count).
At the same time, we simultaneously start copying two large files of 100GB to FC and iSCSI LUNs of storage systems (disks E and G in Windows) from the local disk "C" of our host, using other interfaces.
At the top is the copy process on LUN FC, down on iSCSI.

Test number 1. Disable I / O ports
We approach the storage system from behind))) and with a slight movement of the hand we pull out all the FC and Ethernet 10G cables from the Engine-0 controller. As if the cleaning lady with a mop passed by and decided to wash the floor just where lying snot cables lay (i.e., the controller remains working, but the I / O ports are dead).

We look at IOMETER and copy files. The bandwidth dropped to 0.5 GB / s, but quickly returned to its previous level (in about 4-5 seconds). No errors.
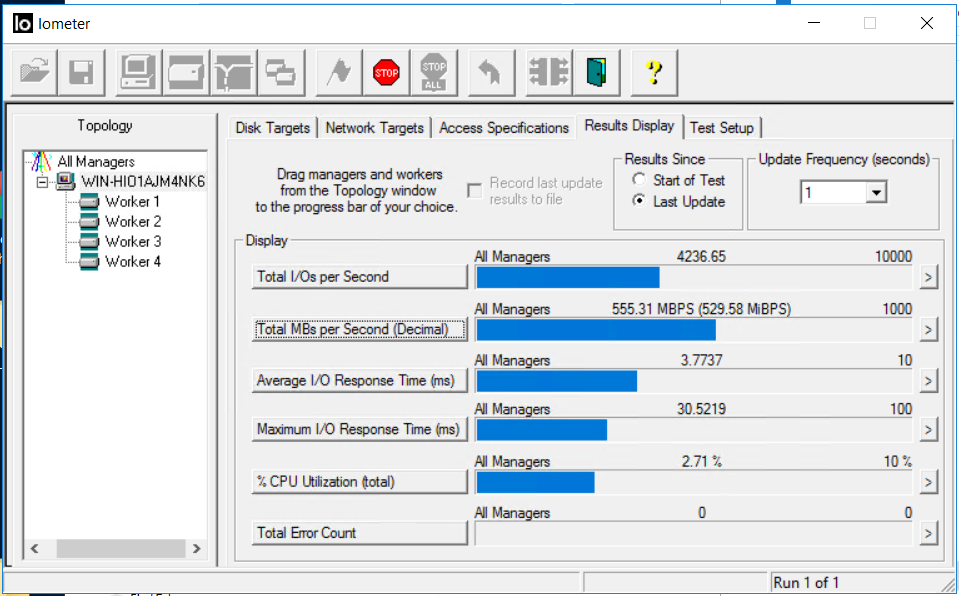
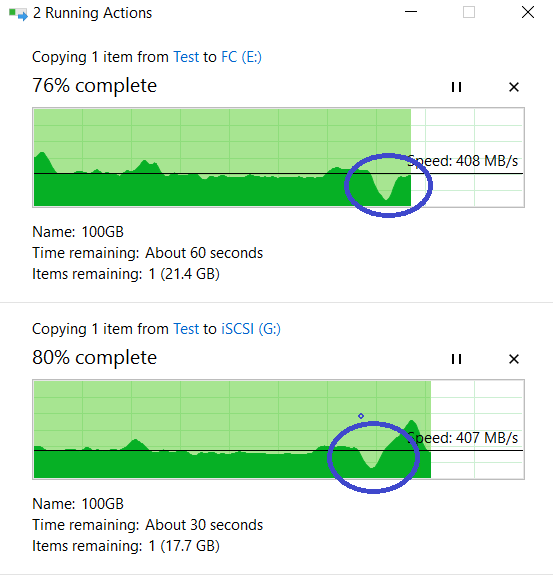
Copying files did not stop, there is a drawdown in speed, but not at all critical (from 840 MB / s dropped to 720 MB / s). Copy did not stop.
We look at the storage logs and see a message about the unavailability of ports and automatic relocation of the group.

