The basics of natural language processing for text
Natural language processing is currently not used unless in very conservative industries. In most technological solutions, the recognition and processing of “human” languages has long been implemented: that is why the usual IVR with hard-coded response options is gradually becoming a thing of the past, chatbots begin to communicate more adequately without a live operator, filters in the mail work with a bang, etc. How does the recognition of recorded speech, that is, text? Or rather, ask what is the basis of modern recognition and processing techniques? Our today's adapted translation responds well to this - under the cat you will find a longrid that closes the gaps in the basics of NLP. Enjoy reading!

Natural Language Processing (hereinafter - NLP) - natural language processing is a subsection of computer science and AI, dedicated to how computers analyze natural (human) languages. NLP allows the use of machine learning algorithms for text and speech.
For example, we can use NLP to create systems like speech recognition, document summarization, machine translation, spam detection, named entity recognition, question answers, autocomplete, predictive text input, etc.
')
Today, many of us have speech recognition smartphones — they use NLP to understand our speech. Also, many people use laptops with speech recognition built into the OS.

On Windows, there is a virtual assistant, Cortana, that recognizes speech. With Cortana, you can create reminders, open applications, send letters, play games, check the weather, etc.

Siri is an assistant for Apple's OS: iOS, watchOS, macOS, HomePod and tvOS. Many functions also work through voice control: call / write to someone, send a letter, set a timer, take a photo, etc.

A well-known mail service can detect spam so that it does not get into your inbox.

A platform from Google that allows you to create NLP bots. For example, you can make a bot to order a pizza that does not need an old-fashioned IVR to take your order .
NLTK (Natural Language Toolkit) is the leading platform for creating NLP programs in Python. It has easy-to-use interfaces for many language cases , as well as word processing libraries for classifying, tokenizing, stemming , marking , filtering, and semantic reasoning . Well, this is also a free open-source project that is being developed with the help of the community.
We will use this tool to show the basics of NLP. For all the following examples, I assume that the NLTK has already been imported; You can do this with the
In this article we will cover topics:
Tokenization (sometimes segmentation) by sentences is the process of splitting the written language into component sentences. The idea looks pretty simple. In English and some other languages, we can isolate a sentence every time we find a certain punctuation mark - a full stop.
But even in English, this task is not trivial, since the dot is also used in abbreviations. The abbreviation table can help a lot during word processing to avoid misallocating sentences. In most cases, libraries are used for this, so you may not particularly worry about implementation details.
Example:
Take a small text about the backgammon board game:
To make offers tokenization using NLTK, you can use the
At the output we get 3 separate sentences:
Tokenization (sometimes segmentation) by words is the process of dividing sentences into word-components. In English and many other languages that use one or another version of the Latin alphabet, a space is a good word delimiter.
However, problems may arise if we use only a space — in English, compound nouns are written differently and sometimes with a space. And here again the libraries help us.
Example:
Let's take the sentences from the previous example and apply the
Conclusion:
Typically, the texts contain different grammatical forms of the same word, and the same root words may also occur. Lemmatization and stemming aim to bring all occurring word forms to one, normal vocabulary form.
Examples:
Reduction of different word forms to one:
The same, but already applied to the whole sentence:
Lemmatization and stemming are special cases of normalization and they differ.
Stemming is a rough heuristic process that cuts off the “extra” from the root of words, often this leads to the loss of word-building suffixes.
Lemmatization is a more subtle process that uses vocabulary and morphological analysis to eventually bring the word to its canonical form - the lemma.
The difference is that a stemmer (a specific implementation of the algorithm of stemming - comment of the translator) operates without a knowledge of the context and, accordingly, does not understand the difference between words that have different meanings depending on the part of speech. However, stimmers have their advantages: they are easier to implement and they work faster. Plus, lower “accuracy” may not matter in some cases.
Examples:
Now that we know the difference, let's look at an example:
Conclusion:

Stop words are words that are discarded from the text before / after text processing. When we apply machine learning to texts, such words can add a lot of noise, so it’s necessary to get rid of irrelevant words.
Stop words are usually understood by articles, interjections, unions, etc., which do not carry meaning. It should be understood that there is no universal list of stop words, it all depends on the specific case.
NLTK has a predefined list of stop words. Before first use, you will need to download it:
Conclusion:
Consider how you can remove the stop words from the sentence:
Conclusion:
If you are not familiar with list comprehensions, you can learn more here . Here is another way to achieve the same result:
However, remember that list comprehensions are faster because they are optimized - the interpreter identifies the predictive pattern during the loop.
You may ask why we converted the list into a multitude . A set is an abstract data type that can store unique values in an undefined order. Search by set is much faster than search by list. For a small number of words it does not matter, but if we are talking about a large number of words, then it is strongly recommended to use sets. If you want to learn a little more about the time for performing various operations, look at this wonderful cheat sheet .

A regular expression (regular, regexp, regex) is a sequence of characters that defines a search pattern. For example:
Excerpt from the Python documentation :
The re module in Python represents regular expression operations. We can use the re.sub function to replace everything that matches the search pattern with the specified string. This is how you can replace all non-words with spaces:
Conclusion:
Regulars are a powerful tool, with its help you can create much more complex patterns. If you want to learn more about regular expressions, then I can recommend these 2 web applications: regex , regex101 .

Machine learning algorithms cannot directly work with raw text, therefore it is necessary to convert text into sets of numbers (vectors). This is called feature extraction .
A word bag is a popular and simple feature extraction technique used when working with text. It describes the occurrences of each word in the text.
To use the model, we need:
Any information on the order or structure of words is ignored. That is why it is called a BAG of words. This model tries to understand whether a familiar word occurs in a document, but does not know exactly where it occurs.
Intuition suggests that similar documents have similar content . Also, thanks to the content, we can learn something about the meaning of the document.
Example:
Consider the steps of creating this model. We use only 4 sentences to understand how the model works. In real life you will encounter large amounts of data.

Imagine that this is our data and we want to load it as an array:
To do this, it is enough to read the file and divide by rows:
Conclusion:

We collect all unique words from 4 loaded sentences, ignoring case, punctuation and single-character tokens. This will be our dictionary (famous words).
To create a dictionary, you can use the CountVectorizer class from the sklearn library. Go to the next step.

Next, we need to evaluate the words in the document. At this step, our goal is to turn raw text into a set of numbers. After that, we use these sets as input to a machine learning model. The simplest method of scoring is to mark the presence of words, that is, to put 1 if there is a word and 0 in its absence.
Now we can create a bag of words using the aforementioned class CountVectorizer.
Conclusion:
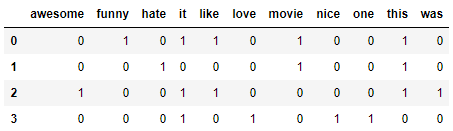
These are our suggestions. Now we see how the word bag model works.
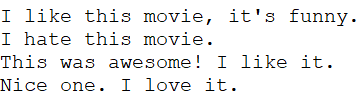

