Tracing Services, OpenTracing and Jaeger

In our projects we use microservice architecture. In case of bottlenecks in performance, a lot of time is spent on monitoring and log analysis. When logging the timings of individual operations to a log file, it is usually difficult to understand what led to the call of these operations, to track the sequence of actions or the time shift of one operation relative to another in different services.
To minimize manual labor, we decided to use one of the trace tools. How and for what you can use the trace and how we did it, and will be discussed in this article.
What problems can be solved using tracing
- Find bottlenecks in performance both within a single service and throughout the execution tree between all participating services. For example:
')- Many short consecutive calls between services, for example, to geocoding or to a database.
- Long waiting for input / output, for example, data transfer over the network or disk read.
- Long data parsing.
- The long operations demanding cpu.
- Lots of code that are not needed for the final result and can be deleted or run deferred.
- Visually understand in what sequence what is called and what happens when an operation is performed.
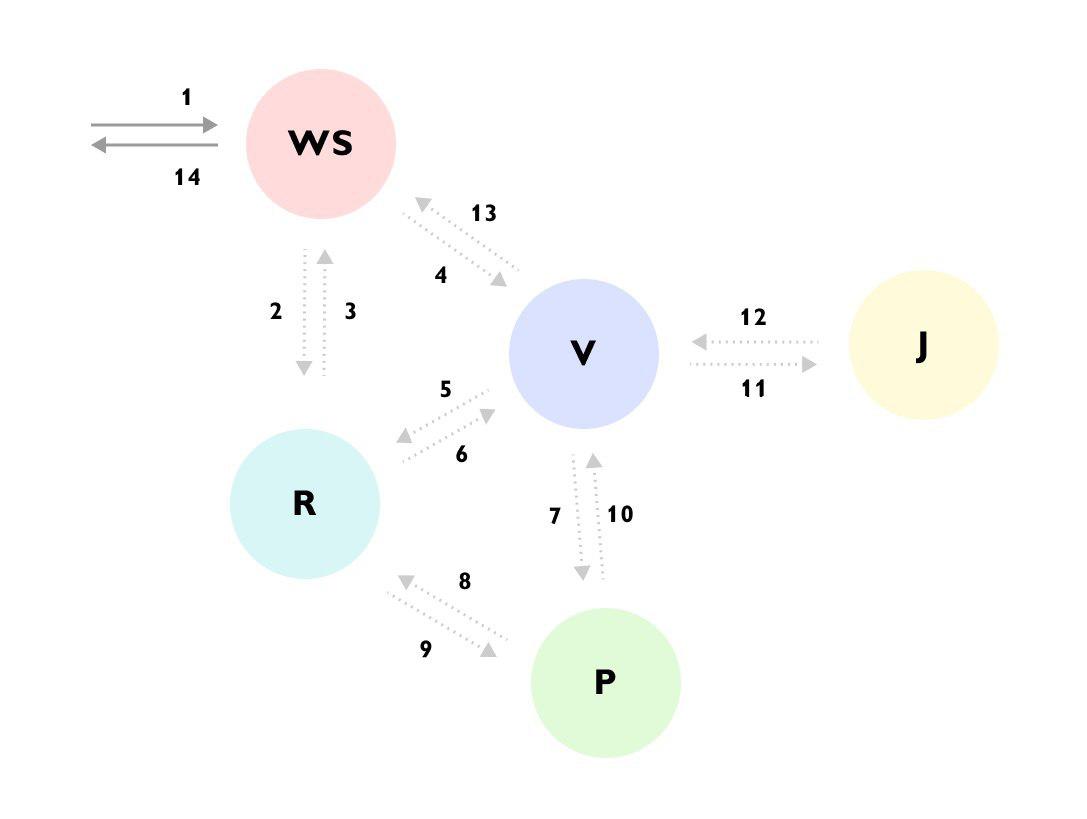
It can be seen that, for example, the Request came to the service WS -> the service WS supplemented the data through the service R -> then sent a request to the service V -> service V uploaded a lot of data from the service R -> went to the service P -> service P went again in service R -> service V ignored the result and went to service J -> and only then returned the answer to service WS, while continuing to calculate something else in the background.
