How we saved the code review

I am a leading Java developer in Yandex.Money.
Every working morning in 2018 I was met by about 30 pull-requests waiting for a review, but I did not have enough time to sort them all out in a day. At the end of the summer I went on vacation, and when I returned, I found a line of 50 PR assigned to me. There was no desire to rake them, and this was only the tip of the iceberg, which I saw with my own eyes. That day I decided that it was time to change something.
This is a story about how we accelerated the code review, unloaded the leading developers and improved the tools we use every day.
Code Review 1.0. As it was before?
In Yandex.Money, the code review has long been a mandatory development stage, and everyone has become accustomed to this. Some understood that this is the same necessary thing as testing; others treated it as a necessary evil, and someone came across a code review only as the author of pull requests, but he avoided reviewing someone else's code. I think many people have traveled a path consistently from the last to the first, and this is normal.
For code review, we used Bitbucket from the start. For each component repository, a list of 3-4 default viewers was added, which were added to all PRs. Usually this list was compiled and edited by the head of the department, and sometimes volunteers who wanted to review a particular component were added there. The library repositories were a bit simpler - the list of reviewers was the same for all libraries, and senior developers were included there.
As a result, almost the entire burden fell on the senior developers, who gradually ceased to be enough, given the growth of the department up to 60 people, increasing the number of repositories (60+ components, 100+ libraries) and speeding up our CI / CD.
In addition to the large load and lack of resource resources, there were other problems:
- in some components, one could expect a reaction of reviewers for more than a day,
- high workload of those who are appointed as a reviewer in several components,
- It is difficult to attract new reviewers, including because of the previous paragraph,
- if the main reviewer got sick or on vacation, the time with the code-review of components began to increase noticeably,
- The assigned reviewers did not always have a real expertise in the component, because of this, the quality of the code review suffered.
Before you solve these problems, you need to decide on what we generally expect from the code review.
The correct code review is like?
We have identified four points that should be in the updated revision code:
- Check solution architecture . Pretty obvious thing. We expect this from senior developers with expertise in this component.
- Verification of the technical implementation , which we expect also from senior and midlov with expertise in this component.
- The transfer of knowledge , which is the study of business logic and code base for beginners and junami through code review.
- Ability to assess hard skills of developers . I would like for each developer to be assigned a mentor who assesses growth, determines the development vector, notices any shortcomings, makes comments, and so on. Therefore, a mentor must also see the code of his charges.
Perhaps someone sees other goals or does not agree with ours - share in the comments. For now, I will move from setting goals to finding the means to achieve them - we decided that we want to achieve them all and (almost) immediately.
Code Review 2.0. How come?
What did we come up with? We began to argue step by step.
In Yandex.Money, developers work in teams on business lines, usually 2-4 backend developers per team.
Suppose I am going to open a pull-request, that is, I am its author . I have my team , whose developers are well aware of the business logic of what I do, because we all participate in common projects, often synchronize and actively interact in general. Therefore, I want to add them to my pull-requests first of all, so that at least they know what I am doing.
Each component in Yandex.Money is assigned a team that is responsible for it and accompanies on production.
If I modify the component for which another team is responsible, then it seems logical to add developers from this team to the reviewers - they are responsible for this component and should monitor the quality of its code. But in order not to overload the reviewers, we take only one random person from this team - we believe that this is enough.
It may happen that the team responsible for the component does not have sufficient expertise in it. This happens when newcomers appear in the team or they have been entrusted with this component only recently. However, I know that we have real experts on this repository in our company, and it would be great if some of them look at my code! Of course, my knowledge is difficult to formalize, but you can take the history of the repository and count the code review by the number of PR and statistics, who have been working on this code and / or reviewing it a lot. We calculate the examination metrics in the repository, select the top developers for this metric, call them experts, and add one random expert to the reviewers.
In 2018, we introduced a mentoring institute in the company, so now for each team is looked after by one mentor from among the senior developers. Also, every newcomer in the company at first has a personal tutor.
Let my code look my mentor! He will be able to come to the rescue in case of problems with the code review, and will also have an idea of my technical strengths and weaknesses.