Also, the information panel tells us that everything is not very good with FC ports.
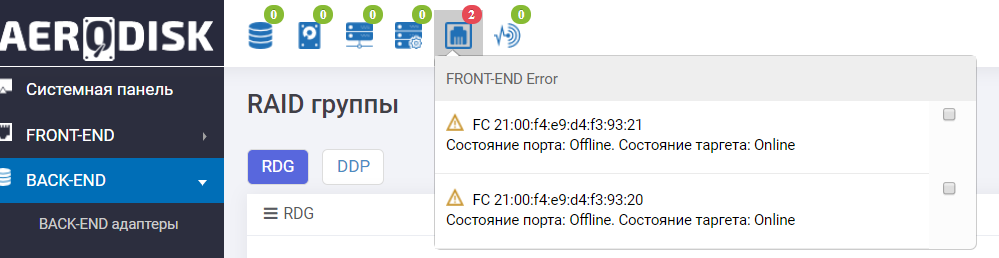
The failure of the I / O ports of the storage system was successful.
Test number 2. Disconnecting the storage controller
Almost immediately (after sticking the cables back into the storage system), we decided to finish the storage system by pulling the controller out of the chassis.
Again we approach the storage system from behind (we liked it))) and this time we pull out the controller Engine-1, which at this moment is the owner of the RDG (to which the group has moved).
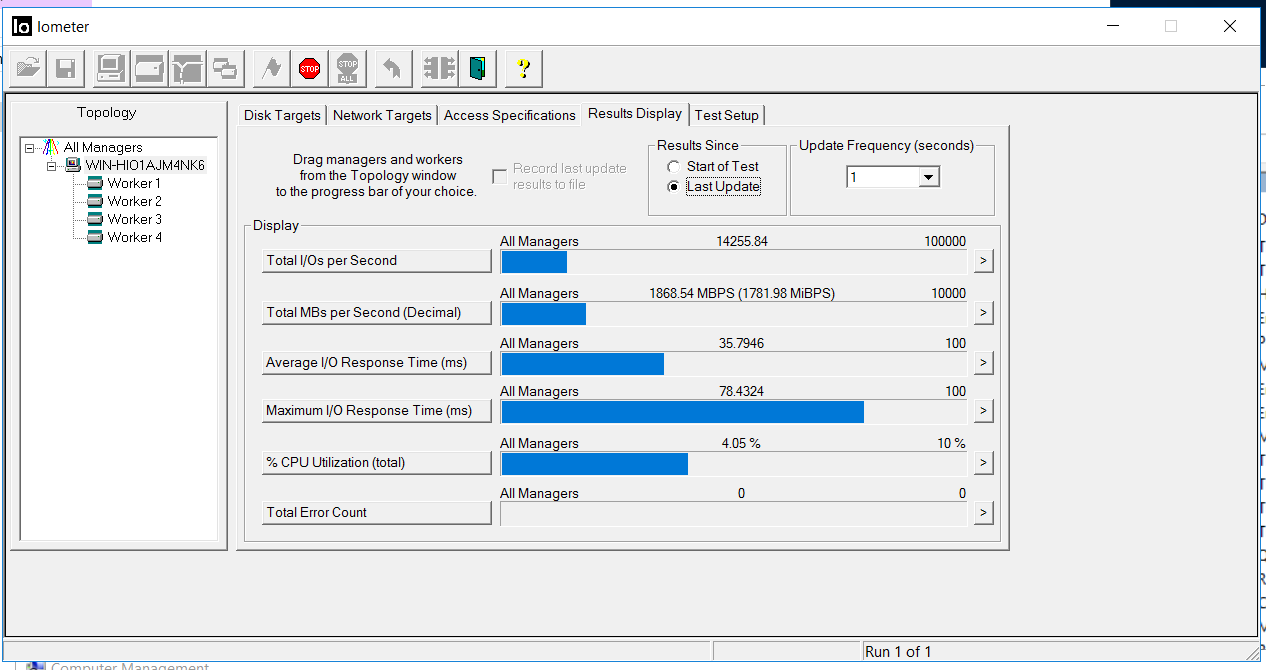
The situation in the IOmeter is as follows. Input output stopped for about 5 seconds. Errors do not accumulate.
After 5 seconds, I / O resumed, with roughly the same throughput, but with delays of 35 milliseconds (delays corrected after about a couple of minutes). As can be seen from the screenshots, the Total error count value is 0, that is, there were no read or write errors.
We look at copying our files. As you can see, it was not interrupted, there was a slight performance drawdown, but in general, everything returned to the same ~ 800 MB / s.
We go to the storage system and we see a curse in the information panel there that the Engine-1 controller is inaccessible (of course, we crashed it).
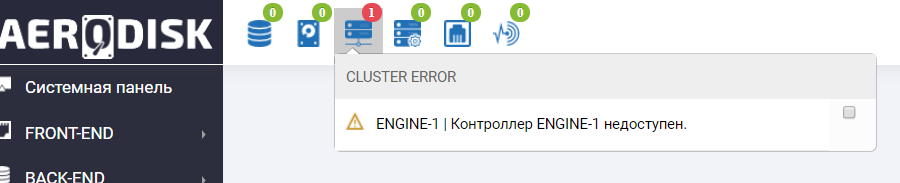
We also see a similar entry in the logs.