Without such a trace or detailed documentation on the whole process it is very difficult to understand what is happening, having first looked at the code, and the code is scattered across different services and hidden behind a bunch of bins and interfaces. - Collection of information about the tree of execution for subsequent pending analysis. At each stage of the execution, you can add information that is available at this stage and further understand what input data led to such a scenario. For example:
- User ID
- The rights
- Type of method selected
- Log or execution error
- The transformation of traces into a subset of metrics and further analysis already in the form of metrics.
What can trace logging. Span
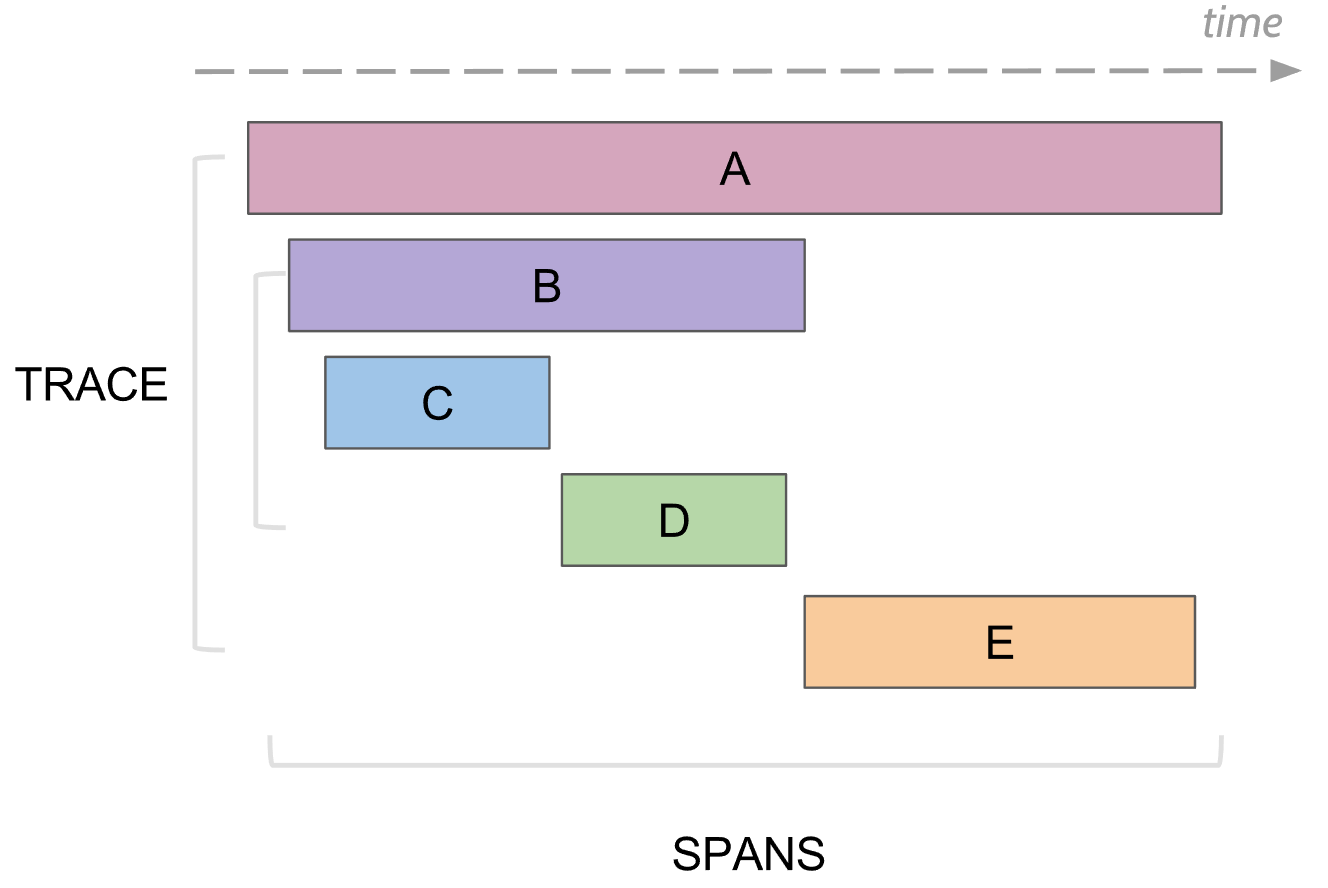
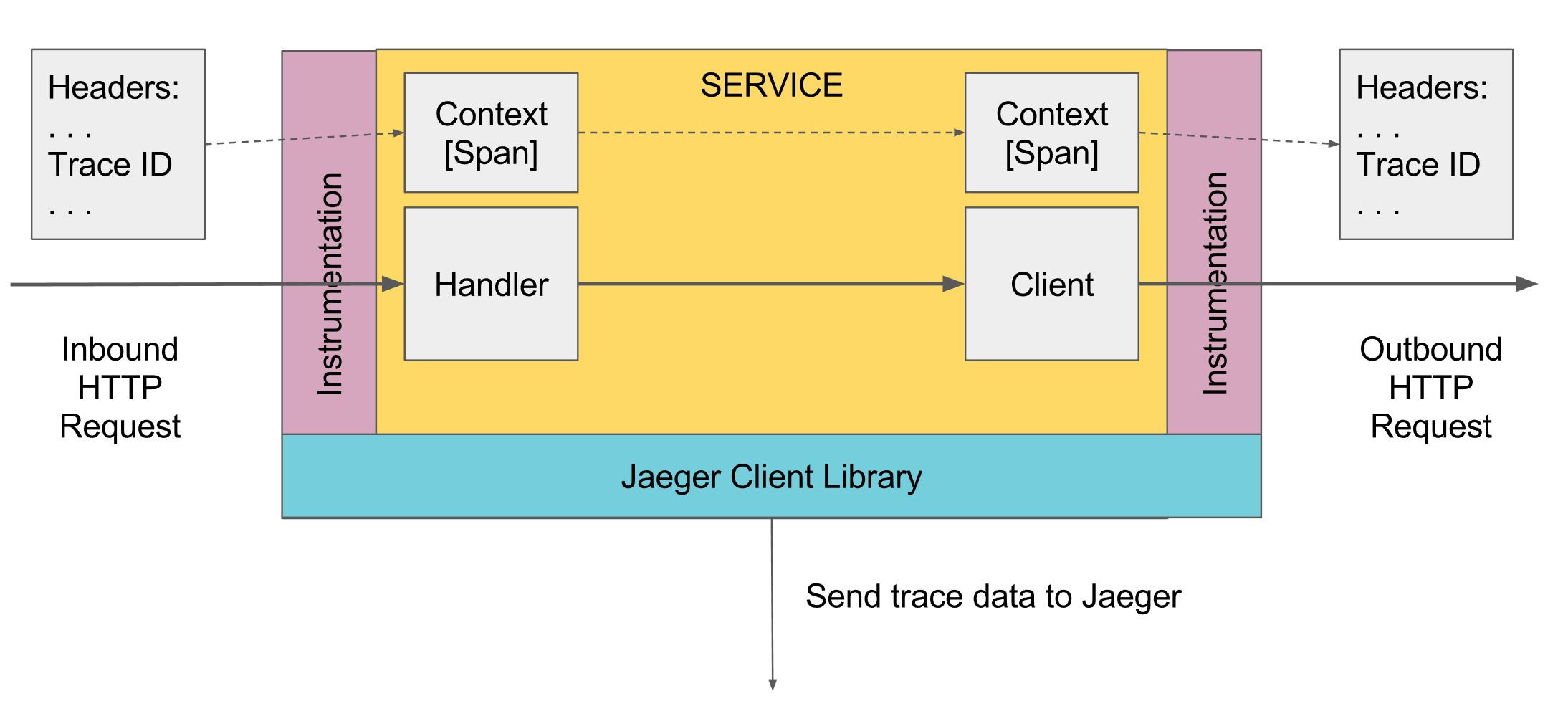
In the trace there is a concept of span, it is an analogue of one log, to the console. Span has:
- Name, usually the name of the method that was executed
- The name of the service in which the span was generated
- Own unique ID
- Some kind of meta information in the form of key / value, which was pledged into it. For example, method parameters or method ended with an error or not
- The start and end time of this run
- Parent Span ID
Each span is sent to the collector of spans for saving to the database for later viewing as soon as it has completed its execution. In the future, you can build a tree of all spans by connecting the parent's id. In the analysis, you can find, for example, all spans in some service that took more than some time. Next, going to a specific span, see the whole tree above and below this span.