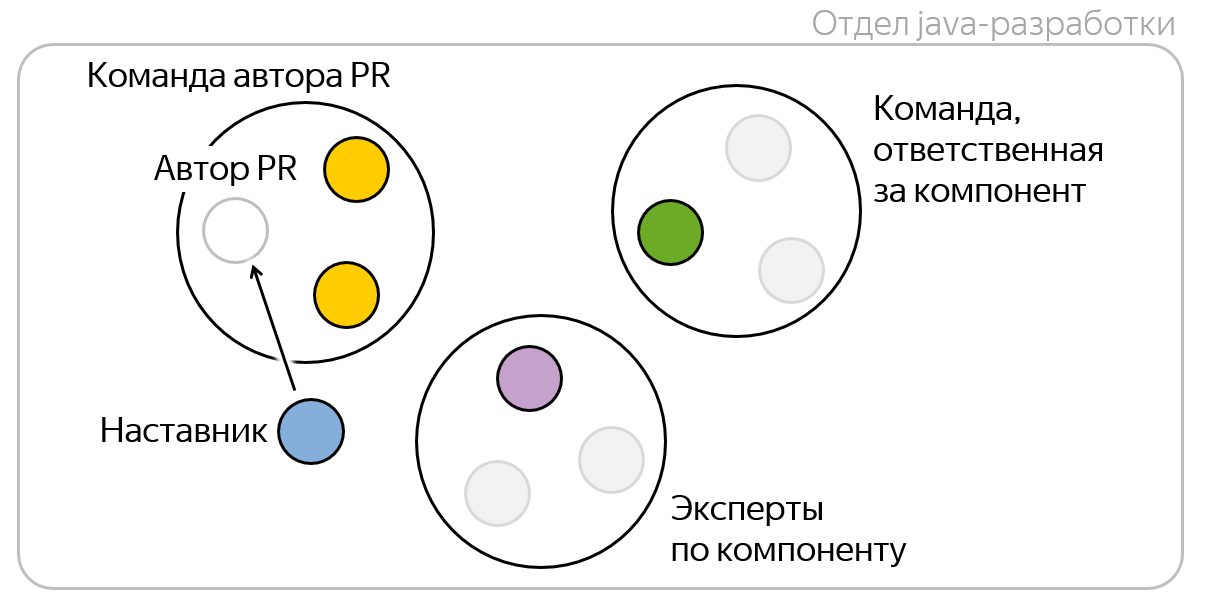
In total, five or six people can be added to the reviewers of each pull request. But in fact, they are usually a little smaller, because different roles can be combined in one person. My mentor may be an expert at the same time, and my team may be responsible for the component. Subjectively, it seems that 3-4 reviewers would be optimal for pull requests.
Code Review 2.0. What is under the hood?
Things are easy: make it all work. It was helped here by the fact that all of our teams were already established in a separate system that provides the REST API for their receipt. Therefore, after a couple of weeks of leisurely development in free time, the first version of the plug-in for Bitbucket was born, which was gradually refined and acquired all the necessary functionality during the autumn.
How the plugin works
Usually in Bitbucket when creating a PR, reviewers are prefilled, which are specified in the settings of the project or repository. Here, from the user's point of view, nothing has changed - all the reviewers are also pre-populated when opening this page, except that a field has been added describing which reviewer in which role was added. And the roles of reviewers have the following:
- teammate is a member of the PR team of the author; it is easily added thanks to the REST API with teams of teams,
- repository owner is a random member of the team responsible for the component; it was necessary in the repository settings to give the opportunity to choose the responsible team
- repository expert - random repository expert; I'll tell you more about this later
- mentor - a team or novice mentor, is also available via a REST API from a service with teams.
Repository experts
A little more talk about how we consider the experts. Every day, the plugin goes through all repositories, looks at all pull-requests for the last year and counts two simple metrics:
- the number of pull requests created by the developer
- the amount of PR that he has developed and set approve, needs work or decline.
Add weights to these metrics based on the fact that from the point of view of expertise in the code, the refinement of this code is more important than the review. First, we estimated the number of pull requests created by one and a half times more important than the review, and later we increased the ratio to three to one. We summarize these metrics multiplied by their weights, and we get the developer rating.
Next, we sort all these developers by rating, select the top-5, and at the same time we cut off those whose rating is below the threshold to cut off bystanders. And we usually get from three to five experts for each repository.
Above, I described to you the approach to the selection of reviewers that we chose and implemented, but at the same time we implemented several small improvements that made the code review process even faster, more convenient and more pleasant.
Banning a merge pull request until a task is verified in Jira
Such an obvious and necessary thing, which, unfortunately, does not go out of the box. We only get stable code in dev, which passed not only static checks and developer tests, but also integration testing along with other services. The status of such testing in our country is reflected only in the Jira task, and therefore, earlier, developers had to manually look at whether the task was checked in order to hold the pull-request.
Automatic merge pull requests
A large part of his life may be spent in a state when he doesn’t prevent him from holding anything, but the person forgets to do it or doesn’t do it right away. A striking example is the expectation of testing a task, without which we are not merging it in dev. This is where the automatic merge comes in handy, which works on a simple principle: if PR can be held down, then we do it.
All necessary conditions for merge are covered with checks. We check the success of the build, the level of test coverage, the lack of snapshot dependencies of the libraries, the status of the task in Jira, and the presence of all the necessary tools. That is, we have everything to use such functionality and forget about PR from the moment the code review is passed and the task is passed to testing (unless of course QA doesn’t detect problems in it).