The complexity of this model is how to define a dictionary and how to count the occurrence of words.
When the size of the dictionary increases, the vector of the document also grows. In the example above, the length of the vector is equal to the number of known words.
In some cases, we can have an incredibly large amount of data and then the vector can consist of thousands or millions of elements. Moreover, each document can contain only a small part of the words from the dictionary.
As a result, there will be a lot of zeros in the vector representation. Vectors with a large number of zeros are called sparse vectors, they require more memory and computational resources.
However, we can reduce the number of known words when we use this model to reduce the requirements for computing resources. To do this, you can use the same techniques that we have already considered before creating a bag of words:
Another more complex way to create a dictionary is to use grouped words. This will change the size of the dictionary and give the bag more words about the document. This approach is called the " N-gram ."
An n-gram is a sequence of any entities (words, letters, numbers, numbers, etc.). In the context of language cases, an N-gram is usually understood as a sequence of words. A unigram is one word, a bigram is a sequence of two words, a trigram is three words, and so on. The number N indicates how many grouped words are included in the N-gram. Not all possible N-grams fall into the model, but only those that appear in the body.
Example:
Consider this sentence:
Here are his bigrams:
As you can see, the bag of bigrams is a more effective approach than a bag of words.
Scoring of words
When a dictionary is created, the presence of words should be evaluated. We have already considered a simple, binary approach (1 - there is a word, 0 - no word).
There are other methods:
Frequency scoring has a problem: the words with the highest frequency, respectively, have the highest rating. These words may not have as much informational gain for a model as in less frequent words. One way to remedy the situation is to lower the word grade, which is often found in all similar documents . This is called TF-IDF .
TF-IDF (short for term frequency - inverse document frequency) is a statistical measure for assessing the importance of a word in a document that is part of a collection or corpus.
TF-IDF scoring increases in proportion to the frequency with which a word appears in a document, but this is offset by the number of documents containing that word.
The scoring formula for word X in document Y is:
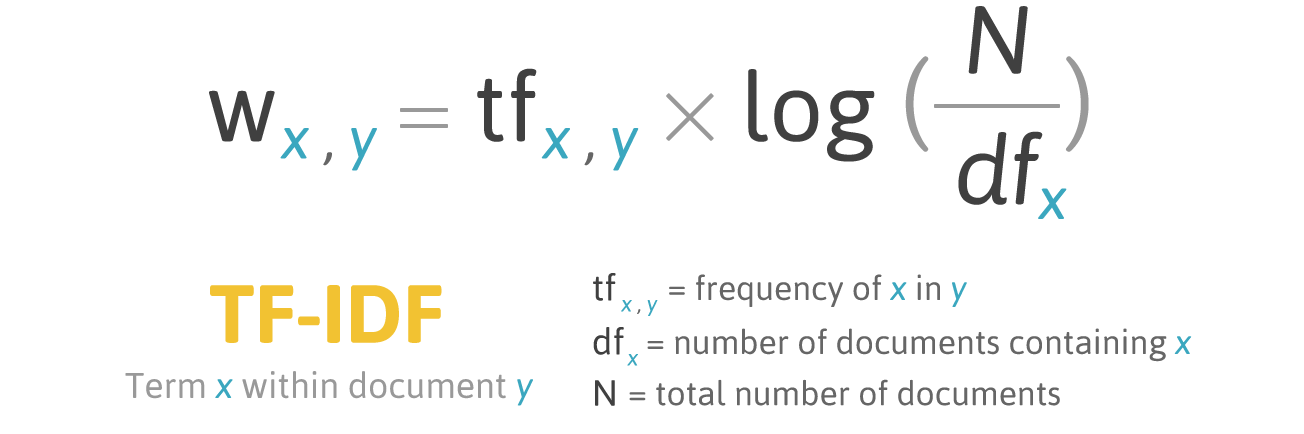
Formula TF-IDF. Source: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
TF (term frequency) is the ratio of the number of occurrences of a word to the total number of words in a document.
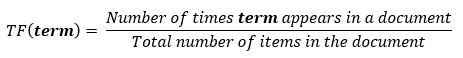
IDF (inverse document frequency) is the inverse of the frequency with which a word occurs in collection documents.

As a result, you can calculate TF-IDF for the word term as follows:
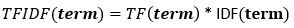
Example:
You can use the TfidfVectorizer class from the sklearn library to calculate the TF-IDF. Let's do this with the same messages that we used in the bag example.
Code:
Conclusion:

In this article, the basics of NLP for the text were disassembled, namely:
Fine! Now, knowing the basics of feature extraction, you can use features as input to machine learning algorithms.
If you want to see all the concepts described in one big example, then you are here .
What is Natural Language Processing?
Natural Language Processing (hereinafter - NLP) - natural language processing is a subsection of computer science and AI, dedicated to how computers analyze natural (human) languages. NLP allows the use of machine learning algorithms for text and speech.
For example, we can use NLP to create systems like speech recognition, document summarization, machine translation, spam detection, named entity recognition, question answers, autocomplete, predictive text input, etc.
')
Today, many of us have speech recognition smartphones — they use NLP to understand our speech. Also, many people use laptops with speech recognition built into the OS.
Examples
Cortana
On Windows, there is a virtual assistant, Cortana, that recognizes speech. With Cortana, you can create reminders, open applications, send letters, play games, check the weather, etc.
Siri
Siri is an assistant for Apple's OS: iOS, watchOS, macOS, HomePod and tvOS. Many functions also work through voice control: call / write to someone, send a letter, set a timer, take a photo, etc.
Gmail
A well-known mail service can detect spam so that it does not get into your inbox.
Dialogflow
A platform from Google that allows you to create NLP bots. For example, you can make a bot to order a pizza that does not need an old-fashioned IVR to take your order .
NLTK Python Library
NLTK (Natural Language Toolkit) is the leading platform for creating NLP programs in Python. It has easy-to-use interfaces for many language cases , as well as word processing libraries for classifying, tokenizing, stemming , marking , filtering, and semantic reasoning . Well, this is also a free open-source project that is being developed with the help of the community.
We will use this tool to show the basics of NLP. For all the following examples, I assume that the NLTK has already been imported; You can do this with the
import nltkBasics of NLP for text
In this article we will cover topics:
- Tokenization by suggestions.
- Tokenization by words.
- Lemmatization and stemming of the text.
- Stop words.
- Regular expressions.
- Bag of words .
- TF-IDF .
1. Tokenization by suggestions
Tokenization (sometimes segmentation) by sentences is the process of splitting the written language into component sentences. The idea looks pretty simple. In English and some other languages, we can isolate a sentence every time we find a certain punctuation mark - a full stop.
But even in English, this task is not trivial, since the dot is also used in abbreviations. The abbreviation table can help a lot during word processing to avoid misallocating sentences. In most cases, libraries are used for this, so you may not particularly worry about implementation details.
Example:
Take a small text about the backgammon board game:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice. To make offers tokenization using NLTK, you can use the
nltk.sent_tokenize methodAt the output we get 3 separate sentences:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice. 2. Tokenization by words
Tokenization (sometimes segmentation) by words is the process of dividing sentences into word-components. In English and many other languages that use one or another version of the Latin alphabet, a space is a good word delimiter.
However, problems may arise if we use only a space — in English, compound nouns are written differently and sometimes with a space. And here again the libraries help us.
Example:
Let's take the sentences from the previous example and apply the
nltk.word_tokenize method to them nltk.word_tokenizeConclusion:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.'] 3. Lemmatization and stemming of text
Typically, the texts contain different grammatical forms of the same word, and the same root words may also occur. Lemmatization and stemming aim to bring all occurring word forms to one, normal vocabulary form.
Examples:
Reduction of different word forms to one:
dog, dogs, dog's, dogs' => dog The same, but already applied to the whole sentence:
the boy's dogs are different sizes => the boy dog be differ size Lemmatization and stemming are special cases of normalization and they differ.
Stemming is a rough heuristic process that cuts off the “extra” from the root of words, often this leads to the loss of word-building suffixes.
Lemmatization is a more subtle process that uses vocabulary and morphological analysis to eventually bring the word to its canonical form - the lemma.
The difference is that a stemmer (a specific implementation of the algorithm of stemming - comment of the translator) operates without a knowledge of the context and, accordingly, does not understand the difference between words that have different meanings depending on the part of speech. However, stimmers have their advantages: they are easier to implement and they work faster. Plus, lower “accuracy” may not matter in some cases.
Examples:
- The word good is a lemma for the word better. Stemmer will not see this connection, because here you need to check with the dictionary.