Opentracing, Jagger and how we implemented it for our projects
There is a common standard for Opentracing , which describes how and what should be assembled, without being traced to a specific implementation in any language. For example, in Java, all work with traces is carried out through the general API Opentracing, and under it can be hidden, for example, Jaeger or an empty default implementation that does nothing.
We use Jaeger as an implementation of Opentracing. It consists of several components:
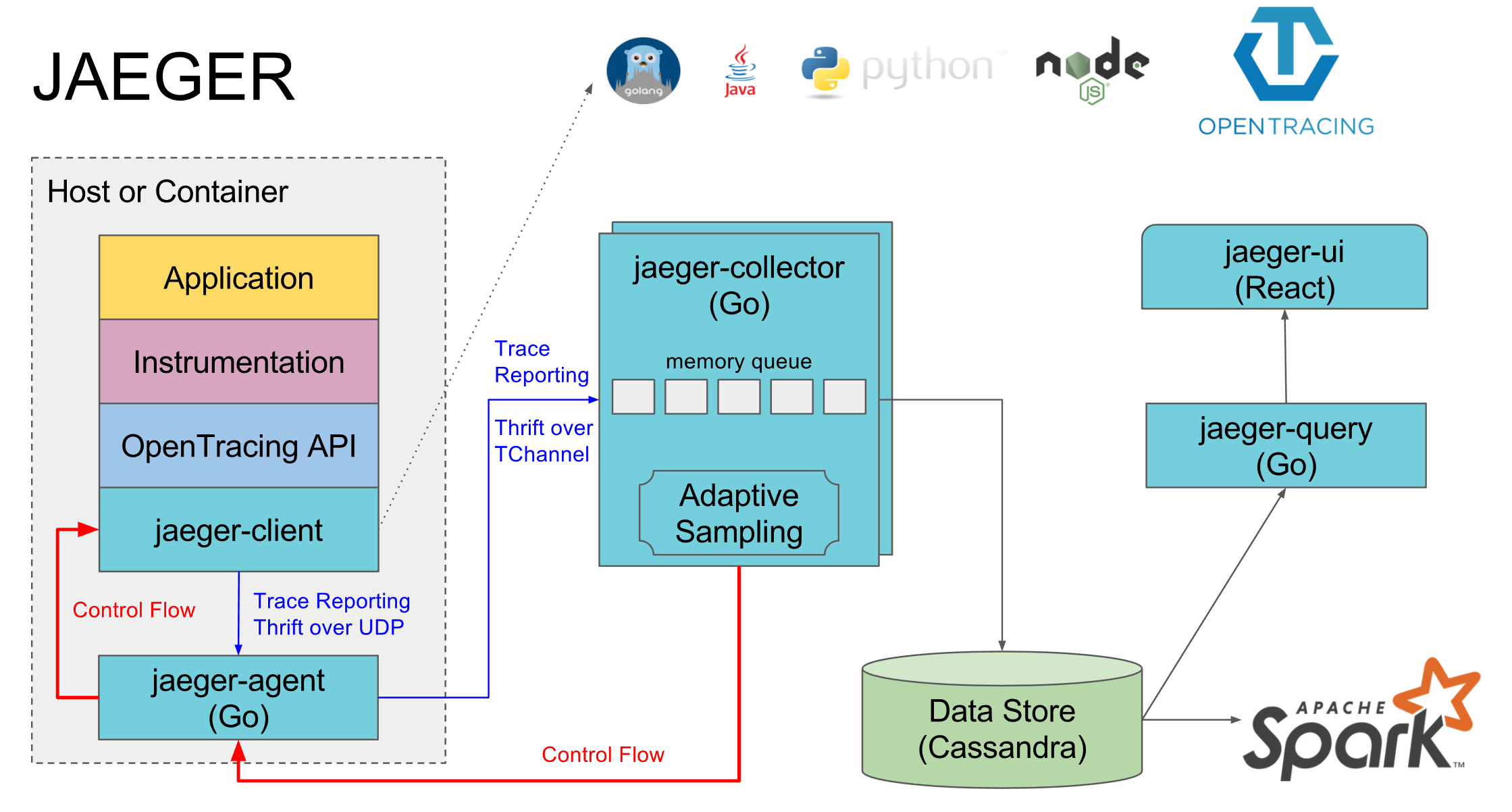
- Jaeger-agent is a local agent that usually stands on each machine and log services to it on the local default port. If there is no agent, then the traces of all services on this machine are usually turned off
- Jaeger-collector - all agents send the collected traces to it, and he puts them in the selected database
- The database is their preferred cassandra, but we use elasticsearch, there are implementations for a couple of other DBs and an in-memory implementation that does not save anything to disk.
- Jaeger-query is a service that goes to the database and gives already collected traces for analysis.
- Jaeger-ui is a web interface for searching and viewing traces, it goes to jaeger-query
A separate component is the implementation of opentracing jaeger for specific languages, through which spans are sent to the jaeger-agent.
Connecting Jagger in Java is to impose a simple io.opentracing.Tracer interface, after which all the traces through it will fly into the real agent.
Also for the components of the spring, you can connect opentracing-spring-cloud-starter and implementation from Jaeger opentracing-spring-jaeger-cloud-starter which automatically configures tracing for everything that passes through these components, for example http requests to controllers, requests to the database via jdbc etc.
Logging traces in Java
Somewhere at the very top level, the first Span must be created, this can be done automatically, for example, by the spring controller when a request is received, or manually if there is none. Then it is transmitted via Scope below. If some method below wants to add Span, it takes the current activeSpan from Scope, creates a new Span and says that its parent received activeSpan, and makes the new Span active. When external services are called, the current active span is transmitted to them, and those services create new spans with reference to this span.