The failure of the storage controller was also successful.
Test number 3. Disconnect the power supply.
We just started the file copying again, but IOMETER did not stop it.
We pull BP-Schnick.

One more alert in the information panel was added to the storage system.

Also in the sensor menu, we see that the sensors associated with the power supply pulled out were reddened.

Storage continues to work. The failure of the BP-shnik does not affect the work of the storage system; from the point of view of the host, the copying speed and IOMETER indicators remained unchanged.
The power failure test was successful.
Before the final test, we decided to bring the storage system back to life a bit, put the controller and power supply unit back, and also put things in order with the cables, which the storage system happily told us about with green icons in our health panel.

')
Test number 4. The failure of the three disks in the group
Before this test, we performed an additional preparatory step. The fact is that a very useful thing is provided in SHD ENGINE - different rebuild (rebuild) policies. Earlier TS Solution wrote about this feature, but recall its essence. The storage administrator can specify the priority of resource allocation when rebuilding. Either in the direction of I / O performance, that is, a rebuild is longer, but there is no performance drawdown. Or in the direction of the speed rebuild, but the performance will be reduced. Or a balanced version. Since the performance of the storage system during a rebuild of a disk group is always the admin’s headache, we will test the policy with a bias towards I / O performance and to the detriment of the rebuild speed.

Now check the disk failure. We also enable writing to LUNs (files and IOMETER). Since we have a triple parity group (RAID-60P), it means that the system must withstand the failure of three disks, and after the failure the automatic replacement should work, one disk should take place in the RDG in place of one of the failed, and the rebuild should start.
Getting started. To begin with, we highlight the disks that we want to pull out through the storage system interface (in order not to overshoot and not to pull the autochange disk).

Check the display on the gland. All OK, we see the highlighted three disks.

And pull these three disks.

We look at the host. And there ... nothing much happened.
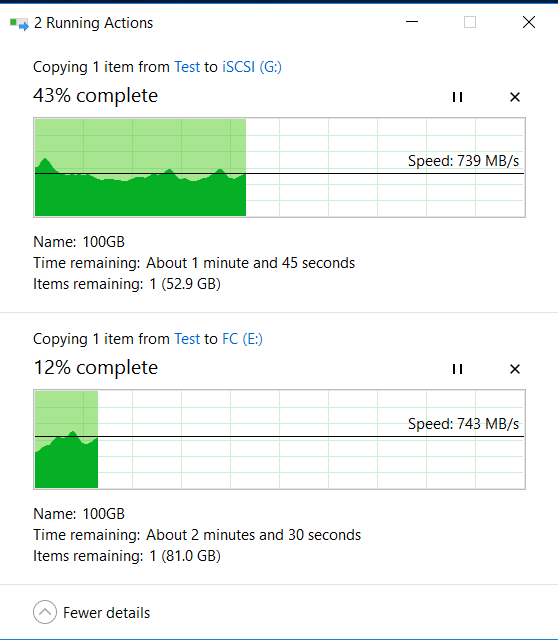
Copying indicators (they are higher than at the beginning, as the cache got warm) and IOMETER, while pulling out disks and starting up, the rebuild does not change much (within 5-10%).
We look, that on.
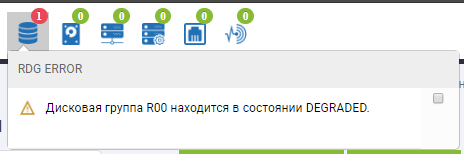
In the status of the group we see that the rebuilding process has begun and it is close to completion.