- The word play is the basic form of the word playing. Both stemming and lemmatization can do this.
- The word meeting can be both the normal form of the noun and the verb form to meet, depending on the context. Unlike stemming, lemmatization will try to choose the right lemma based on context.
Now that we know the difference, let's look at an example:
Conclusion:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive 4. Stop words
Stop words are words that are discarded from the text before / after text processing. When we apply machine learning to texts, such words can add a lot of noise, so it’s necessary to get rid of irrelevant words.
Stop words are usually understood by articles, interjections, unions, etc., which do not carry meaning. It should be understood that there is no universal list of stop words, it all depends on the specific case.
NLTK has a predefined list of stop words. Before first use, you will need to download it:
nltk.download(“stopwords”) . After downloading, you can import the stopwords package and look at the words themselves:Conclusion:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"] Consider how you can remove the stop words from the sentence:
Conclusion:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.'] If you are not familiar with list comprehensions, you can learn more here . Here is another way to achieve the same result:
However, remember that list comprehensions are faster because they are optimized - the interpreter identifies the predictive pattern during the loop.
You may ask why we converted the list into a multitude . A set is an abstract data type that can store unique values in an undefined order. Search by set is much faster than search by list. For a small number of words it does not matter, but if we are talking about a large number of words, then it is strongly recommended to use sets. If you want to learn a little more about the time for performing various operations, look at this wonderful cheat sheet .
5. Regular expressions.
A regular expression (regular, regexp, regex) is a sequence of characters that defines a search pattern. For example:
- . - any character except newline;
- \ w - one word;
- \ d is one digit;
- \ s - one space;
- \ W - one is not a word;
- \ D is one Netsifra;
- \ S - one bad;
- [abc] - finds any of the specified characters match any of a, b, or c;
- [^ abc] - finds any character except the specified ones;
- [ag] - finds a character in the range from a to g.
Excerpt from the Python documentation :
A regular expression uses a backslashWe can use regulars to further filter our text. For example, you can remove all characters that are not words. In many cases, punctuation is not needed and is easy to remove with the help of regulars.(\)to indicate special forms or to allow the use of special characters. This is contrary to the use of the backslash in Python: for example, to literally mark a backslash, you need to write'\\\\'as a pattern for the search, because the regular expression should look like\\, where each backslash should be escaped.
The solution is to use raw string notation for search patterns; backslashes will not be processed in a special way if used with the'r'prefix. Thus,r”\n”is a string with two characters('\' 'n'), and“\n”is a string with one character (newline).
The re module in Python represents regular expression operations. We can use the re.sub function to replace everything that matches the search pattern with the specified string. This is how you can replace all non-words with spaces:
Conclusion:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing ' Regulars are a powerful tool, with its help you can create much more complex patterns. If you want to learn more about regular expressions, then I can recommend these 2 web applications: regex , regex101 .
6. A bag of words
Machine learning algorithms cannot directly work with raw text, therefore it is necessary to convert text into sets of numbers (vectors). This is called feature extraction .
A word bag is a popular and simple feature extraction technique used when working with text. It describes the occurrences of each word in the text.
To use the model, we need:
- Define a dictionary of known words (tokens).
- Select the degree of presence of famous words.
Any information on the order or structure of words is ignored. That is why it is called a BAG of words. This model tries to understand whether a familiar word occurs in a document, but does not know exactly where it occurs.
Intuition suggests that similar documents have similar content . Also, thanks to the content, we can learn something about the meaning of the document.
Example:
Consider the steps of creating this model. We use only 4 sentences to understand how the model works. In real life you will encounter large amounts of data.
1. Load the data
Imagine that this is our data and we want to load it as an array:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it. To do this, it is enough to read the file and divide by rows:
Conclusion:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.'] 2. Define a dictionary
We collect all unique words from 4 loaded sentences, ignoring case, punctuation and single-character tokens. This will be our dictionary (famous words).
To create a dictionary, you can use the CountVectorizer class from the sklearn library. Go to the next step.
3. Create document vectors