And we implemented it in a rather convenient way: we entered a special bot, AutoMergeBot, which just needs to be added to the reviewers so that it starts monitoring this pull request and retains it when the time comes.
Accounting for the absence of reviewers
If the owner of the component or an expert is on vacation or at the hospital, he will not be added to the reviewer, and the one who is in the workplace will take his place. As a bonus for this reviser, when leaving a vacation, there will not be a mountain of alien pull requests. It was not difficult to implement it due to the fact that all the absences of our employees were initiated by applications in Jira.
Accounting employment reviewers
Someone reviews ten PR a day, and someone five. Someone has already accumulated 20 unprecedented PR, and someone has almost none. We take all this into account in order to more evenly distribute the burden on the viewers. The more load, the less it is added to the new PR - everything is simple.
Marking the size of PR when creating
On the page for creating a pull request, the author can choose his approximate size: S, M or L. This helps the reviewers estimate the estimated time they will spend on the code review. For example, I have 5 minutes free, and I understand that I can manage to see the pull-requisition of size S. It makes no sense to open M or L, because I don’t have time to watch them and next time I’ll have to start from scratch.
In the future, we want to take these attributes into account when calculating PR statistics.
Urgent PR marking
Also, when creating a PR, the author can indicate that the task is very urgent, by adding such a symbol to the PR name. It will immediately see the reviewers and try to look first. It seems a trifle, but very useful and convenient.
Tracking start and end code review
If during the improvement of the process it is impossible to understand how much it has improved, then there is no point in starting.
So with the code review - we can try to improve it as much as we want, but how can we be sure of the positive dynamics without metrics and statistics? In our case, this is not the easiest task - out of the box, Bitbucket and Jira did not give an opportunity to track the time of the code review. In service was only the metric of the lifetime of PR, which did not quite suit us, because we merged pull-requests only after the end of the testing task, therefore extraneous indicators were mixed in this metric.
Jira stores and allows you to unload all control points of the life cycle of a task, so we thought it would be right to enrich this data with two additional tags: the start and end time with a code review. It was necessary just to teach the plugin for Bitbucket to push these tags in Jira. Thus, Jira both was and remains single point of truth for the task, and for this data set we can separate the code review time from the task testing time.