In the skeleton of the RDG, you can see that there are 2 disks in red status, and one has already been replaced. There is no autochange disk anymore, it replaced the 3rd failed disk. Rebuild was performed for several minutes, the recording of files upon the failure of 3 disks was not interrupted, the input-output performance did not change much.
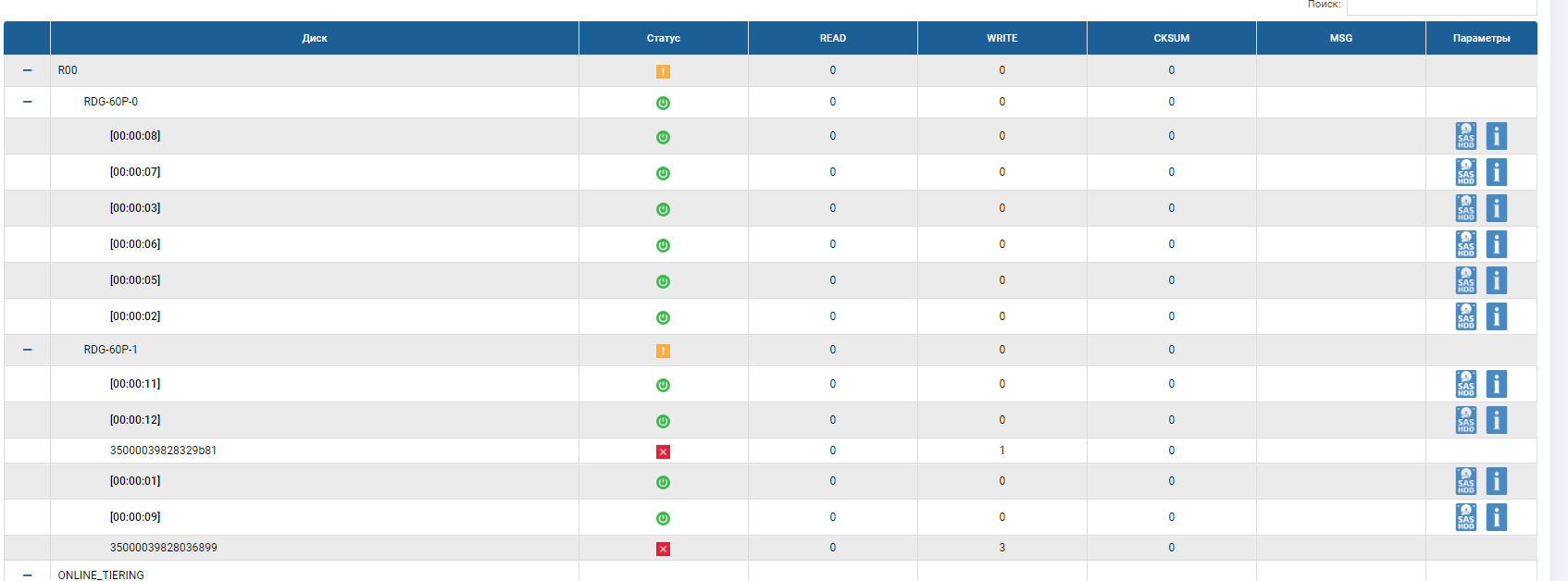
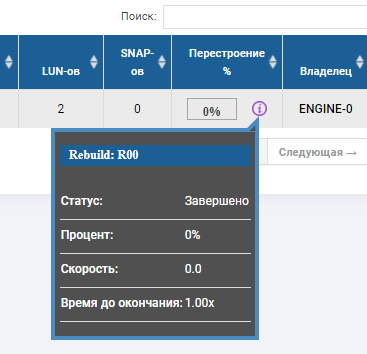
The disk failure test was definitely a success.
Conclusion
At this point, we decided to stop the storage violence. Summing up:
- Check FC port failure - successful
- Verifying Ethernet Port Failure Successfully
- Check controller failure - successful
- Power failure check - successful
- Check disk failure in the group \ pool - successfully
None of the failures stopped recording and did not cause synthetic load errors, a performance drawdown, of course, was (and we know how to beat it, which we will do soon), but considering that it is seconds, it is quite acceptable. Conclusion: the fault tolerance of all storage components AERODISK worked at the level, there are no points of failure.
It is obvious that within the framework of one article we cannot test all failure scenarios, but tried to cover the most popular ones. Therefore, please send your comments, suggestions for the following publications and, of course, adequate criticism. We will be happy discussions (and better come to the training, just in case duplicate the schedule)! To new tests!
- Nizhny Novgorod (ALREADY WORKS - you can sign up here https://aerodisk.promo/nn/ );
until April 16, 2019, you can visit the center at any time, and on April 16, 2019, a large training course will be organized. - Krasnodar (SOON OPENING - you can sign up here https://aerodisk.promo/krsnd/ );
From April 9 to 25, 2019, you can visit the center at any working time, and a large training course will be organized on April 25, 2019. - Ekaterinburg (OPENING SOON, follow the information on our website or on Habré);
May-June 2019. - Novosibirsk (follow the information on our website or on Habré);
October 2019 - Krasnoyarsk (follow the information on our website or on Habré);
November 2019.
Source: https://habr.com/ru/post/447070/
All Articles