All work goes through the Tracer instance, you can get it through the DI mechanism, or GlobalTracer.get () as a global variable if the DI mechanism does not work. By default, if the tracer was not initialized, NoopTracer will return and it will do nothing.
Further, the current scope is obtained from the tracer via ScopeManager, a new scope is created from the current one with the binding of a new span, and then the created Scope is closed, which closes the created span and returns the previous Scope to the active state. Scope is bound to a stream, therefore, in multi-threaded programming, one should not forget to transfer the active span to another stream, for further activation of the Scope of another stream with reference to this span.
io.opentracing.Tracer tracer = ...; // GlobalTracer.get() void DoSmth () { try (Scope scope = tracer.buildSpan("DoSmth").startActive(true)) { ... } } void DoOther () { Span span = tracer.buildSpan("someWork").start(); try (Scope scope = tracer.scopeManager().activate(span, false)) { // Do things. } catch(Exception ex) { Tags.ERROR.set(span, true); span.log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage())); } finally { span.finish(); } } void DoAsync () { try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) { ... final Span span = scope.span(); doAsyncWork(() -> { // STEP 2 ABOVE: reactivate the Span in the callback, passing true to // startActive() if/when the Span must be finished. try (Scope scope = tracer.scopeManager().activate(span, false)) { ... } }); } } For multi-threaded programming, there is also TracedExecutorService and similar wrappers that automatically forward the current span to the stream when the asynchronous task starts:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() ); For external http requests there is TracingHttpClient
HttpClient httpClient = new TracingHttpClientBuilder().build(); The problems we are facing
- Beans and DI does not always work if tracer is used not in a service or component, then Autowired Tracer may not work and will have to use GlobalTracer.get ().