The most subtle point here is how to determine the end of the code review? Maybe this is the time to receive the first approx, maybe the last, or maybe this is the time of the last edits being made by the PR author? I do not have an answer to this question, here you just need to agree among themselves and choose one thing or cover all three events with metrics and follow the deviations.
Tracking download reviewers
Another useful metric is the workload of reviewers. As I wrote above, we take it into account when assigning auditors to new PRs, but we also publish this information in order to follow the dynamics by team, department or company. Sometimes it helps to detect anomalies and potential problems: if you can see that one or several people in a team have 10 or more PRs not seen every day, then there is a reason to find out if everything is in order.
View metrics in Grafana
Building reports on data from Jira is useful, but not very convenient, so at the same time we added sending metrics on major events in StatsD in order to build graphs based on real-time data in Grafana. We monitor the average time to the first upruva, the average lifetime of PR, and also look at the anomalous values for these metrics in order to quickly find and solve problems.
At the time of this writing, our dashboard looks like this:
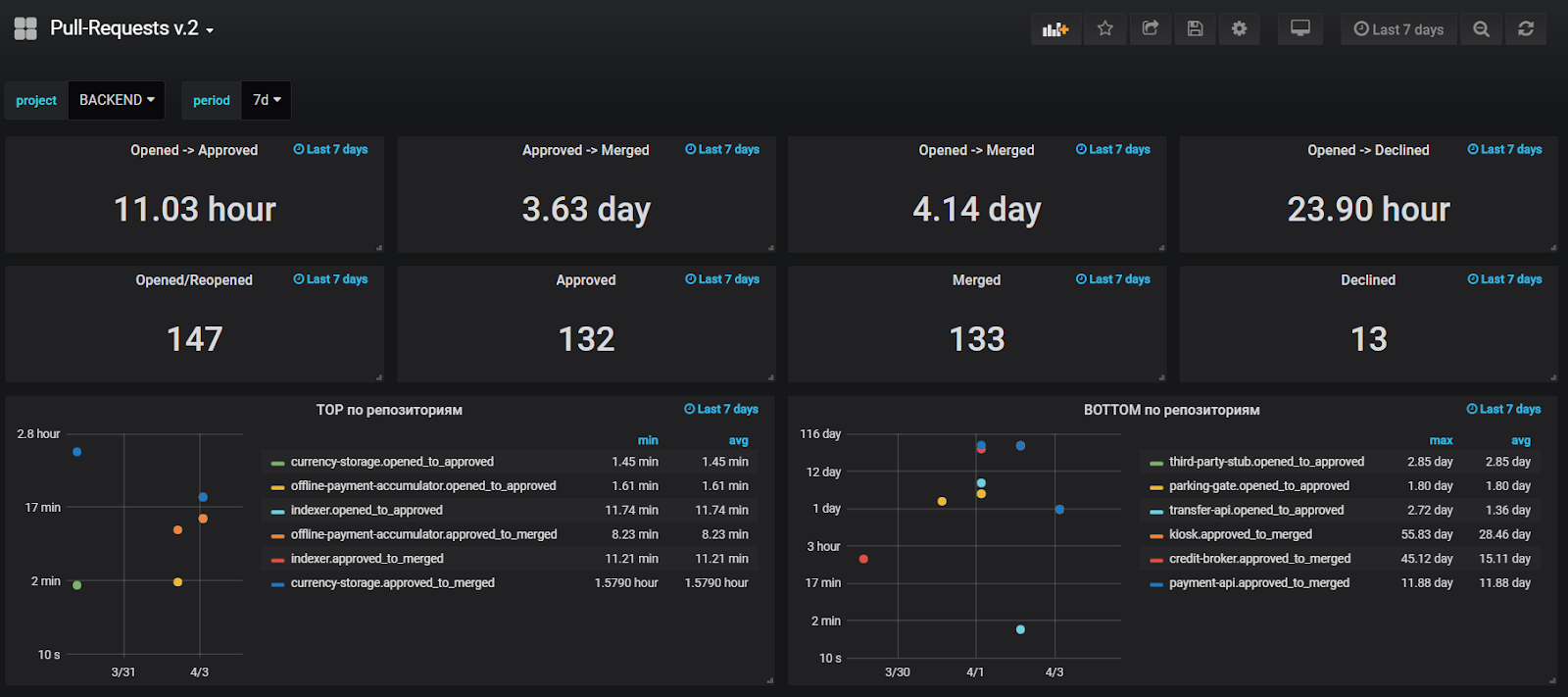
What was the result?
Unfortunately, we are all strong in hindsight, so we did not introduce the metrics mentioned above with the code review before the change in the process itself (September-October 2018), but along the way, so we can reliably track improvements or deterioration only from the beginning of December 2018 What did we have time to notice?
First of all, the reduction of the burden on senior developers is striking, and I felt this by my own example. As I already mentioned, for me it was the norm to see about 30 PR in the queue in the morning, but now this number ranges between 10 and 15. The department statistics confirms this: since December 2018, no one has raised the maximum number of PRs waiting for a review above 15. On average, we see a picture that says that on average, every developer expects 4-5 unprecedented PRs in the morning, which seems to be quite an adequate number.
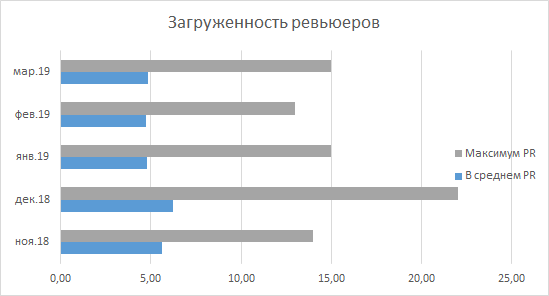
As for the relevance of the selection of reviewers and the quality of the code review, here we can only rely on subjective indicators. According to the surveys of colleagues, we really began to receive an excellent selection of reviewers, no one has to be added manually now, and no PR remains abandoned and forgotten.
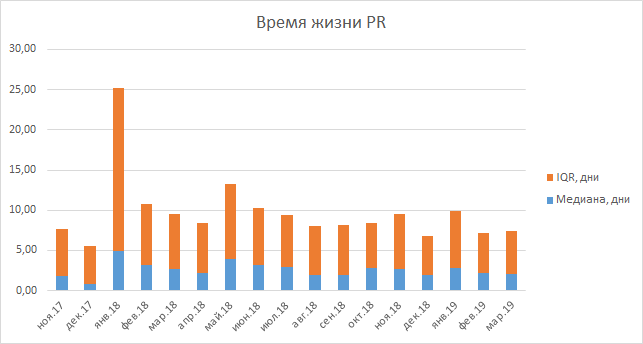
If we talk about the passage of the code review, it is still too early to calculate statistics on this indicator, because we started collecting it quite recently. At our disposal there is only the lifetime of pull-rekvestov, which actually did not grow and did not fall. This metric includes the time for testing the task, so it is difficult to draw definitive conclusions on it, and, in addition, by changing the revision code, we did not make it longer.
')
Source: https://habr.com/ru/post/446654/
All Articles