Next, we need to evaluate the words in the document. At this step, our goal is to turn raw text into a set of numbers. After that, we use these sets as input to a machine learning model. The simplest method of scoring is to mark the presence of words, that is, to put 1 if there is a word and 0 in its absence.
Now we can create a bag of words using the aforementioned class CountVectorizer.
Conclusion:
These are our suggestions. Now we see how the word bag model works.
Just a few words about the bag of words
The complexity of this model is how to define a dictionary and how to count the occurrence of words.
When the size of the dictionary increases, the vector of the document also grows. In the example above, the length of the vector is equal to the number of known words.
In some cases, we can have an incredibly large amount of data and then the vector can consist of thousands or millions of elements. Moreover, each document can contain only a small part of the words from the dictionary.
As a result, there will be a lot of zeros in the vector representation. Vectors with a large number of zeros are called sparse vectors, they require more memory and computational resources.
However, we can reduce the number of known words when we use this model to reduce the requirements for computing resources. To do this, you can use the same techniques that we have already considered before creating a bag of words:
- ignore word case;
- ignoring punctuation;
- discarding stop words;
- reduction of words to their basic forms (lemmatization and stemming);
- correction of incorrectly written words.
Another more complex way to create a dictionary is to use grouped words. This will change the size of the dictionary and give the bag more words about the document. This approach is called the " N-gram ."
An n-gram is a sequence of any entities (words, letters, numbers, numbers, etc.). In the context of language cases, an N-gram is usually understood as a sequence of words. A unigram is one word, a bigram is a sequence of two words, a trigram is three words, and so on. The number N indicates how many grouped words are included in the N-gram. Not all possible N-grams fall into the model, but only those that appear in the body.
Example:
Consider this sentence:
The office building is open today Here are his bigrams:
- the office
- office building
- building is
- is open
- open today
As you can see, the bag of bigrams is a more effective approach than a bag of words.
Scoring of words
When a dictionary is created, the presence of words should be evaluated. We have already considered a simple, binary approach (1 - there is a word, 0 - no word).
There are other methods:
- Amount. It is calculated how many times each word occurs in the document.
- Frequency. It is calculated how often each word occurs in the text (in relation to the total number of words).
7. TF-IDF
Frequency scoring has a problem: the words with the highest frequency, respectively, have the highest rating. These words may not have as much informational gain for a model as in less frequent words. One way to remedy the situation is to lower the word grade, which is often found in all similar documents . This is called TF-IDF .
TF-IDF (short for term frequency - inverse document frequency) is a statistical measure for assessing the importance of a word in a document that is part of a collection or corpus.
TF-IDF scoring increases in proportion to the frequency with which a word appears in a document, but this is offset by the number of documents containing that word.
The scoring formula for word X in document Y is:
Formula TF-IDF. Source: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
TF (term frequency) is the ratio of the number of occurrences of a word to the total number of words in a document.
IDF (inverse document frequency) is the inverse of the frequency with which a word occurs in collection documents.
As a result, you can calculate TF-IDF for the word term as follows:
Example:
You can use the TfidfVectorizer class from the sklearn library to calculate the TF-IDF. Let's do this with the same messages that we used in the bag example.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it. Code:
Conclusion:
Conclusion
In this article, the basics of NLP for the text were disassembled, namely:
- NLP allows the use of machine learning algorithms for text and speech;
- NLTK (Natural Language Toolkit) - the leading platform for creating NLP-programs in Python;
- sentence tokenization is the process of splitting a written language into component sentences;
- word tokenization is the process of splitting sentences into word components;
- Lemmatization and stemming aim to bring all occurring word forms to one, normal vocabulary form;
- stop words are words that are discarded from the text before / after text processing;
- A regular expression (regular, regexp, regex) is a sequence of characters that defines a search pattern;
- A bag of words is a popular and simple feature extraction technique used when working with text. It describes the occurrences of each word in the text.
Fine! Now, knowing the basics of feature extraction, you can use features as input to machine learning algorithms.
If you want to see all the concepts described in one big example, then you are here .
Source: https://habr.com/ru/post/446738/
All Articles