- Annotations do not work if it is not a component or service, or if the method is called from a neighboring method of the same class. You need to be careful, check what works, and use the manual creation of the trace if @Traced does not work. It is also possible to fasten an additional compiler for java annotations, then it should work everywhere.
- In the old spring and spring boot, the opentraing spring cloud autoconfiguration does not work because of bugs in DI, then if you want to automatically work the traces in the components of the spring, you can do it by analogy with github.com/opentracing-contrib/java-spring-jaeger/blob/ master / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- In groovy does not work try with resources, you must use try finally.
- Each service must register its spring.application.name under which the traces will be logged. With that, a separate name for the sale and the test, so as not to interfere with them together.
- If you use GlobalTracer and tomcat, then all services running on this tomcat have one GlobalTracer, so they will have the same service name for all.
- When adding traces to a method, you need to be sure that it is not called in a loop many times. It is necessary to add one common trace for all calls, which will log the total running time. Otherwise, an overload will be created.
- Once in jaeger-ui, they made too large requests for a large number of traces, and since they did not wait for an answer, they did it again. As a result, jaeger-query began to eat a lot of memory and slow down the elastic. Helped restart jaeger-query
Sampling, storage and viewing of traces
There are three types of sampling traces :
- Const which sends and saves all traces.
- Probabilistic which filters traces with some given probability.
- Ratelimiting which limits the number of traces per second. You can configure these parameters on the client, either on the jaeger-agent or in the collector. Now we have const 1 used in the stack of valuators as there are not very many requests, but they take a long time. In the future, if it will exert excessive load on the system can be limited.
If you use cassandra, then by default it stores the traces only for two days. We use elasticsearch and traces are stored for all time and are not deleted. A separate index is created for each day, for example jaeger-service-2019-03-04. In the future, you need to set up an automatic cleanup of old traces.
In order to see the traces you need:
- Select a service for which you want to filter traces, for example tomcat7-default for a service that is running in Tomcote and cannot have its own name.
- Next, select the operation, the time period and the minimum operation time, for example, from 10 seconds to take only long runs.
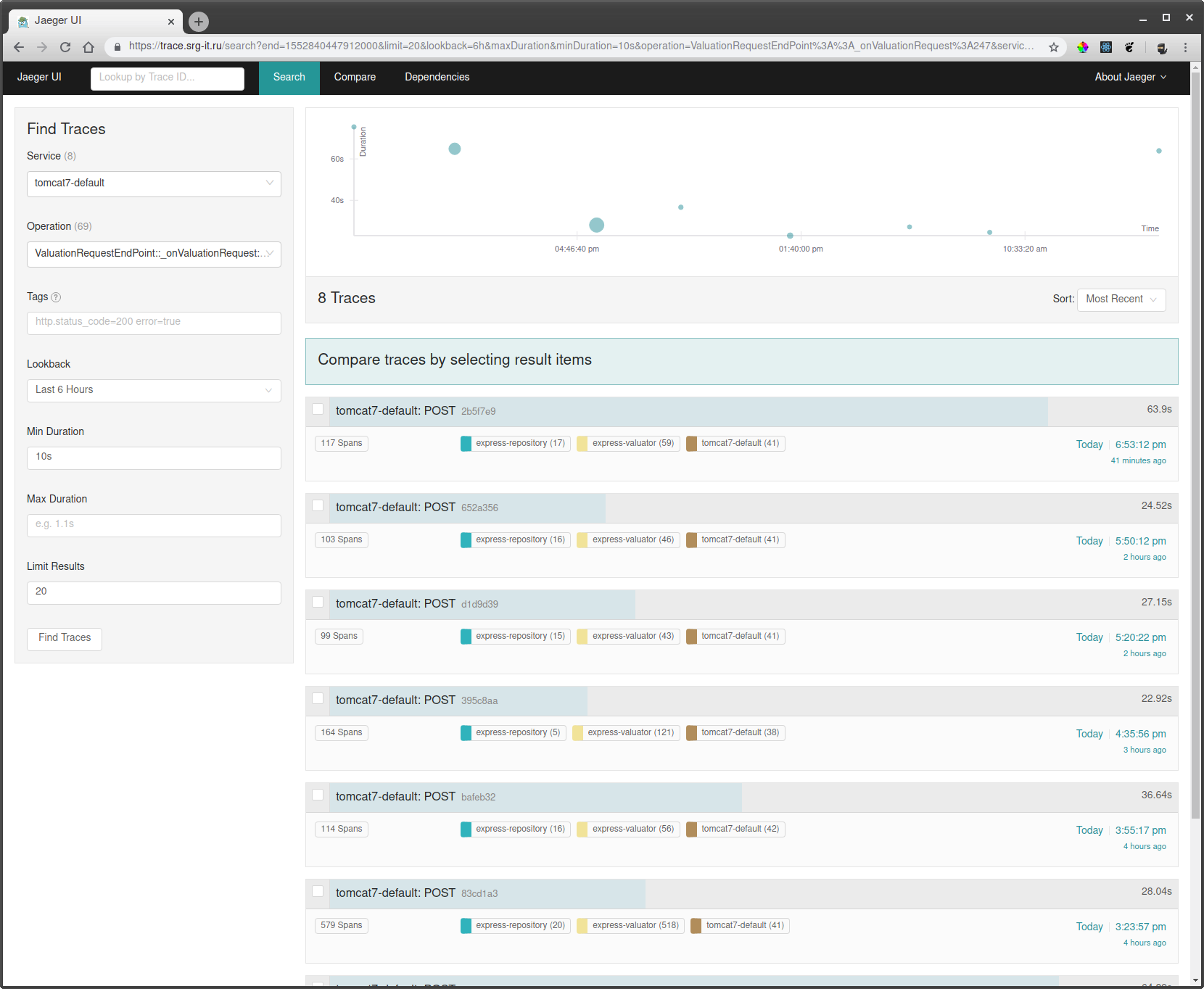
- Go to one of the traces and watch what was going on there.

Also, if you know some kind of request id, then you can find a trace by this id through a tag search, if that id is logged to the trace of the trace.
Documentation
- Documentation opentracing opentracing.io/docs/overview/what-is-tracing
- Documentation jaeger www.jaegertracing.io/docs/1.10
- Connecting jaeger java github.com/jaegertracing/jaeger-client-java
- Connection spring opentracing
github.com/jaegertracing/jaeger-client-java
github.com/opentracing-contrib/java-spring-cloud
Articles
- habr.com/ru/company/carprice/blog/340946 Jaeger Opentracing and Microservices in a real PHP and Golang project
- eng.uber.com/distributed-tracing Evolving Distributed Tracing at Uber Engineering
- opentracing.io/guides/java
- medium.com/jaegertracing/running-jaeger-agent-on-bare-metal-d1fc47d31fab Running Jaeger Agent on bare metal
Video
- www.youtube.com/watch?v=qg0ENOdP1Lo Bryan Boreham
- www.youtube.com/watch?v=WRntQsUajow Intro: Jaeger - Yuri Shkuro, Uber & Pavol Loffay, Red Hat
- www.youtube.com/watch?v=fsHb0qK37bc Serghei Iakovlev, “The Little Story of Big Victory: OpenTracing, AWS and Jaeger”
Source: https://habr.com/ru/post/446752/
All Articles